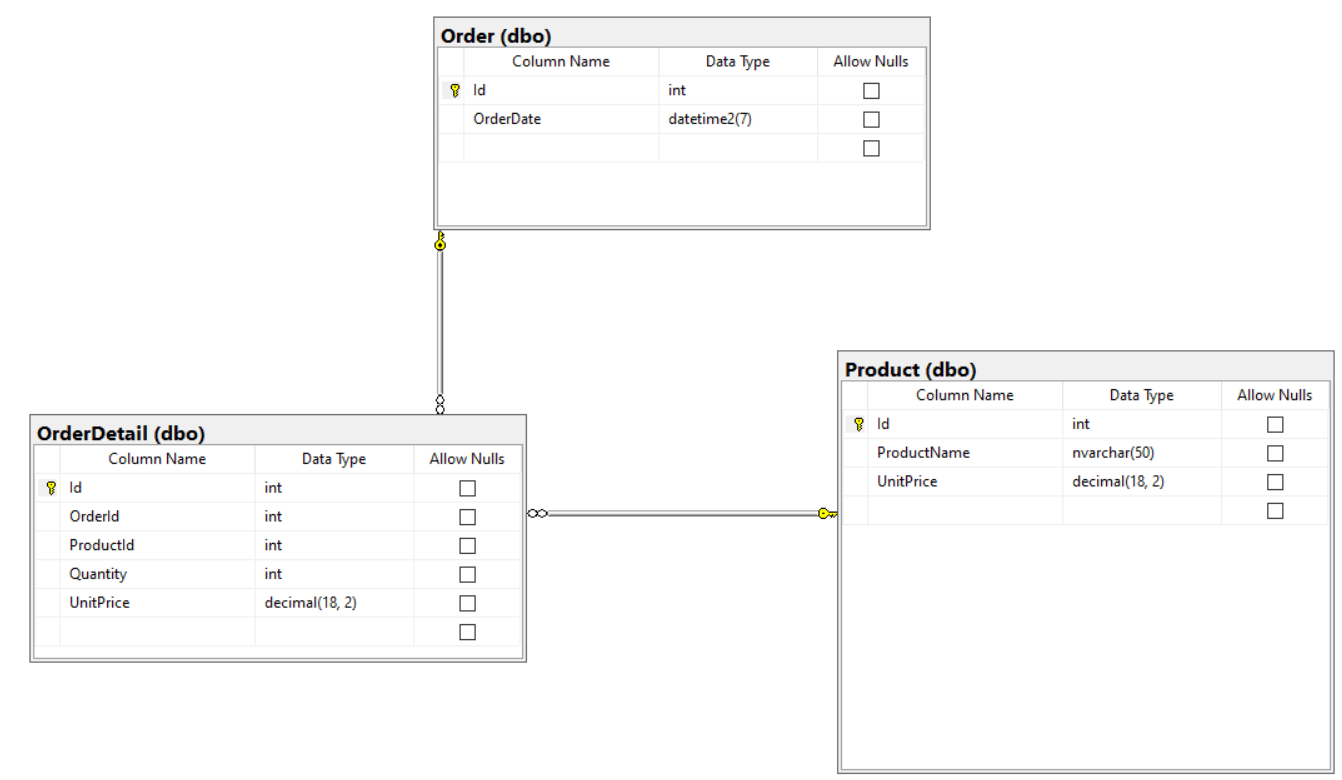
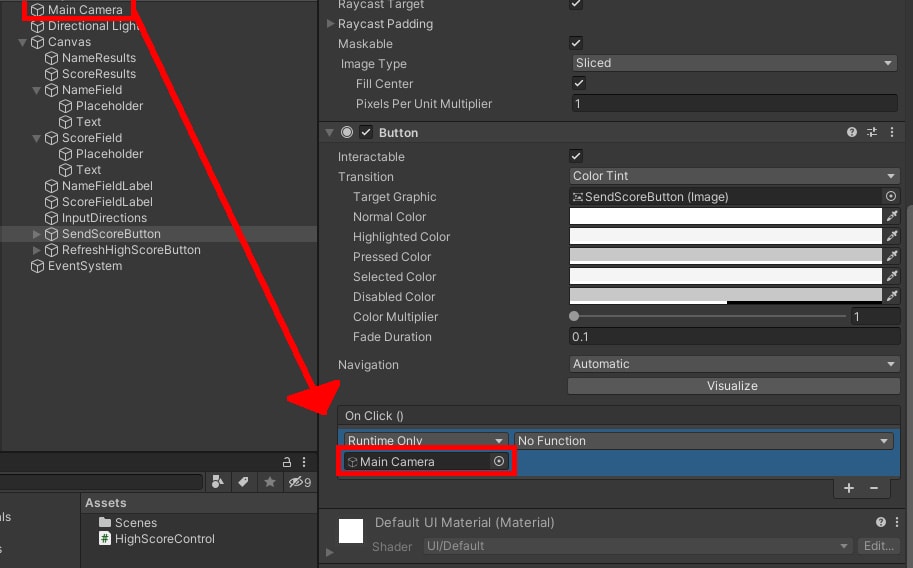
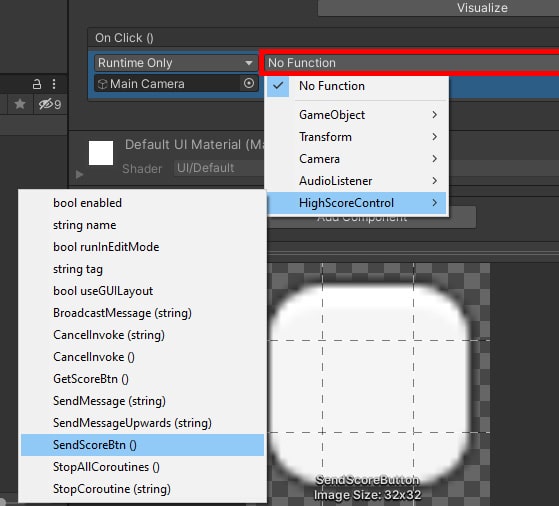
When developing an application that accesses SQL Server, you need to set up a security model, so each user gets the access they need based on their job duties. Some applications require the same access for all users, while other application might require different security access rights based on the role a user has in the organization. The best practice for providing user access is to use role-based security. SQL Server provides user-defined Server and Database roles for defining security rules for different user security needs. This article will discuss how to use user-defined server and database roles to provide secure access to SQL Server resources.
What is Role-Based Security?
Role-based security is the concept of providing each application user access to the SQL Server resources they need by being a member of a role. A role is an object in SQL Server that contains members, much like a Windows group contains members. When a user is a member of a role, they inherit the permissions associated with the role.
When role-based security is used, the actual access permissions to SQL Server resources are granted to a role and not a specific user. Role-based security reduces the amount of administration work needed to grant and manage security when multiple application users require the same access to SQL Server resources. Once a role has been set up, and the appropriate permissions have been granted, it is just a simple matter of adding users to the role to provide them with the same security access. Without using roles, an administrator would need to grant the same permissions to each user, thus causing additional administration work. There is also the possibility of making an error, resulting in some users getting the wrong set of permissions.
Since SQL Server 2012, Microsoft has provided two different types of user-defined roles: Server and Database. The user-defined server roles provide security access to server resources. In contrast, user-defined database roles provide access to database resources.
User-Defined Server Roles
User-defined server roles are created at the server level and allow you to assign a specific set of server-level permissions to the role. One example of where a user-defined server role would be useful is to limit the server-level access that a junior DBA might have. By creating a server-level role, you could provide a junior DBA with access to only those server resources they need to perform their Junior DBA duties without giving them full server access via the sysadmin fixed server role.
To demonstrate how to create a server-level user-defined role with limited server permissions, I will create a user-defined server role named Junior DBA. As the name implies, this user-defined role will be set up with a limited set of server rights for a junior DBA. I want this Junior DBA user-defined role to only have access to view databases and server state information.
The first step to setting up the Junior DBA user-defined role is to create the role. The new role can be created using TSQL or SSMS. Listing 1 shows the TSQL code to create this role.
