The series so far:
- Getting started with MySQL
- Working with MySQL tables
Tables lie at the heart of any MySQL database, providing a structure for how data is organized and accessed by other applications. Tables also help to ensure the integrity of that data. The better you understand how to create and modify tables, the easier it will be to manage other database objects and the more effectively you can work with MySQL as a whole. Having a solid foundation in tables can also help you build more effective queries so that you’re retrieving the data you need (and only that data), without compromising database performance.
This article is the second in a series on MySQL. I recommend that you review the first article before launching into this one, if you haven’t done so already. In this article, I focus primarily on how to create, alter, and drop tables, demonstrating how to use both SQL statements and the GUI features in MySQL Workbench. As with the first article, I used the MySQL Community edition on a Windows computer to create the examples for this article. All the examples were created in Workbench, which comes with the Community edition.
Using the MySQL Workbench GUI to create a database
Before creating any tables, you need a database for those tables, so I’ll spend a little time on databases first. Creating a database in MySQL is a relatively straightforward process. As you saw in the first article in this series, you can run a simple CREATE DATABASE statement against the target MySQL instance where you want to add the database. This is especially easy if you plan to use the default collation and character set. For example, to create the travel database, you need only run the following statement:
CREATE DATABASE travel;
The CREATE DATABASE statement does exactly what it says. It creates a database on the MySQL instance that you’re connected to. If you want to make sure the database doesn’t exist before running the statement, you can add the IF NOT EXISTS clause:
CREATE DATABASE IF NOT EXISTS travel;
Both statements instruct MySQL to create a database that uses the default collation and character set. You can run either statement from the MySQL command prompt or from within MySQL Workbench. To run a statement in Workbench, you need only open a query tab, type, or paste the statement onto the tab, and click one of the execute buttons on the toolbar. MySQL does the rest.
Instead of using a CREATE DATABASE statement to create a database, you can use a CREATE SCHEMA statement. They both support the same syntax, and both achieve the same results. This is because MySQL treats databases and schemas as one in the same. In fact, MySQL considers CREATE SCHEMA to be a synonym for CREATE DATABASE. When you create a database, you create a schema. When you create a schema, you create a database. Workbench uses both terms, freely switching between one and the other.
You can also use the GUI features built into Workbench to create a database. Although this might seem overkill, given how easy it is to run a CREATE DATABASE statement, the GUI offers the advantage of listing all the character sets and collations available to a database definition, should you decide not to use the defaults.
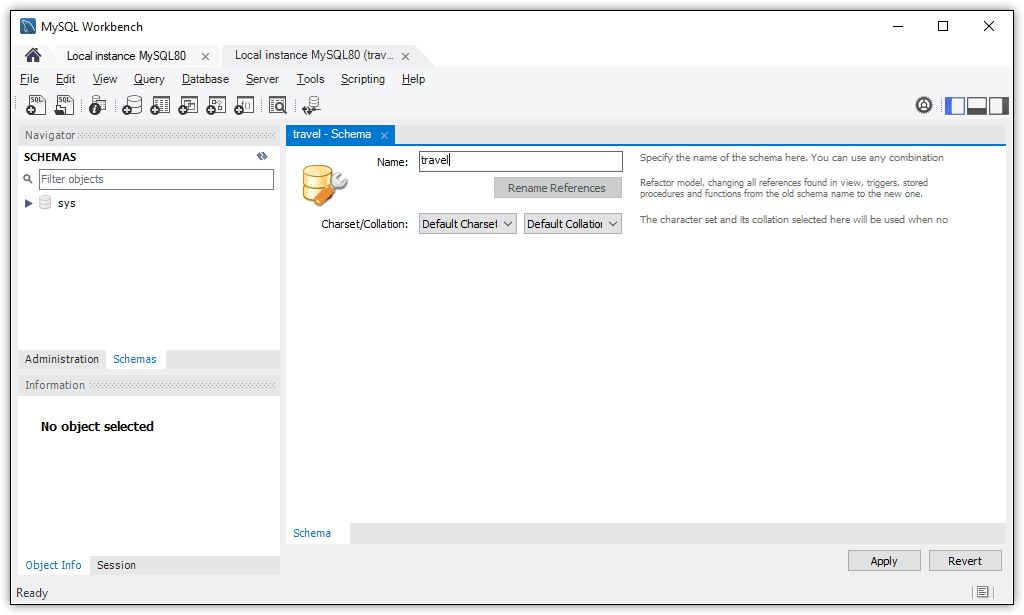
To use the GUI to create a database, start by clicking the create schema button on the Workbench toolbar. (The button looks like a standard database icon and displays the tooltip Create a new schema in the connected server.) When the Schema tab opens, you need only provide a database name, as shown in Figure 1.

