The series so far:
- Text Mining and Sentiment Analysis: Introduction
- Text Mining and Sentiment Analysis: Power BI Visualizations
- Text Mining and Sentiment Analysis: Analysis with R
- Text Mining and Sentiment Analysis: Oracle Text
The fourth article of the series will focus on leveraging Oracle Text features in Oracle Database to perform sentiment analysis.
The first three articles of this series covered Sentiment Analysis using tools and services in the Microsoft ecosystem: Azure cognitive services and Power BI. This article will explore the Text features in an Oracle Database to perform Sentiment Analysis. The approach demonstrated in this article is useful in environments where the Oracle platform, tools, and technologies are predominantly used. Several organizations have not fully embraced the use of the public cloud for various reasons. This approach is suitable when using the public cloud may not be feasible in your organization.
Oracle Text feature has been available since Oracle Database release 12c. It provides indexing, word and theme searching, sentiment analysis, and document classification capabilities. According to Oracle documentation “Oracle Text can perform linguistic analysis on documents, as well as search text using a variety of strategies including keyword searching, context queries, Boolean operations, pattern matching, mixed thematic queries, HTML/XML section searching, and so on. It can render search results in various formats including unformatted text, HTML with term highlighting, and original document format. Oracle Text supports multiple languages and uses advanced relevance-ranking technology to improve search quality. Oracle Text also offers advanced features like classification, clustering, and support for information visualization metaphors”.
This article will focus on performing sentiment analysis using Oracle Text. Oracle Application Developer’s guide describes this as “Oracle Text enables you to perform sentiment analysis for a topic or document by using sentiment classifiers that are trained to identify sentiment metadata. Sentiment analysis is the process of identifying and extracting sentiment metadata about a specified topic or entity from a set of documents. Trained sentiment classifiers identify the sentiment. When you run a query with sentiment analysis, in addition to the search results, sentiment metadata (positive or negative sentiment) is also identified and displayed”.
In Oracle Text, a sentiment classifier is a specific type of document classifier that is used to extract sentiment metadata. Oracle text provides a default sentiment classifier (unsupervised). If you have suitable training data, Oracle Text also gives you the ability to train your own sentiment classifiers.
Please note that this article uses the Oracle Database Application Development virtual machine, running on a windows host for the demo.
Initial setup
- Download and install VirtualBox by following instructions listed on VirtualBox website.
- Download and set up Oracle Database Virtual Box Appliance / Virtual Machine by following instructions listed on the Oracle website.
- Start up the Virtual Machine and ensure SQL Developer is available on the desktop screen. Please note that you may need to create a free account to download the Virtual Machine.
![Oracle DB Developer VM [Running] - Oracle VM VirtualBox](https://www.red-gate.com/simple-talk/wp-content/uploads/2021/08/oracle-db-developer-vm-running-oracle-vm-virtu.png)
Figure 1. Oracle Database Developer Virtual Machine
- This article uses the same Excel file raw data from previous articles, available on my GitHub repository. Please download and save this file at a convenient location on your Virtual Machine
Set up an Oracle Text User
Set up a user with the CTXAPP role, enabling you to work with Oracle Text indexes and use Oracle Text PL/SQL packages.
- On the Virtual Machine, launch the Oracle SQL Developer application. Under the Connections menu, click on system >. When prompted for credentials, enter sys as sysdba in the username field and oracle in the password field.
- When a new worksheet opens, run this query
select * from v$database ;. From the query result, verify the value under the NAME column is ORCLDB. You may also run the queryselect user from dualto verify the username of the current connection. It is important to verify this, as the subsequent steps for setting up the Oracle Text user need to be performed as the system administrator. The screenshot below unions the two queries for simplicity of display.
![Oracle DB Developer VM [Running] - Oracle VM VirtualBox](https://www.red-gate.com/simple-talk/wp-content/uploads/2021/08/oracle-db-developer-vm-running-oracle-vm-virtu-1.png)
Figure 2. Use Oracle SQL Developer to connect to ORCLDB database as “SYS” user
- Run the following SQL statement to create user redgatedemo.
CREATE USER redgatedemo IDENTIFIED BY mydemopassword;
Upon successful execution, you should see the message User REDGATEDEMO created.
- Run the following SQL statements to grant user redgatedemo the roles necessary for connecting and using database and CTXAPP resources. The CTXAPP role includes execute privileges on various CTX PL/SQL packages.
GRANT RESOURCE, CONNECT, CTXAPP TO redgatedemo; GRANT UNLIMITED TABLESPACE TO redgatedemo;
Upon successful execution, you should see the message Grant succeeded.
Import raw data file in Oracle Table
Click the green plus sign under Connections to open the New / Select Database Connection dialog. Connect to the Oracle Database with user redgatedemo as shown in Figure 3.
![Oracle DB Developer VM [Running] - Oracle VM VirtualBox](https://www.red-gate.com/simple-talk/wp-content/uploads/2021/08/oracle-db-developer-vm-running-oracle-vm-virtu-2.png)
Figure 3. Connect to Oracle database with redgatedemo user
- Run the following SQL to create a table, with a unique index and primary key.
