The series so far:
- Reporting Services Basics: Overview and Installation
- Reporting Services Basics: Creating Your First Report
In the previous article in the series, I explained a bit about the history and architecture of SSRS and helped you get a development environment set up. Now it’s time to start building your first report. The reports in this article are based on the AdventureWorks2017 database, which you should have restored if you followed along with the earlier article.
Solutions and Projects
For those of you familiar with working in Visual Studio, you will already understand the concept of solutions and projects. A solution contains one or more project, and the projects may be of all the same or different project types. For example, I was working on a business intelligence project a few years ago and had four different types of projects in my solution, one of which was an SSRS project. Figure 1 shows what my solution looked like.
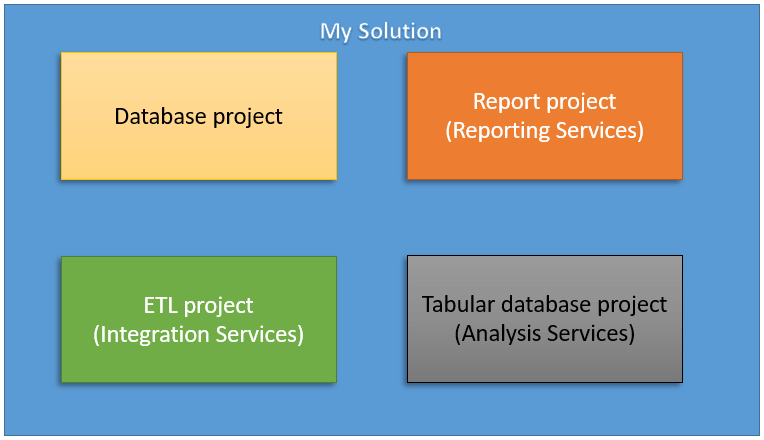
Figure 1: My BI project organization
In theory, you could have one solution and one project for all the work you do for years developing reports, but that is not very practical. Typically, you might have a project for one topic area, project, or department. It’s up to you (or your manager) how you organize you work.
There are two ways to create an SSRS project, either manually or with a wizard. I will show you the wizard method in this article, which sets up the project as you create a report.
Using the Report Wizard
The report wizard is not the best way to create a report, but it is a nice way for beginners to SSRS to get started. Generally, the reports you create through the wizard won’t meet any but the most basic development requirements, but do not discount it entirely. It will allow you to get a report up and running with zero code and zero property setting, and the resulting report often makes a good starting point for more complicated reports. Once you’ve created a report with the Report Wizard, you are free to modify it further as you wish, just as for a report you create from scratch, manually.
Your very first report project, MyFirstProject, demonstrates how to create a report with grouping levels, including one of the dynamic features, collapsing and expanding sections. The result is not perfect, but it is a good start.
To create a report project with the wizard, follow these steps:
- Search for and launch Visual Studio (SSDT). If this is the first time you have run Visual Studio, you’ll be greeted by this screen. You will be prompted to sign in to the online developer services. For now, just click Not now, maybe later.
- You can select which color theme you would like to use. Select one and click Start Visual Studio.
- When Visual Studio opens, you’ll see a screen that looks like this:
- To create the project, select File New Project…
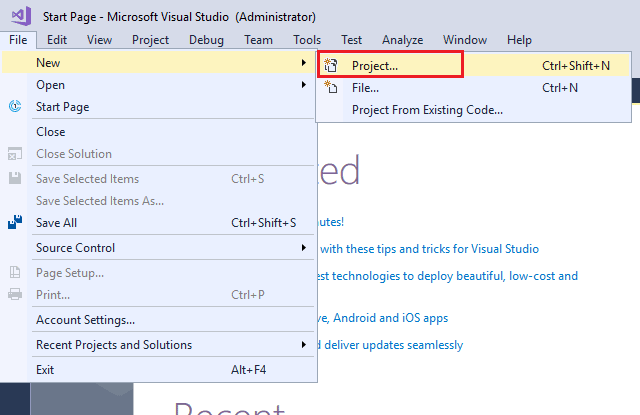
- Look for the Reporting Services templates in the Business Intelligence section and select Report Server Project Wizard. (You may have to look around; when I recently installed SSRS, Reporting Services didn’t end up in that section.)
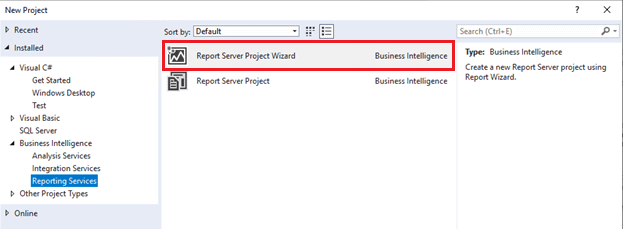
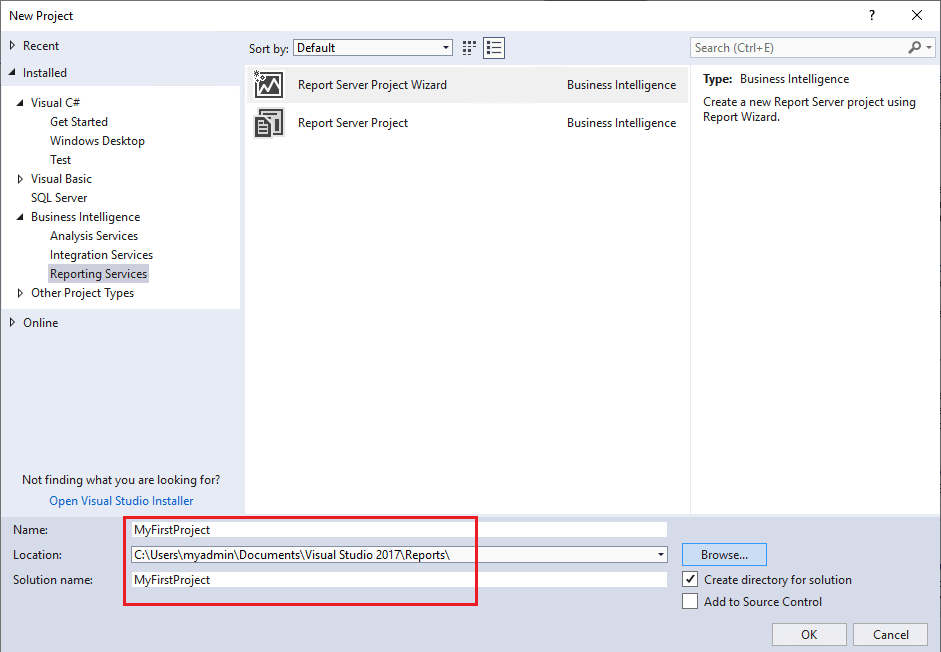
- Fill in a name for the project and location. Notice that the Solution name will automatically be the same as the project name. You can override that if you wish.