Figure 1. Adding a database to a MySQL instance
If you want to use a character set or collation other than the defaults, you can select them from the drop-down lists. For example, you might select utf8 for the character set and utf8_unicode_ci for the collation.
With MySQL, you can set the character set and collation at multiple levels: server, database, table, column, or string literal. The default server character set is utf8mb4, and the default collation is utf8mb4_0900_ai_ci. Before deviating from the defaults, I suggest that you first review the MySQL documentation on character sets and collations.
The Schema tab also includes the Rename References option. However, this is disabled and applies only when you’re updating a database model. Workbench sometimes includes interface options that don’t apply to the current circumstances, which can be confusing when you’re first getting started with MySQL or Workbench. However, you’re usually safe to stick with the default values if you’re not sure about an option, at least until you better understand how it works and whether it’s even applicable.
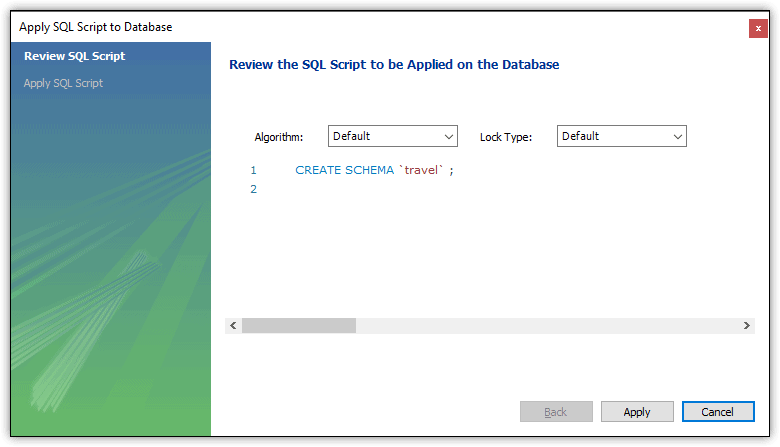
For this article (assuming that you want to follow along with the examples), you can stick with the default character set and collation and click Apply. This will launch the Apply SQL Script to Database wizard, shown in Figure 2. The wizard’s first screen displays the SQL statement that Workbench generated but not yet applied against the MySQL instance.
Figure 2. Verifying the CREATE SCHEMA statement
The screen also includes the Algorithm option and Lock Type option. Both options are related to MySQL’s online DDL feature, which provides support for in-place table alterations and concurrent DML. You do not need to be concerned about these options right now and can stick with the defaults. (This is another example of Workbench’s sometimes confusing options.) However, if you’re interested in learning more about these features, you can find information in the MySQL documentation that covers InnoDB and online DDL.
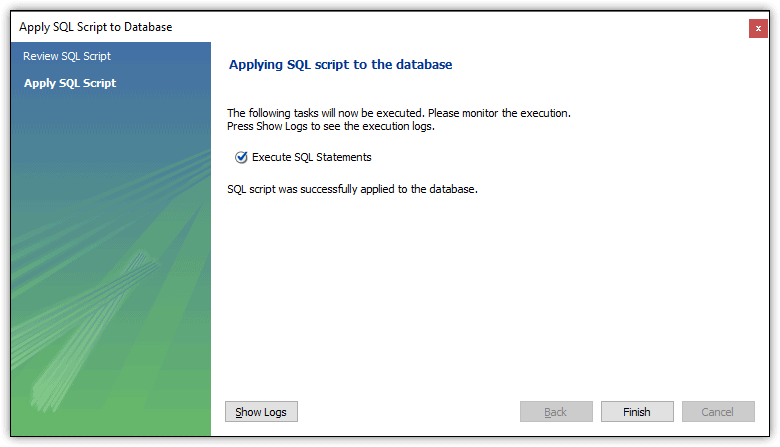
To create the database, click Apply, which takes you to the next screen, shown in figure 3. This screen essentially confirms that the database has been created. You can then click Finish to close the dialog box. Be sure to close the original Schema tab as well.
Figure 3. Finalizing the new schema (database)
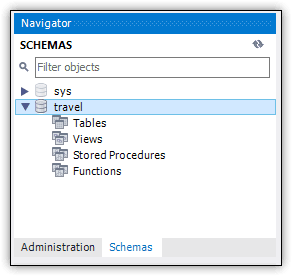
The database should now be listed in the Schemas panel in Navigator. If it is not, click the refresh button in the panel’s upper right corner. The travel database (schema) should then show up along with other databases on the MySQL instance. On my system, the only other database is the default sys database, as shown in Figure 4.
