The series so far:
- Introduction to SQL Server Security — Part 1
- Introduction to SQL Server Security — Part 2
Microsoft introduced contained databases in SQL Server 2012. A contained database is one that is isolated from other databases and from the SQL Server instance that hosts the database. The database maintains much of its own metadata and supports database-level authentication, eliminating the need for server-based logins. As a result, a contained database is more portable than a traditional, non-contained database. It can also simplify database development and administration, as well as make it easier to support Always On Availability Groups.
Controlling access to a contained database is similar to a non-contained database, except for a few important differences. In the first two articles in this series, I touched briefly upon the topic of contained databases when discussing SQL Server access control. In this article, I dig deeper into contained databases and offer several examples that show how to create contained database users, duplicate users across multiple contained databases, and unlink database users from their server-level logins.
Setting Up Your Environments
To try out the examples in this article, you need a test environment that includes a contained database. On my system, I used SQL Server Management Studio (SSMS) to create a simple database and populate it with data from the WideWorldImporters database, although you can use any data that fits your needs.
Before you can implement a contained database, you must enable the SQL Server instance to support this feature, if it’s not already enabled. To use T-SQL to enable contained databases, run the following EXECUTE statement:
EXEC sp_configure 'contained database authentication', 1;
GO
RECONFIGURE;
GO
The EXECUTE statement calls the sp_configure stored procedure to set the contained database authentication setting to 1 (on). You should then run the RECONFIGURE statement to implement the changes.
For the examples in this article, create the ImportSales1 contained database, using the following T-SQL script:
USE master;
GO
DROP DATABASE IF EXISTS ImportSales1;
GO
CREATE DATABASE ImportSales1
CONTAINMENT = PARTIAL;
GO
When you create a database, you can specify that it should be contained by including the CONTAINMENT clause in the CREATE DATABASE statement and set its value to PARTIAL. The default value is NONE, which disables the contained database feature. The PARTIAL value is used because SQL Server supports only partially contained databases, as opposed to fully contained databases. Currently, SQL Server does not support fully contained databases.
A partially contained database allows you to implement uncontained features that cross the database boundary. For example, you can create a database user that is linked to a SQL Server login in a partially contained database. Fully contained databases do not allow the use of uncontained features.
After you create the ImportSales1 database, you can add tables and then populate them, just like you can with a non-contained database. To support the examples in the rest of the article, use the following T-SQL script:
USE ImportSales1;
GO
CREATE SCHEMA Sales;
GO
CREATE TABLE Sales.Customers(
CustID INT NOT NULL PRIMARY KEY,
Customer NVARCHAR(100) NOT NULL,
Contact NVARCHAR(50) NOT NULL,
Category NVARCHAR(50) NOT NULL);
GO
INSERT INTO Sales.Customers(CustID, Customer, Contact, Category)
SELECT CustomerID, CustomerName,
PrimaryContact, CustomerCategoryName
FROM WideWorldImporters.Website.Customers
WHERE BuyingGroupName IS NOT NULL;
GO
The script creates the Sales schema, adds the Customers table to the schema, and then populates the table with data from the WideWorldImporters database. The SELECT statement’s WHERE clause limits the results to those rows with a BuyingGroupName value that is NOT NULL (402 rows on my system). If you create a different structure or use different data, be sure to modify the remaining examples as necessary.
Creating Database Users
In SQL Server, you can create users that are specific to a contained database and not linked to server-level logins. Contained users make it possible to maintain the separation between the contained database and the SQL Server instance, so it’s easier to move the database between instances.
SQL Server supports two types of contained users: SQL user with password and Windows user. The password-based user is a database user that is assigned a password for authenticating directly to the database. The user is not associated with any Windows accounts.
To create a password-based user, you must include a WITH PASSWORD clause in your CREATE USER statement. For example, the following CREATE USER statement defines a user named sqluser02 and assigns the password tempPW@56789 to the user:
USE ImportSales1;
GO
CREATE USER sqluser02
WITH PASSWORD = 'tempPW@56789';
GO
When a password-based user tries to access a contained database, the user account is authenticated at the database level, rather than the server level. In addition, all authorization granted through assigned permissions is limited to the database.
The second type of contained database user—Windows user—is based on a Windows account, either local or domain. The Windows computer or Active Directory service authenticates the user and passes an access token onto the database. As with password-based users, authorization also occurs within the database according to how permissions have been granted or denied.
When you create a Windows user, be sure that the Windows account is not already associated with a login. If you try to create a Windows user with the same name as a login, SQL Server will automatically associate that user with the login, which means that the user will not be contained.