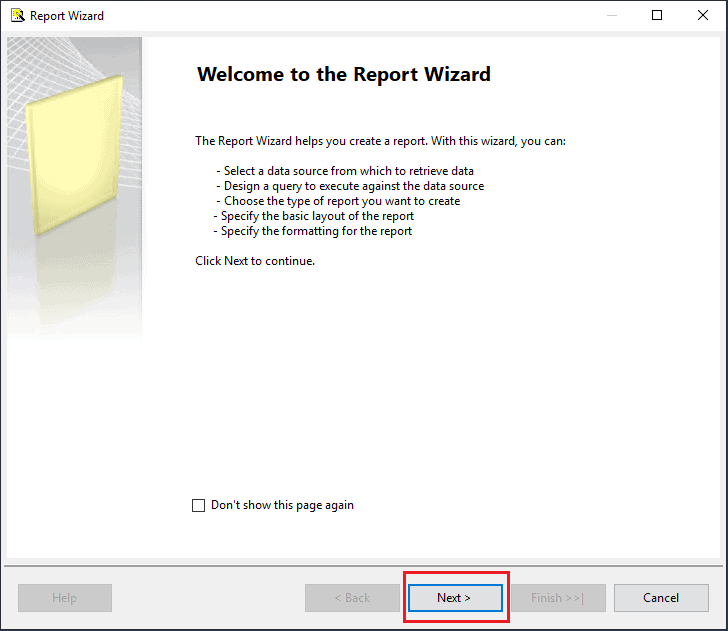
- Click OK, which will launch the wizard. Click Next on the introduction page.
- On the Select the Data Source page, you will set up a new data source. You’ll learn more about data sources and datasets in the next article in this series. Click the Edit button.
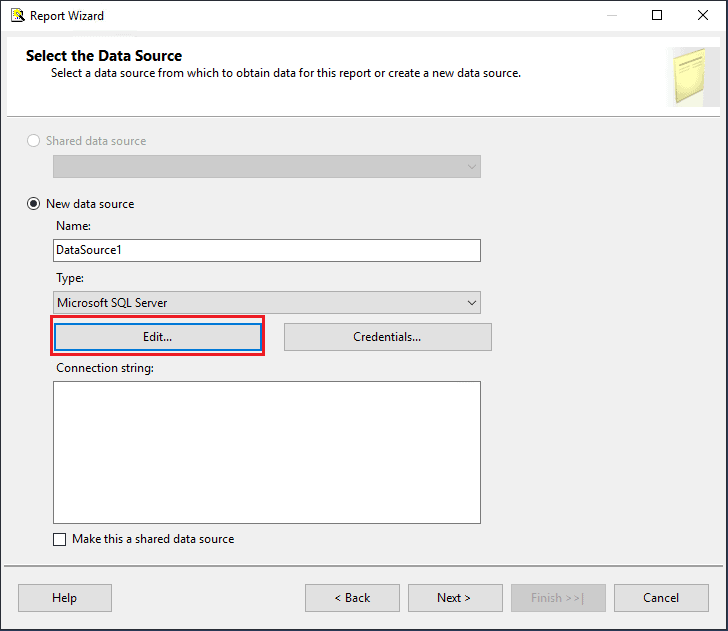
- This brings up the Connection Properties window. Enter the SQL Server name, and, if local, you can type in localhost. If you have a named instance, you will need to use this syntax: [computername]\[instancename].
- Leave the Authentication setting at Windows Authentication.
- Click the dropdown to find the AdventureWorks2017 database.
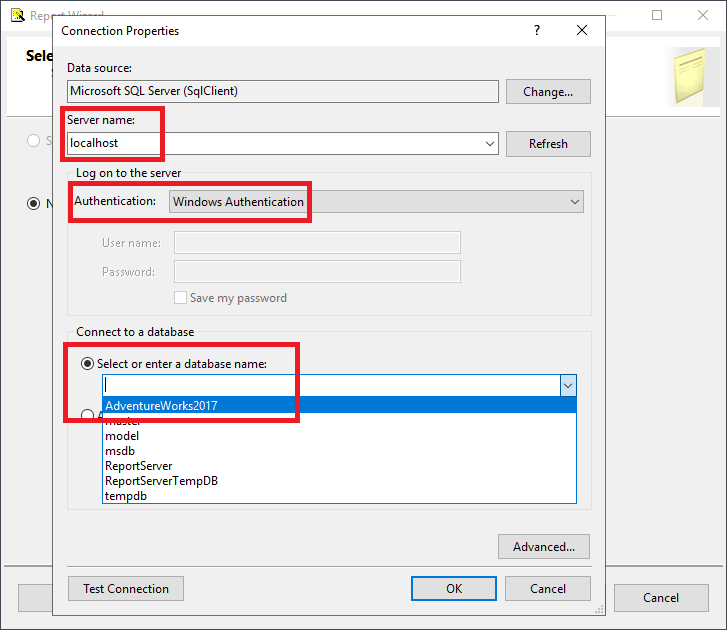
- Click OK to save the connection properties. You’ll now see the Connection string in the dialog.