-- Create a Table to load text data
CREATE TABLE REDGATEDEMO.DEMO_SENTIMENTANALYSIS_TEAMHEALTH
(
ID NUMBER GENERATED ALWAYS AS IDENTITY
,PERIOD VARCHAR2( 500 ) NOT NULL
,MANAGER VARCHAR2( 500 ) NOT NULL
,TEAM VARCHAR2( 500 ) NOT NULL
-- this will store raw text of survey response
,RESPONSE VARCHAR2( 4000 ) NOT NULL
,DW_CREATION_DATE DATE DEFAULT SYSDATE
);
-- create a unique index
CREATE UNIQUE INDEX REDGATEDEMO.DEMO_SENTIANALYSIS_TEAMHEALTH_PK
ON REDGATEDEMO.DEMO_SENTIMENTANALYSIS_TEAMHEALTH(ID )
ONLINE;
-- create a primary key
ALTER TABLE REDGATEDEMO.DEMO_SENTIMENTANALYSIS_TEAMHEALTH
ADD CONSTRAINT DEMO_SENTIANALYSIS_TEAMHEALTH_PK PRIMARY KEY
(ID )
USING INDEX REDGATEDEMO.DEMO_SENTIANALYSIS_TEAMHEALTH_PK ENABLE VALIDATE;
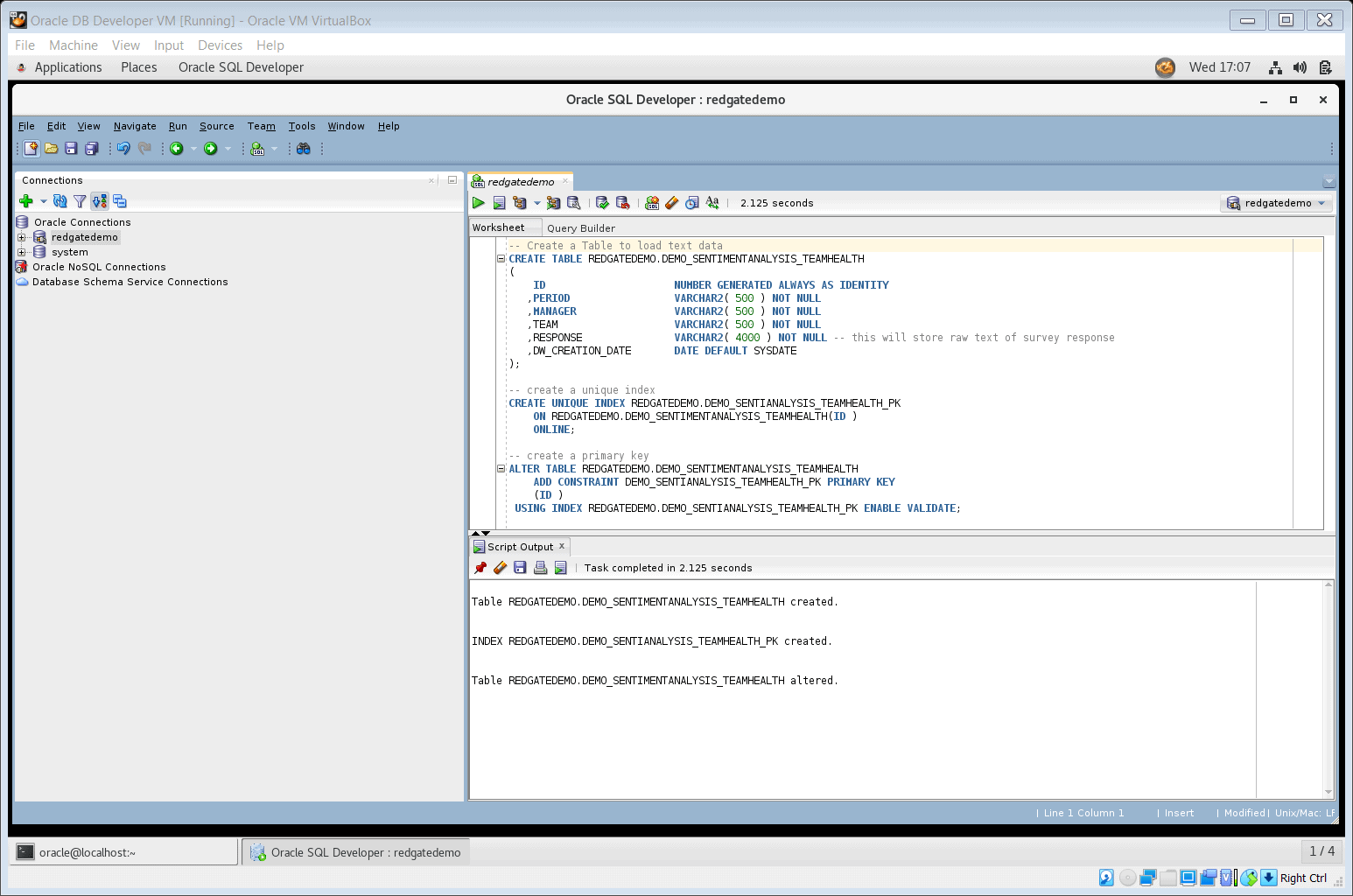
Figure 4. Create table to load text data
