Power BI Datamarts is an important new feature announced during BUILD. This new feature expands Power BI possibilities in directions which may be unexpected to many Power BI users. Next, discover more about what this means for Power BI users and developers.
What’s a single source of truth?
Before explaining Datamarts, I will need to start from the beginning. Every company needs a single source of truth.
Could you imagine if, when checking the total of active customers in the company, one e-mail report has a number, one Power BI dashboard has a different number, and the production database has a third one?
In my country we have an old saying “Who has one watch knows the time, who has two watches only knows the average”. Every company needs to be sure to have a single watch and keep it always on time. A single source of truth.
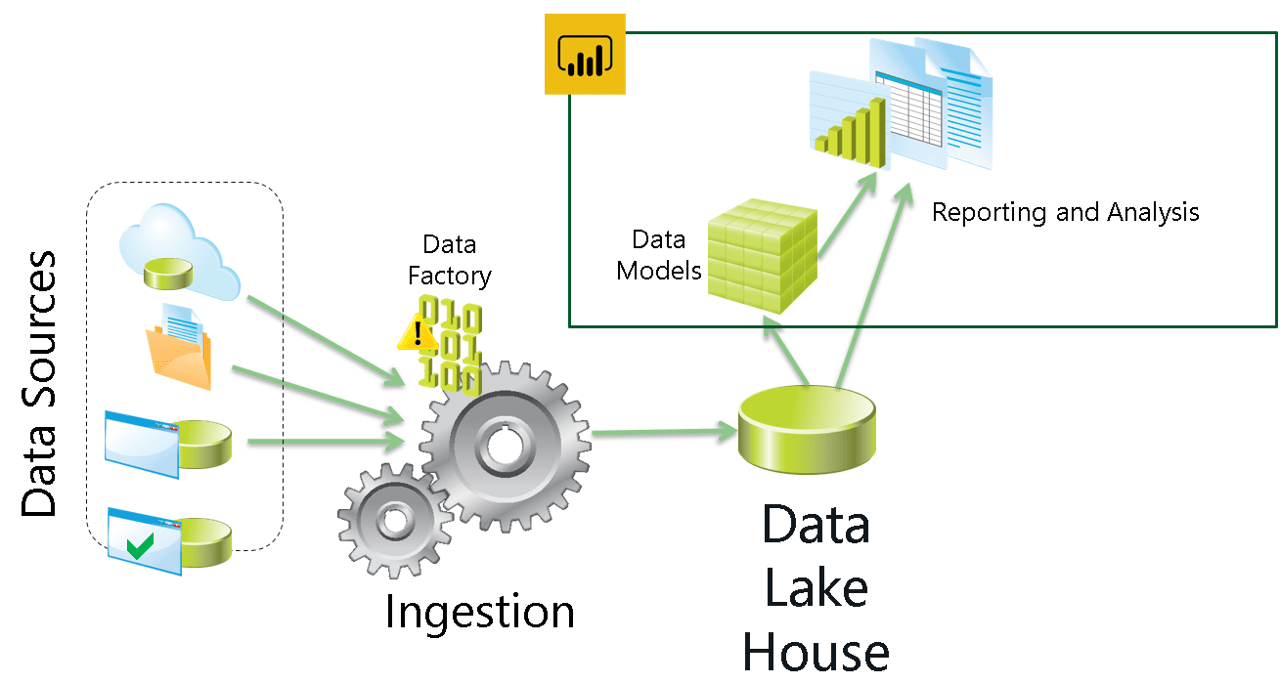
Data warehouses are one implementation of this single source of truth. It’s beyond the Power BI work. ETL is used to extract data from all production databases to a Data Warehouse. Power BI uses the Data Warehouse as a source and becomes the serving layer for the company’s data platform.

This is a good practice. It’s not always followed or a technical requirement, but it’s a good practice. I wrote before about the relation between ETL and Power BI in this other article: https://www.red-gate.com/simple-talk/blogs/power-bi-etl-or-not-etl-thats-the-question/
What’s a data mart?
According to its theorical definition, a data mart is a subset of the data warehouse. A data warehouse can contain complex structures, such as slowly changing dimensions (also know as dimension type 2). These structures are not simple to be used by an end user.
These complex structures hold important historical information which can be useful, but most users will need more focused information. That’s where the data marts come to the rescue.
A data mart can be a more focused and more user-friendly set of data, extracted from the data warehouse and prepared for the end user. 90% of the time the user requirements will be fulfilled by dashboards and reports created from the data mart. But there is also those 10% of questions which appear out of the blue from a CEO request. These questions may require an exploratory analysis over the data mart or even the data warehouse. That’s why there is the old saying “A data warehouse doesn’t have a response time, but a delivery time”.