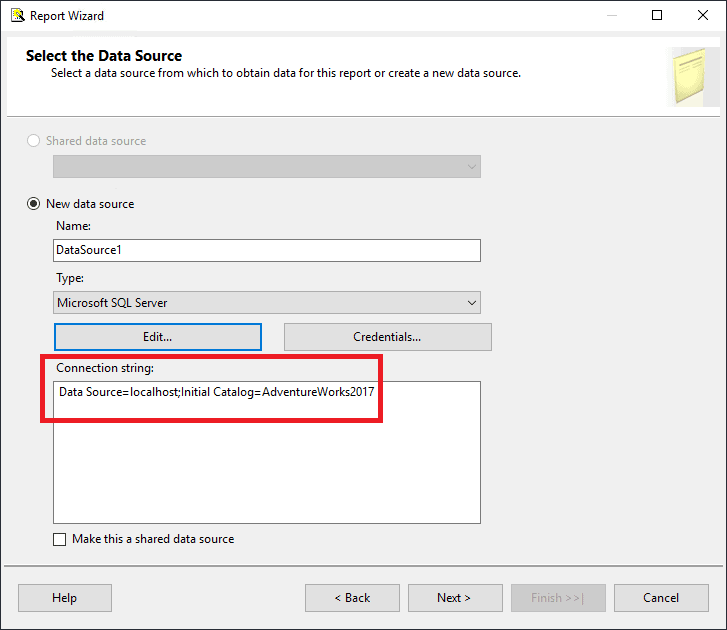
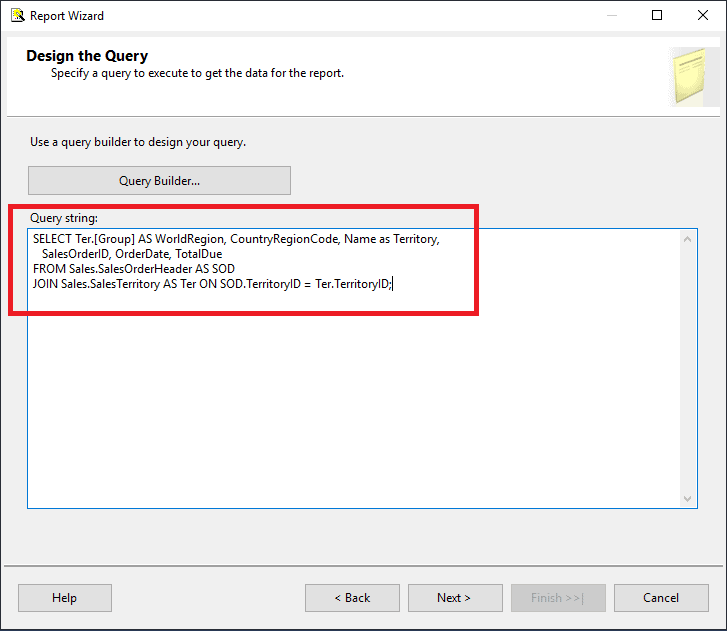
- Click Next to move to the Design the Query page. There is a Query Builder which you can use, or just write your query in SSMS to make sure it runs as expected. In this case, I’m providing a query for you. Paste this query into the Query string window:
SELECT Ter.[Group] AS WorldRegion,
CountryRegionCode,
Name as Territory,
SalesOrderID,
OrderDate,
TotalDue
FROM Sales.SalesOrderHeader AS SOD
JOIN Sales.SalesTerritory AS Ter
ON SOD.TerritoryID = Ter.TerritoryID;
- Click Next to move to the next screen where you can select either a Tabular or Matrix report. A Matrix report is like a pivot table in Excel. For now, select Tabular.
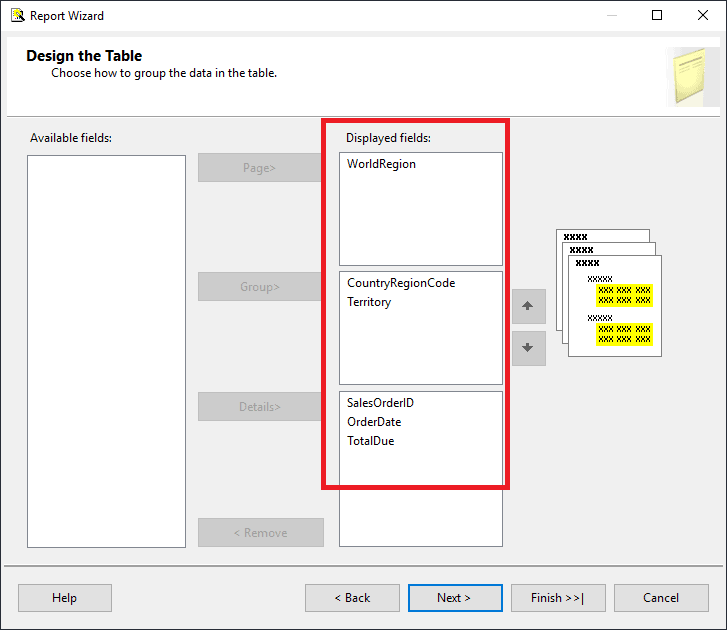
- Click Next to move to the Design the Table screen. I’ll tell you what to do here, but when you are creating a real report, you will need to figure out how the grouping levels, if any, need to be arranged before you start working on the report. Select the fields and move them to the proper areas.
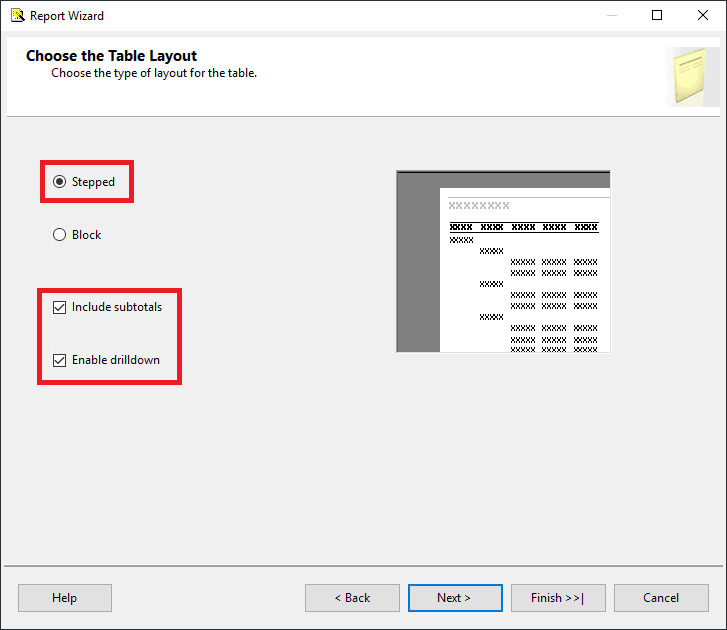
- Click Next to move to the Choose the Table Layout page. You have the choice of Stepped or Block. Click each to see how the report layout will look. For this example, choose Stepped and also select Include subtotals and Enable drilldown.
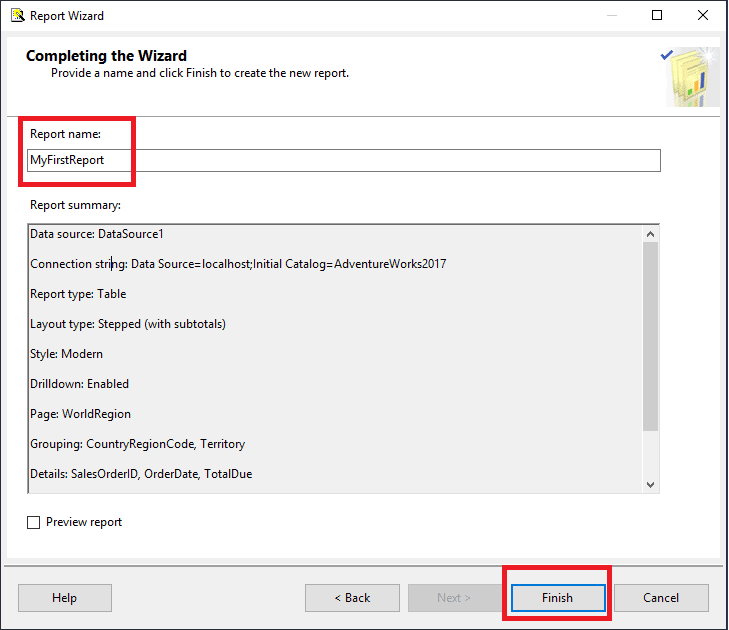
- Click Next to move to the Completing the Wizard page. Here you should add a Report name and click Finish to build the report.