- If you haven’t already, download the Excel file from the Github repo and save it to a convenient location on the Virtual Machine
- In Oracle SQL Developer, under the left side connection menu, navigate to Oracle Connections > redgatedemo > Tables > DEMO_SENTIMENTANALYSIS_TEAMHEALTH. Right click on this table and select Import Data
![Oracle DB Developer VM [Running] - Oracle VM VirtualBox Import data](https://www.red-gate.com/simple-talk/wp-content/uploads/2021/08/oracle-db-developer-vm-running-oracle-vm-virtu-4.png)
Figure 5. Launch the Data Import Wizard
- This will launch Data Import Wizard. Use this easy-to-follow five-step wizard to load the previously downloaded Excel file into the Oracle database table – REDGATEDEMO.DEMO_SENTIANALYSIS_TEAMHEALTH
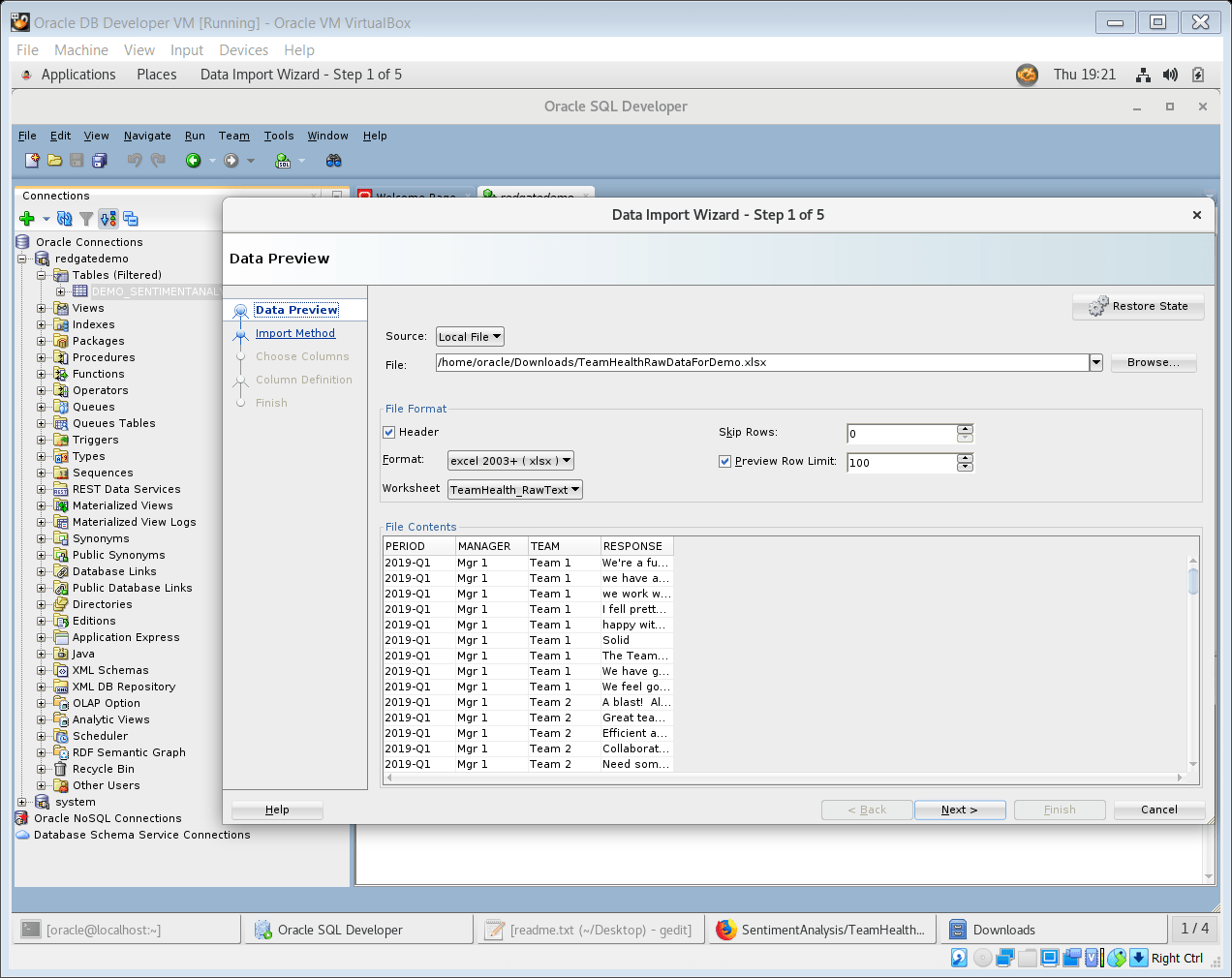
Figure 6. Step 1 of the Data Import Wizard
