The series so far:
- Introduction to SQL Server Security — Part 1
- Introduction to SQL Server Security — Part 2
One of the most important tasks that DBAs must perform when managing a SQL Server database is to ensure that authorized users can access the data they need and carry out the necessary operations on that data. To this end, SQL Server includes a number of components for authenticating users and authorizing them to access objects at the server, database, and schema levels, while preventing unauthorized users from doing anything they should not.
In the first article in this series, I introduced you to authentication and authorization as part of a larger discussion about SQL Server security. In this article, I dig deeper into these topics and provide some examples that demonstrate how to implement basic access controls on a SQL Server 2017 instance.
Note, however, that authentication and authorization are huge topics. For this reason, you might also want to refer to a couple of other Simple Talk articles, one that I wrote and the other by Phil Factor:
You should also refer to Microsoft documentation as necessary to ensure you fully understand what types of access you’re granting to your users and what tasks they can and cannot perform. A good place to start is with Security Center for SQL Server Database Engine and Azure SQL Database, which covers a number of important aspects of SQL Server security, including access control.
Getting Started with Authentication and Authorization
SQL Server provides three types of components for controlling which users can log onto SQL Server, what data they can access, and which operations they can carry out:
- Principals: Individuals, groups, or processes granted access to the SQL Server instance, either at the server level or database level. Server-level principals include logins and server roles. Database-level principals include users and database roles.
- Securables: Objects that make up the server and database environment. The objects can be broken into three hierarchical levels:
- Server-level securables include such objects as databases and availability groups.
- Database-level securables include such objects as schemas and full-text catalogs.
- Schema-level securables include such objects as tables, views, functions, and stored procedures.
- Permissions: The types of access permitted to principals on specific securables. You can grant or deny permissions to securables at the server, database, or schema level. The permissions you grant at a higher level of the hierarchy also apply to children and grandchildren objects, unless you specifically deny those permissions at the lower level.
Together, these three component types provide a structure for authenticating and authorizing SQL Server users. You must grant each principal the appropriate permissions it needs on specific securables to enable users to access SQL Server resources. For example, if the sqluser01 database user needs to be able to query data in the Sales schema, you can grant the SELECT permission to that user on the schema. The user would then be able to query each table and view within the schema.
In most cases, you’ll take some or all of the following steps to provide users with the access they need to SQL Server resources:
- At the server level, create a login for each user that should be able to log into SQL Server. You can create Windows authentication logins that are associated with Windows user or group accounts, or you can create SQL Server authentication logins that are specific to that instance of SQL Server.
- Create user-defined server roles if the fixed server roles do not meet your configuration requirements.
- Assign logins to the appropriate server roles (either fixed or user-defined).
- For each applicable server-level securable, grant or deny permissions to the logins and server roles.
- At the database level, create a database user for each login. A database user can be associated with only one server login. You can also create database users that are not associated with logins, in which case, you can skip the first four steps.
- Create user-defined database roles if the fixed database roles do not meet your configuration requirements.
- Assign users to the appropriate database roles (either fixed or user-defined).
- For each applicable database-level or schema-level securable, grant or deny permissions to the database users and roles.
You will not necessarily have to carry out all these steps, depending on your particular circumstances. For example, you might not need to create any user-defined roles at the server or database levels. In addition, you do not need to follow these steps in the exact order. You might grant permissions to server logins or database users when you create them, or you might create server roles and database roles before creating the logins or users. The steps listed here are meant only as a guideline.
The examples in the following sections walk you through the process of creating principals and assigning permissions to them for specific securables. All the examples use T-SQL to carry out these operations. You can also use features built into the SQL Server Management Studio (SSMS) interface to perform many of these tasks, but knowing the T-SQL can make it easier to repeat steps and add them to your scripts.
Creating Server Logins
SQL Server supports four types of logins: Windows, SQL Server, certificate-mapped, and asymmetric key-mapped. For this article, I focus on Windows and SQL Server logins, using the CREATE LOGIN statement to define several logins. Because logins exist at the server level, you must create them within the context of the master database.