Viewing the Wizard Report
Once the wizard creates the report, you’ll see the definition and the report listed in the Solution Explorer.
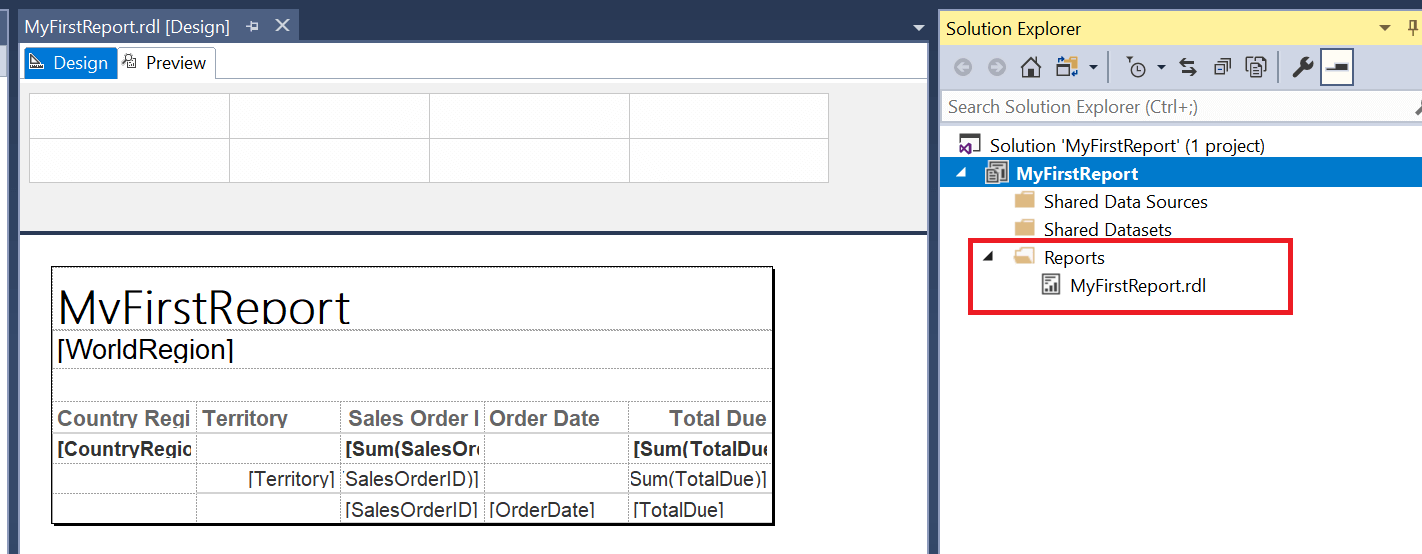
To view how the report looks when it’s run, click the Preview tab at the top.
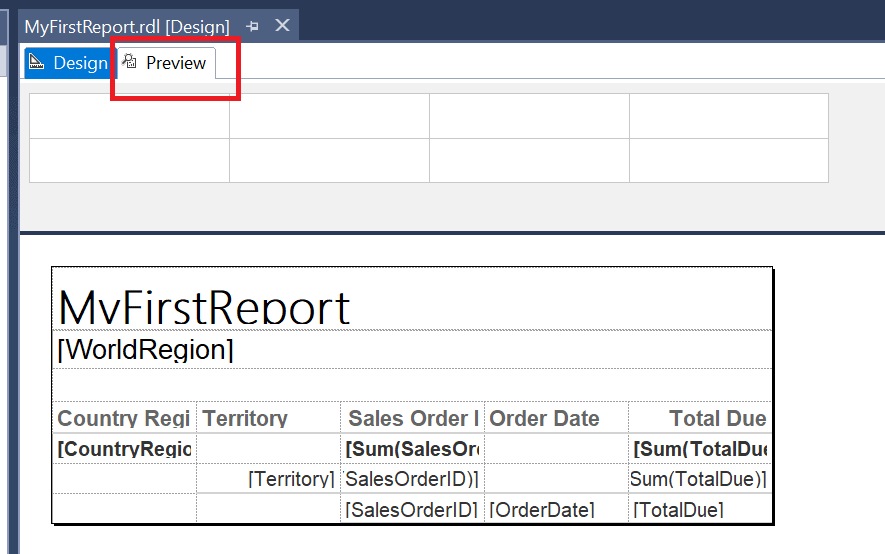
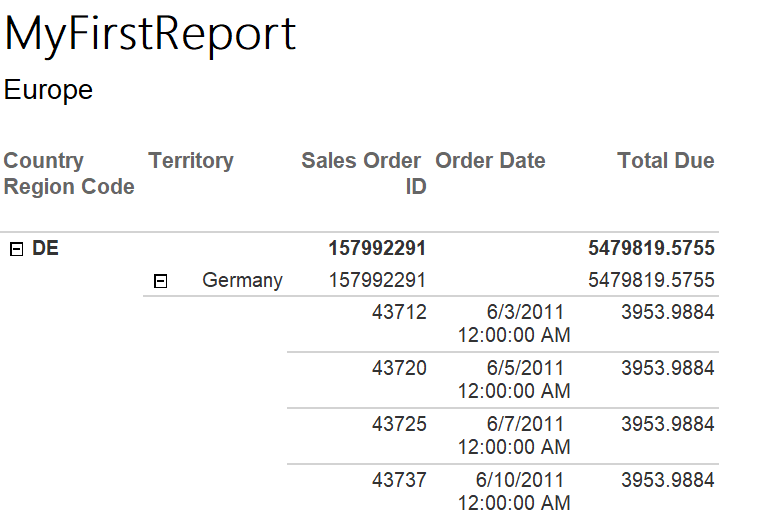
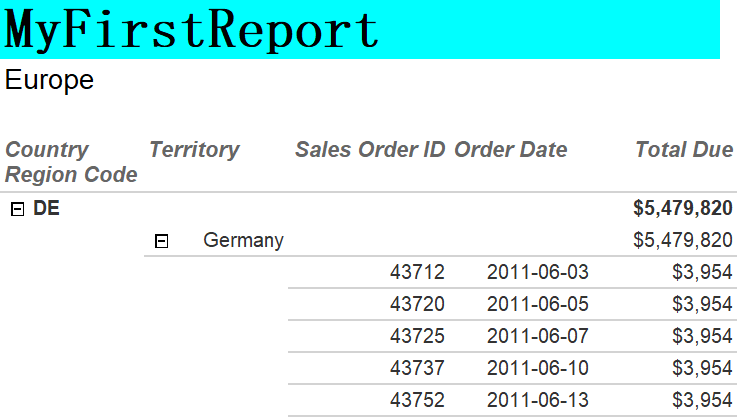
When previewing, SSRS will combine the report definition with the actual data. The interesting thing about this report is that you selected Enable drilldown, so the sections are collapsed.