Please note Step 3 of the Data Import Wizard is Choose columns. Please ensure you have selected only the four columns Period, Manager, Team, and Response to import. Sometimes you may see a long list of empty excel columns with headings like column5, column6, etc. under the Available columns section of the wizard, which should not be imported.
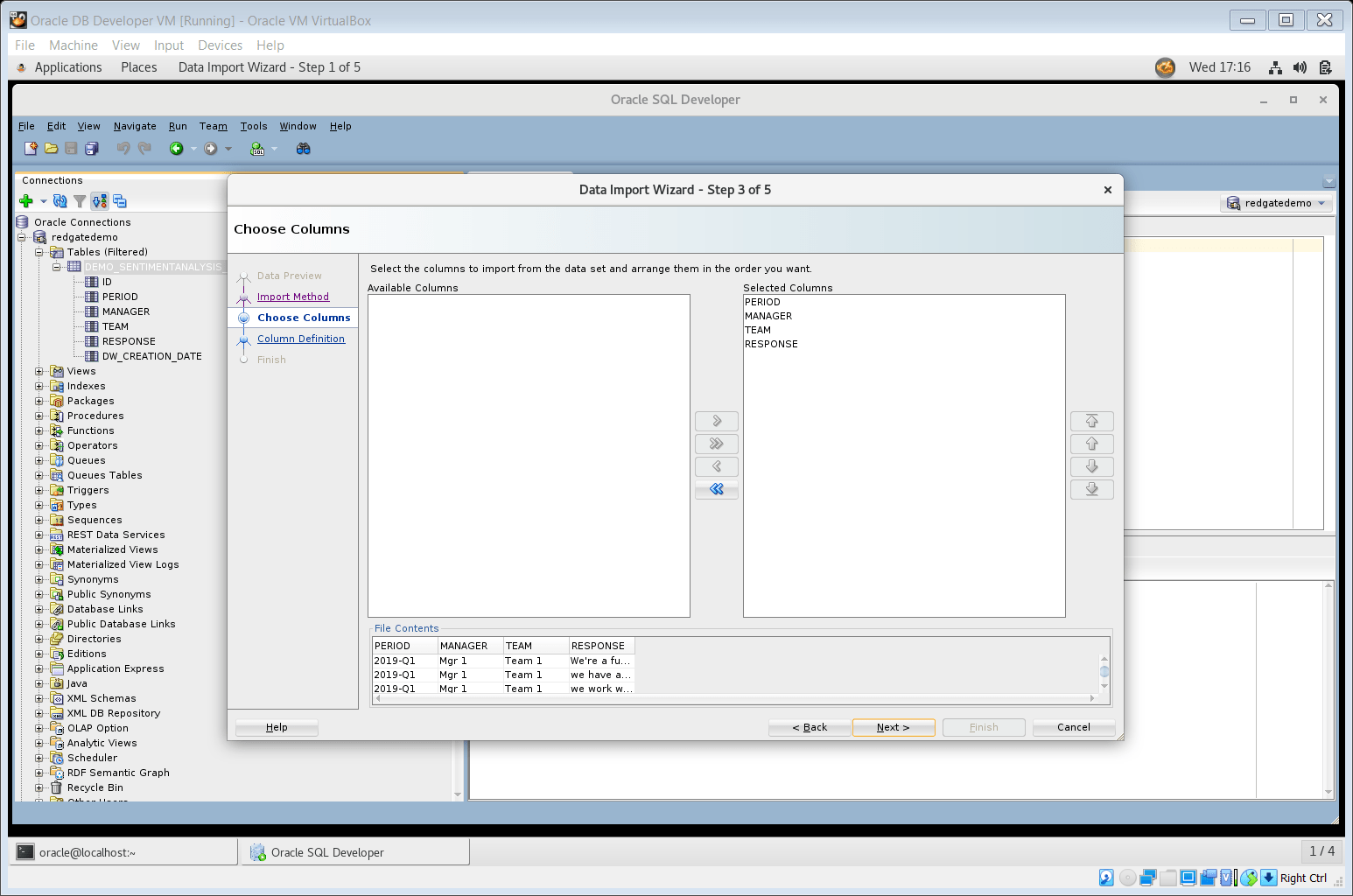
Figure 7. Step 3 of the Data Import Wizard (select columns to import)
The wizard will display a success message upon completion
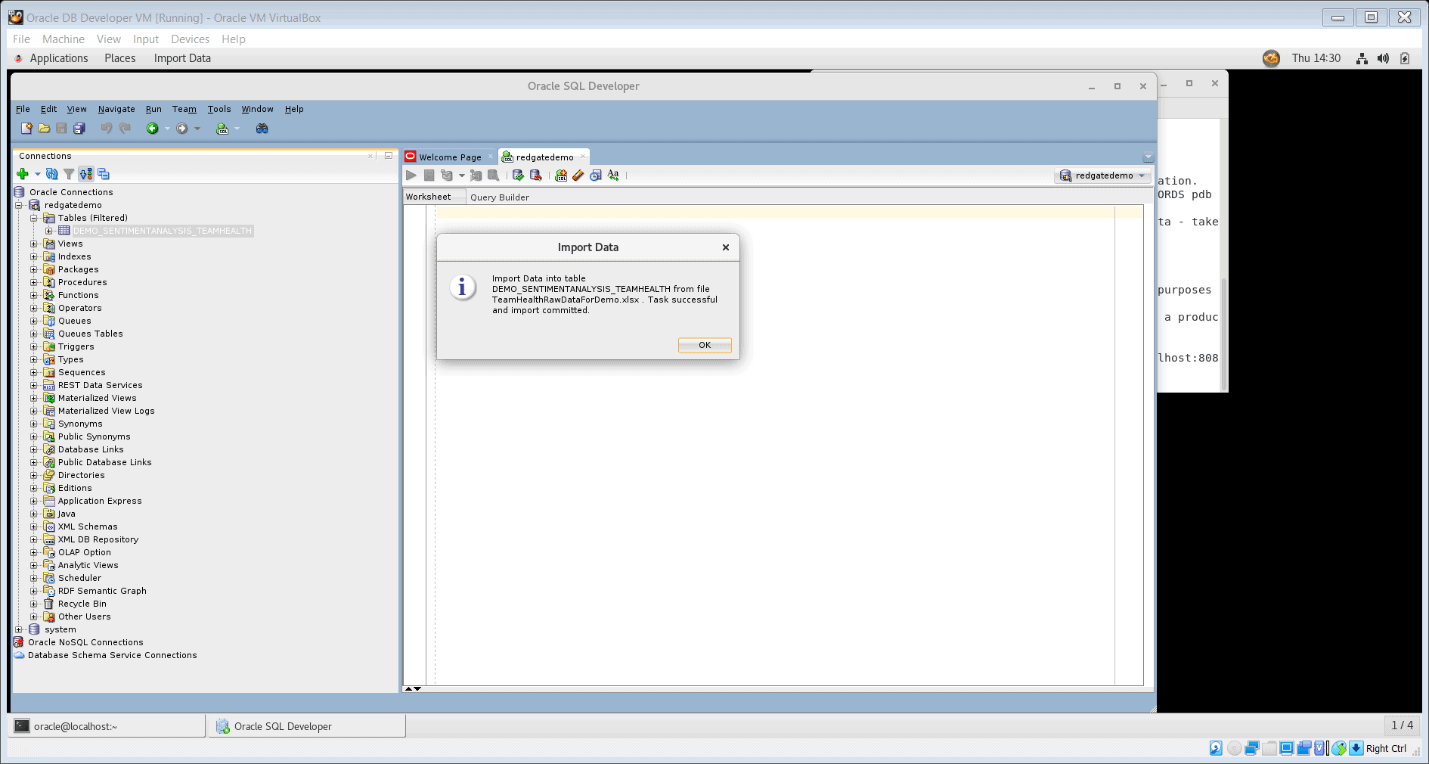
Figure 8. Data Import wizard completed successfully
Sentiment Classifier in Oracle text
In Oracle Text, a sentiment classifier is a specific type of document classifier that can extract sentiment metadata from a document. To use a sentiment classifier, it is first associated with a sentiment classifier preference, then trained.