A Windows login is associated with a local Windows account or domain account. When you create the login, you must specify the Windows account, preceded by the computer name or domain name and a backslash. For example, the following CREATE LOGIN statement defines a login based on the winuser01 local user account on the win10b computer:
USE master;
GO
CREATE LOGIN [win10b\winuser01] FROM WINDOWS
WITH DEFAULT_DATABASE = master, DEFAULT_LANGUAGE = us_english;
GO
The statement must include the FROM WINDOWS clause to indicate that this is a Windows login. In this case, the statement also includes an optional WITH clause, which specifies a default database and language.
If you’re creating a login based on a domain account, replace the computer name with the domain name, following the same format:
[<domain_name>\<windows_account>]
You should also use this format if creating a login based on a Windows group. For example, the following CREATE LOGIN statement creates a login based on wingroup01, a group defined on the local Windows computer:
CREATE LOGIN [win10b\wingroup01] FROM WINDOWS
WITH DEFAULT_DATABASE = master, DEFAULT_LANGUAGE = us_english;
GO
By creating a login based on a group, you can provide the same level of access to any user within that group, while letting Windows and SQL Server handle authenticating and authorizing the individual users.
You can also use the CREATE LOGIN statement to define a SQL Server login (one that is not associated with a Windows account), in which case, do not include the FROM WINDOWS clause. However, you must include a WITH clause that specifies a password, as shown in the following example:
CREATE LOGIN sqluser01
WITH PASSWORD = 'tempPW@56789'
MUST_CHANGE, CHECK_EXPIRATION = ON,
DEFAULT_DATABASE = master, DEFAULT_LANGUAGE = us_english;
GO
For the password, you can provide a string value, as I’ve done here, or a hashed value, along with the HASH keyword. You can also define additional options. In this case, the WITH clause includes the MUST_CHANGE option to force the user to change the password when first logging into SQL Server. The clause also sets the CHECK_EXPIRATION option to ON, which means that the password expiration policy will be enforced on this login.
Once you’ve created a login, you can use the GRANT statement to grant permissions to that login. For example, the following statement grants the IMPERSONATE ANY LOGIN permission to the winuser01 and sqluser01 users, allowing them to run T-SQL statements within the context of another user:
GRANT IMPERSONATE ANY LOGIN TO [win10b\winuser01], sqluser01;
GO
After you’ve granted permissions to a principal, you can use the sys.server_principals and sys.server_permissions catalog views to verify that the permissions have been configured correctly:
SELECT pr.principal_id, pr.name, pe.state_desc, pe.permission_name
FROM sys.server_principals pr INNER JOIN sys.server_permissions pe
ON pr.principal_id = pe.grantee_principal_id
WHERE pr.principal_id = SUSER_ID('win10b\winuser01')
OR pr.principal_id = SUSER_ID('sqluser01');
The SELECT statement joins the two catalog views and filters the results by the two logins, using the SUSER_ID built-in function to retrieve each login’s principal identification number. Figure 1 shows the data returned by the SELECT statement.
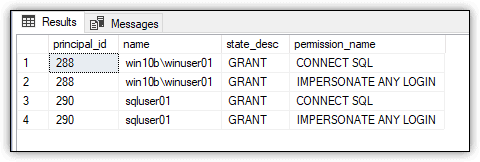
Figure 1. Viewing permissions assigned to SQL Server principals
The results show that both users have been assigned the IMPERSONATE ANY LOGIN permission, along with the CONNECT SQL permission, which is assigned by default to all logins to enable them to connect to the SQL Server instance.
Creating Server Roles
A server role makes it possible for you to group logins together in order to more easily manage server-level permissions. SQL Server supports fixed server roles and user-defined server roles. You can assign logins to a fixed server role, but you cannot change its permissions. You can do both with a user-defined server role.
Creating and configuring a user-defined server role is very straightforward. You create the role, grant permissions to the role, and then add logins—or you can add the logins and then grant the permissions. The following T-SQL takes the first approach:
CREATE SERVER ROLE devops;
GRANT ALTER ANY DATABASE TO devops;
ALTER SERVER ROLE devops ADD MEMBER [win10b\winuser01];
GO
The CREATE SERVER ROLE statement defines a server role named devops. If you want to specify an owner for the server role, you can include an AUTHORIZATION clause. Without the clause, the login that executes that statement becomes the owner.
The GRANT statement grants the ALTER ANY DATABASE permission to the devops role, which means that any members of that role will acquire that permission. The ALTER SERVER ROLE statement adds the winuser01 login to the devops role.