In the following example, the CREATE USER statement defines a user based on the winuser02 local account, which I created on the win10b computer:
CREATE USER [win10b\winuser02];
GO
Whenever referencing a Windows account in this way, you must use the following format, including the brackets (unless enclosing the account in quotes):
[<domain_or_computer>\<windows_account>]
After you’ve created your contained users, you can grant, deny, or revoke permissions just like you can with any database users. For example, the following GRANT statement grants the SELECT permission on the Sales schema to both users:
GRANT SELECT ON SCHEMA::Sales TO sqluser02, [win10b\winuser02];
GO
You can also add contained users to fixed and user-defined database roles, and assign permissions to the user-defined roles. For more information about creating database users and granting them permissions, refer back to the second article in this series.
Creating Duplicate Database Users
When working with contained databases, you might find that some users need to be able to access multiple databases. For password-based users (SQL user with password), you should create the same user in each database, assigning the same password and security identifier (SID) to each user instance.
One way to get the SID is to retrieve it from the sys.database_principals system view after creating the first user, as shown in the following example:
USE ImportSales1;
GO
SELECT SID FROM sys.database_principals WHERE name = 'sqluser02';
The SELECT statement returns the SID value for the sqluser02 user in the ImportSales1 database. The returned value will be unique to that user and will be in a form similar to the following:
0x0105000000000009030000008F5AC110DFB07044AFDADA6962B63B03
You should use this value whenever you duplicate the user in other contained databases. To see how this works, you can create a database similar to the ImportSales1 database but instead name it ImportSales2, as in the following example:
USE master;
GO
DROP DATABASE IF EXISTS ImportSales2;
GO
CREATE DATABASE ImportSales2
CONTAINMENT = PARTIAL;
GO
USE ImportSales2;
GO
CREATE SCHEMA Sales;
GO
CREATE TABLE Sales.Customers(
CustID INT NOT NULL PRIMARY KEY,
Customer NVARCHAR(100) NOT NULL,
Contact NVARCHAR(50) NOT NULL,
Category NVARCHAR(50) NOT NULL);
GO
INSERT INTO Sales.Customers(CustID, Customer, Contact, Category)
SELECT CustomerID, CustomerName,
PrimaryContact, CustomerCategoryName
FROM WideWorldImporters.Website.Customers
WHERE BuyingGroupName IS NULL;
GO
The script creates the ImportSales2 database, adds the Sales schema to the database, adds the Customers table to the schema, and populates the table with 261 rows of data from the WideWorldImporters database. In this case, the WHERE clause filters for NULL values, rather than NOT NULL.
Next, create the sqluser02 user in the ImportSales2 database, only this time, include an SID clause that specifies the user’s SID from the ImportSales1 database, as shown in the following example:
USE ImportSales2;
GO
CREATE USER sqluser02
WITH PASSWORD = 'tempPW@56789',
SID = 0x0105000000000009030000008F5AC110DFB07044AFDADA6962B63B03;
GO
To create a duplicate Windows-based user, use the same CREATE USER statement you used in the ImportSales1 database:
CREATE USER [win10b\winuser02];
GO
You can also use the same GRANT statement to assign the SELECT permission to the Sales schema for both users:
GRANT SELECT ON SCHEMA::Sales TO sqluser02, [win10b\winuser02];
GO
That’s all there is to creating duplicate password-based and Windows-based users. You can use the same format for creating duplicate users in additional contained databases, depending on your data access requirements.
Running T-SQL Queries
To test the users you created in the contained databases, you can use an EXECUTE AS statement in SSMS to run queries within the execution context of a specific contained user. For example, the following T-SQL sets the execution context to the sqluser02 user, runs a SELECT statement against the Customers table, and then uses the REVERT statement to return to the original execution context:
EXECUTE AS USER = 'sqluser02';
SELECT * FROM Sales.Customers
REVERT;
GO
On my system, the SELECT statement returns 261 rows because the statement ran within the context of the last specified database, ImportSales2. However, the sqluser02 user exists in both databases, sharing the same name, password, and SID, so you should be able to query the Customers table in both databases, as in the following example:
EXECUTE AS USER = 'sqluser02';
SELECT * FROM ImportSales1.Sales.Customers
UNION ALL
SELECT * FROM ImportSales2.Sales.Customers;
REVERT;
GO
Unfortunately, if you try to run the statement, you’ll receive an error similar to the following:
The server principal "S-1-9-3-281107087-1148235999-1775950511-54244962"
is not able to access the database "ImportSales1" under
the current security context.