Power BI, working as a serving layer, can use a data warehouse or a data mart as a source. More than that, many people, including me, would consider Power BI as a tool to build data marts using a data warehouse as a source.
Exploratory analysis vs explanatory analysis
You may have heard before about how Story Telling knowledge is important to build Power BI reports. It is. That’s because Power BI reports are very powerful for explanatory analysis.
You start with the data. A lot of historical data inside the company data warehouse. From this data, conclusions need to be made and call to actions based on these conclusions need to be defined. Once conclusions are made, the reports are the tool used to explain it to the end users, convincing them about your conclusions.
Using Power BI reports, you can make explanatory analysis in Power BI applying story telling techniques. But what about exploratory analysis? What can Power BI offer for exploratory analysis? Explore the possibilities next.
Exploring data with Power BI interactive reports
As you may know, Power BI reports are interactive. The user can view the reports in different ways, in different points of view.
The question you may need to ask is: Are the interactive reports enough for exploratory analysis?
I will use some concepts from books about story telling to try to answer this question. I like one analogy from one specific book. Exploratory analysis is the work of opening 100 oysters to find 1 pearl. Explanatory analysis is the work of explaining about that pearl to your users. It’s a bad practice to provide the users with the 100 oysters and leave to them the work to find the pearl.
However, while studying storytelling, you also need to know your users. You tell stories to your end user, such as a businessman who wants to know what’s hidden in the middle of the data. But if your user is a data analyst whose responsibility is to explore the data and find new possibilities, this guy will need to see the 100 oysters and find the pearl by himself.
There are many tricks to achieve this. Creating dynamic measures on the visuals, allowing the user to change the measure in the visual, creating dynamic hierarchies and much more.
In my humble opinion, with a good amount of work you can fulfil the user needs up to a point. But you know your users need more when the users keep asking you to receive the data in Excel. This is how the users tell you they want more exploratory power over the data.
Power BI building tools
Before building a report, you need to import data and build a model. You can use Power Query to import data with an entire language for this, the M language. For the model, there is DAX to build measures.
These tools focus is to build a model and from there build a story. However, they can be used for exploratory analysis. Power Query can be used to build different transformations on the source and check the results. You can build, edit, drop, build again, the entire back-and-forth of an exploratory analysis. The same can be done with DAX measures. You can create, change, adjust, in such a way to explore the existing data and discovering what’s needed.
Besides these tools, there are also an R visual and a Python visual, both allowing analysis of data using these languages.
All these tools enable using Power BI for exploratory analysis. However, is this analysis so easy as something done directly in SQL, Python or R over the data source?
In my humble opinion, using these tools for exploratory analysis is possible, but it’s a work around. That’s what is about to change with the use of Power BI Datamarts.
Bottom-UP design
Building a data warehouse, data marts and using Power BI as the serving layer is a state-of-the-art scenario, but you don’t always have the option to build it this way.
Many times, the data is spread among many different data sources. Sometimes these data sources can be set of Excel files, SharePoint lists or many other data sources which would make the ETL process more complex.
These data sources, using technologies built for modest sized data, will start to grow and will create problems during their growth.
This is the kind of scenario where building a data warehouse can happen in the reverse order: You start building small data marts, using the data sources and resources you have available. Later, you can merge these data marts into a single data warehouse. This is called a bottom-up design.
Building a data warehouse is a challenge regardless of top-down or bottom-up design. When using the bottom-up architecture, the risk is to end up with many data marts that can’t be merged, because they don’t fit in a bigger scenario. It’s like a puzzle. Working on isolated pieces without a view of the entire image may result in pieces that don’t match.
Once again, the Datamart feature in Power BI can help with the bottom-up scenario. When you face the need to retrieve the data from many disconnected and not so trustworthy sources, you can use the Datamarts in Power BI as a starting point to consolidate the data sources.
What’s Power BI Datamarts?
Power BI Datamart is a new feature announced in public preview during Microsoft BUILD. This feature requires the use of Power BI Premium or Premium Per User (PPU).