Listing 1: Creating a user-defined server role
CREATE SERVER ROLE [Junior DBA] AUTHORIZATION SA;
The code in Listing 1 only creates the role and gives the ownership of this role to the account SA, by providing the AUTHORIZATION keyword followed by the login SA. If the authorization keyword and login were omitted, then my login would have owned this user-defined server role. This TSQL code has only created the role but did not assign any server rights to the new role.
I could have also created this server role using SSMS by performing the following steps.
- Open up Object Explorer and connect to the server where the new server role needs to be created.
- Expand the Security folder.
- Right-click on the Server Role item and select the New Server Role… item from the pop-up menu.
If I had used the SSMS steps to create my Junior DBA role, then the New Server Role window in Figure 1 would have been displayed.
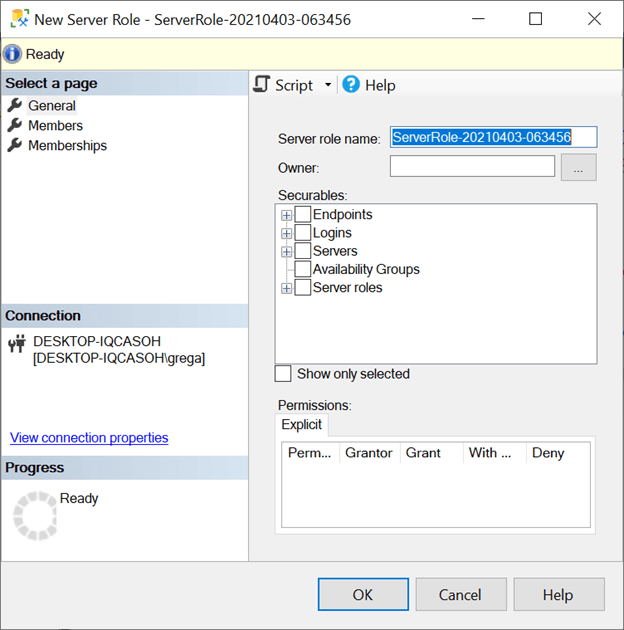
Figure 1: New Server Role window
As you can see, SSMS automatically generated a user-defined role name of ServerRole-20210403-063456. Since this isn’t the name I want for my role, I now need to type over that automatically generated name with my role name of Junior DBA and enter dbo in the owner field. At this point, I could click on the OK button, and this role would be created, just as if I ran the TSQL code in Listing 1. But since I want my new Junior DBA role to have some rights, let me move on and show you how to assign rights to this new role using SSMS.
In Figure 1, the Securables section on the right side of the window has a list of server-level rights that can be granted to a user-defined role. For this demonstration, I’m only going to give my junior DBA role the following rights: view any database, view any definition, and view server state information. To give these rights, I first click on the Servers item and then scroll down and grant permissions to those view rights I want my junior DBA to have. After doing this, my New Server Role window looks like what is shown in Figure 2.
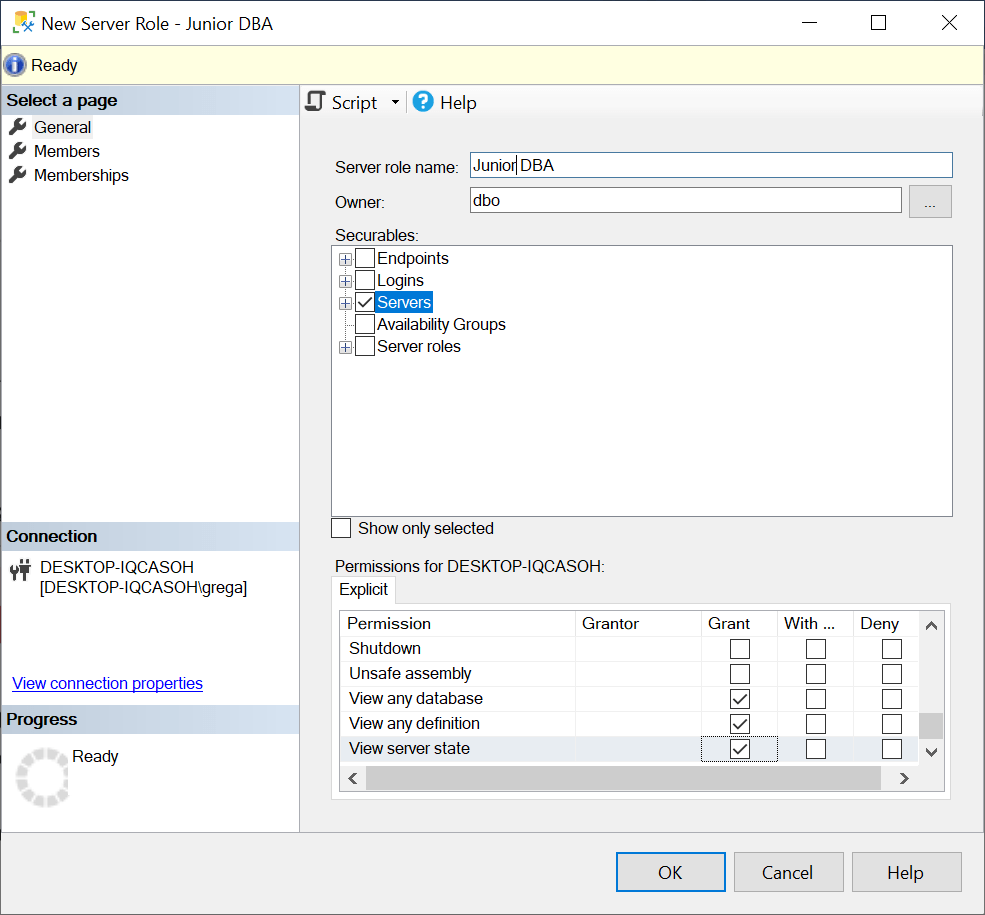
Figure 2: Junior DBA user-defined role with permission
The last step needed to create my new Junior DBA role with these rights is to click on the OK button.
The rights I provided to my new junior DBA role using SSMS could have also been granted using TSQL by running the script in Listing 2.
Listing 2: TSQL to grant permissions to the Junior DBA role
USE [master]; GO GRANT VIEW ANY DATABASE TO [Junior DBA]; GRANT VIEW ANY DEFINITION TO [Junior DBA]; GRANT VIEW SERVER STATE TO [Junior DBA]; GO