Figure 4. Viewing the new database in Navigator
At this point, MySQL has created only the database structure. You can now add tables to the database, along with views, stored procedures, and functions.
Using the MySQL Workbench GUI to create a table
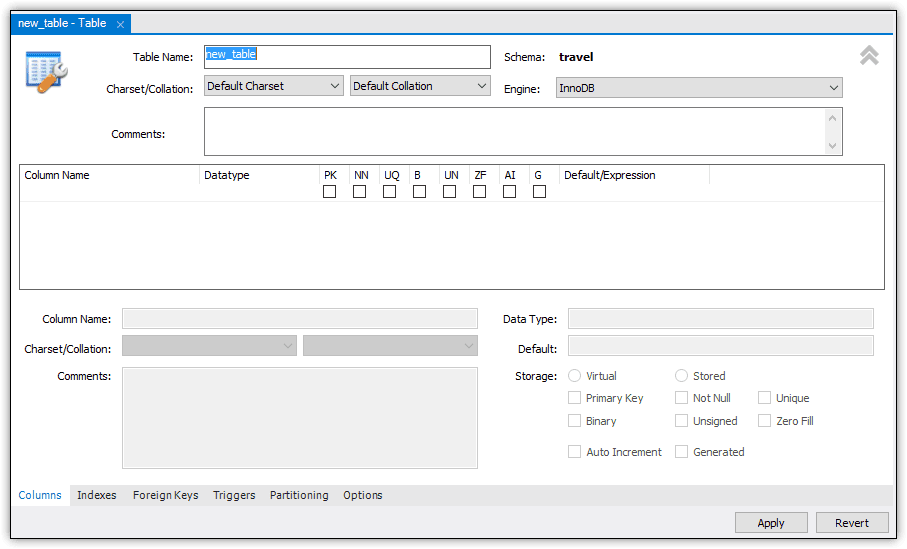
You can also use the Workbench GUI to add a table a database. For this approach, start by selecting the travel database node in Navigator. You might need to double-click the node to select it. The database name should be bold once selected. With the database selected, click the create table button on the Workbench toolbar. (The button looks like a standard table icon and includes the tooltip Create a new table in the active schema in connected server.) When you click the button, Workbench opens the Table tab, as shown in Figure 5.
Figure 5. Adding a table through the Workbench GUI
The tab provides a detailed form for adding columns to the table and configuring table and column options. The tab also includes several of its own tabs (near the bottom of the interface). The Columns tab is selected by default, which is where you’ll be doing most of your work.
Start by providing a name for the table. For this article, I used manufacturers. I also stuck with the default character set and collation, as well as the default storage engine, InnoDB. The InnoDB engine is considered a good general-purpose storage engine that balances high reliability and high performance.
MySQL also supports other storage engines, such as MyISAM, MEMORY, CSV, and ARCHIVE. Each one has specific characteristics and uses. For now, I recommend that you stick with the default InnoDB until you better understand the differences between storage engines. I also recommend that you review the MySQL documentation for detailed information about the different engine types.
At this point, you can also add a table-level comment if you’re so inclined. Although that’s not necessary for this article, information of this sort can be useful when building a database for production.
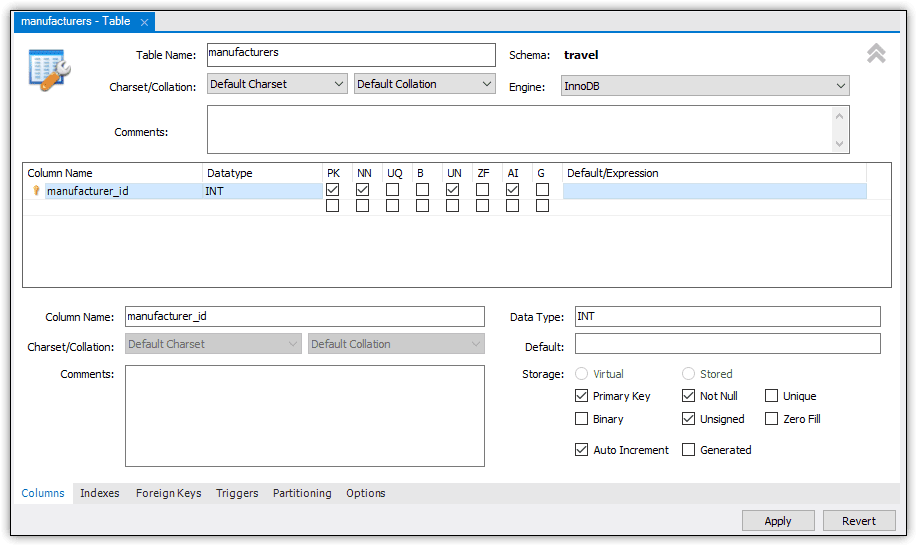
Once you have the basics in place, you can add the first column, which will be named manufacturer_id. It will also be the primary key and include the AUTO_INCREMENT option, which tells MySQL to automatically generate a unique number for that column’s value, similar to the IDENTITY property in SQL Server.