Click the first plus sign to expand the section. You’ll see that there is another section that can be expanded to see the details.
Cleaning up the Wizard Report
The wizard successfully created a report, but there are some things to clean up. For example, wouldn’t it be nice to format the currency fields? You might also want to add some color to the report.
Here is a list of items that must be cleaned up before the report is useful:
- Remove totals and subtotals from Sales Order ID fields
- Format date fields
- Format currency fields
- Adjust widths
Selecting the cell you wish to modify is one of the trickiest things about formatting reports. You can select the cell, the contents of the cell, or even a portion of contents of the cell. I’ve had good luck by clicking the edge of the cell when I want to select it for formatting. It might take some practice, but don’t give up!
You need to remove all the total and subtotals from the Sales Order ID column. In addition to the header, the only one you should keep is the one in the Detail row, which is at the bottom of the report. You may be able to see that the two to be removed are formulas which start with [SUM.
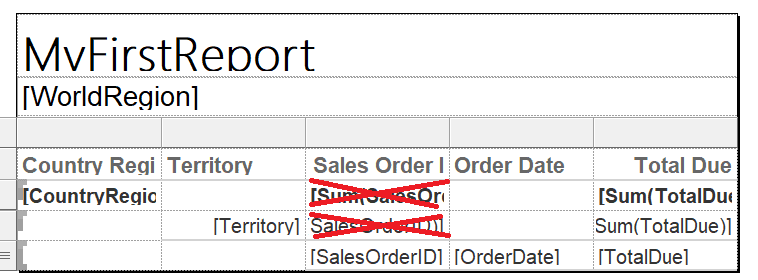
Select each cell and click Delete to remove the two formulas.

The next item in the list is to format the dates. All the dates in the AdventureWorks database are the old DateTime data type and has 12:00 am for each time. There is no reason to show these times. The easiest way to format is to right-click on the cell so that the context menu pops up. Select Text Box Properties…
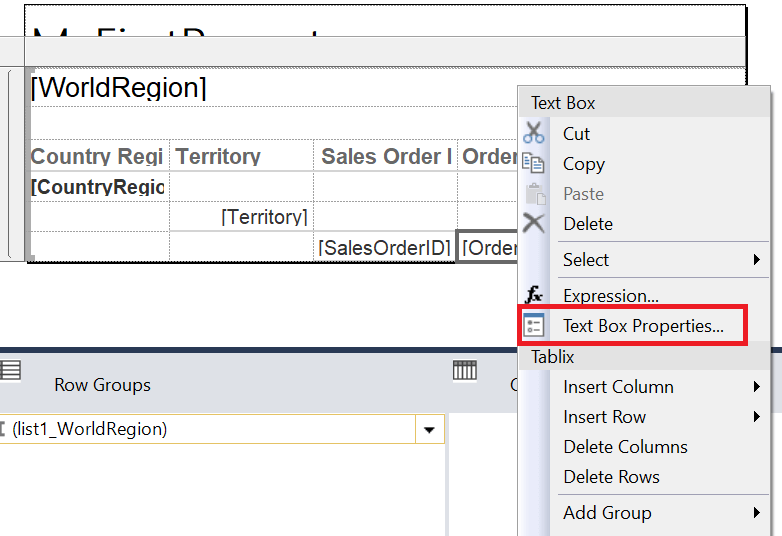
The Text Box Properties dialog has quite a few options. You’ll learn more about them as you read through the series, but for now select Number Date.
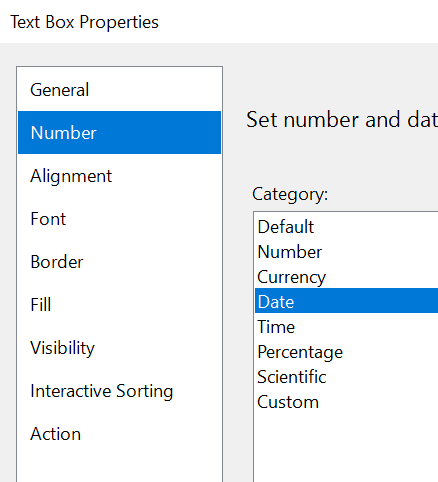
You’ll see a list of many date formats. Select one of them that displays only the date and click OK.
It’s a good idea to preview the report as you go, so take a look now by clicking the Preview tab. You’ll need to also expand the plus signs to see the all the changes.
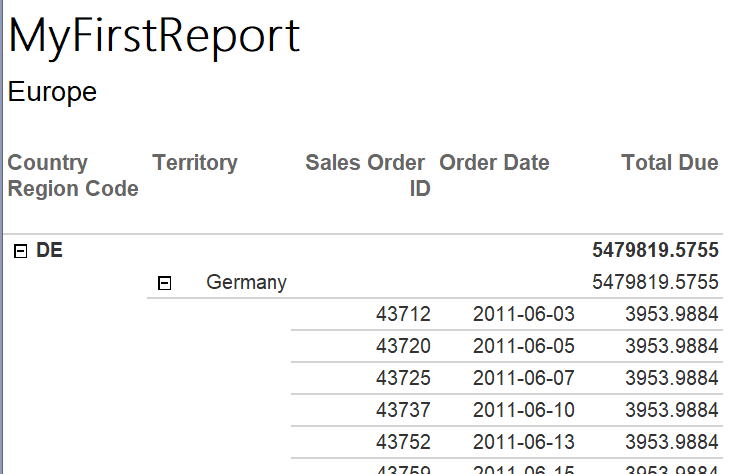
Back in design view, it’s now time to format the three currency cells. The only way to use the Text Box Property dialog is to format each of them separately. I’ll show you a trick that will save you some time, especially if you have several of them to format.
