I still remember the time our “Senior Architect” got so frustrated at a long-running transaction filling up the log files that he just deleted the darn things, causing SQL Server to spew memory dumps until we DBAs put the instance out of its misery. Managing log files can be hard, and correctly sizing them isn’t just a challenge for the clueless. You must take the effect of Rebuilds, ALTERs, and other operations on the logs into careful account. Moreover, size isn’t the only lurking log-related threat. You’ve probably heard (if not lived through) horror stories of days-long rollbacks or snails-pace recoveries.
Accelerated Database Recovery (ADR), new with SQL Server 2019 and Azure SQL Database, is meant to help here. It’s worth learning about, because it’s likely to become a commonly used feature, and is in fact required for Hyperscale. For those who don’t have time to dive into the whitepaper, or who want more details than in Microsoft’s introduction, this article is meant to function as a primer to how it works. I’m going to assume basic knowledge about logging and recovery, and I’m also going to oversimplify some parts. The article illustrates (and animates!) how ADR works and how Microsoft optimized the feature.
The starting line is a realization that keeping old versions of rows can help log-related pain points. How does ADR use row versioning to solve these? Read on!
Versions to the Rescue
Begin with a rollback, where one session makes a number of changes but then aborts. This is how it typically works:
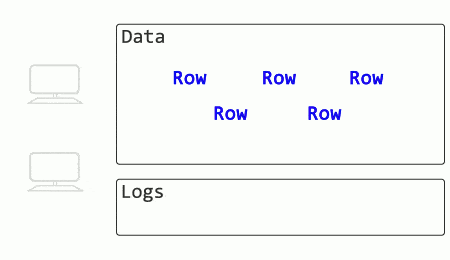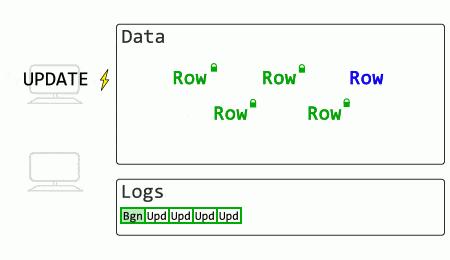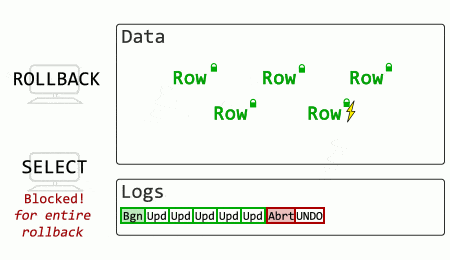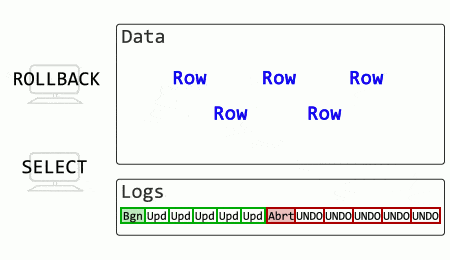
See how another session’s SELECT is blocked until the rollback process completes? When an UPDATE rolls back, other queries have to wait until the modifications are undone before they can select data (with exceptions for existing isolation levels that use versioning).
What if SQL Server stored old row versions?
