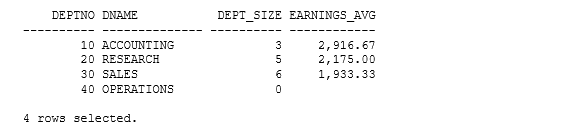The series so far:
- Getting started with MySQL
- Working with MySQL tables
- Working with MySQL views
Like other database management systems, MySQL lets you create views that enable users and applications to retrieve data without providing them direct access to the underlying tables. You can think of a view as a predefined query that MySQL runs when the view is invoked. MySQL stores the view definition as a database object, similar to a table object.
A view offers several advantages. It abstracts the underlying table schema and restricts access to only the data returned by the view. Applications invoking the view cannot see how the tables are structured or what other data the tables contain. In this sense, the view acts as a virtual table, adding another layer of security that hides the structure of the physical tables.
A view also helps simplify queries because it presents a less complex version of the schema. For example, an application developer doesn’t need to create detailed, multi-table joins but can instead invoke the view in a basic SELECT statement. In addition, a view’s ability to abstract schema makes it possible to modify the underlying table definitions without breaking the application.
Despite the advantages that a view offers, it also comes with a number of limitations. For instance, MySQL does not let you create an index on a view, define a trigger on a view, or reference a system or user-defined variable in the view’s query.
In addition, it’s possible to drop a table that is referenced by a view without generating an error. It’s not until a user or application tries to invoke the view that MySQL raises the alarm, which could have a severe impact on running workloads. (For a complete rundown on view restrictions and for other information about views, refer to the MySQL documentation on creating views.)
Preparing your MySQL environment
A view is a stored query that MySQL runs when the view is invoked. The query is typically a SELECT statement that retrieves data from one or more tables. Starting with MySQL 8.0.19, the query can instead be a VALUES or TABLE statement, but in most cases, a SELECT statement is used, so that’s the approach I take in this article.
Any tables that are referenced by the SELECT statement must already exist before you can create the view. Beyond that, there’s not much else you need to have in place to add a view to a database, other than to be sure you have the permissions necessary to create views and query the underlying tables (a topic I’ll be discussing in more detail later in this series).
For the examples in this article, I created the travel database and added the manufacturers and airplanes tables. These are the same tables I created and updated in the previous article in this series. To add the database and tables to your MySQL instance, you can run the following SQL code:
DROP DATABASE IF EXISTS travel;
CREATE DATABASE travel;
USE travel;
CREATE TABLE manufacturers (
manufacturer_id INT UNSIGNED NOT NULL AUTO_INCREMENT,
manufacturer VARCHAR(50) NOT NULL,
create_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
last_update TIMESTAMP NOT NULL
DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (manufacturer_id) )
ENGINE=InnoDB AUTO_INCREMENT=1001;
CREATE TABLE airplanes (
plane_id INT UNSIGNED NOT NULL AUTO_INCREMENT,
plane VARCHAR(50) NOT NULL,
manufacturer_id INT UNSIGNED NOT NULL,
engine_type VARCHAR(50) NOT NULL,
engine_count TINYINT NOT NULL,
max_weight MEDIUMINT UNSIGNED NOT NULL,
wingspan DECIMAL(5,2) NOT NULL,
plane_length DECIMAL(5,2) NOT NULL,
parking_area INT GENERATED ALWAYS AS ((wingspan * plane_length)) STORED,
icao_code CHAR(4) NOT NULL,
create_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
last_update TIMESTAMP NOT NULL
DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (plane_id),
CONSTRAINT fk_manufacturer_id FOREIGN KEY (manufacturer_id)
REFERENCES manufacturers (manufacturer_id) )
ENGINE=InnoDB AUTO_INCREMENT=101;
To run these statements, copy the code and paste it into a query tab in Workbench. You can then execute the statements all at once or run them one at a time in the order they’re shown here. You must create the manufacturers table before you create the airplanes table because the airplanes table includes a foreign key that references the manufacturers table.