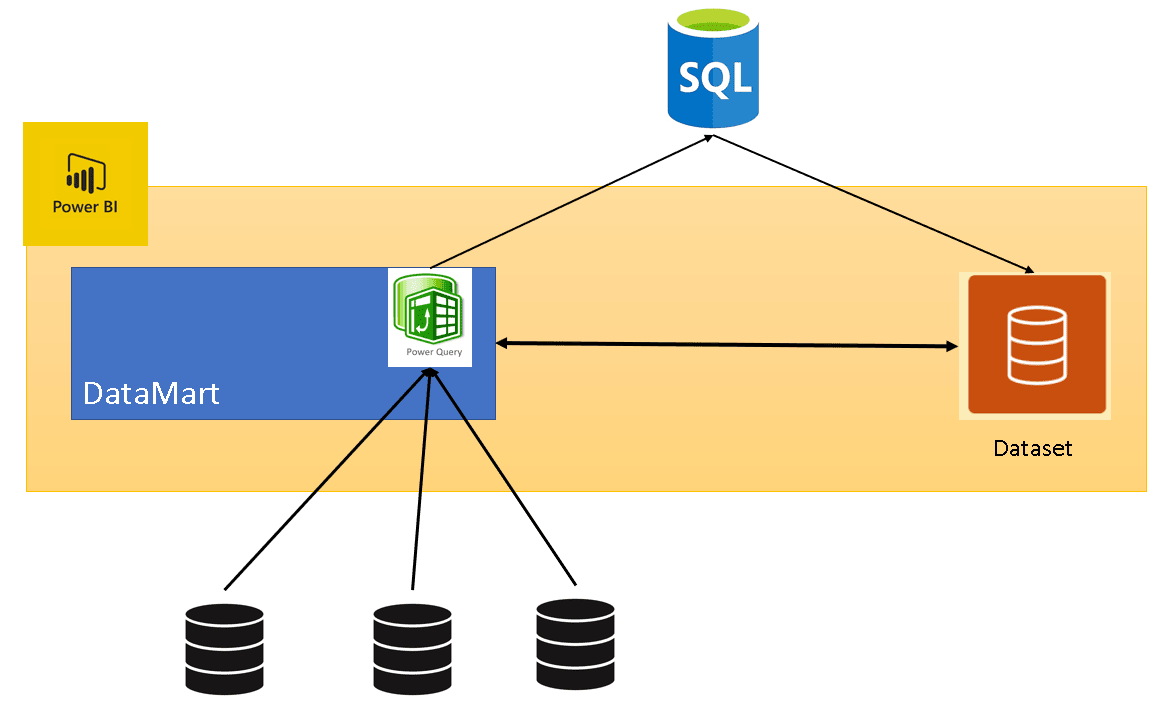
The Datamart uses an underlying Azure SQL Database to store its data. This creates very powerful possibilities. When creating a Datamart, you can import the data from many different sources to this Azure SQL Database using Power Query. The Datamart will also automatically create and manage a dataset linked to the internal Azure SQL Database.
Some architectural details:
- The dataset model is built on the Datamart
- Renaming the Datamart renames the dataset
- The tables in the dataset use direct query but have support for caching, which is done transparently for us
- It also supports dataflows as sources
- You have limited control over the settings of the dataset
- You have very limited control over the underlying Azure SQL Database. It’s provisioned by Power BI.
After learning about the architecture, here are the main features you can expect from the Power BI Datamart:
- It provides a UI to build a data mart in the portal
- This UI is basically the use of Power Query to import data. The portal doesn’t support the use of Power Query with datasets, you need to use Power BI desktop.
- Using Datamarts, you can build Power Query ETLs using the portal. The data imported by Power Query will be saved in the Azure SQL Database
- You can build a model using the imported tables.
- You can define relationships, create measures, and configure the attributes and tables.
- The UI provides additional resources for exploratory analysis
- The Datamart UI provides data exploration features
There are two new tabs, one for query design, another one for SQL. On both tabs you can explore the data to discover useful information in your data.
The UI also allows you to download the query results to Excel, to expand the exploratory analysis possibilities
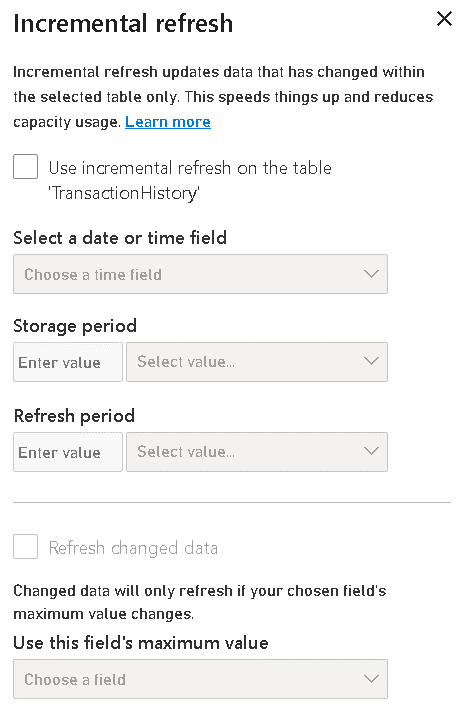
- Support for incremental refresh
Incremental refresh is essential for big tables, and they are expected in a data mart. The configuration is very similar to the incremental refresh configuration you may already know, but the data is being inserted in the Azure SQL Database.