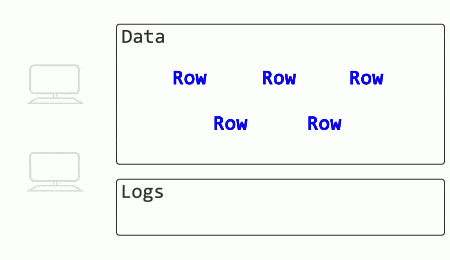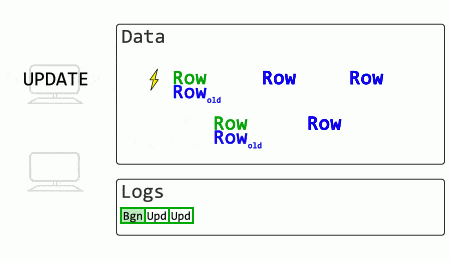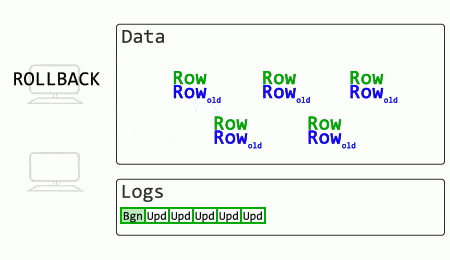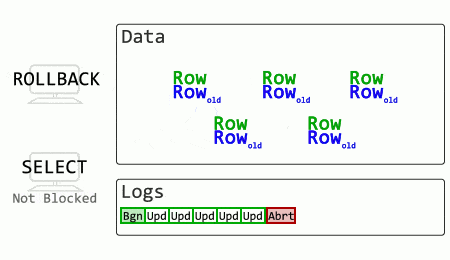
The rollback in this case is effectively instant (merely marking a particular transaction as aborted). The SELECT no longer has to wait for change reversal to finish and locks to release but can read the older, committed record.
Recovery after a restart or a restore is a more complicated process. When a database is recovered, there’s no guarantee about data on disk. Some committed transactions may need to be redone, and some in-flight transactions may need to be aborted and their changes rolled back. This occurs across multiple phases:
- Analysis (figuring out changes that matter)
- Redo (replaying changes)
- Undo (reversing changes)
Important side note here, since some misleading graphics are floating around: data modification only occurs for changes since the last checkpoint – earlier Redo activity is for locks. Here’s roughly what Recovery looks like now, with gross omissions and oversimplifications.
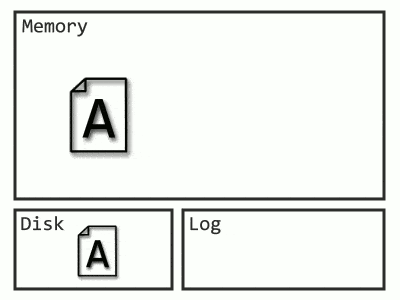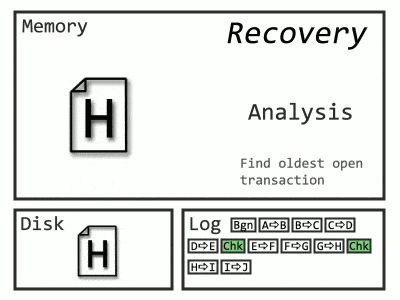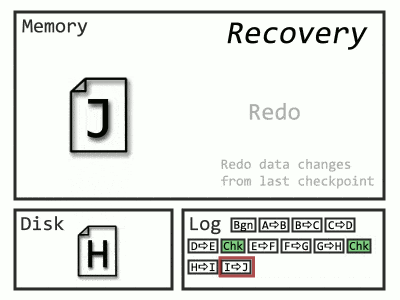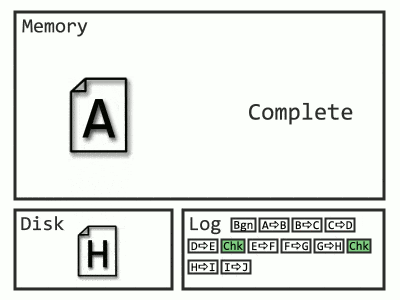
The process has to go all the way back to the start of the oldest transaction, which, if you have junior developers, could be a very long time ago.