At this point, the new user-defined server role Junior DBA role has only been created and doesn’t contain any members. Before I can add members, I need to create a login for my junior DBA. For this demo, I will create a SQL authenticated login named JD using the TSQL code in Listing 3.
Listing 3: Creating my JD login
USE [master]
GO
CREATE LOGIN [JD] WITH PASSWORD=N'Junior',
DEFAULT_DATABASE=[master],
CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF
GO
To make the JD login a member of the Junior DBA role, I could use SSMS to make it a member of this role from the properties of the login or the role. I can also use the TSQL code in Listing 4.
Listing 4: Adding member to a new server role
ALTER SERVER ROLE [Junior DBA] ADD MEMBER [JD]
I have not seen server roles used that much in the real world, but user-defined server roles provide value when you want to create a role that has limited server-level permissions.
User-Defined Database Roles
User-defined database roles are for setting up different security profiles at the database level. For example, suppose you have an application with different kinds of security needs based on each user’s role in the organization. By using user-defined roles, you could set up a different role for each of the different security profiles needed by your application.
To show how user-defined database roles can provide database users access to database resources, I will add three different database users to the AdventureWorks2019 database. Each user has a different set of access rights to support a hypothetical sales application. The SalesForce application requires 3 different security profiles to support the security model needed. Each security profile will have a different set of security permissions. For each security profile, I will set up a different user-defined role and then assign to each new role the required permissions. The user-defined roles will be called: SalesManager, ProductionControl, and SalesPerson.
The SalesManager user-defined role will need access to control all resources in the AdventureWorks2019 database. The ProductionControl user-defined role will need to have rights to insert, update, and deleted data in any tables in the Production schema and will need read access to all other tables in the AdventureWorks2019 database. The last profile, SalesPerson, will need access to insert, update and delete information in all tables in the Sales schema tables and have read access to all other tables in the AdventureWorks2019 database.