- Support for role-based permissions configuration
- Integrated with Power BI Deployment Pipelines
- Datamarts allow a read-only connection to the Azure SQL Database. This is probably the most powerful tool for exploratory analysis
To understand this new feature, implement a Datamart step-by-step.
Important: The new Power BI feature is called “Datamart”, while the theoretical concept is called “Data mart”.
Implementing a Power BI Datamart
This will be the starting point:
- An Azure SQL Database using the sample AdventureWorskLT
- You need to execute the script Make_big_adventure.SQL adapted for the AdventureWorksLT. You can find it on https://github.com/DennesTorres/BigAdventureAndQSHints/blob/main/make_big_adventureLT.sql
- You need a premium Power BI workspace, either premium by capacity or premium per user
- Recommendation: The Azure SQL Database is recommended to have 10 DTU’s or more. Less than that and some slowness may be noticed
- Recommendation: If you create a non-clustered index on the table BigTransactionhistory, column TransactionDate, the access to the database will be faster.
After preparing the environment, it’s time to start to build the Datamart.
Creating the Datamart: First stage, importing the tables
- In the premium workspace, click New button and select the Datamart menu item
- On the Datamart design window, click the Import data from SQL Server image in the centre of the screen
Mind you also have options for Excel and Dataflows highlighted, but you also can use the Get Data button and use different kinds of data sources
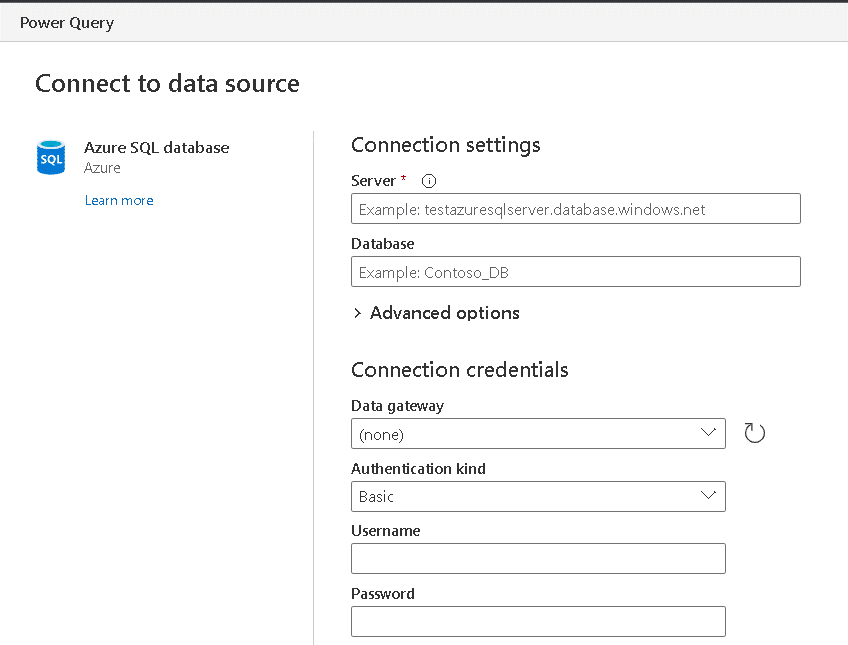
- In the Connect To Data Source window, fill the Server textbox with the address of your Azure SQL Database
- On the Connect To Data Source window, fill the Database textbox with the database name
- On the Connect To Data Source window, fill the user name and password with the Azure SQL Authentication
If your data source were on premises, you could use a gateway for it, but in this case, it’s not needed.