That’s all there is to it. You can then use the sys.server_principals and sys.server_permissions catalog views to verify that the permissions on the devops role have been set up correctly:
SELECT pe.state_desc, pe.permission_name
FROM sys.server_principals pr INNER JOIN sys.server_permissions pe
ON pr.principal_id = pe.grantee_principal_id
WHERE pr.principal_id = SUSER_ID('devops');
The statement’s results should confirm that that devops role has been granted the ALTER ANY DATABASE permission.
You can also confirm that the winuser01 login has been added to the devops role by using the sys.server_role_members and sys.server_principals catalog views:
SELECT rm.member_principal_id, pr.name
FROM sys.server_role_members rm INNER JOIN sys.server_principals pr
ON rm.member_principal_id = pr.principal_id
WHERE rm.role_principal_id = SUSER_ID('devops');
The results from the SELECT statement should indicate that the winuser01 login has been added to the devops role and that no other logins are included. Of course, in a real-world scenario, you would be adding multiple logins to a user-defined server role. Otherwise, there would be little reason to create it.
Creating Database Users
After you’ve set up your server-level logins, you can create database users that map back to those logins, whether they’re Windows or SQL Server logins. You can also create database users that do not map to logins. These types of logins are generally used for contained databases, impersonation, or development and testing.
SQL Server provides the CREATE USER statement for creating database users. You must run this statement within the context of the database in which the user is being defined. For example, the following T-SQL creates a user in the WideWorldImporters database and then assigns the ALTER permission to the user on the Sales schema:
USE WideWorldImporters;
GO
CREATE USER [win10b\winuser01];
GRANT ALTER ON SCHEMA::Sales TO [win10b\winuser01];
GO
The winuser01 user is based on the win10b\winuser01 login. When you create a database user that has the same name as a login, you do not need to specify the login. However, if you want to create a user with a different name, you must include the FOR LOGIN or FROM LOGIN clause, as in the following example:
CREATE USER winuser03 FOR LOGIN [win10b\winuser01];
GRANT ALTER ON SCHEMA::Sales TO winuser03;
GO
You can create only one user in a database per login. If you want to try out both these statements, you’ll need to drop the first user before creating the second. The examples that follow are based on the win10b\winuser01 user.
The two preceding examples also include a GRANT statement that assigns the ALTER permission to the user on the Sales schema. As a result, the user will be able to alter any object within that schema. Notice that the statement includes the SCHEMA::Sales element. When you grant a permission on a specific object, you must specify the type of object and its name, separated by the scope qualifier (double colons).
In some GRANT statements, the securable is implied, so it does not need to be specified. For instance, in an earlier example, you granted the ALTER ANY DATABASE permission to the devops role. Because you granted this permission at the server level for all database objects at that level, you did not need to specify a securable.
After you’ve granted permissions to a database user, you can use the sys.database_principals and sys.database_permissions catalog views to verify that the permissions have been configured correctly:
SELECT pe.state_desc, pe.permission_name
FROM sys.database_principals pr INNER JOIN sys.database_permissions pe
ON pr.principal_id = pe.grantee_principal_id
WHERE pr.principal_id = USER_ID('win10b\winuser01');
Notice that the WHERE clause uses the USER_ID function and not the SUSER_ID function, which was used in the earlier examples. The USER_ID function returns the user principal ID, rather than the login principal ID. Figure 2 shows the results returned by the SELECT statement. In addition to the ALTER permission, the user is automatically granted the CONNECT permission:
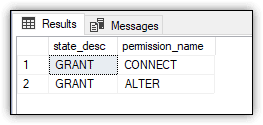
Figure 2. Viewing permissions assigned to winuser01
Creating a database user that’s associated with a SQL Server login is just as simple as creating a user based on a Windows login, especially when you use the same name, as in the following example:
CREATE USER sqluser01;
GO
The CREATE USER statement creates the sqluser01 user, but this time, the example grants no permissions. As a result, the user receives only the CONNECT permission, which you can verify by running the following SELECT statement:
SELECT pe.state_desc, pe.permission_name
FROM sys.database_principals pr INNER JOIN sys.database_permissions pe
ON pr.principal_id = pe.grantee_principal_id
WHERE pr.principal_id = USER_ID('sqluser01');
You can also create a user based on a Windows account even if you don’t create a login. For example, the following statement creates the winuser02 user that’s associated with the win10b\winuser02 account on the local computer:
CREATE USER [win10b\winuser02];
GO
Creating a user in this way makes it possible to support contained databases, which do not use server logins. Once again, you can verify that the user has been granted only the CONNECT permission by running the following SELECT statement:
SELECT pe.state_desc, pe.permission_name
FROM sys.database_principals pr INNER JOIN sys.database_permissions pe
ON pr.principal_id = pe.grantee_principal_id
WHERE pr.principal_id = USER_ID('win10b\winuser02');
SQL Server also lets you create a user that is not associated with either a login or Windows account. To do so, you must include the WITHOUT LOGIN clause, as shown in the following example.