Oracle documentation describes a sentiment classifier preference as “It specifies the parameters that are used to train a sentiment classifier. These parameters are defined as attributes of the sentiment classifier preference. You can either create a sentiment classifier preference or use the default”. The default sentiment classifier is CTXSYS.DEFAULT_SENTIMENT_CLASSIFIER. The CTX_DDL.CREATE_PREFERENCE procedure is used to create a user-defined sentiment classifier preference and the CTX_DDL.SET_ATTRIBUTE procedure is used to specify its parameters.
Oracle Text provides a default sentiment classifier, a pre-trained out-of-the-box model that works well for most general-purpose sentiment analysis applications. It leverages an AUTO_LEXER that performs language identification, word segmentation, document analysis, part-of-speech tagging, and stemming. In the world of text processing and analysis, a lexer reads an input text and breaks it down into tokens using language-specific grammar rules. The lexer generates a stream of tokens as output. Oracle’s AUTO_LEXER supports several languages and is most commonly used due to its ability to detect the language automatically. The default sentiment classifier is ideal for use in scenarios where a labeled training dataset is not available, and your sentiment classification needs are general purpose in nature (for example, social media posts, Google and Yelp reviews, etc.)
Oracle Text also provides the ability to create your own user-defined sentiment classifiers. To train your own sentiment classifier, a user needs an associated sentiment classifier preference, a training set of documents, and the target sentiment categories. The CTX_CLS.SA_TRAIN procedure is used to train a sentiment classifier. During training, a user assigns each sample document to a category, which Oracle Text uses to infer rules for how to perform sentiment analysis. This technique is an example of supervised machine learning and relies on suitable training data. You may need to train your own sentiment classifier if the default classifier does not meet the needs of your use-case (for example, complex text in a domain that needs deep subject matter understanding like medicine, international law, etc.). Training a user-defined sentiment classifier is out of scope for this article. To learn how to train your a user-defined sentiment classifier in Oracle Text, please follow this link to Oracle documentation.
Performing Sentiment Analysis using the default classifier
The CTX_DOC PL/SQL package is a part of Oracle Text features and provides several functions and procedures for various document services, including Sentiment. The following steps demonstrate the use of the CTX_DOC package for performing sentiment analysis, using the unsupervised technique (with default sentiment classifier and sentiment classifier preference)
- Run the following SQL statement to create a sentiment classifier preference demoautolexer of type AUTO_LEXER. Oracle Text will default values for attributes that are not explicitly defined. Please note that the type AUTO_LEXER should be used only for the default classifier. When training a user-defined classifier, always use the type SENTIMENT_CLASSIFIER.
exec ctx_ddl.create_preference('demoautolexer','AUTO_LEXER');
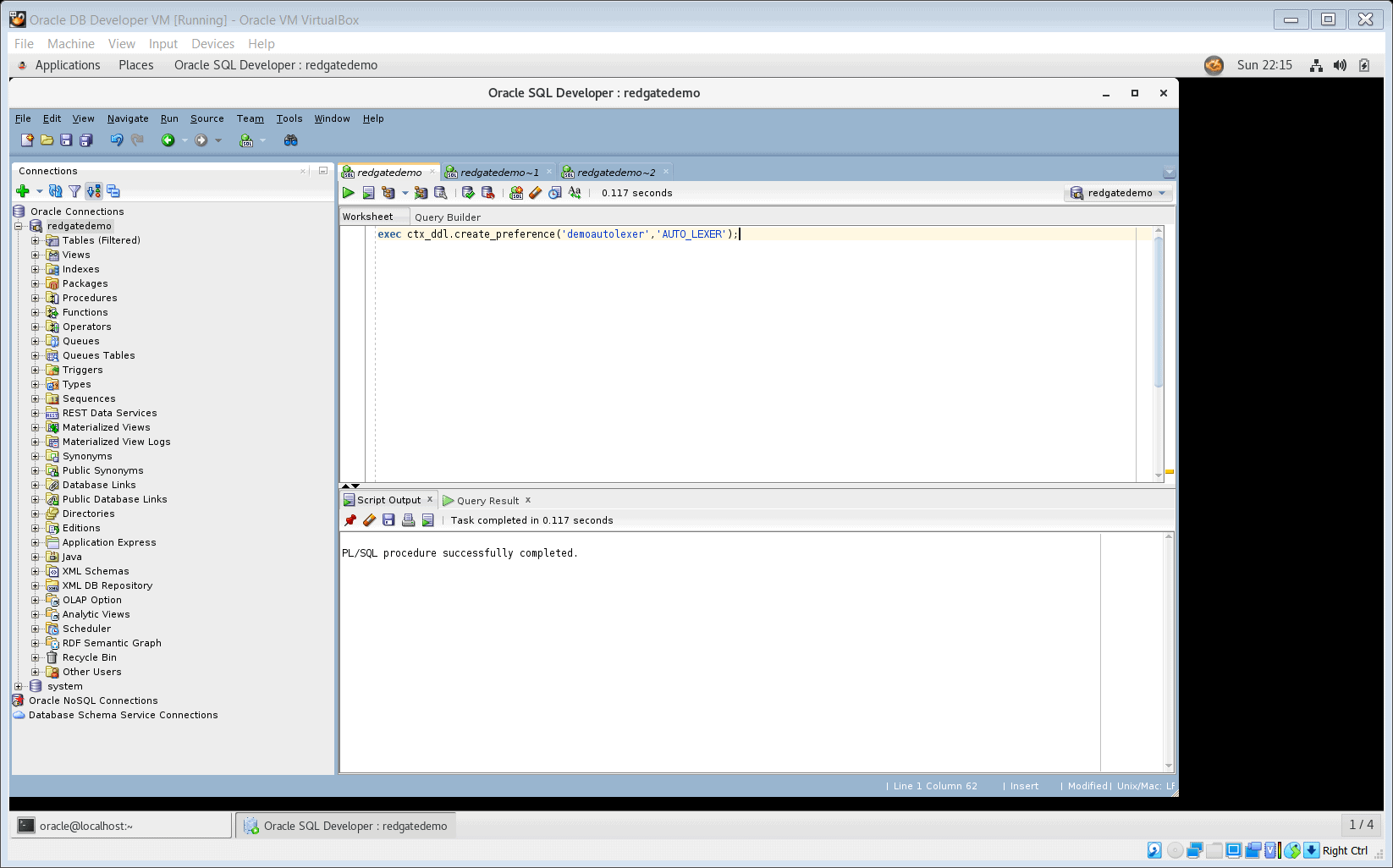
Figure 9. create a sentiment classifier preference of type AUTO_LEXER
- Run the following SQL statement to create a context index on the document set (table with text data). The context parameters for this index specify the use of
AUTO_LEXERand defaultstoplist. A stoplist refers to the list of most common words in a particular language, which are usually removed before processing natural language data. This step may take a few minutes to complete.