- Click Next button
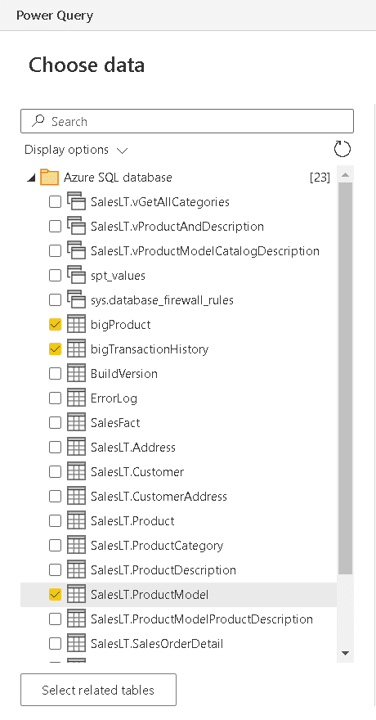
- On the Power Query window, under Choose Data, select the tables you will include in your Datamart. In this example, include bigTransactionHistory, bigProduct and SalesLT.ProductModel
- Click the Transform data button
- On the Power Query window, under Queries, click the table bigProduct
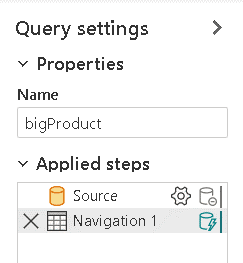
- On the Query Settings tab, rename it to Product
- Repeat the steps to rename the table bigTransactionHistory to TransactionHistory
- Select the Product table
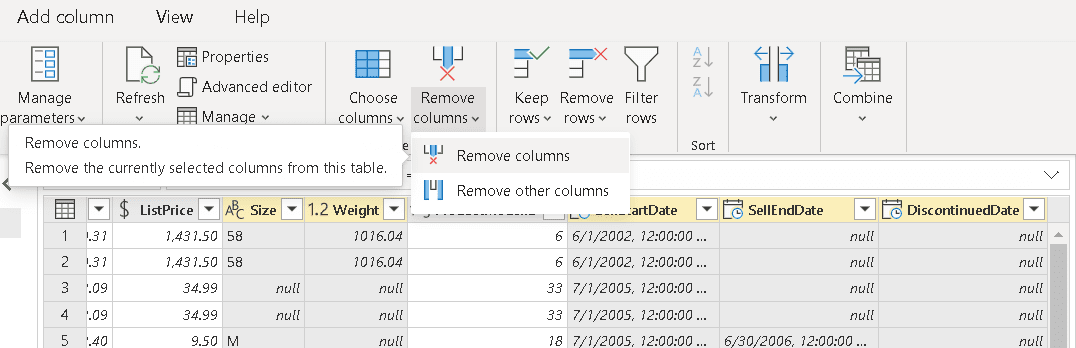
- Select the columns Size, Weight, SellStartDate, SellEndDate and DiscontinuedDate
- Use the button Remove Column to remove the unneeded columns
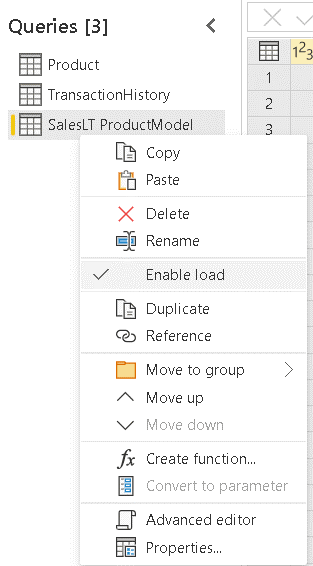
- Right-click the table SalesLT ProductModel
- Disable the option Enable Load
You will merge the information about the product model with the product details. You don’t need the ProductModel table as part of the model. When the Enable Load is disabled, the name of the table appears in Italic among the queries