Imagine it with row versions:
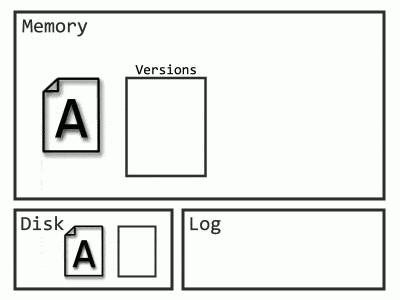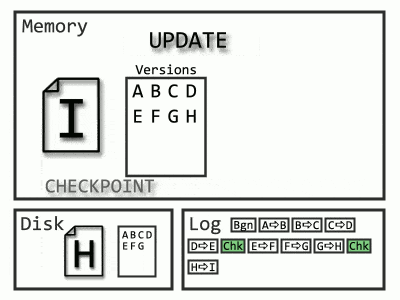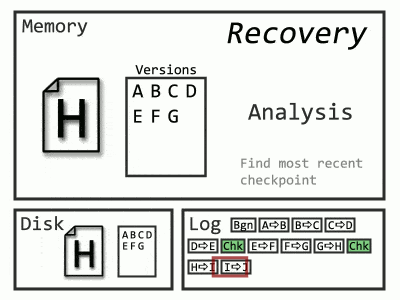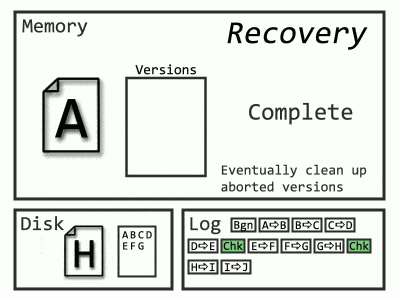
Now Recovery only needs to start from the latest checkpoint, and the Undo phase is unnecessary, as queries can begin selecting data from the old versions (remember how versions helped with rollbacks). Even more exciting, since those log records before the checkpoint aren’t needed, SQL Server can throw them out as soon as they’re no longer required (read: after they’re backed up).
The potential benefits are now apparent: versioning can help with rollback, versioning can help with recovery, and versioning can even eliminate the risk of log file explosion during a large transaction.
Three New Structures: PVS, ATM, and S-Log
The potential benefits of versioning are large – what does it take to make it a reality? Three new important structures emerge as solutions to important challenges, each of which is critical to understanding ADR. Other minor objects and a host of cleanup processes exist as well but are tied to these central additions.
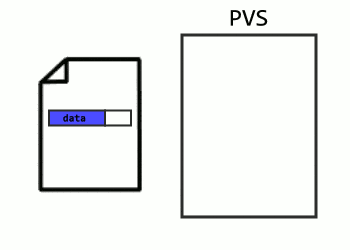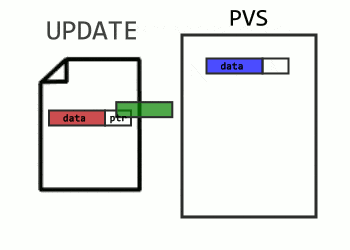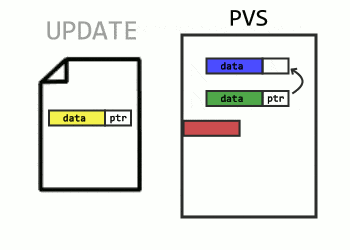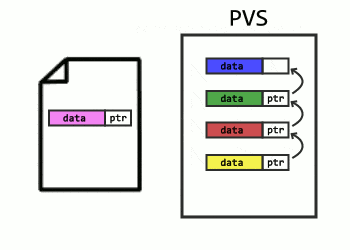
Persistent Version Store (PVS)
The first issue is with the original way versioning is implemented with isolation levels that use versioning: versions don’t survive a restart. In database lingo, they’re not durable. Versions live in tempdb, and when the server restarts, tempdb gets rebuilt. And that just won’t do for recovery, since recovery is often from a restart that would have wiped tempdb clean, taking those critical versions with it.
The solution to this is to make versions durable, or persistent, thus the name Persistent Version Store (PVS). Instead of being written to tempdb, they are instead stored in a table in the database, and their creation is logged to make them recoverable.