The problem is not with how you’ve set up the user accounts or query, but rather with how the TRUSTWORTHY database property is configured. The property determines whether the SQL Server instance trusts the database and the contents within it. Although this might seem to have little to do with contained databases, the TRUSTWORTHY property must be set to ON for the ImportSales2 database because you’re running the query within the context of that database but trying to access data in the ImportSales1 database.
By default, the TRUSTWORTHY property is set to OFF to reduce certain types of threats. You can find more information about the property in the SQL Server help topic TRUSTWORTHY Database Property.
Before setting the property, you must be sure you’re working in the correct execution context. If you’ve been following along with the examples, your session might still be operating within the context of the sqluser02 user. This is because the UNION ALL query in the last example failed, which means that the REVERT statement never ran. As a result, your current SQL Server session is still be running within the execution context of the sqluser02 user. To correct this situation, simply rerun the REVERT statement.
At any point, you can verify the current execution context by calling the CURRENT_USER function:
SELECT CURRENT_USER;
Once you’ve established that you’re working within the context of the correct user, run the following ALTER DATABASE statement to set the TRUSTWORTHY property to ON:
ALTER DATABASE ImportSales2 SET TRUSTWORTHY ON;
GO
Now when you run the following query, it should return the 663 rows from the two tables:
EXECUTE AS USER = 'sqluser02';
SELECT * FROM ImportSales1.Sales.Customers
UNION ALL
SELECT * FROM ImportSales2.Sales.Customers;
REVERT;
GO
You should also receive the same results if you run the query under the execution context of the win10b\winuser02 user, as shown in the following example:
EXECUTE AS USER = 'win10b\winuser02';
SELECT * FROM ImportSales1.Sales.Customers
UNION ALL
SELECT * FROM ImportSales2.Sales.Customers;
REVERT;
GO
I created and ran all the above examples in SSMS. If you try them out for yourselves, you’ll also likely use SSMS or SQL Server Data Tools (SSDT). In the real world, however, most connections will be through third-party scripts, utilities, or applications. In such cases, the connection string that establishes the connection to the contained database must specify that database as the initial catalog. Otherwise the connection will fail.
Unlinking Database Users from Their Server Logins
Because SQL Server contained databases are only partially contained, they can include users mapped to server logins. The users might have existed before changing the database to a contained state, or they might have been added after the fact. In either case, the database is less portable because of its login connections.
SQL Server provides the sp_migrate_user_to_contained system stored procedure for quickly unlinking database users from their associated SQL Server logins. To see how this works, start by creating the following user in the ImportSales1 database:
USE ImportSales1;
GO
CREATE USER sqluser03 FOR LOGIN sqluser01;
GRANT SELECT ON SCHEMA::Sales TO sqluser03;
GO
The script creates the sqluser03 user based on the sqluser01 login and grants to the user the SELECT permission on the Sales schema. (If the sqluser01 login doesn’t exist on your system, you can also use a different login or refer to the second article in this series for information about creating the sqluser01 login.)
After you create the database user, you can test that it has the expected access by running the following query:
EXECUTE AS USER = 'sqluser03';
SELECT * FROM ImportSales1.Sales.Customers;
REVERT;
GO
The query should return all the rows from the Customers table in the ImportSales1 database.
If you view the user’s properties in Object Explorer in SSMS, you’ll find that the General tab shows the associated login as sqluser01 and the user type as SQL user with login, as shown in Figure 1
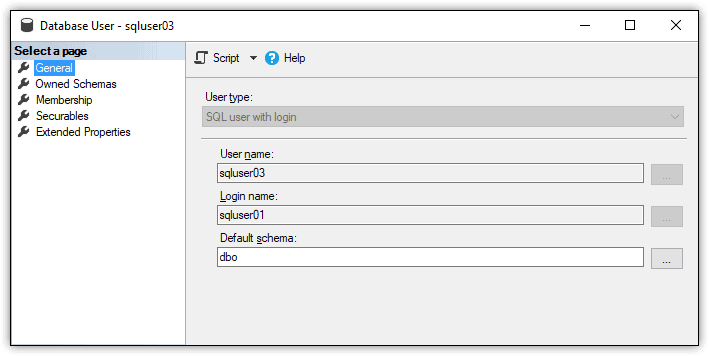
Figure 1. Database user based on a SQL Server login
To unlink this user from the SQL Server login, run the sp_migrate_user_to_contained stored procedure, specifying the database user that you want to migrate, as shown in the following example:
EXEC sp_migrate_user_to_contained
@username = N'sqluser03',
@rename = N'keep_name',
@disablelogin = N'do_not_disable_login';
The sp_migrate_user_to_contained system stored procedure takes the following three parameters:
- The
@username parameter is the database user.