create index DEMO_SENTIMENTANALYSIS_TEAMHEALTH_TXTIDX
on DEMO_SENTIMENTANALYSIS_TEAMHEALTH(RESPONSE) indextype is
ctxsys.context parameters
('lexer demoautolexer stoplist ctxsys.default_stoplist');
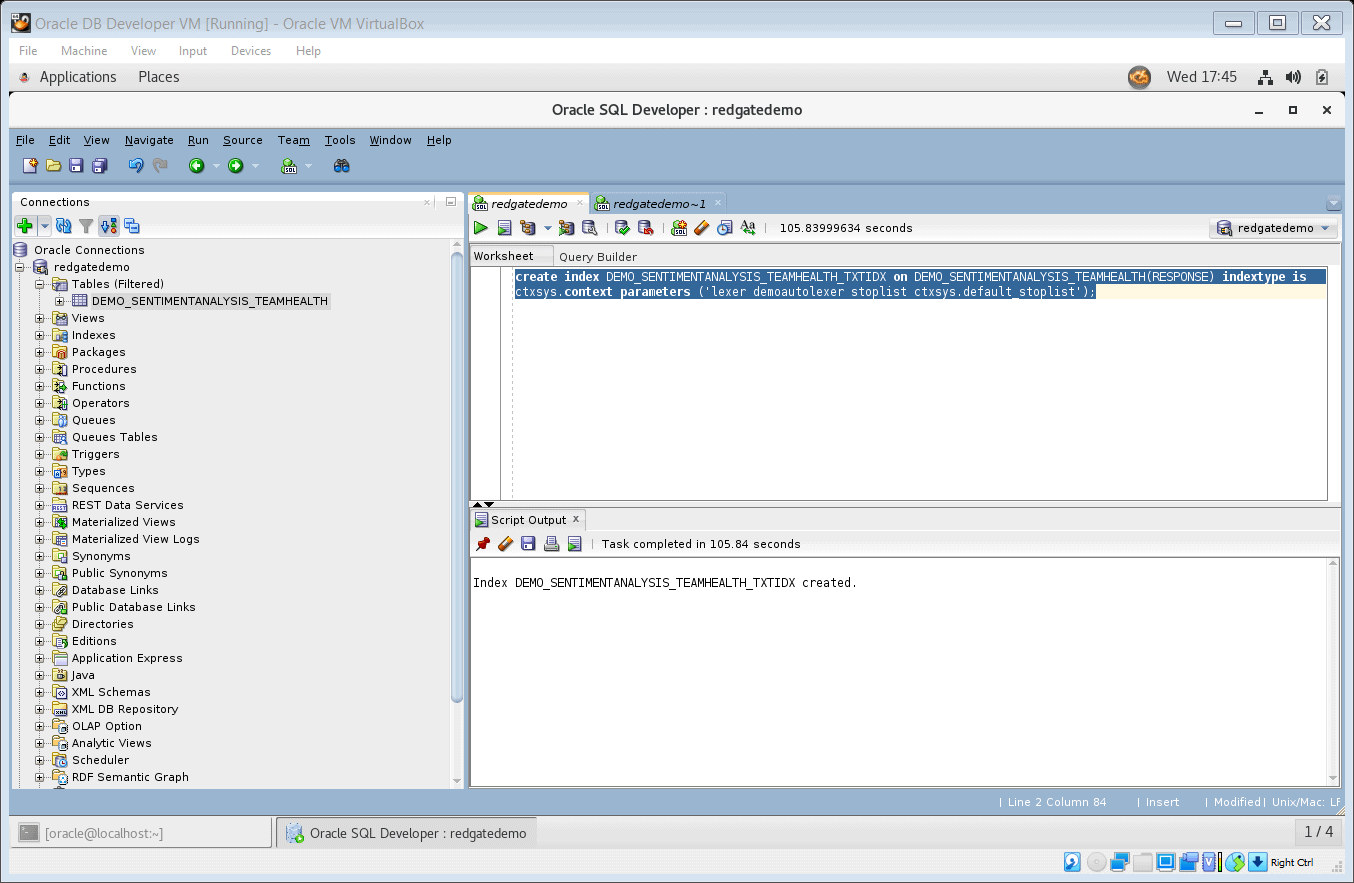
Figure 10. Create text index
- You can now use this text index in a select statement using the
SENTIMENT_AGGREGATEmethod of the CTX_DOC package. This method takes a document id as input, which in this example is theIDfield (the primary key of table DEMO_SENTIMENTANALYSIS_TEAMHEALTH).
Oracle documentation describes the output of theCTX_DOC.SENTIMENT_AGGREGATE procedure as “a single consolidated sentiment score for the document. The sentiment score is a value in the range of -100 to 100, and it indicates the strength of the sentiment. A negative score represents a negative sentiment, and a positive score represents a positive sentiment. Based on the sentiment scores, you can group scores into labels such as Strongly Negative (–80 to –100), Negative (–80 to –50), Neutral (-50 to +50), Positive (+50 to +80), and Strongly Positive (+80 to +100).”