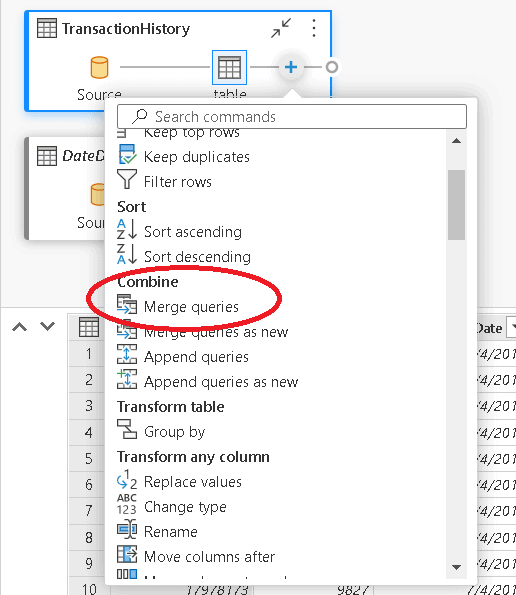
- Select the table Product
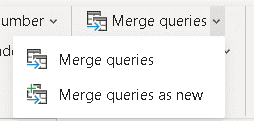
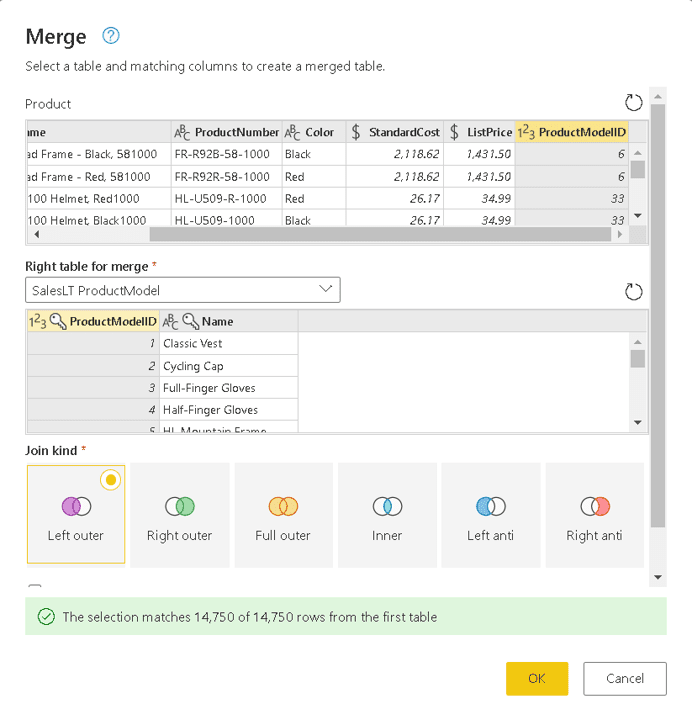
- Click the Merge queries button
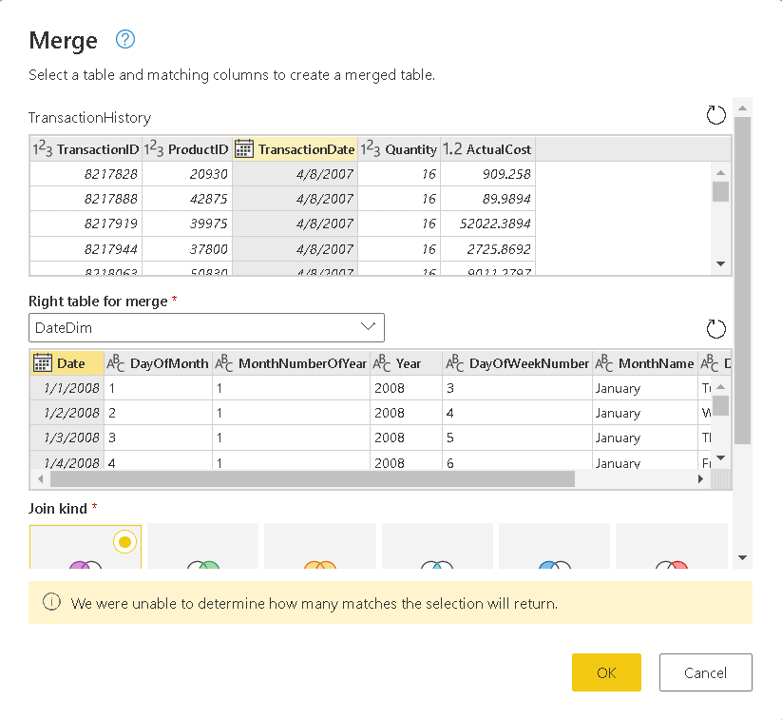
- On the Merge window, on the Right table for merge, select the table SalesLT ProductModel
- On the Merge window, Product table, select the ProductModelID field
- On the Merge window, SalesLT ProductModel table, select the ProductModelID table
- Once the match message appears in a green bar on the lower side of the window, click the Ok button
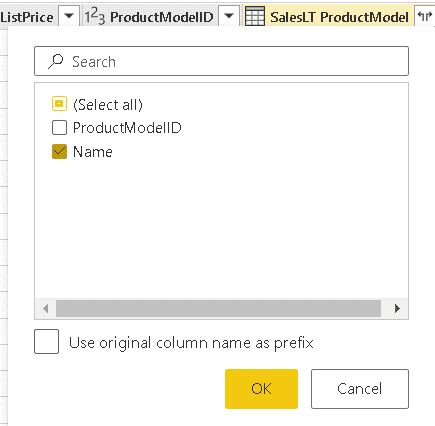
- On the new SalesLT ProductModel column, click the expand button
- On the window opened from the expand button, select the Name field, and uncheck all the others
- Click the OK button
- Double click the Name.1 column header and change the name to ProductModel
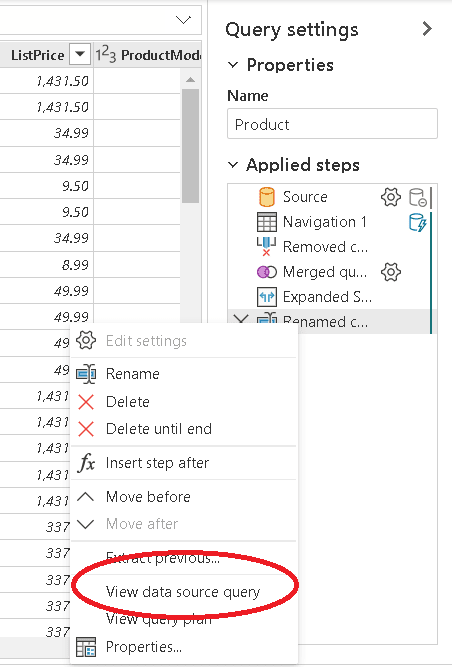
All the steps executed so far are registered on the properties window, Applied Steps. This is exactly how Power Query works, but until now this experience was available only on dataflows or in Power BI desktop.