Versions work mostly the same as before. Every row has transaction information, and if necessary, a pointer to the older version in the version store. I would visualize it like this:
Aborted Transaction Map (ATM)
Versioning sounds promising, but this leads to another missing piece. How does a query know which row to read in the presence of an aborted transaction? The solution is to track which transactions were aborted, not just which ones are ongoing. This way, every time a query looks at a row, it checks whether the row was modified by an aborted transaction. The list of aborted transactions is called the Aborted Transaction Map. It’s implemented as a hash table, and I imagine it like below:

Secondary Log (S-Log)
The solution is making good progress, but there’s another problem (get used to this). Most transactions sent to SQL Server are composed of various smaller operations, and not everything can be versioned. For example, a large insert may add many rows which include versioning information, but will also require space allocations that get tracked in pages impossible to version. In the case of an operation that can’t be versioned, there are two main options: 1) Make it a short, independent transaction and clean it up later if needed. 2) Log it anyways and follow the traditional Redo/Undo recovery process.
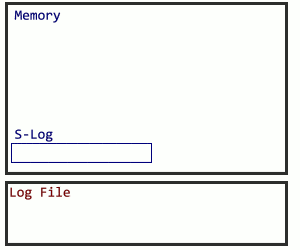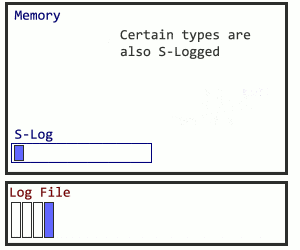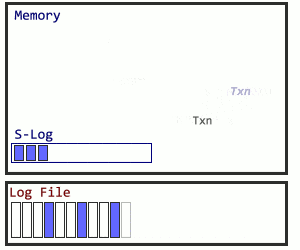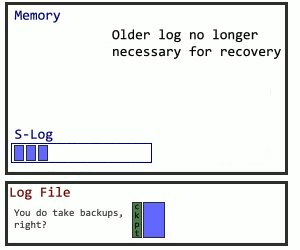
But following the traditional logging method, even for a subset of logged activity, runs the risk of undoing the progress. What happens to logs before a checkpoint? How will the database recover? In this case, Microsoft sets up a secondary structure in concert with the log file named the S-Log. The secret sauce for the S-Log is what happens during a checkpoint. SQL Server locates all S-Log records from before the checkpoint, and adds them all together after the checkpoint, making the old log records safe to truncate. Here’s how I visualize it:
Optimizing the New Structures
There are now sufficient pieces in place for functional Accelerated Database Recovery. Versions are made durable in the Persistent Version Store to survive restarts, aborted transactions are tracked in the Aborted Transaction Map, and the S-Log captures unversionable actions and guarantees they’re accessible after the most recent checkpoint. These are the three main components: PVS, ATM, and S-Log.
These structures all add overhead. Real-world performance matters, so how can they be optimized? Microsoft doesn’t want a tagline of “ADR: It Just Runs Slower.”
PVS is probably the component with the most optimization. The first issue to be wary of is a case where repeated aborted transactions push the actual, committed row further and further down the version chain.
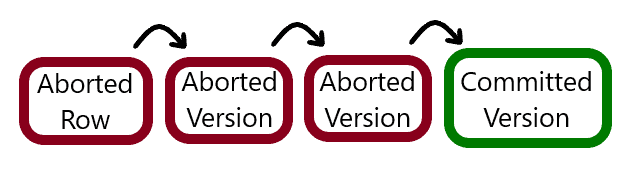
In this situation, instead of aborted transactions pushing the last committed data further away, the updating query will check transaction status before making a new version. If the row on page belongs to an aborted transaction, the new row will overwrite it, while keeping the pointer to the older, committed row.
Another optimization for PVS is in how it does versioning. Since creating a new version in the PVS pages takes a separate transaction and stores data on a separate page, it sometimes makes sense to store the version within the original row itself. This is done with a differential appended to the row, looking something like below (again, with criminal oversimplification).