- The
@rename parameter determines whether to use the database user or the server login for the name. The keep_name value retains the database user name. The copy_login_name uses the login name.
- The
@disablelogin parameter determines whether to disable the login. In this case, the login will not be disabled. To disable the login, instead, specify the disable_login value.
After you run the EXECUTE statement, reopen the properties for the sqluser03 user. You’ll find that a login is no longer associated with the user and that the user type has been changed to SQL user with password, as shown in Figure 2.
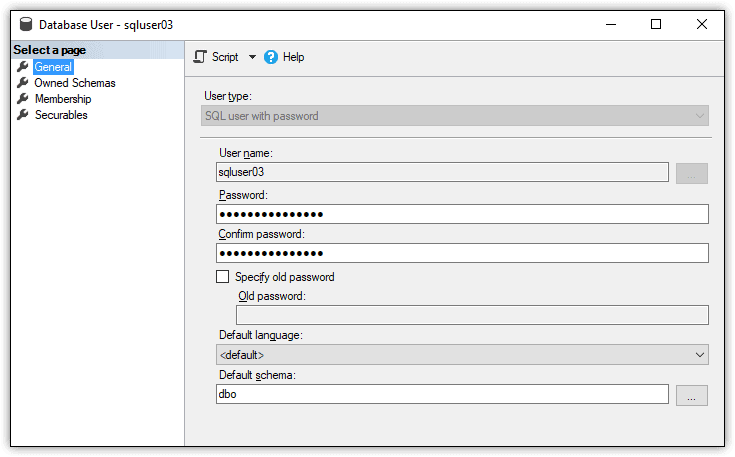
Figure 2. Password-based contained database user
When you unlink a database user from a login, SQL Server assign’s the login’s password to the user, as indicated in the figure. As a security best practice, you should reset the user’s password at this point. If you were to now rerun the following query, you should again receive the same rows from the ImportSales1 database:
EXECUTE AS USER = 'sqluser03';
SELECT * FROM ImportSales1.Sales.Customers;
REVERT;
GO
By unlinking the login from the database user, you can take full advantage of the portability inherent in contained databases. Be aware, however, that the sp_migrate_user_to_contained stored procedure works only for SQL Server logins and not Windows logins.
Securing SQL Server Contained Databases
Contained databases can make it easier to move a database from one SQL Server instance to another, without having to worry about duplicating login information between those instances. However, before implementing contained databases, you should be familiar with Microsoft’s security guidelines, described in the SQL Server help topic Security Best Practices with Contained Databases. The topic explains some of the subtler aspects of controlling access to contained databases, particularly when it comes to roles and permissions.
Aside from these guidelines, you’ll find that controlling access to a contained database works much like a non-contained database. You might need to duplicate users across multiple contained databases or unlink database users from their server logins, but these are relatively straightforward processes, much like controlling access in general. Once you understand the basics, you should have little trouble supporting more complex scenarios.
The post Introduction to SQL Server Security — Part 3 appeared first on Simple Talk.
from Simple Talk https://ift.tt/2EaIFyv
via









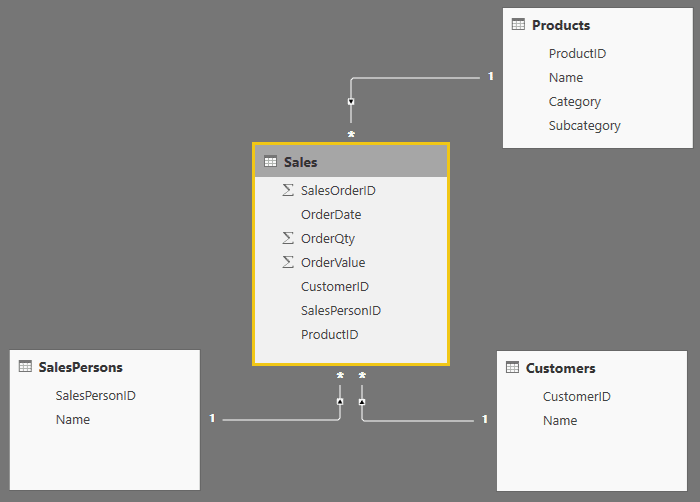 Figure 11: The sales dimensional model
Figure 11: The sales dimensional model