To add the column, double-click the first cell in the grid’s Column Name column and type manufacturer_id. In the Datatype column for that row, type INT or select INT from the drop-down list. Next, select the following check boxes:
- PK. Configures the column as the primary key.
- NN. Configures the column as NOT NULL.
- UN. Configures the INT database as UNSIGNED.
- AI. Configures the column with the AUTO_INCREMENT option.
With regard to the UNSIGNED option, MySQL lets you specify whether an integer data type is signed or unsigned. If signed, a column’s values can include negative numbers. If unsigned, the values cannot include negative numbers. Integer data types are signed by default. Older MySQL versions permitted you to configure the DECIMAL, DOUBLE, and FLOAT data types as unsigned, but that feature has been deprecated.
Integer signing affects the range of supported values. Consider the INT data type. If a column is defined with a signed INT data type, the column’s values must be between -2147483648 and 2147483647. However, if the data type is unsigned, the values must be between 0 and 4294967295. If you know that a column will never need to store a negative integer, you can define the data type as unsigned to support a greater range of positive integers.
As you configure a column, Workbench updates the option settings in the section below the grid. This bottom section reflects the settings of the column selected in the grid and can be handy when defining multiple columns. The bottom section also provides several additional optional. For example, you can add a comment specific to the selected column. You can also set the character set and collation at the column level (for character data types).
Figure 6 shows the manufacturer_id column as it’s been defined so far. Notice that the bottom section reflects all the settings specified in the column grid.
Figure 6. Adding a column to a table definition
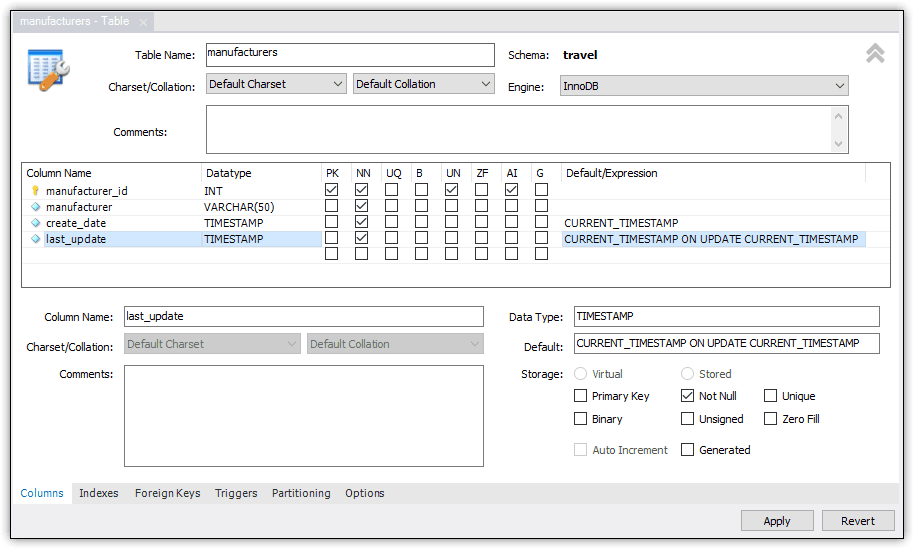
You can repeat a similar process for each additional column you want to include, choosing the data type and configurable options. When specifying the data type, you can type it or select it from the drop-down list. However, some of the data types in the drop-down-list, including TIMESTAMP, are listed with trailing parentheses that should not be there. This is apparently a Workbench bug. You’ll have to manually remove the parentheses for the data type to be listed correctly. You can also specify a default value for any columns you’re defining. For this article, I added three more columns:
- The manufacturer column is configured with the VARCHAR(50) data type and is NOT NULL.
- The create_date column is configured with the TIMESTAMP data type and is NOT NULL. It is also configured with the default value CURRENT_TIMESTAMP, a system function that returns the current date and time.
- The last_update column is configured with the TIMESTAMP data type and is NOT NULL. It is also configured with a default value that include the CURRENT_TIMESTAMP function, along with the ON UPDATE CURRENT_TIMESTAMP option, which generates a value whenever the table is updated.