When you’re creating a view, it’s a good idea to test the view’s SELECT statement and then run the view after it’s created. For this, you’ll need some test data. The following two INSERT statements will add a small amount of data to the two tables, enough to get you started with creating a view:
INSERT INTO manufacturers (manufacturer)
VALUES ('Airbus'), ('Beechcraft'), ('Piper');
INSERT INTO airplanes
(plane, manufacturer_id, engine_type, engine_count,
max_weight, wingspan, plane_length, icao_code)
VALUES
('A380-800', 1001, 'jet', 4, 1267658, 261.65, 238.62, 'A388'),
('A319neo Sharklet', 1001, 'jet', 2, 166449, 117.45, 111.02, 'A319'),
('ACJ320neo (Corporate Jet version)', 1001, 'jet', 2, 174165, 117.45, 123.27, 'A320'),
('A300-200 (A300-C4-200, F4-200)', 1001, 'jet', 2, 363760, 147.08, 175.50, 'A30B'),
('Beech 390 Premier I, IA, II (Raytheon Premier I)', 1002, 'jet', 2, 12500, 44.50, 46.00, 'PRM1'),
('Beechjet 400 (from/same as MU-300-10 Diamond II)', 1002, 'jet', 2, 15780, 43.50, 48.42, 'BE40'),
('1900D', 1002, 'Turboprop', 2,17120, 57.75, 57.67, 'B190'),
('PA-24-400 Comanche', 1003, 'piston', 1, 3600, 36.00, 24.79, 'PA24'),
('PA-46-600TP Malibu Meridian, M600', 1003, 'Turboprop', 1, 6000, 43.17, 29.60, 'P46T'),
('J-3 Cub', 1003, 'piston', 1, 1220, 38.00, 22.42, 'J3');
I’ll be discussing INSERT statements in more detail later in this series, so I won’t spend a lot of time on them here. For now, all you need to know is that the first statement adds three rows to the manufacturers table, and the second statement adds 10 rows to the airplanes table.
You can execute both statements at the same time or one at a time. You must execute them in the order specified here so you don’t violate the foreign key defined on the airplanes table. Because the foreign key is configured on the manufacturer_id column, the values in the column must first exist in the manufacturers table. Again, I’ll be digging deeper into all this later in the series.
That’s the only setup you need to do to prepare your MySQL environment so you can follow along with the examples in this article. As with the first two articles in this series, I used the MySQL Community edition on a Windows computer to build the examples. I created the examples in Workbench, which comes with the Community edition.
Creating a view in MySQL
If you reviewed the previous article in this series, you know that the Workbench GUI provides the Table tab, a handy tool for building and editing a table definition. However, the one for creating views—the View tab—is not nearly so useful. One of the biggest advantages with the Table tab, especially for beginners, is that it shows the various options available to a table definition. The View tab does not provide this advantage. It basically leaves it up to you to build the CREATE VIEW statement, just like you would on a query tab.
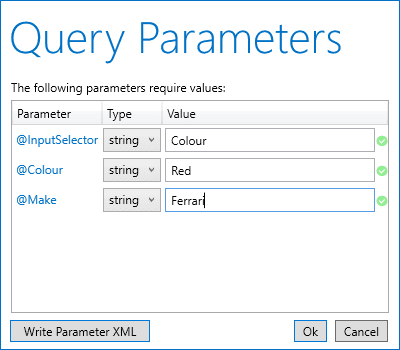
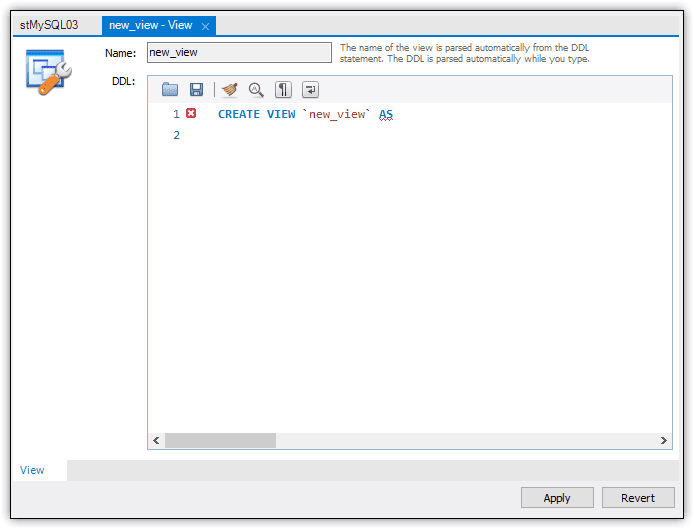
For this article, I used a query tab for all the examples. However, it’s good to know how to access the View tab in case you want to use it. To launch the tab, select the database in Navigator and then click the create view button on the Workbench toolbar. (The button is to the right of the create table icon and includes the tooltip Create a new view in the active schema in the connected server.) When you click the button, Workbench opens the View tab, as shown in Figure 1.