Moreover, funneling all database versions into a single table sounds like a recipe for contention. Microsoft is aware of this, however, and say they partition accessors and preallocate space, in addition to making the PVS table append-only.
The ATM has performance tweaks as well. A system with numerous rollbacks would experience a bloated, inefficient ATM. To mitigate this, sufficiently small transactions (measured by transaction log size) are rolled back immediately, instead of leaving transaction info in the map for later cleanup.
Optimizations of the S-Log are focused on keeping it small – both by limiting what goes into it and by constant cleaning to minimize its memory footprint. Remember that the S-Log is for operations that aren’t viable for versioning. Probably the most significant contributor to these would be allocation operations. In what should be a familiar strategy by now, these are instead committed immediately, with a background process tasked with undoing any mistakes. Deallocations can’t be committed immediately, but are deferred instead of logged, again with a background process assigned for cleanup.
The other big risk for S-Log explosion would come from locks. For various reasons, locks are logged in SQL Server. Under ADR, the number of these is reduced. Only the highest level locks are logged in the S-Log. To make sure recovery still works correctly during the S-Log process, a new locking object is introduced to make sure no incorrect reads occur.
Cleanup Processes
What happens to versions that are no longer needed? Will the Aborted Transaction Map continue to grow indefinitely? The size of these new structures has performance implications as well, so background cleanup tasks are required.
You may have noticed the process called Logical Revert in Microsoft’s explanation of ADR. Because it’s inefficient to leave aborted rows hanging around in data pages, there’s a cleanup process for this too. In the case where the data page contains an aborted row while the committed version is in the PVS (or an in-row version), Logical Revert will overwrite the aborted row with the committed, effectively moving the committed row back. I visualize it like this:
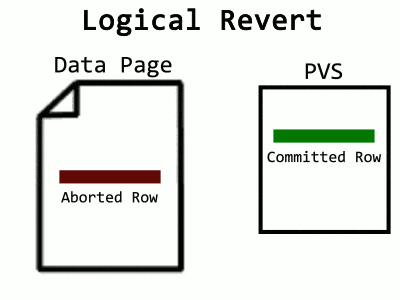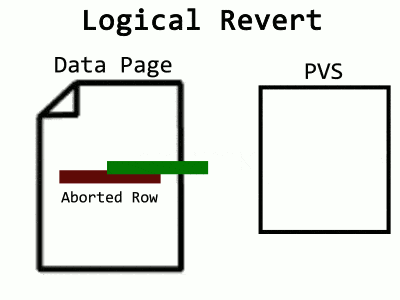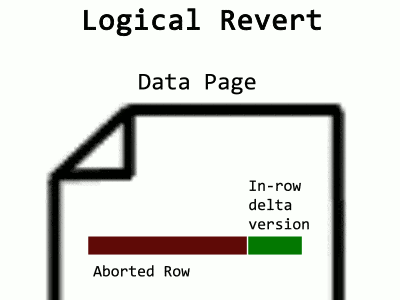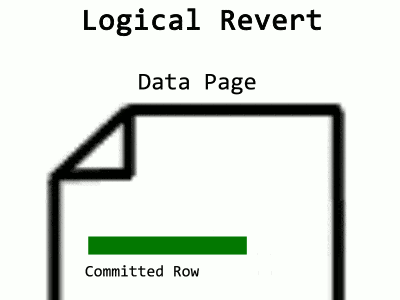
Over time, the ATM will fill up, and a background task cleans it. For an aborted transaction to be removed from the map, all of its aborted rows left in pages need Logical Revert applied to them. Cleaning one transaction at a time would require a way to determine which pages a transaction touched. Log records would allow that, except in ADR, SQL Server is truncating log records early. Instead, what happens is a scan of the entire database – at least, the pages containing rows from aborted transactions. PFS pages now track which data pages contain aborted rows, allowing a faster sweep. Also, instead of worrying about constant additions to the ATM, a snapshot of it is taken at the beginning, and when the sweep completes, all transactions present in the snapshot are removed. What’s that? Too many words? Fine, have an animation:
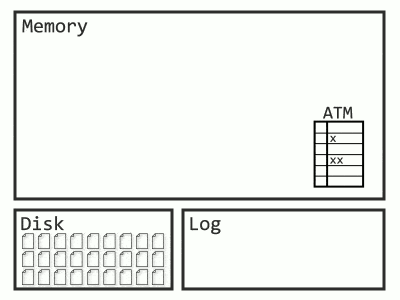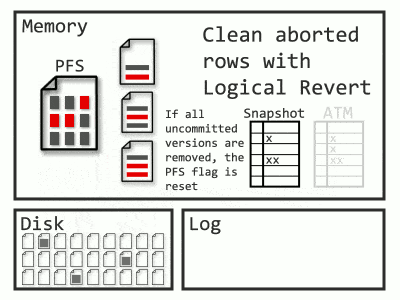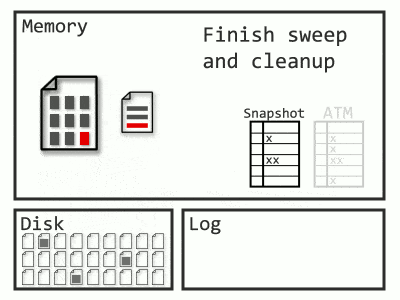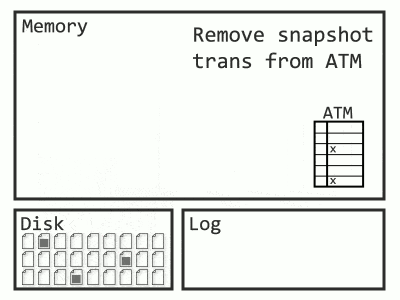
PVS pages use their own hash map as well, but this stores the most recent transaction per page. The oldest transaction necessary for Snapshot Isolation and the oldest transaction in the ATM are both tracked. Any PVS page with a max transaction earlier than both of these is safe to clean up. Since the PVS is append-only, cleanup occurs by deallocating the page.
The S-Log, as an in-memory structure, is also critical to keep lean. The in-memory records are needed for transactions that might rollback, while the on-disk logs are for recovery. As such, any S-Log for a transaction that can’t roll back is eligible for removal. There are two cleanup processes here. The first occurs at checkpoints, where S-Log records for transactions older than the oldest active transaction are removed. The second is a background scan that looks for S-Logs related to inactive transactions and removes them.
Summary
You can now review the key points:
- Long rollbacks, long recovery, and bloated log files are problems
- Versioning can solve these problems
- To do so, it needs the PVS, ATM, and S-Log
- These structures have optimizations to make them faster
- These structures use numerous deferred cleanup processes
I would also summarize as below. If you want to check yourself after reading this, try to recreate the grid from memory.
|
Major Structure |
PVS |
ATM |
S-Log |
|
Purpose |
Makes versions durable |
Tracks Aborted Transactions |
Allows logging for unversionable changes |
|
Optimizations |
In-row versions. Table design. Abort overwrites. |
Short transaction rollbacks |
Most unversionable changes moved to deferred cleanup. |
|
Cleanup |
Hash map transaction tracking, page deallocation. |
Whole database sweep, PFS tracking, ATM snapshot |
Background and checkpoint cleanup for unneeded S-Logs |
By now, it should be obvious that ADR isn’t a magic go-faster option, (nor is NOLOCK by the way, despite what certain developers seem to believe.) There’s storage overhead, compute overhead, and a myriad of deferred cleanup processes.
After the number of log-related incidents I’ve suffered, I’m ready to say these are tradeoffs I’m willing to make. Moreover, I don’t even get a say if I want to use some newer cloud offerings like Hyperscale. I believe there are two critical components to supporting a product: the ability to Google well and actually understanding how it works. Since Stack Exchange doesn’t have answers on ADR failure modes yet, I’ll do my best to be prepared, and I hope this serves as a useful primer for you too.