Right-click on one of the Total Due cells and select Text Box Properties… Navigate to Number Currency. If you just click OK at this point, it will format the cell to your local currency, but you might want to change the Decimal Places to 0 and select Use 1000 separator or make some other changes. You’ll see a sample of the format at the top.
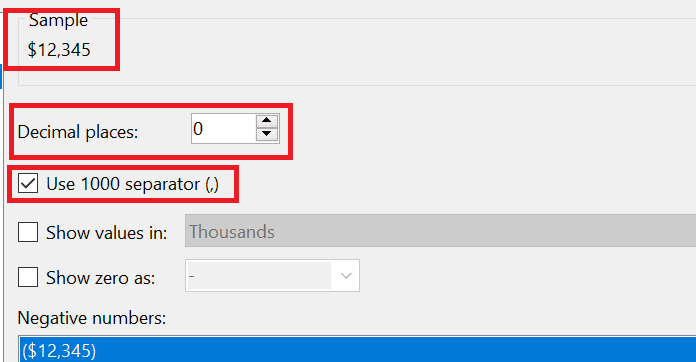
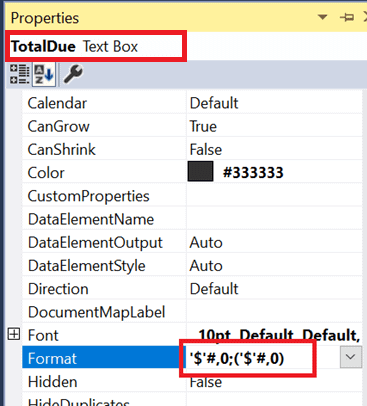
Click OK to save the format. In order to save time, you will copy the format to the other currency cells. While the cell you formatted is selected, bring up the Properties window by clicking F4. Note that this is not the same as the Text Box Properties. The cell’s name is shown at the top of the window.
Scroll down until you find the Format property. Select the text and copy to the Clipboard.
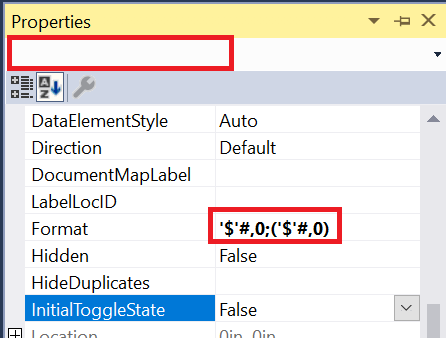
Now select the other currency cells. You can select multiple cells by holding down the CTRL key. You can also select entire columns if that is helpful. In this case, select the Total Due column by clicking the column handle.

Open the Properties window again and paste the formula into the Format property. Since multiple cells are selected, the name is blank.
Preview the report to view the currency cell formatting.
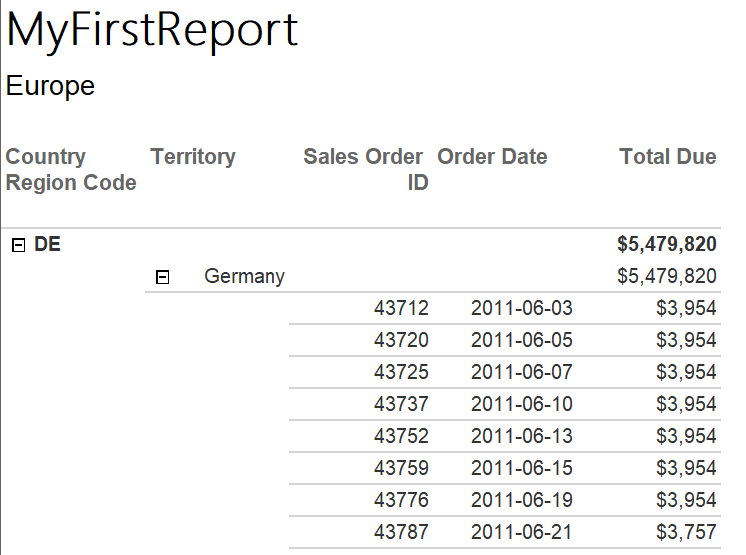
Switch back to design view. The last thing on the list is to adjust widths. You will probably want to expand the Sales Order ID column. Select the column and then drag the right side of it over to expand the cell slightly.
Changing Fonts and Colors
It’s simple to change font properties and background colors, and SSRS gives you three ways to do it. You can use the Text Box Property dialog box, the Properties window, or menu items at above the design window.
Select the report name text box at the top of the report. Select a different font name and size.

Select the background icon, highlighted above, and choose a different color. Click OK. You can also format entire rows or columns by selecting a handle. Select the row handle for the header row and then format with Italics. Format any other items as desired and then preview the report.
Try formatting a single cell with the Text Box Properties dialog or the Properties window. You may find that the menu items are the easiest when it comes to formatting the fonts and colors.
Print Layout Mode
One of the most frustrating things about previewing the report is that you can’t really tell how the report will look when printed or exported to PDF. To solve this issue, you can switch to Print Layout mode while viewing the report in preview.
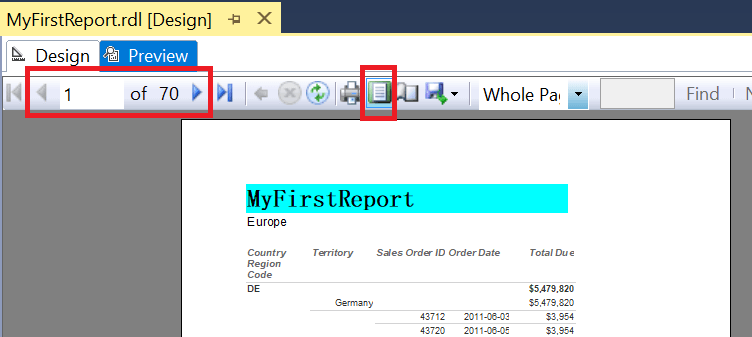
It’s critical that you view the report this way and even scroll to the next page in order to make sure that the report width fits properly on the page, and that it doesn’t leave strange blank pages between populated pages.
This report fits perfectly on the page, so to see the problem, switch back to design view. Grab the right edge of the report and pull it several inches to the right, leaving quite a bit of white space.