In order to show how to add databases users to each of these different user-defined roles, I will create the following logins and AdventureWorks2019 database users: Tom, Dick, and Sally. These logins and users will be created using the TSQL Code in Listing 5.
Listing 5: Creating Logins and Database Users
USE [master]
GO
-- Create Logins
CREATE LOGIN [Tom] WITH PASSWORD=N'Salesman',
DEFAULT_DATABASE=[AdventureWorks2019],
CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF;
CREATE LOGIN [Dick] WITH PASSWORD=N'ProductionControl',
DEFAULT_DATABASE=[AdventureWorks2019],
CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF;
CREATE LOGIN [Sally] WITH PASSWORD=N'SalesManager',
DEFAULT_DATABASE=[AdventureWorks2019],
CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF;
GO
USE AdventureWOrks2019;
GO
-- Create Database Users
CREATE USER [Tom] FOR LOGIN [Tom] WITH DEFAULT_SCHEMA=[dbo];
GO
CREATE USER [Dick] FOR LOGIN [Dick] WITH DEFAULT_SCHEMA=[dbo];
GO
CREATE USER [Sally] FOR LOGIN [Sally] WITH DEFAULT_SCHEMA=[dbo];
GO
Since the SalesManager role will need access to all resources in the database, they will be setup with db_owner permissions. To create the SalesManager role and grant it permissions, I will perform the following steps using SSMS:
- Open up Object Explorer
- Expand the AdventureWorks2019 database
- Expand the Security folder
- Right-click on the Role item and then mouse over the New item in the menu displayed to bring up the next menu, where I then click on the New Database Role… menu item.
After completing these steps, the Database Role – New window in Figure 3 will be displayed.