The post How Does Accelerated Database Recovery Work? appeared first on Simple Talk.
from Simple Talk https://ift.tt/2rqMhcY
via

 Figure 1: Creating a new project in Unity Hub.
Figure 1: Creating a new project in Unity Hub.
 Figure 5: Creating a new shader.
Figure 5: Creating a new shader.
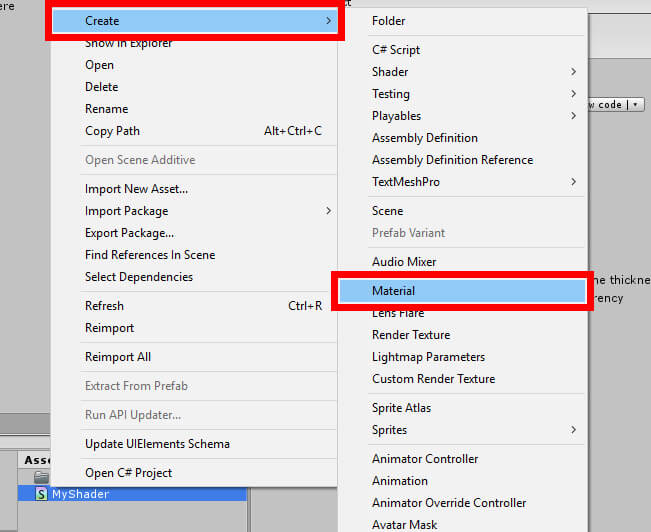
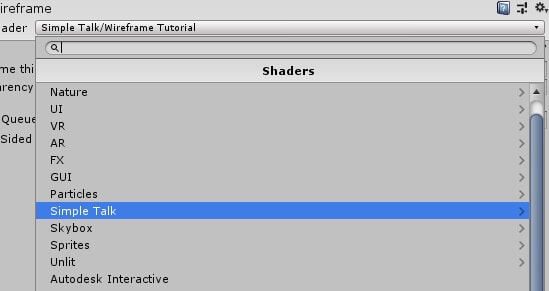
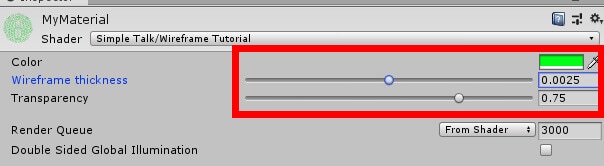
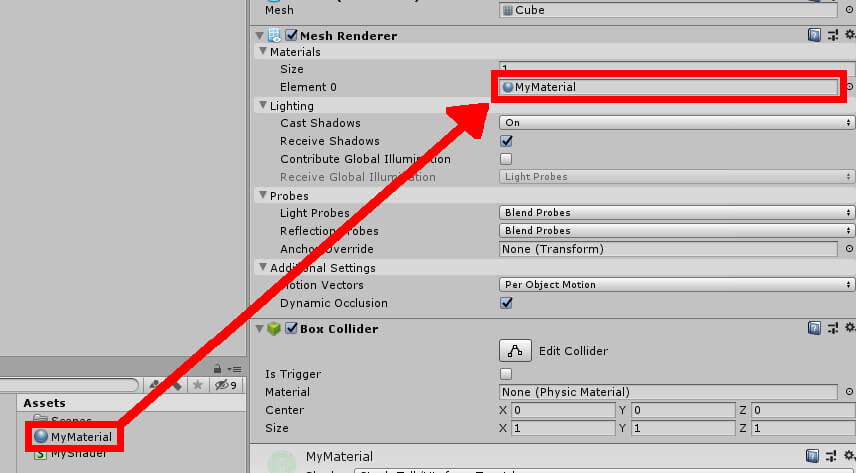 Figure 11: Setting object material.
Figure 11: Setting object material. Figure 12: Cube and Sphere with new material.
Figure 12: Cube and Sphere with new material.