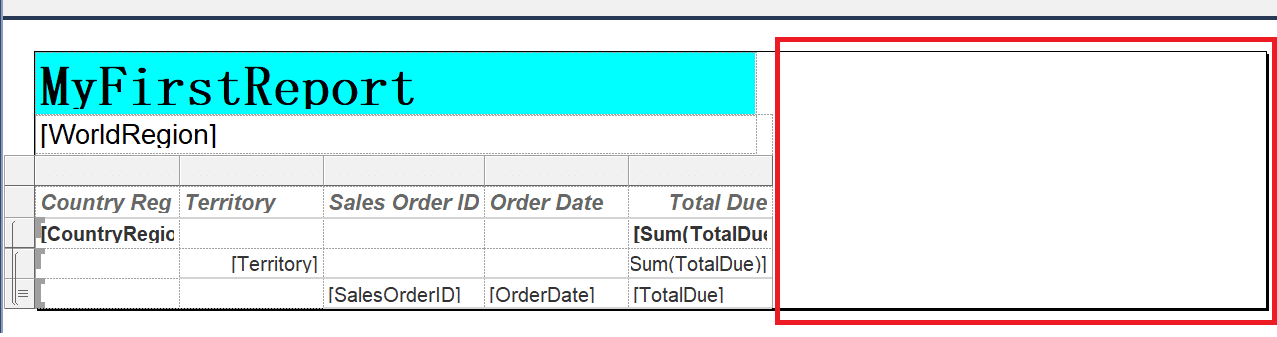
Go back into preview mode. Make sure that Print Layout is toggled off so that you can expand the DE and Germany sections. Switch to Print Layout and scroll a few pages. You’ll see that every other page is blank! This is due to width of the page even though the right side is not populated with any data.
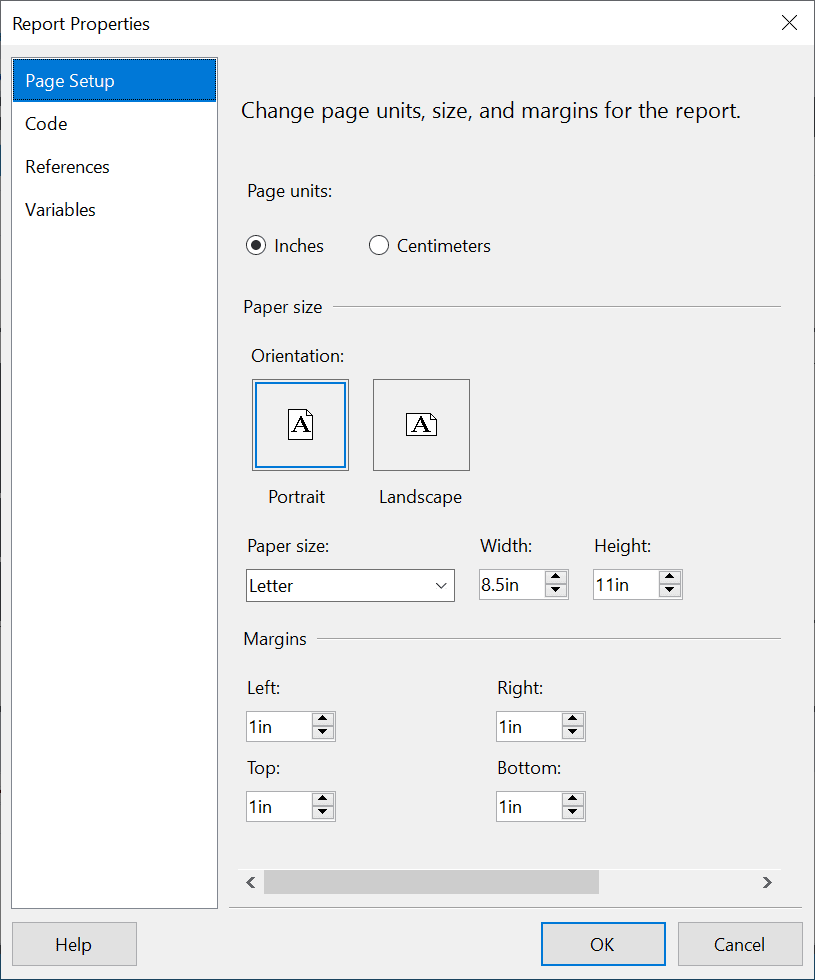
Another thing that you may need to do from time to time is to change the print layout. If the report is fairly wide, you can change to landscape or even switch to a different size paper, such as legal, if your company uses that size. Switch back to design view and select Report Report Properties from the menu. Here you can switch the Orientation between Portrait and Landscape, change the paper size, and modify the report margins.
One more tool at your disposal is the ruler which you can turn on from Report View Ruler. Make sure that your report width plus the Left and Right margins do not exceed the width of your paper.
It may take some trial and error, but don’t stop working until you are sure that the report will print properly.
Launching the Wizard from the Solution Explorer
Now that you’ve created a report with the wizard, you should be able to see it in the Solution Explorer, typically on the right of the screen.
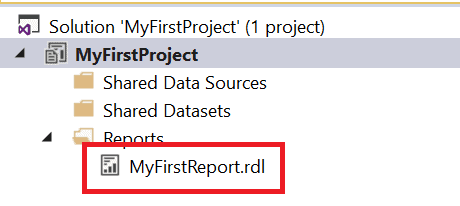
If you close the report definition, you can open it by double-clicking the name here. Another thing you might want to do is to create another report. If you would like to launch the wizard again, all you have to do is to right-click the Reports folder and select Add new report.
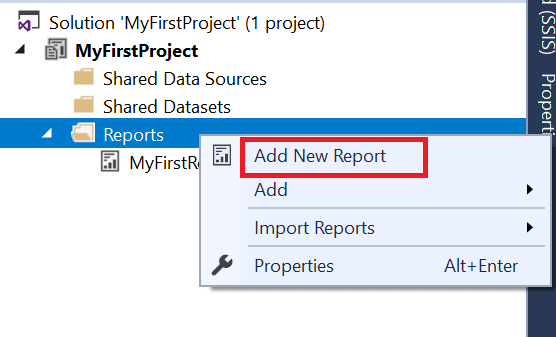
Instead, if you would like to create a report manually, choose Reports Add New Item Report. Creating a new report this way will be covered in the next article.
What if you close the project and want to open it again later? There are several ways to do that.