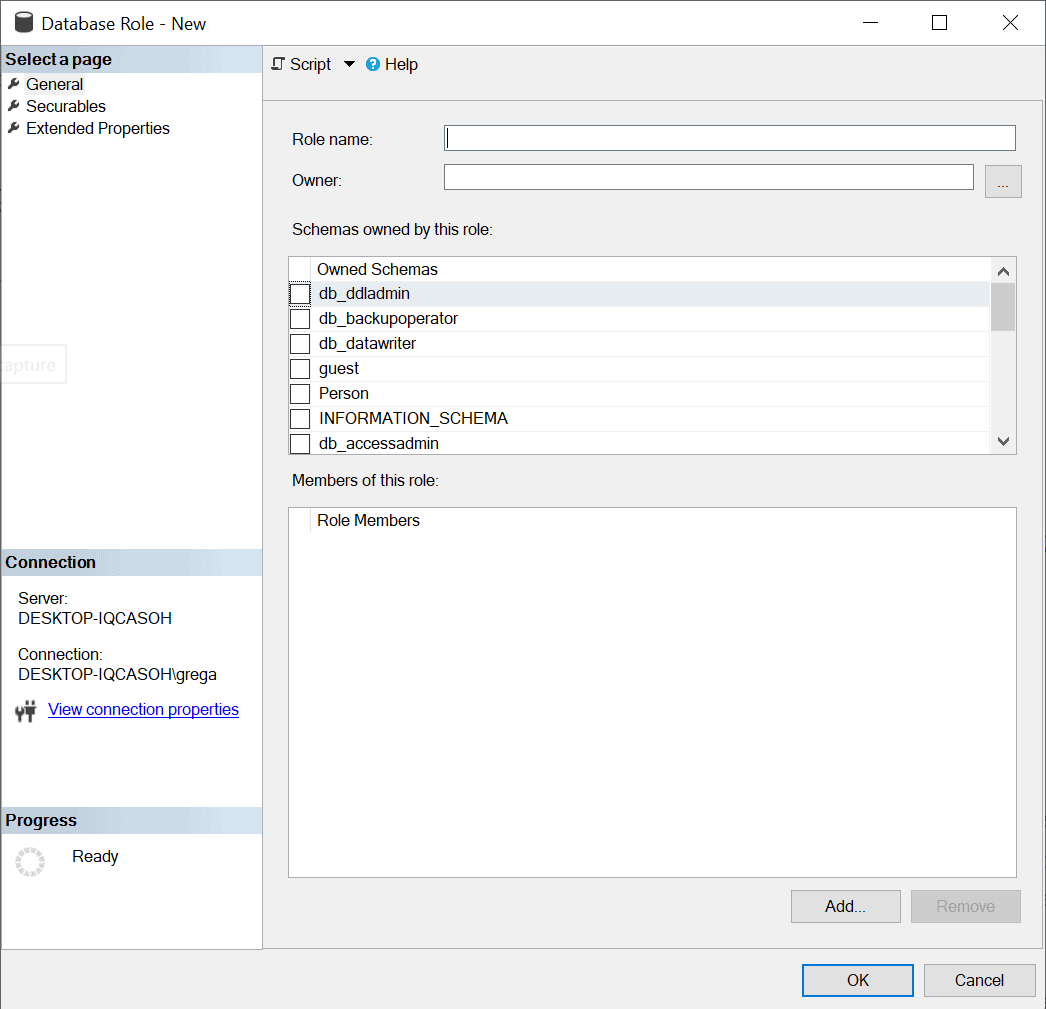
Figure 3: New Database Role Window
With the General tab selected on the left, I will enter SalesManager in the Role name field on the right. Since I want dbo to own this new role, I enter dbo in the owner field. To add members to this role, I click on the Add button. Doing this brings up the Select Database User or Role window, where I will then use the Browse button to select Sally to be added as a member to this new role, as shown in Figure 4.
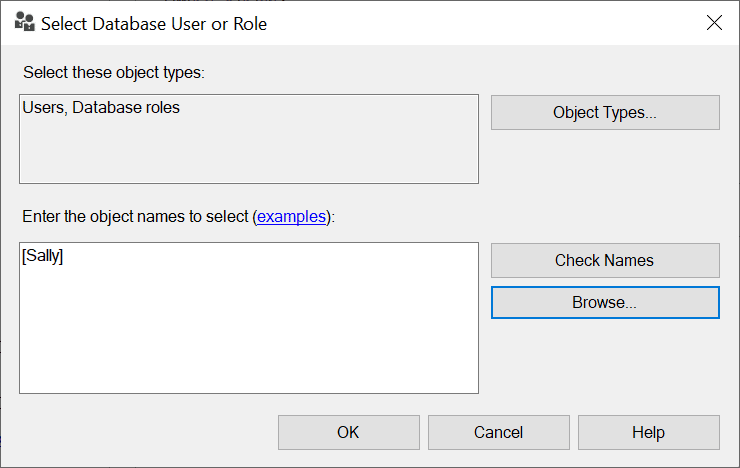
Figure 4: Adding Sally as a member
To finish adding Sally as a member to this new role definition, I click on the OK button. Upon doing this, the window in Figure 5 is displayed.
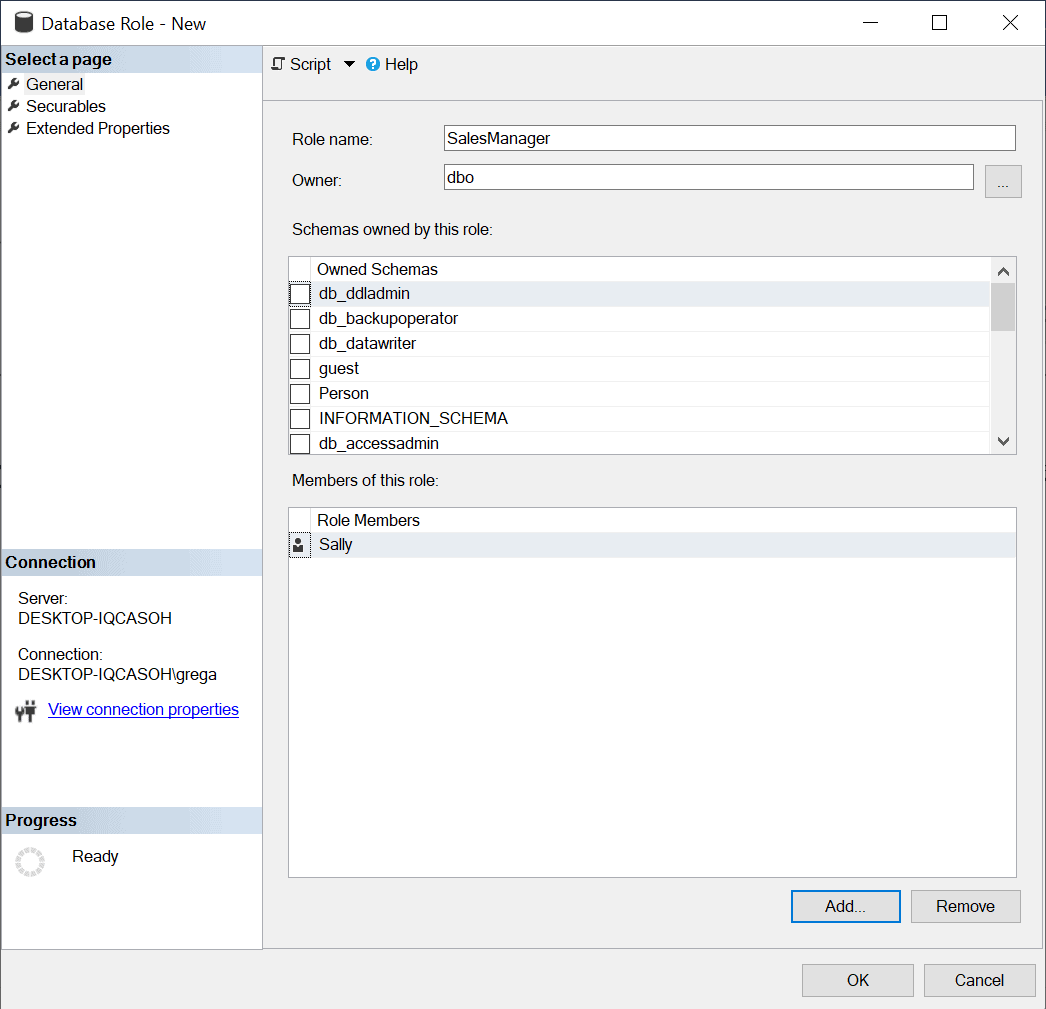
Figure 5: New Database Role with Sally as a member
To finish creating this role, I click on the OK button. At this point, all I’ve done is create a new role named SalesManager that has Sally as the sole member of this role. Alternatively, I could have used the script in Listing 6 to create the SalesManager role.
Listing 6: Creating SalesManager role with Sally as a member
USE [AdventureWorks2019]; GO CREATE ROLE [SalesManager] AUTHORIZATION [dbo]; GO ALTER ROLE [SalesManager ADD MEMBER [Sally]; GO
To finish setting up this role, I will need to grant permissions. Since the SalesManager needs to be able to manage all resources in the database, I will give this role the same permissions as the fixed database role db_owner. The easiest way to accomplish this is to make the SalesManager role a member of the db_owner fixed database role, which is accomplished by running the code in Listing 7.