Figure 1. Adding a view through the Workbench GUI
The only thing you can do in this tab is to write a CREATE VIEW statement. Although the tab provides a bit of a stub for getting started with the statement, it does not offer much else. You’re on your own to write the actual statement (or copy and paste it from another source). From there, you must then step through a couple more screens, just like you do with the Table tab, but without the benefit of an auto-generated statement.
Whether or not you use the View tab is up to you. Either way, you must still come up with the CREATE VIEW statement. With that in mind, consider the following example, which creates a view based on the two tables in the travel database:
CREATE VIEW airbus_info
AS
SELECT a.plane, a.engine_type, a.engine_count,
a.wingspan, a.plane_length, a.parking_area
FROM airplanes a INNER JOIN manufacturers m
ON a.manufacturer_id = m.manufacturer_id
WHERE m.manufacturer = 'airbus'
ORDER BY a.plane;
At its most basic, the CREATE VIEW statement requires only that you specify a name for the view, followed by the AS keyword, and then followed by the SELECT statement. In this case, I’ve named the view airbus_info.
The SELECT statement itself is relatively straightforward. It defines an inner join between the airplanes and manufacturers tables, with the join based on the manufacturer_id column in each table. The WHERE clause limits the results to those rows in which the manufacturer value is airbus, and the ORDER BY clause sorts the results by the plane column.
When you’re creating a view, it’s always a good idea to run the SELECT statement on its own to ensure it’s returning the results you’re looking for. I’ve kept the statement relatively simple because I’ll be discussing SELECT statements in more detail later in this series. However, the statement I’ve used here does everything we need it to do to demonstrate how to create a view. A view’s SELECT statement can be as simple or as complex as you need it to be.
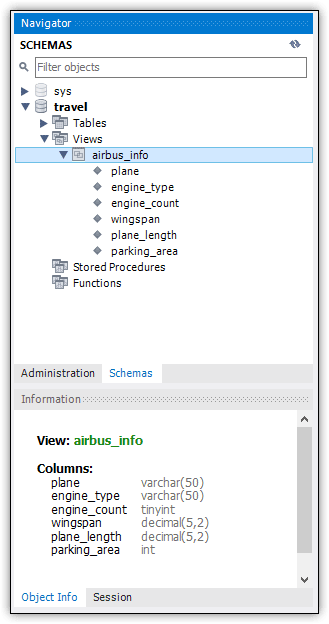
When you execute the CREATE VIEW statement, MySQL adds the view definition to the active database. You can verify that the view has been created in Navigator. You might need to refresh Navigator to see the listing, but you should find it under the Views node, as shown in Figure 2.
Figure 2. Viewing the new view in Navigator
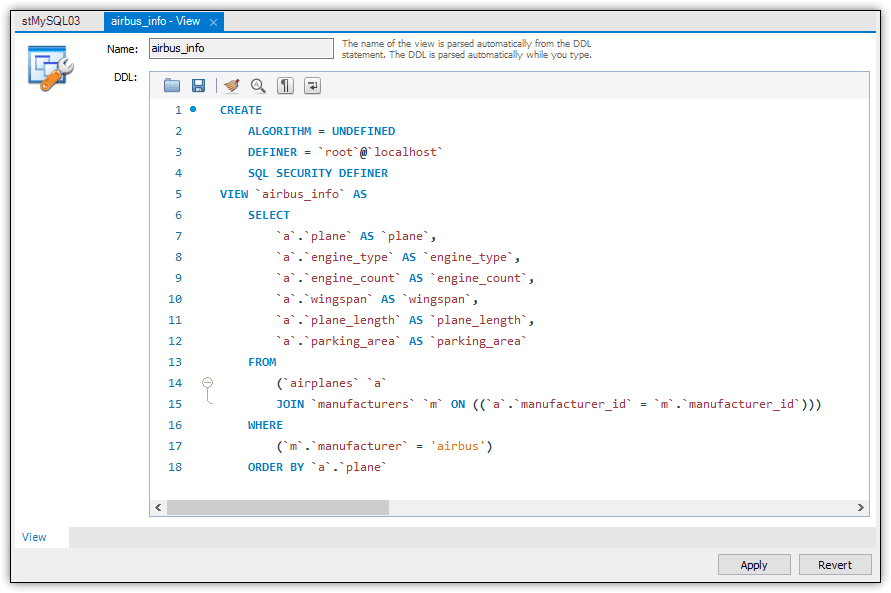
From here, you can open the view definition in the View tab. When you hover over the view’s name in Navigator, you’ll see several small icons for accessing additional features. One of these looks like a wrench. If you click this, Workbench will launch the View tab and display the view’s code, as shown in Figure 3.