Figure 7 shows the Table tab after I added the three columns. The grid includes a row for each column, with each row reflecting the column’s configuration.
Figure 7. Adding multiple columns to the new table definition
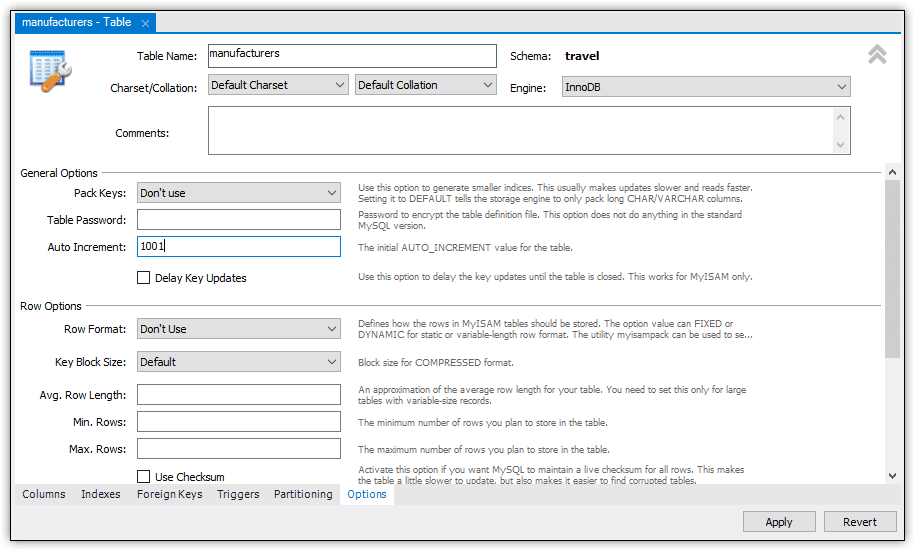
There’s one other step to take to complete the table’s definition. For this, you need to go to the Options tab and set the initial AUTO_INCREMENT seed value. In this case, I used 1001, as shown in Figure 8. As a result, the first record added to the table will be assigned a manufacturer_id value of 1001, with each subsequent row incremented by 1.
Figure 8. Setting the seed value for the AUTO_INCREMENT option
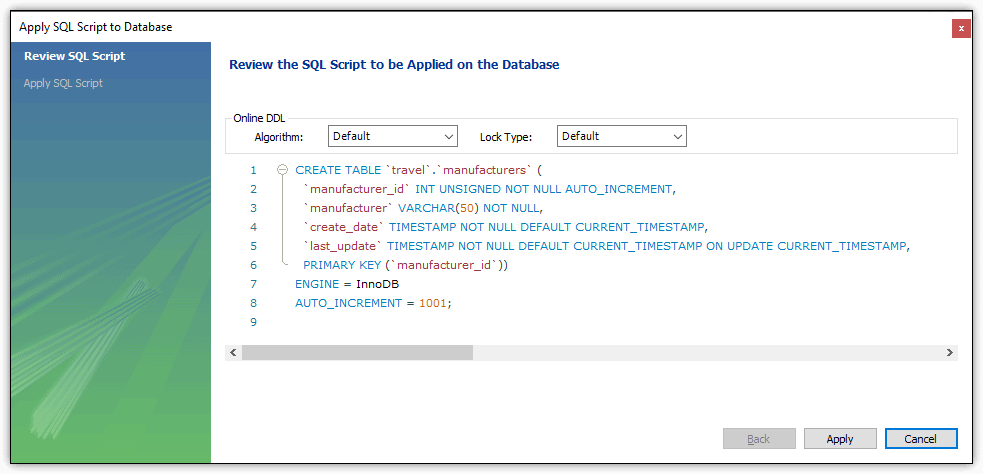
As you can see, there are plenty of other table options that you can configure, and there are other tabs on which you can configure additional options. But for now, we’ll stop here and add the table to the database. To do so, click the Apply button, which launches the Apply SQL Script to Database wizard, shown in Figure 9.
Figure 9. Verifying the CREATE TABLE statement
On this screen, you can review the SQL statement that has been generated and select an algorithm and lock type, if desired. You can also edit the SQL statement directly on this screen. (Just be sure not to introduce any errors.)
Notice that the manufacturer_id column is configured with the INT data type (unsigned) and defined as the primary key. It also includes the AUTO_INCREMENT option. The AUTO_INCREMENT seed value, 1001, is specified as a table option, along with the InnoDB storage engine. Notice, too, that the create_date and last_update columns include the specified DEFAULT clauses.