Listing 7: Adding SalesManger roles as a member of the db_owner role
USE [AdventureWorks2019] GO ALTER ROLE [db_owner] ADD MEMBER [SalesManager] GO
The next security profile to set up for my hypothetical application is ProductionControl. User Dick will be a member of this role, and the role needs to have SELECT, INSERT, UPDATE, and DELETE rights to all tables in the Production Schema, as well as need read access to all tables in the AdventureWorks2019 database. To create this role, add Dick as a member, and provide the necessary permissions, I will run the code in Listing 8.
Listing 8: Setting up the ProductionControl user-defined database role
USE [AdventureWorks2019]; GO CREATE ROLE [ProductionControl] AUTHORIZATION [dbo]; GO ALTER ROLE [ProductionControl] ADD MEMBER [Dick]; GO GRANT DELETE ON SCHEMA::[Production] TO [ProductionControl]; GRANT INSERT ON SCHEMA::[Production] TO [ProductionControl]; GRANT SELECT ON SCHEMA::[Production] TO [ProductionControl]; GRANT UPDATE ON SCHEMA::[Production] TO [ProductionControl]; GO ALTER ROLE [db_datareader] ADD MEMBER [ProductionControl]; GO
The final security profile I need to set up for my hypothetical application is SalesPerson. For this security profile, I will be created a user-defined database role name SalesPerson. I will add the database user Tom as a member to this role. This role will need SELECT, INSERT, UPDATE, and DELETE permissions to all tables in the Sales schema and will need read access to all tables in the AdventureWorks2019 database. To create this role and all the necessary permissions, I will run the script in Listing 9.