CREATE USER sqluser02 WITHOUT LOGIN;
GO
Creating a user without a login can be useful for development and testing. More importantly, it can be used with SQL Server’s impersonation capabilities. Users can authenticate to SQL Server under their own credentials and then impersonate the user account that’s not associated with a login. In this way, the authentication process can be monitored, but specific types of permissions can be granted to the unassociated user.
Creating Database Roles
A database role is a group of users that share a common set of database-level permissions. As with server roles, SQL Server supports both fixed and user-defined database roles. To set up a user-defined database role, you must create the role, grant permissions to the role, and add members to the role (or add members and then grant permissions). The following example demonstrates how to set up the dbdev role:
CREATE ROLE dbdev;
GRANT SELECT ON DATABASE::WideWorldImporters TO dbdev;
ALTER ROLE dbdev ADD MEMBER [win10b\winuser01];
ALTER ROLE dbdev ADD MEMBER sqluser01;
GO
The CREATE ROLE statement creates the database role. The GRANT statement grants the role the SELECT permission on the database. The two ALTER ROLE statements add the winuser01 and sqluser01 users to the role.
You can verify that the SELECT permission has been granted to the role by running the following SELECT statement:
SELECT pe.state_desc, pe.permission_name
FROM sys.database_principals pr INNER JOIN sys.database_permissions pe
ON pr.principal_id = pe.grantee_principal_id
WHERE pr.principal_id = USER_ID('dbdev');
In some cases, you might want to see the effective (cumulative) permissions granted to a principal on a securable. A simple way to do this is to use the fn_my_permissions table-valued function, specifying the securable and its type.
The trick to using this function is to call it within the execution context of the specific user. To do so, you must first issue an EXECUTE AS statement and then, after running your SELECT statement, issue a REVERT statement, as shown in the following example:
EXECUTE AS USER = 'win10b\winuser01';
SELECT * FROM fn_my_permissions ('Sales.BuyingGroups', 'OBJECT');
REVERT;
GO
The fn_my_permissions function takes two arguments: the target securable and the type of securable. In this case, the target securable is the Sales.BuyingGroups table, and the securable type is OBJECT, which includes schema-level securables such as tables, views, and stored procedures. Figure 3 shows the results returned by the SELECT statement.
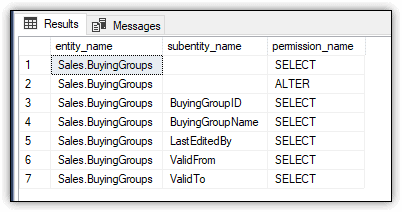
Figure 3. Viewing effective permissions for winuser01
As you’ll recall from the previous section, the ALTER permission was granted to winuser01 after the user was created, and the SELECT permission was granted to the role after it was created. Notice that each of the table’s columns is also assigned the SELECT permission.
Now run the same SELECT statement within the execution context of the sqluser01 user:
EXECUTE AS USER = 'sqluser01';
SELECT * FROM fn_my_permissions ('Sales.BuyingGroups', 'OBJECT');
REVERT;
GO
The SELECT statement returns the results shown in Figure 4, which are specific to the user specified in the EXECUTE AS statement.
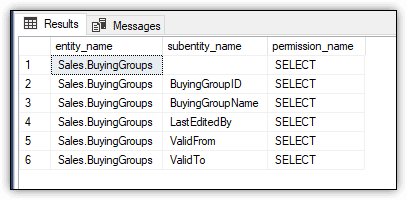
Figure 4. Viewing effective permissions for sqluser01
This time, the ALTER permission is not included in the results because that permission was never granted to that user.