Open Visual Studio…
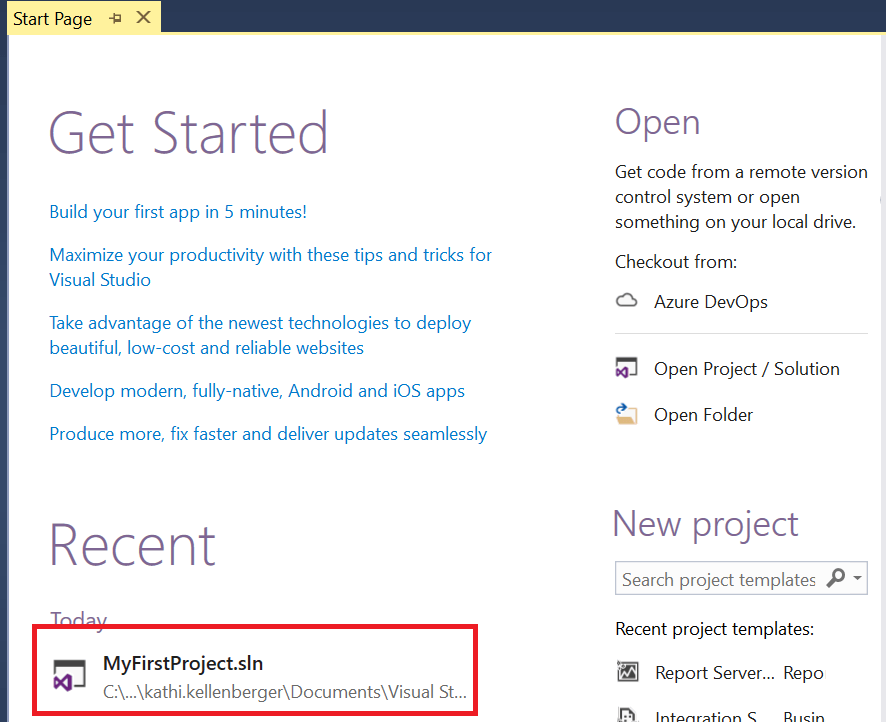
- Click the name of the project on the Start Page under Recent
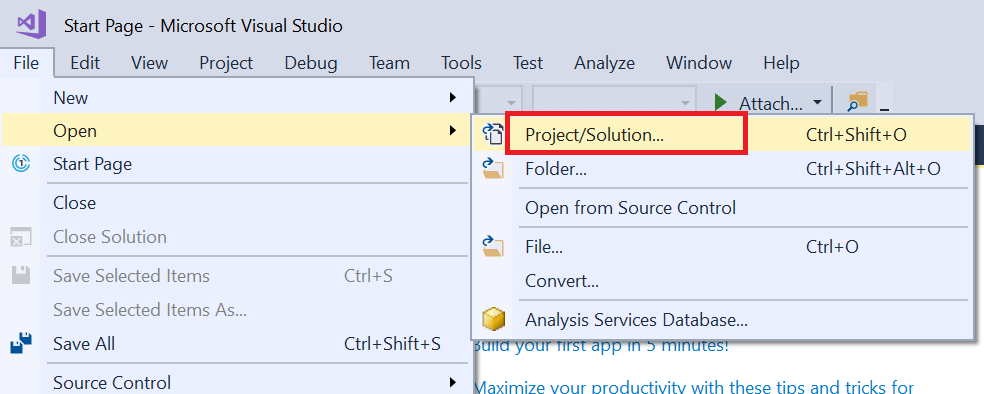
- From the menu, select File Open and then navigate to the solution on your hard drive.
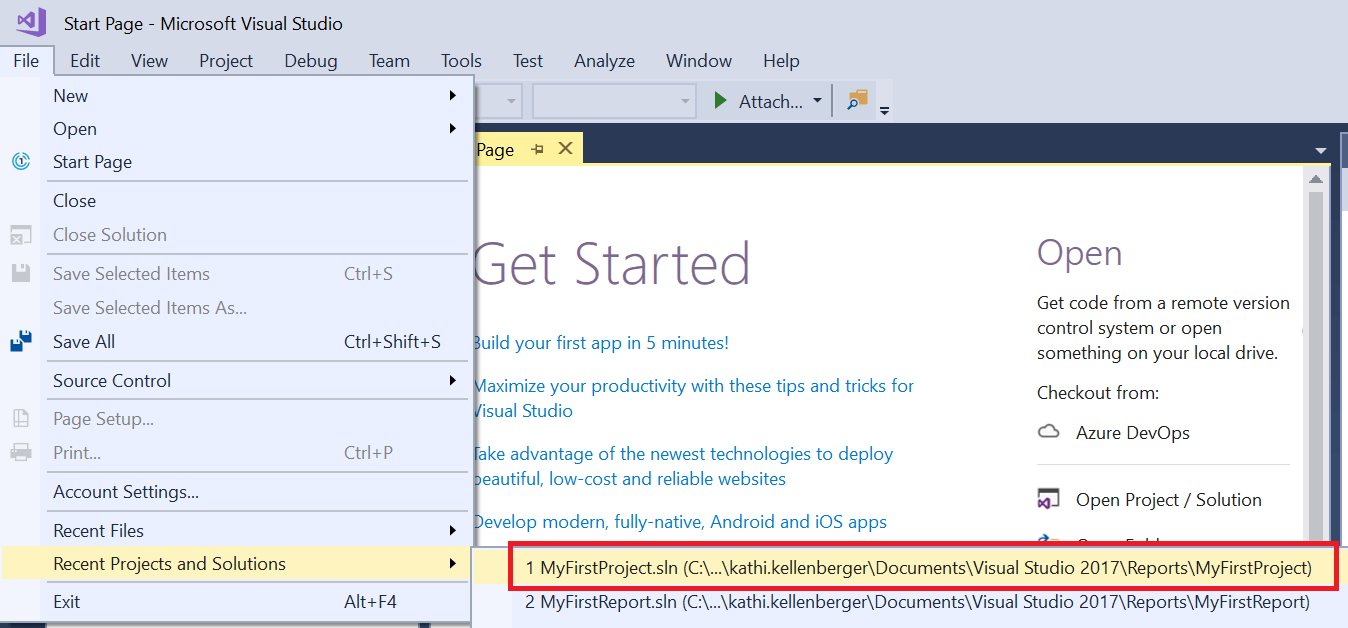
- From the menu, select File Recent Projects and Solutions and then select it from the list.
You could also navigate using the file explorer and double-click the sln file which will also launch Visual Studio, but this is more difficult than the other methods.
Be sure to save your solution once you are done working.
Conclusion
In this article, you created a report using the wizard, learned about formatting and how to make sure that your report fits properly on the page when printed. The Report Wizard is a nice way to get started, but you will probably realize that there are many limitations soon enough and not become dependent upon it.
In the next article, you’ll learn about data sources, datasets, and create a report from scratch without using the wizard.
The post Reporting Services Basics: Creating Your First Report appeared first on Simple Talk.
from Simple Talk http://bit.ly/2I8rFel
via