One important performance detail about the steps is to know if the steps will be executed in the source database, converted into a single native query on the source database, or if the sequence of transformations prevent this.
The usual way to check this is to right click the last transformation and check if the option View Data Source Query is available. If it’s available, it means the transformations are good enough to be executed as a single native query.
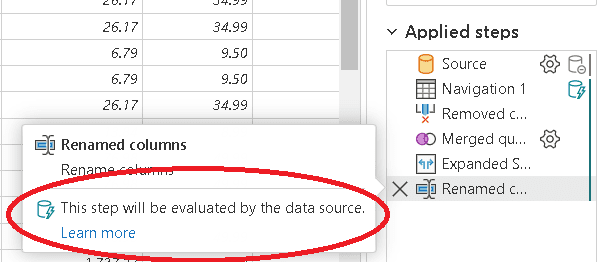
The UI in the portal has some additional features beyond the desktop UI. If you move the mouse over the last step, it tells you how the step will be executed. You can see the same on every step.
Creating the Datamart: Second stage, creating a date dimension
A model needs a date dimension. Every fact happens on a date and the date is an important dimension to analyse the fact. In this example, the TransactionDate column is found in the TransactionHistory table.
Why is the TransactionDate field is not enough, you may ask.
When analysing the facts, it might be analyzed by Year, Month, Day, Day of the week, and much more. If relying only on the TransactionDate field, you will need to create DAX measures, and this would impact the performance of your model.
Building a date dimension, which will be stored in the underlying Azure SQL Database for the Datamart, you will not have the need to build so many DAX expressions and the model will have better performance.
You could say there is a “not so old saying” about this: The better the underlying model, the fewer custom DAX expressions will be needed to build in the model. The date dimension is one great example of this, and the Datamart brings the possibility to create a better underlying model, leaving the DAX expressions only for dynamic calculations which really can’t be created in the underlying model.
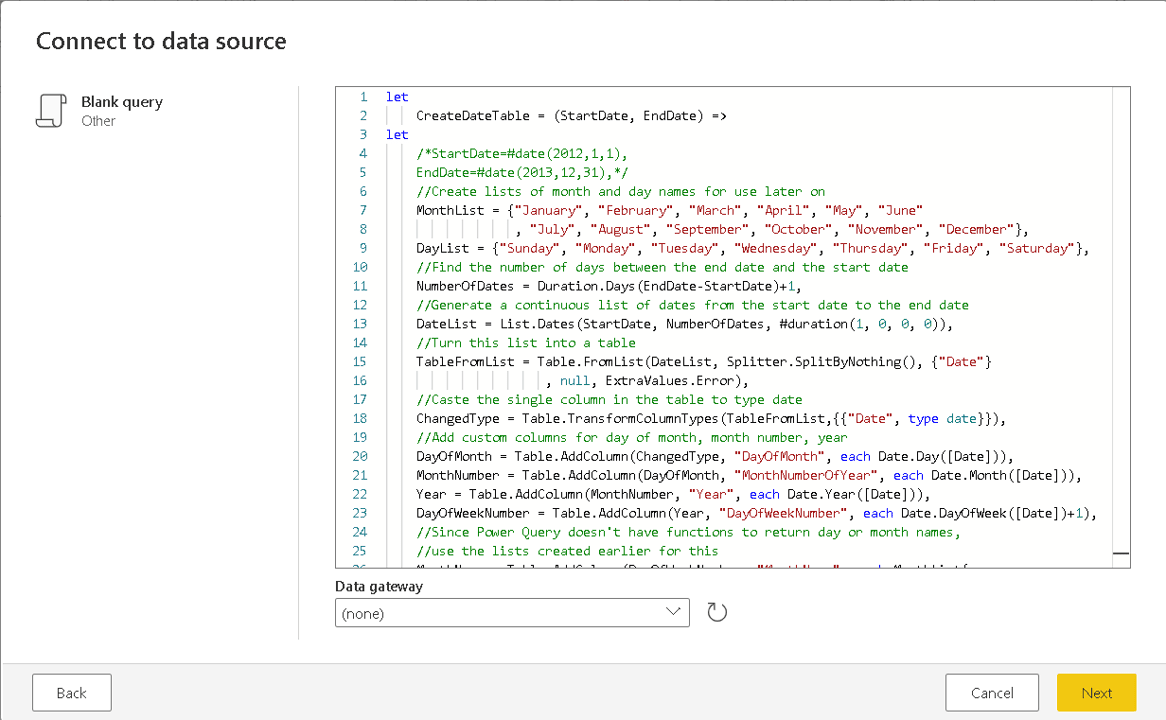
There are many different methods to create a date dimension. In this example, I will use the M scrips created by Chris Webb on the following blog: https://blog.crossjoin.co.uk/2013/11/19/generating-a-date-dimension-table-in-power-query/