Figure 3. Accessing the view definition through the Workbench GUI
MySQL added several options to the view definition that were not included in the original CREATE VIEW statement. The options are all configured with their default values. We’ll be discussing these options in just a bit.
You can edit the CREATE VIEW statement directly on the View tab. After you make the necessary changes, click Apply, review the code, click Apply again, and click Finish. Then close the View tab. We won’t be using this method for this article but know that it’s an option if you ever decide to go this route.
You can also open the CREATE VIEW statement on a query tab. Right-click the view in Navigator, point to Send to SQL Editor, and then click Create Statement. The statement is rendered on a single line, which is fairly unreadable. However, you can fix this by clicking the reformat button on the tab’s toolbar. (The button looks like a little broom and includes the tooltip Beautify/reformat the SQL script.)
Accessing view information through the INFORMATION_SCHEMA database
Like other relational database systems, MySQL adheres to many of the SQL standards maintained by the American National Standards Institute (ANSI). One of these standards includes the creation of the INFORMATION_SCHEMA database, which provides read-only access to details about a database system and its databases.
The information available through the INFORMATION_SCHEMA database is exposed though a set of views, one of which is named Views. Through it, you can access information about the views you create in your MySQL database. For example, the following query returns details about the view we just created in the travel database:
SELECT * FROM information_schema.views
WHERE table_schema = 'travel';
The statement uses the asterisk (*) wildcard to indicate that all columns should be returned. It also qualifies the name of the target view in the FROM clause by including the database name (information_schema), followed by a period and the name of the view (views). In addition, the statement includes a WHERE clause that filters out all views except those in the travel database.
When you run this statement, the results should include a row for the airbus_info view that you created above. The information provides details about how the view has been defined. The meaning of many of the columns in the result set should be apparent, and others I’ll be covering later in the article. But I did want to point out two columns in particular: CHECK_OPTION and IS_UPDATEABLE.
Both columns have to do with updatable views, a topic I’ll be covering later in this series. For now, just know that MySQL supports updateable views and that a view is considered updateable if it meets a specific set of criteria. MySQL automatically determines whether a view is updateable based on these criteria. If it is updateable, MySQL sets the IS_UPDATEABLE column to YES (true). Otherwise, the value is NO (false).
Another column worth noting is VIEW_DEFINITION, which contains the view’s query. If you want to view this query and nothing else, you can define your SELECT statement to limit the results:
SELECT view_definition
FROM information_schema.views
WHERE table_schema = 'travel'
AND table_name = 'airbus_info';
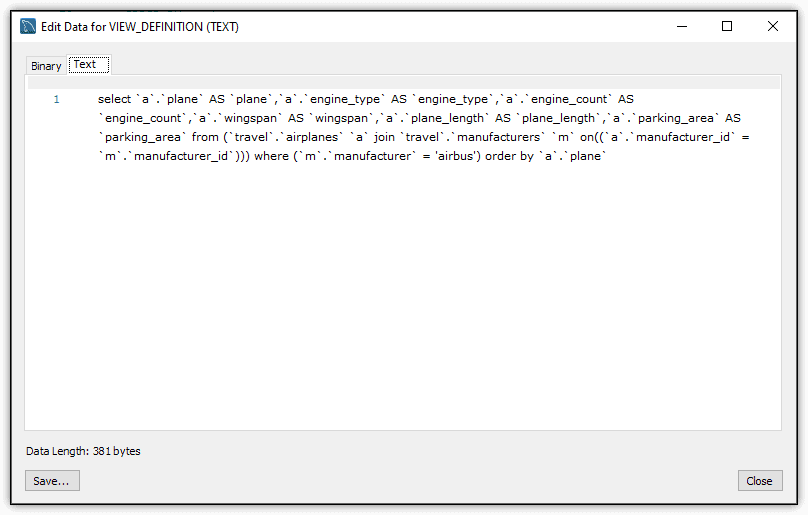
The SELECT clause now specifies that only the view_definition column be returned, rather than all columns. However, even with limiting the results, they can still be difficult to read. Fortunately, Workbench provides a handy feature for viewing a column’s value in its entirety. To access this feature, right-click the value directly in the results and click Open Value in Viewer. MySQL launches a separate window that displays the value, as shown in Figure 4.
Figure 4. Examining the view’s SELECT statement in Viewer
Here you can review both the binary and text values. In addition, you can save the statement to a text file by clicking the Save button. You cannot save the binary value to a file.