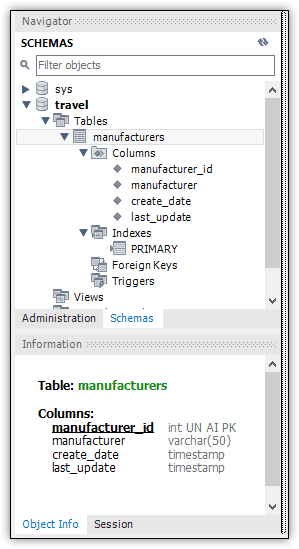
To complete the table creation process, simply click Apply and then click Finish on the next screen. You should then be able to confirm in Navigator that the table has been created, as shown in Figure 10.
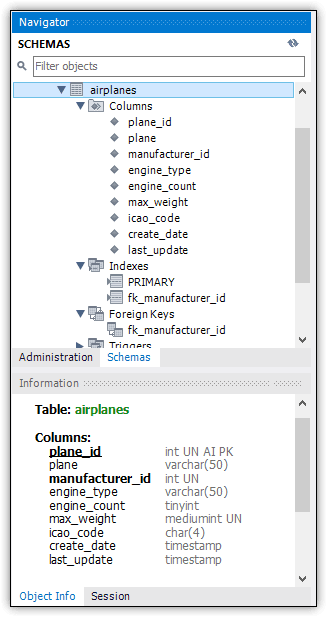
Figure 10. Viewing the new table in Navigator
Notice that an index is created for the primary key column. MySQL automatically names primary key indexes PRIMARY, which might be different from what you’ve seen in other database systems. Because a table can include only one primary key, there is no problem with duplicate index names.
Using SQL to create a table in a MySQL database
The Workbench GUI features can be handy for creating database objects, especially if you’re new to MySQL or database development. They can also be useful when trying to understand the various options available when creating an object. However, most developers prefer to write the SQL code themselves, and if you already have at least some experience with SQL, you’ll likely have little problem adapting to MySQL.
With this in mind, the next step will be to create a second table in the travel database. For this, you can use the following CREATE TABLE statement:
CREATE TABLE IF NOT EXISTS airplanes (
plane_id INT UNSIGNED NOT NULL AUTO_INCREMENT,
plane VARCHAR(50) NOT NULL,
manufacturer_id INT UNSIGNED NOT NULL,
engine_type VARCHAR(50) NOT NULL,
engine_count TINYINT NOT NULL,
max_weight MEDIUMINT UNSIGNED NOT NULL,
icao_code CHAR(4) NOT NULL,
create_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
last_update TIMESTAMP NOT NULL
DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (plane_id),
CONSTRAINT fk_manufacturer_id FOREIGN KEY (manufacturer_id)
REFERENCES manufacturers (manufacturer_id) )
ENGINE=InnoDB AUTO_INCREMENT=101;
For the most part, the CREATE TABLE statement uses fairly standard SQL. The table is similar to the one I created in the first article in this series. It also shares some of the same elements as the manufacturers table you created above. The table includes nine columns with a mix of data types and options, although all columns are configured as NOT NULL.
One item worth pointing out is the max-weight column, which is configured with the MEDIUMINT data type (unsigned). As you’ll recall from the first article, the data type falls between SMALLINT and INT data types in terms of the supported numeric range. In this way, you have more granular options for working with integer values. Neither SQL Server nor Oracle Database support the MEDIUMINT data type.
What you haven’t seen before (at least not in this or the previous article) is the foreign key constraint that’s defined on the manufacturer_id column. The foreign key references the manufacturer_id column in the manufacturers table. The constraint ensures that any manufacturer_id value added to the airplanes table must already exist in the manufacturers table. If you try to add a different value, you’ll receive an error.
The table definition also includes two table options. The ENGINE option species InnoDB as the storage engine, and the AUTO_INCREMENT option sets the seed value to 101.
At this point, the CREATE TABLE statement should be fairly complete (at least for now), so you can go ahead and execute it in Workbench. You can then view the table in Navigator, as shown in Figure 11.
Figure 11. Viewing the airplanes table in Navigator
As you can see, Navigator lists the foreign key beneath the Foreign Keys node. Notice that MySQL also adds an index for the foreign key, which is assigned the same name as the foreign key. We’ll be covering indexes later in this series.