Digging into Permissions
Several of the examples so far have used the GRANT statement to assign permissions to principals, but SQL Server actually provides three T-SQL statements for working with permissions:
- Use a
GRANT statement to enable principals to access specific securables.
- Use a
DENY statement to prevent principals from accessing specific securables. A DENY statement overrides any granted permissions.
- Use a
REVOKE statement to remove permissions that have been granted to principals on specific securables.
Permissions are cumulative in that the user receives all permissions granted specifically to the database user as well as to its associated login. Also, if the user has been assigned to a database role or if the login has been assigned to a server role, the user receives the role permissions as well.
Permissions are also transitive, based on the hierarchical nature of the server, database, and schema securables. For example, if you grant the UPDATE permission to a user for a specific database, the user will also be granted the UPDATE permission on all schemas and schema objects such as tables and views.
In addition, some permissions are covering, that is, they include multiple permissions under a single name. A good example of this is the CONTROL permission, which includes such permissions as INSERT, UPDATE, DELETE, EXECUTE, and several others. For instance, the following GRANT statement grants the CONTROL permission to sqluser01 for the Sales schema:
GRANT CONTROL ON SCHEMA::Sales TO sqluser01;
After granting the CONTROL permission, you can again use the fn_my_permissions function to view the effective permissions for that user on the Sales schema:
EXECUTE AS USER = 'sqluser01';
SELECT * FROM fn_my_permissions ('Sales', 'SCHEMA');
REVERT;
GO
Figure 5 shows the results returned by the SELECT statement.
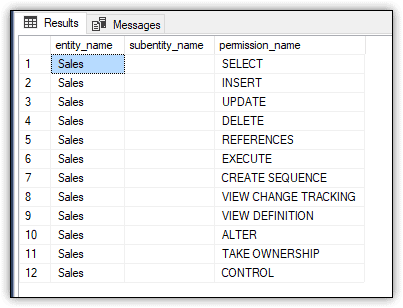
Figure 5. Viewing effective permissions on the Sales schema
The SELECT permission was granted to the user at the database level through the dbdev role and at the schema level as part of the CONTROL permission, as are the rest of the permissions shown in the results. You can also view the effective permissions on an object within the Sales schema by using the following SELECT statement:
EXECUTE AS USER = 'sqluser01';
SELECT * FROM fn_my_permissions ('Sales.BuyingGroups', 'OBJECT');
REVERT;
GO
In this case, the fn_my_permissions function specifies the BuyingGroups table as the target object. As a result, the SELECT statement now returns 25 rows of permissions on that table for sqluser01. Figure 6 shows the first 13 rows from that result set.
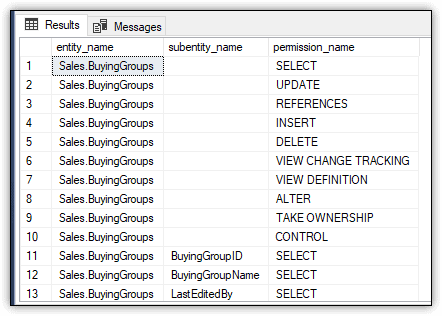
Figure 6. Viewing effective permissions on the BuyingGroups table
As you can see, covering permissions help simplify the process of granting access to the database objects. Without them, your GRANT statements would look more like the following:
GRANT SELECT, INSERT, UPDATE, DELETE, REFERENCES,
EXECUTE, CREATE SEQUENCE, VIEW CHANGE TRACKING,
VIEW DEFINITION, ALTER, TAKE OWNERSHIP, CONTROL
ON SCHEMA::Sales TO sqluser01;
You can also deny permissions on securables. This can be useful when you want to grant permissions at a higher level in the object hierarchy but want to prevent those permissions from extending to a few of the child objects. For example, you can deny the CONTROL permission to sqluser01 on an individual table within the Sales schema, as shown in the following example:
DENY CONTROL ON OBJECT::Sales.BuyingGroups TO sqluser01;
When you deny the CONTROL permission, you deny all permissions that are part of CONTROL, including the SELECT permission. You can verify this by running the following SELECT statement:
EXECUTE AS USER = 'sqluser01';
SELECT * FROM fn_my_permissions ('Sales.BuyingGroups', 'OBJECT');
REVERT;
GO
The SELECT statement returns an empty result set, indicating that sqluser01 no longer has any type of permissions on the BuyingGroups table.