Querying a MySQL view
As noted earlier, I’ll be covering the SELECT statement in more detail later in this series, but I wanted to give you a quick overview of how you can query a view after it’s been created. For the most part, it works much the same way as querying a table. The following example shows a SELECT statement at its most basic, with the airbus_info view identified in the FROM clause:
SELECT * FROM airbus_info;
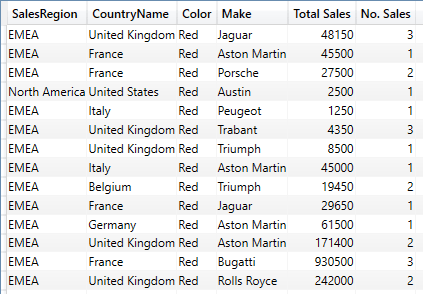
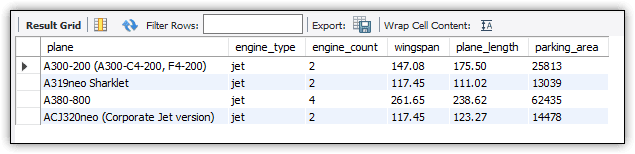
When you execute this SELECT statement, MySQL runs the query in the view definition and returns the results, just like it would if you ran the query directly. Figure 5 shows the results that your SELECT statement should return.
Figure 5. Viewing the query results after invoking the airbus_info view
You can also refine your SELECT statement as you would when querying a view. For example, the following SELECT statement includes a WHERE clause that limits the results to those with a parking_area value greater than 20000:
SELECT * FROM airbus_info
WHERE parking_area > 20000
ORDER BY parking_area DESC;
The statement also includes an ORDER BY clause that sorts the results by the parking_area column in descending order. When you include an ORDER BY clause when calling the view, it overrides the ORDER BY clause in the view definition itself (if one is included). Figure 6 shows the data that your SELECT statement should now return.
Figure 6. Refining the query results when invoking a view
As you can see, the results now include only two rows and those rows are sorted by the values in the parking_area column, with the highest value first. The ORDER BY clause in the view definition sorts the data by the plane values.
Updating a MySQL view definition
MySQL provides several methods for modifying a view definition. One of these is to use a CREATE VIEW statement that includes the OR REPLACE clause, as shown in the following example:
CREATE OR REPLACE
ALGORITHM = MERGE
DEFINER = CURRENT_USER
SQL SECURITY INVOKER
VIEW airbus_info
AS
SELECT a.plane, a.engine_type, a.engine_count,
a.wingspan, a.plane_length, a.parking_area
FROM airplanes a INNER JOIN manufacturers m
ON a.manufacturer_id = m.manufacturer_id
WHERE m.manufacturer = 'airbus'
ORDER BY a.plane;
By adding the OR REPLACE clause after the CREATE keyword, you can refine an existing view definition and then run the statement without generating an error, as would be the case if you didn’t include the clause. This is a great tool when you’re actively developing a database and the schema is continuously changing.
In addition to the OR REPLACE clause, the view definition includes several other elements that weren’t in the original CREATE VIEW statement that you created. The first is the ALGORITHM clause, which tells MySQL to use the MERGE algorithm when processing the view. The algorithm merges the calling statement and view definition in a way that can help make processing the view more efficient. The algorithm is also required for a view to be updatable. For more information about algorithms, see the MySQL documentation on view processing algorithms.
The other two new options—DEFINER and SQL SECURITY—control which user account privileges to use when processing the view. The DEFINER option specifies which account is designated as the view creator. In this case, the option is set to CURRENT_USER, so the definer is the user that who actually runs the CREATE VIEW statement.
The SQL SECURITY option can take either the DEFINER or INVOKER argument. If DEFINER is specified, the view will be processed under the account of the specified DEFINER. If INVOKER is specified, the view will be processed under the account of the user who invokes the view.
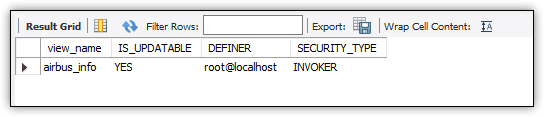
After you run the preceding CREATE VIEW statement, you can verify that the options have been updated by querying the view INFORMATION_SCHEMA.VIEWS:
SELECT table_name AS view_name,
is_updatable, definer, security_type
FROM information_schema.views
WHERE table_schema = 'travel'
AND table_name = 'airbus_info';
Figure 7 shows the results I received when I executed the SELECT statement on my system. Because I ran the CREATE VIEW statement as the root user, the DEFINER column shows my username, with localhost as the server instance. The results also show the INVOKER value in the SECURITY_TYPE column, which corresponds with the SQL SECURITY option.