Altering a table definition in a MySQL table database
You can also use SQL to modify a table definition in MySQL. For example, the following ALTER TABLE statement adds two columns to the airplanes table:
ALTER TABLE airplanes
ADD COLUMN wingspan DECIMAL(5,2) NOT NULL AFTER max_weight,
ADD COLUMN plane_length DECIMAL(5,2) NOT NULL AFTER wingspan;
Both columns are configured with the DECIMAL(5,2) data type. This means that each column can store up to five digits with two decimal places.
Each column definition also includes an AFTER clause, which specifies where to add the column in the table definition. For example, the AFTER clause in the wingspan column definition specifies that the column should be added after the weight column, and the AFTER clause in the plane_length column definition specifies that the column should be added after the wingspan column.
When you run this ALTER TABLE statement, MySQL will update the airplanes table accordingly. You can then view the new columns in Navigator.
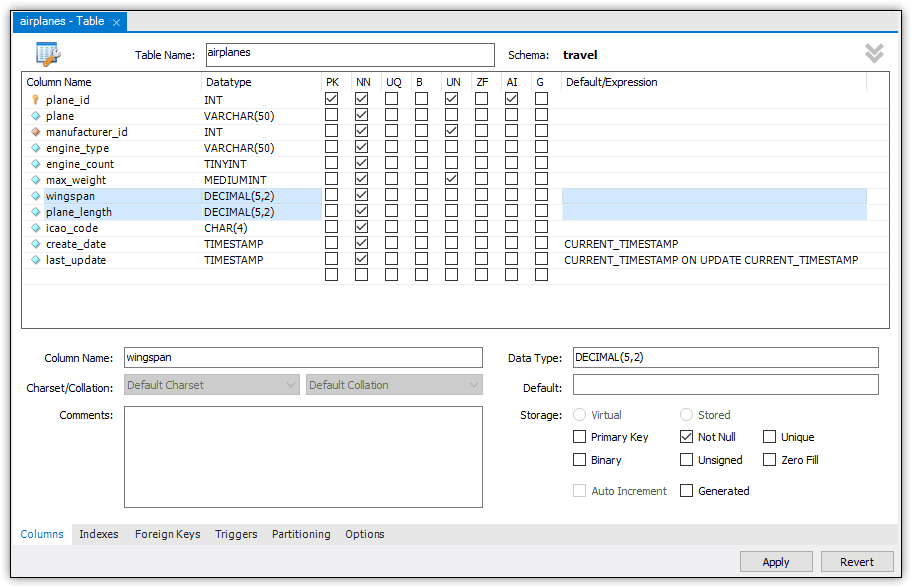
You can also use the Workbench GUI to alter a table definition. To do so, right-click the table in Navigator and then click Alter Table, which opens the Table tab. Here you can modify the column definitions or table options. You can also add or delete columns. Figure 12 shows the Table tab with the wingspan and plane_length columns selected, which are the columns you just added above.
Figure 12. Viewing the new columns in the table editor
The next step will be to add a generated column to the table. A generated column is one in which the value is computed from an expression, similar to computed columns in SQL Server and Oracle Database.
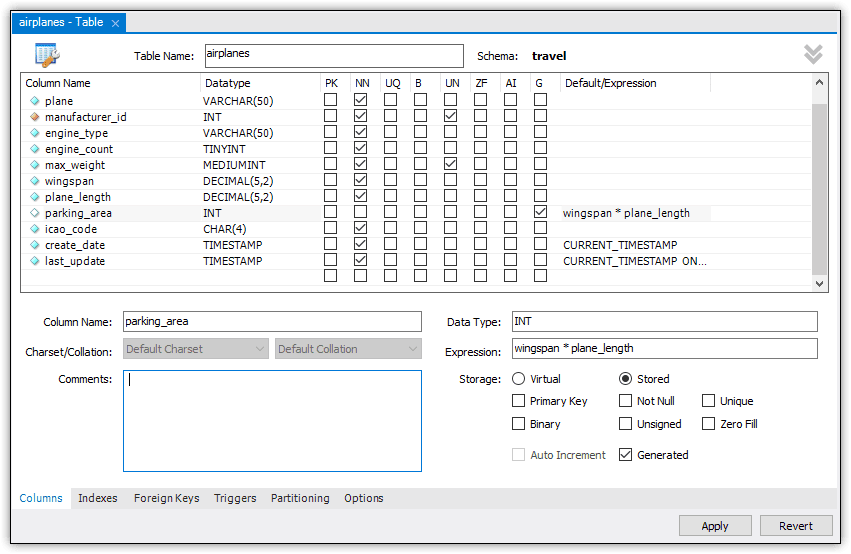
To add the column, double-click the first cell in the first empty line of the table grid (beneath the last_update column definition) and then type parking_area for the column name. On the same line, type INT for the data type, select the G option (for GENERATED), and type wingspan * plane_length in the Default/Expression column. The expression multiplies the wingspan value by the plane_length value to arrive at the total area.