The DENY permission takes precedence over all granted permissions, no matter where in the object hierarchy permissions are granted or denied. However, denying permissions on one object does not impact other objects unless they’re child objects. For example, the following SELECT statement shows that all permissions are still intact on the CustomerCategories table in the Sales schema:
EXECUTE AS USER = 'sqluser01';
SELECT * FROM fn_my_permissions ('Sales.CustomerCategories', 'OBJECT');
REVERT;
GO
However, if you deny permissions on an object that contains child objects, the permissions are also denied on the child objects. For instance, the following DENY statement denies sqluser01 the ALTER permission on the Sales schema:
DENY ALTER ON SCHEMA::Sales TO sqluser01;
If you now run the following SELECT statement, you’ll find that the ALTER permission is no longer granted at the Sales schema:
EXECUTE AS USER = 'sqluser01';
SELECT * FROM fn_my_permissions ('Sales', 'SCHEMA');
REVERT;
GO
You’ll get the same results if you check the effective permissions on one of the objects in the Sales schema, such as the CustomerCategories table:
EXECUTE AS USER = 'sqluser01';
SELECT * FROM fn_my_permissions ('Sales.CustomerCategories', 'OBJECT');
REVERT;
GO
Once again, the ALTER permission is no longer listed.
In some cases, you will need to roll back the permissions that have been granted on an executable, in which case, you can use the REVOKE statement. For example, the following REVOKE statement removes the CONTROL permission from the Sales schema for sqluser01:
REVOKE CONTROL ON SCHEMA::Sales TO sqluser01;
After revoking the CONTROL permission, you can once again use the fn_my_permissions function to view the effective permissions for that user on the Sales schema:
EXECUTE AS USER = 'sqluser01';
SELECT * FROM fn_my_permissions ('Sales', 'SCHEMA');
REVERT;
GO
This time, only the SELECT permission is listed. That’s because this permission was granted separately at the database level as part of the dbdev role. You can also verify the effective permissions on the CustomerCategories table:
EXECUTE AS USER = 'sqluser01';
SELECT * FROM fn_my_permissions ('Sales.CustomerCategories', 'OBJECT');
REVERT;
GO
Once again, the results indicate that only the SELECT permission has been granted on this table, as shown in Figure 7.
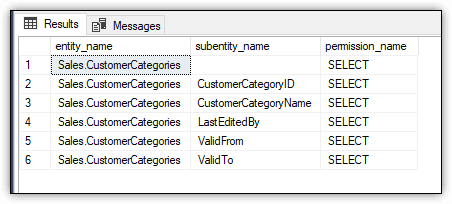
Figure 7. Viewing effective permissions on the CustomerCategories table
When working with permissions, be careful not to confuse the DENY statement with the REVOKE statement. You could end up unintended consequences when users receive permissions from multiple sources, as in the examples above. For example, if you had denied sqluser01 the CONTROL permission to the Sales schema, rather than revoke the permission, the user would no longer have SELECT permissions to the schema and its objects.
Controlling Access to SQL Server Data
Controlling access to SQL Server becomes an increasingly complex process as more users are added and the data structure itself becomes more complicated. Your goal should be to limit users to the least amount of privileges they need to do their jobs. Don’t grant the CONTROL permission on the database when they need only the SELECT permission on a couple of tables. At the same time, don’t make more work for yourself than necessary. If a user needs the SELECT permission on all tables in a schema, grant the permission at the schema level.
SQL Server provides the ability to grant users the access they need at the level they need it. The GRANT, DENY, and REVOKE statements—along with the wide assortments of permissions (230 in SQL Server 2016 and 237 in SQL Server 2017)—make it possible to implement controls at a very granular level, while still providing the flexibility necessary to accommodate access at a higher level in the object hierarchy. However, controlling access takes careful planning and implementation. This is not the time for shortcuts or casual one-offs. The more diligently you control data access, the better for everyone and the more precise the control you have over the data.
The post Introduction to SQL Server Security — Part 2 appeared first on Simple Talk.
from Simple Talk http://bit.ly/2HCdUYp
via