Run the following SQL statement to see the sentiment scores document id = 3 (Row with ID = 3):
SELECT ctx_doc.sentiment_aggregate('DEMO_SENTIMENTANALYSIS_TEAMHEALTH_TXTIDX','3') from dual;
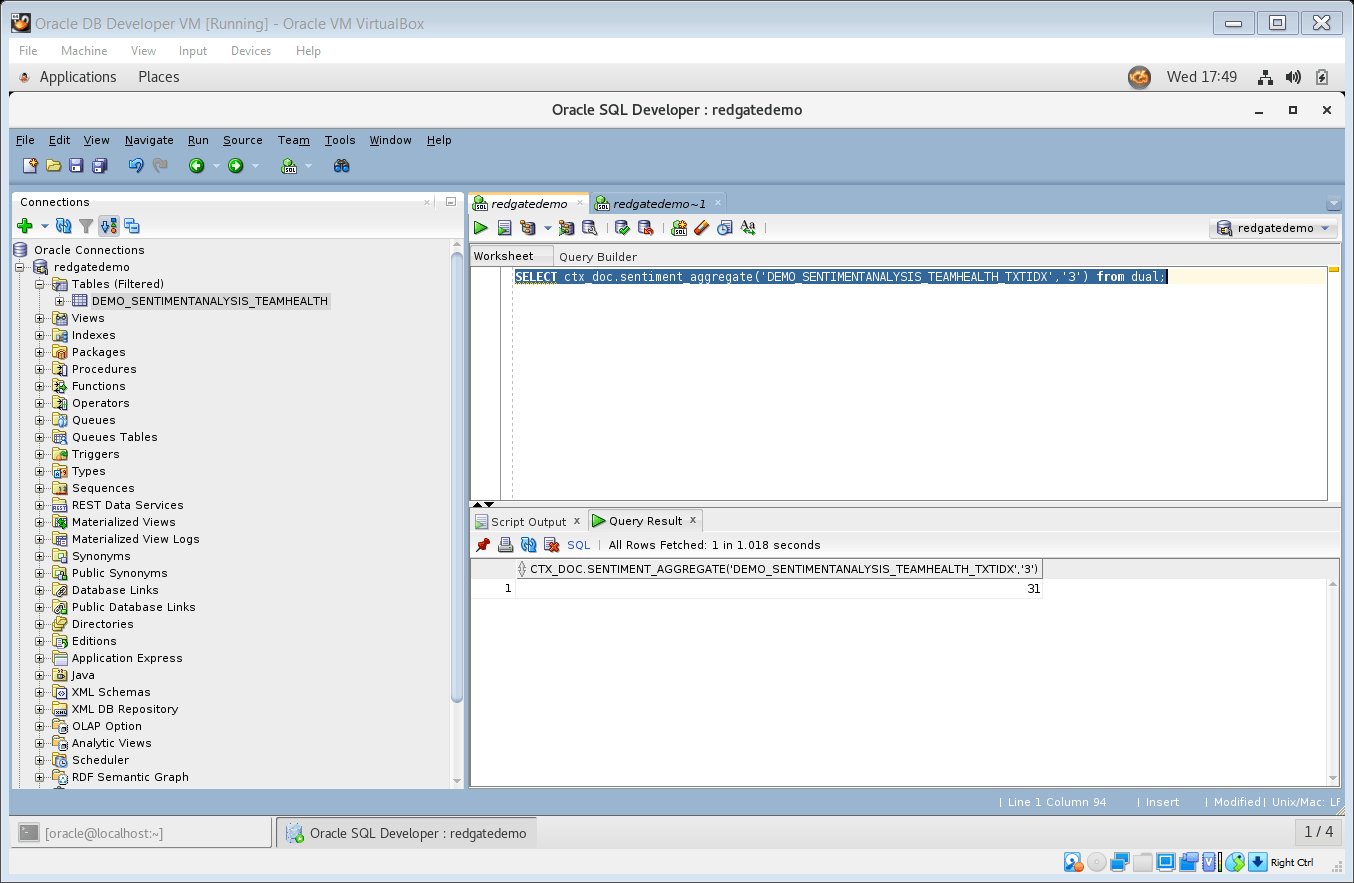
Figure 11. Use ctx_doc.sentiment_aggregate to generate sentiment score for document id = 3
- Run the following SQL statement to see the text as well as sentiment scores for document ids 3 and 4.