Listing 9: Creating the SalesPerson user-defined role
USE [AdventureWorks2019]; GO CREATE ROLE [SalesPerson] AUTHORIZATION [dbo]; GO ALTER ROLE [SalesPerson] ADD MEMBER [Tom]; GO GRANT DELETE ON SCHEMA::[Sales] TO [SalesPerson]; GRANT INSERT ON SCHEMA::[Sales] TO [SalesPerson]; GRANT SELECT ON SCHEMA::[Sales] TO [SalesPerson]; GRANT UPDATE ON SCHEMA::[Sales] TO [SalesPerson]; GO ALTER ROLE [db_datareader] ADD MEMBER [SalesPerson]; GO
By using database roles for each of these different security profiles, I can now easily provide similar permissions to any new database users that might need any one of these security profiles. To give a new database user the same permissions as what either Tom, Dick, or Sally have, all that would be needed is to make them a member of the appropriate user-defined role. Having the permissions to database objects in a user-defined role simplifies the amount of security work a DBA needs to do and ensures two database users have the same security permissions provided they are in the same user-defined database role.
Security Profiles Using User-Defined Roles
User-defined roles is a great way to provide the same security setup to multiple logins or database users that need the same security requirements. With user-defined roles, you set it up once, and then each time someone needs the same rights as the role, you just make them a member of the role. When a user is a member of a role, they inherit the permission associated with the role. User-defined roles minimize the administration work while ensuring members have the same security permission. If you have an application that is used by many users and requires different security profiles for different groups of users, then user-defined roles are the best way to set up and administer these different security profiles.
The post SQL Server security – Providing a security model using user-defined roles appeared first on Simple Talk.
from Simple Talk https://ift.tt/3aGAmvp
via
 great. Let’s talk a bit about the story of this conference and I hope this story can provide it’s 2 cents to the build of our new era, at least starting many discussions about do’s and don’ts on new era conferences. Specially for community members and event organizers, I believe it will worth reading.
great. Let’s talk a bit about the story of this conference and I hope this story can provide it’s 2 cents to the build of our new era, at least starting many discussions about do’s and don’ts on new era conferences. Specially for community members and event organizers, I believe it will worth reading. When the pandemic hit us and SQL Saturdays became virtual, that was Malta’s chance. A virtual SQL Saturday. I filled the request and waited. That’s when things got worse and
When the pandemic hit us and SQL Saturdays became virtual, that was Malta’s chance. A virtual SQL Saturday. I filled the request and waited. That’s when things got worse and  When the community was focused on in-person conferences, it made total sense for the speakers to build a set of some sessions, 5 or not much more, and repeat these sessions in different conferences around the world, spreading the technical knowledge.
When the community was focused on in-person conferences, it made total sense for the speakers to build a set of some sessions, 5 or not much more, and repeat these sessions in different conferences around the world, spreading the technical knowledge. It reminds me something from the past. Most universities in Brazil are used to a yearly conference called Tech Week. The classes in the entire week are replaced by technical presentations delivered by people from the market. I delivered technical sessions on many of these conferences and I started thinking about: How could I use this opportunity to bring something more than just similar sessions every year ? How could I use this opportunity to create a learning progress among the conferences, something from beginning to expert?
It reminds me something from the past. Most universities in Brazil are used to a yearly conference called Tech Week. The classes in the entire week are replaced by technical presentations delivered by people from the market. I delivered technical sessions on many of these conferences and I started thinking about: How could I use this opportunity to bring something more than just similar sessions every year ? How could I use this opportunity to create a learning progress among the conferences, something from beginning to expert? This was the main challenge, cut throw the marketing noise of lots of conferences around the world.
This was the main challenge, cut throw the marketing noise of lots of conferences around the world.