When you create a generated column in the GUI, Workbench automatically selects the Virtual option in the column detail area (near the bottom of the tab). This means that the column values will be generated on demand, rather than being stored in the database. The Stored option does just the opposite. The value is calculated when a row is inserted into the table, where the value remains until the row is updated or deleted. For this article, I used the Stored option.
After you create a column, you can move it to a new location in the list of columns by dragging it to the desired position. In this case, I moved the parking_area column to after the plane_length column, as shown in Figure 13.
Figure 13. Adding a generated column to the airplanes table
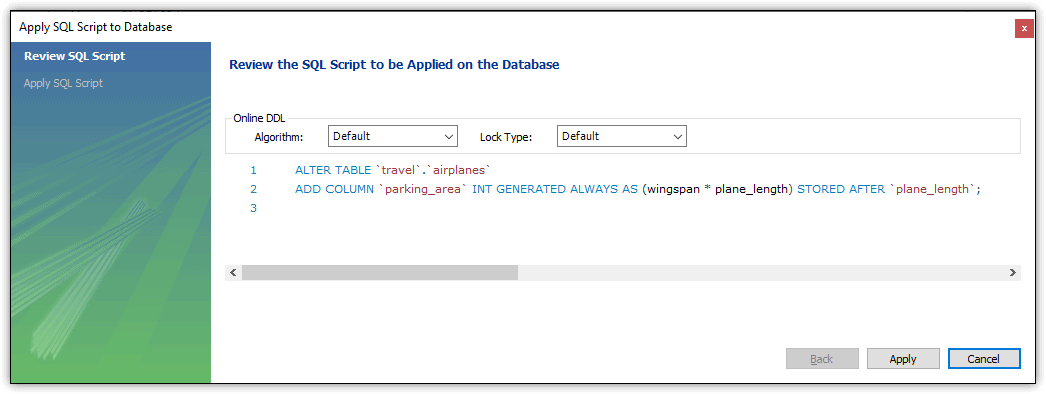
That’s all you need to do to add a generated column to the table. To complete the process, click Apply, which launches the Apply SQL Script to Database wizard. Here you can review the SQL script, as shown in Figure 14.
Figure 14. Verifying the new column being added to the airplanes table
When Workbench generates the ALTER TABLE statement, it adds the GENERATED ALWAYS AS clause to indicate that this is a generated column. (The GENERATED ALWAYS keywords are optional and can be omitted when creating your own SQL statement.) In addition, the clause includes the computed expression, in parentheses.
Workbench also adds the STORED keyword to the column definition to indicate that the calculated values should be stored rather than computed on demand. Plus, the definition includes the AFTER clause, which indicates that the column should be added after the plane_length column.
If this all looks good to you, click Apply again and then click Finish to close the wizard. You can then confirm the table update in Navigator.
Dropping a table from a MySQL database
As with other DDL actions in Workbench, you can use SQL or the GUI to drop a table from a database. For example, you can remove the airplanes table by running the following DROP TABLE statement, which includes the optional IF EXISTS clause:
DROP TABLE IF EXISTS airplanes;
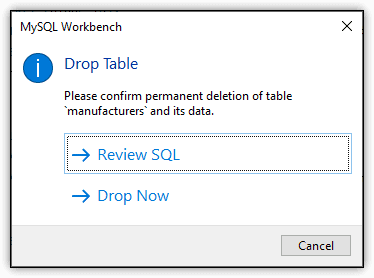
You can also drop a table through Navigator. To do so, right-click the table and then click Drop Table. This launches the Drop Table dialog box, shown in Figure 15. Click Drop Now to remove the table.
Figure 15. Deleting a table in Workbench
Notice that the dialog box also includes the Review SQL option. Click this instead if you want to review the DROP TABLE statement that Workbench has generated. You can then execute the statement from there.
Working with tables in a MySQL database
MySQL tables support a variety of options at both the column and table level, far more than can be covered reasonably in a single article. You can also create temporary tables or partition tables. You’ll find it well worth your while to review the MySQL documentation on the CREATE TABLE statement. There you can see for yourself the many ways in which you can define a MySQL table.
That said, what I’ve covered here should provide you with a good foothold for getting started with tables, whether you use SQL or the MySQL GUI. What you’ve learned here will also provide you with a foundation for working with other types of database objects, which could prove useful as we advance through this series.
The post Working with MySQL tables appeared first on Simple Talk.
from Simple Talk https://ift.tt/fQahq2A
via