SELECT TO_CHAR(ID) DOC_ID, RESPONSE FROM DEMO_SENTIMENTANALYSIS_TEAMHEALTH WHERE ID = 3
UNION ALL
select 'Sentiment Score -> ', TO_CHAR(ctx_doc.sentiment_aggregate('DEMO_SENTIMENTANALYSIS_TEAMHEALTH_TXTIDX','3')) from dual
UNION ALL
SELECT TO_CHAR(ID) DOC_ID, RESPONSE FROM DEMO_SENTIMENTANALYSIS_TEAMHEALTH WHERE ID = 4
UNION ALL
select 'Sentiment Score -> ', TO_CHAR(ctx_doc.sentiment_aggregate('DEMO_SENTIMENTANALYSIS_TEAMHEALTH_TXTIDX','4')) from dual
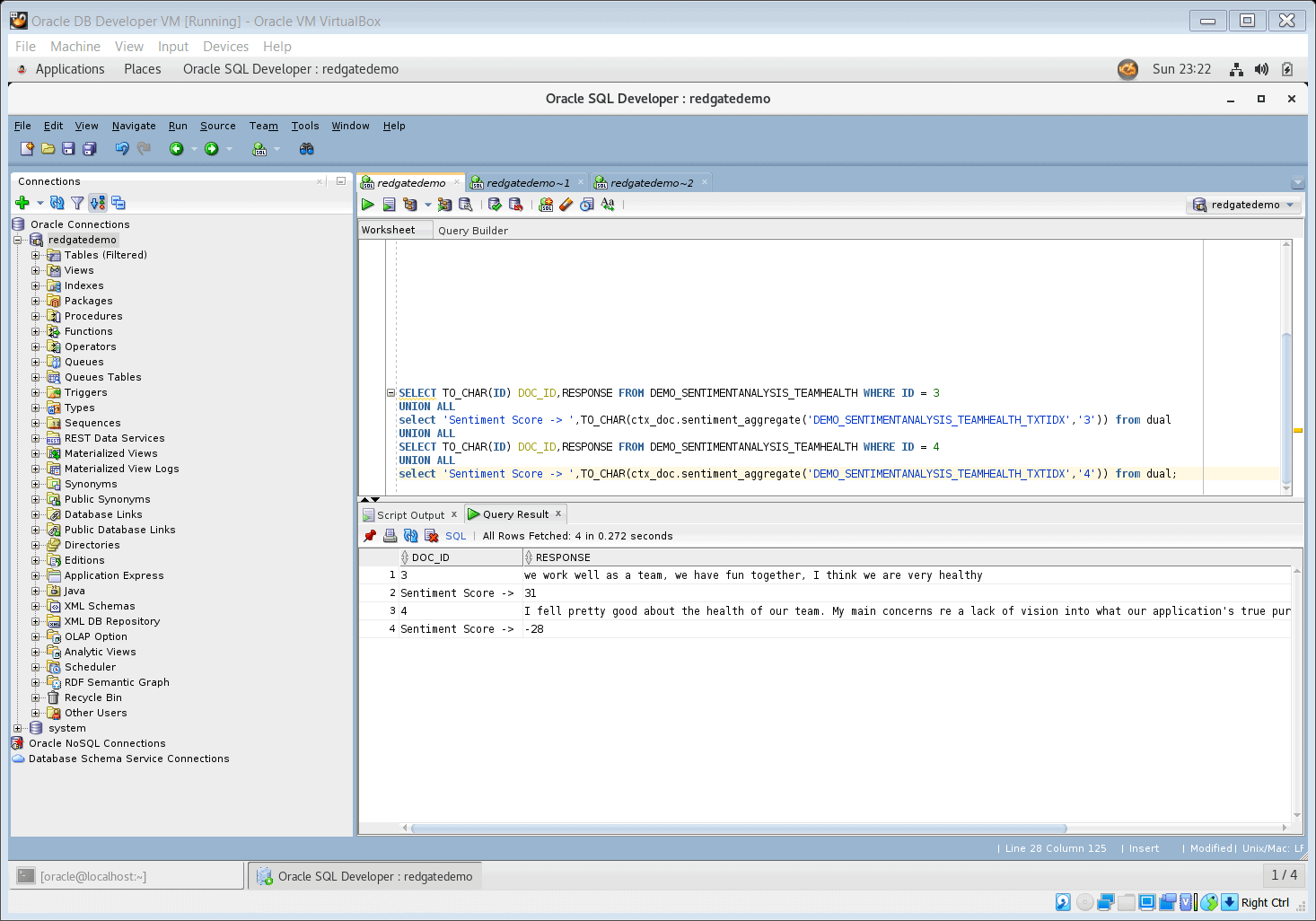
Figure 12. SQL statement to select text and its sentiment score
The results of this SQL statement can be interpreted as:
- The sentiment for document id 3 with the text “we work well as a team, we have fun together, I think we are very healthy” is 31, which falls within the Neutral range of -50 to +50
- The sentiment for document id 4 with text “I fell pretty good about the health of our team. My main concerns re a lack of vision into what our application’s true purpose is and the future direction of our team.” is -28, which also falls in the within the Neutral range of -50 to +50 but is relatively more negative than the sentiment for document id 3. This is confirmed by human interpretation of the text.
A developer would run such SQL statement per document (per row in the table) using a looping operation weand wrapping it in a user-defined PL/SQL package.
Conclusion
This article demonstrated how to perform sentiment analysis with Oracle Text features available in an Oracle Database, using the default sentiment classifier that comes out of the box in Oracle. I highlighted the potential scenarios where the default sentiment classifier may not fulfill your needs, and you may have to train your own user-defined sentiment classifier. This article also helped readers get familiar with how to write a SQL statement to generate sentiment scores and interpret them to gain meaningful insights.
References:
- Introduction to Oracle Database – https://docs.oracle.com/cd/B19306_01/server.102/b14220/intro.htm
- What is Oracle Text –
- Import excel file into Oracle table using SQL Developer – https://www.thatjeffsmith.com/archive/2012/04/how-to-import-from-excel-to-oracle-with-sql-developer/
- Oracle AUTO_LEXER – https://docs.oracle.com/cd/E18283_01/text.112/e16593/cdatadic.htm#BHCGJHDH
- Oracle CTX_DOC package – https://docs.oracle.com/en/database/oracle/oracle-database/19/ccref/CTX_DOC-package.html#GUID-7A07AEB1-2647-468A-A071-A2443EF1A514
- Performing sentiment analysis with CTX_DOC package – https://docs.oracle.com/en/database/oracle/oracle-database/18/ccapp/performing-sentiment-analysis-using-oracle-text.html#GUID-B18361E3-7A3E-4AA7-B96E-80F99247986D
- Training user-defined sentiment classifiers – https://docs.oracle.com/en/database/oracle/oracle-database/18/ccapp/performing-sentiment-analysis-using-oracle-text.html#GUID-7F1B2D64-7F7F-436F-81D3-7C8D18E956BE
The post Text Mining and Sentiment Analysis: Oracle Text appeared first on Simple Talk.
from Simple Talk https://ift.tt/38p5gqz
via