Figure 7. Viewing results from the INFORMATION_SCHEMA database
You might have noticed that INFORMATION_SCHEMA.VIEWS does not return details about the specified algorithm. In this case, however, the IS_UPDATABLE column is set to YES, indicating that the view is updatable, which works only with the MERGE algorithm. That said, if the column is set to NO, you can’t be certain which algorithm is being used because other factors might affect whether the view is updateable.
Another approach you can take to updating a view definition is to run an ALTER VIEW statement. The ALTER VIEW statement syntax is nearly the same the CREATE VIEW syntax. For example, the following ALTER VIEW statement is similar to the previous CREATE VIEW statement except that it also specifies the column names to use for the returned result set:
ALTER
ALGORITHM = MERGE
DEFINER = CURRENT_USER
SQL SECURITY INVOKER
VIEW airbus_info
(plane, engine, count, wingspan, length, area)
AS
SELECT a.plane, a.engine_type, a.engine_count,
a.wingspan, a.plane_length, a.parking_area
FROM airplanes a INNER JOIN manufacturers m
ON a.manufacturer_id = m.manufacturer_id
WHERE m.manufacturer = 'airbus'
ORDER BY a.plane;
In this case, the statement includes a list of column names after the view name. The column names are enclosed in parentheses and separated by commas. These are the column names used for the view’s results, rather than using the column names of the underlying tables.
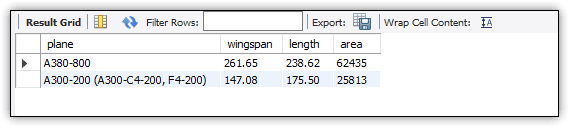
After you run the ALTER VIEW statement, you can then query the view as you did before, except that you must use the specified column names. For example, the following SELECT statement limits and orders the results, like you saw in a previous example:
SELECT plane, wingspan, length, area
FROM airbus_info
WHERE area > 20000
ORDER BY area DESC;
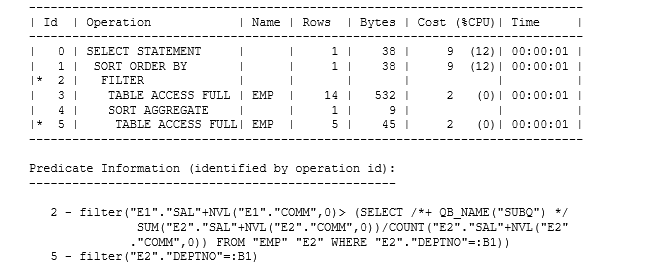
Notice that the SELECT statement uses the new column names, which are also reflected in the results, as shown in Figure 8.
Figure 8. Querying the updated airbus_info view
By specifying the returned column names, you can abstract the underlying schema even further, which provides yet another level of security, while making it easier to alter the underlying table schema. For example, if you change a column name in an underlying table, you might need to update the view’s query, but not the returned column names, avoiding any disruptions to a calling application.
Dropping a MySQL view
Removing a view is a relatively straightforward process. You can use the Workbench GUI or run a DROP VIEW statement. To use the GUI, right-click the view in Navigator and click Drop View. When the Drop View dialog box appears, click Drop Now.
To use a DROP VIEW statement, you need only specify the view name and, optionally, the IF EXISTS clause, as shown in the following example:
DROP VIEW IF EXISTS airbus_info;
You can confirm that the view has been dropped by running the following SELECT statement against INFORMATION_SCHEMA.VIEWS:
SELECT * FROM information_schema.views
WHERE table_schema = 'travel';
The results should no longer include a row for the airbus_info view.
Working with views in a MySQL database
Views can provide an effective tool for presenting data to applications in a way that abstracts the underlying table structure. At the same time, they can help simplify the SQL statements that application developers need to write when retrieving data from a MySQL database. They also add an extra layer of protection by limiting access to the underlying tables.
I’ll be returning to the topic of views later in the series when I discuss querying and modifying data. Until then, the information I’ve provided in this article should give you a good starting point for working with views. As you become more adept at writing SELECT statements, you’ll be able to create more effective views that can return an assortment of information.
The post Working with MySQL Views appeared first on Simple Talk.
from Simple Talk https://ift.tt/JHb6NFk
via