Execute these step-by-step directions to create the date dimension:
- On the top menu, click New Query -> Blank Query
- Paste the query copied from Chris Webb’s blog above
- Click Next button
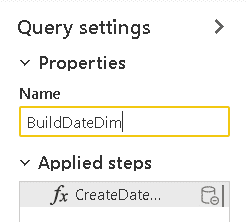
- In the Properties window, change the name of the new query to BuildDateDimension
You may notice this query is in fact a custom M function. The details about custom M functions are beyond this article, but you can learn more about them watch the recording of some technical sessions about advanced ETL with power query: https://www.youtube.com/watch?v=IjLlqTdF2bg&list=PLNbt9tnNIlQ6s597rRyoGx_sLn4rrHOzv
This function requires two parameters, StartDate and EndDate, to build the date dimension. You can provide these parameters dynamically, so you will always have an updated date dimension. On the next steps, retrieve these values from the TransactionHistory table.
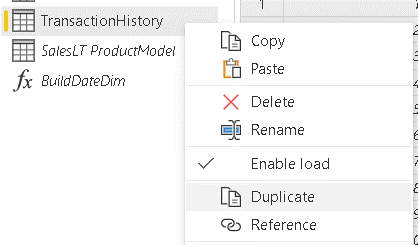
- Right click the TransactionHistory table and click the Duplicate option in the context menu
- Repeat the previous step, resulting in two copies of the TransactionHistory table.
Why duplicate and not reference? Since all the transformations will be converted to native queries anyway, duplicating makes it easy to convert each of the queries into an independent native SQL query. If you use reference, future changes to the source query would affect the new query.
I wrote a blog post exactly about this example, you can read more on https://ift.tt/NKvsbcW.
- Select the first duplicated query
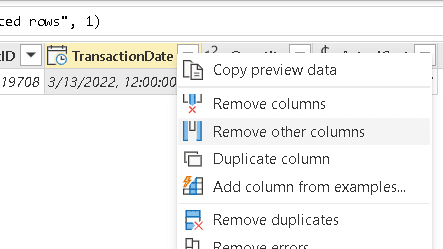
- Select the TransactionDate field
- Right-click the column header and click the Remove other columns in the context menu
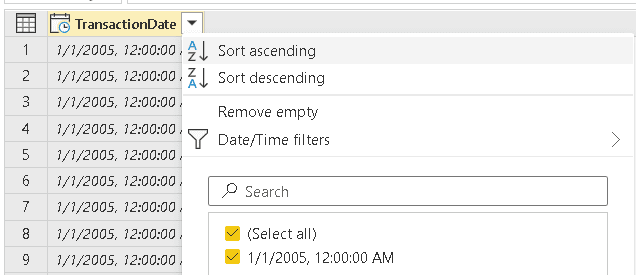
- Click the button on the TransactionDate header
- Click the Sort Ascending menu item
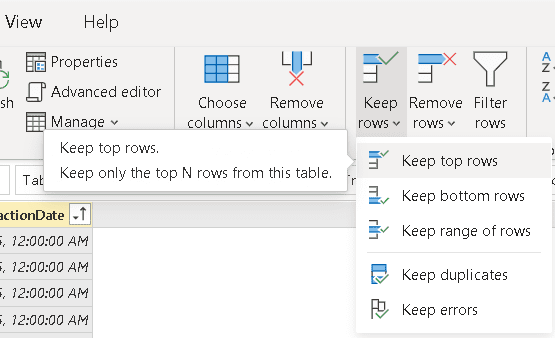
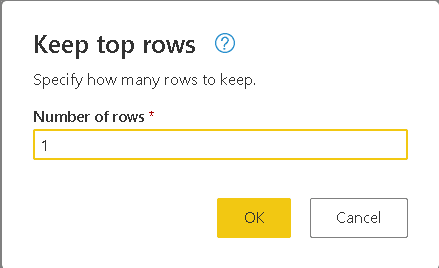
- Click the Keep top rows menu item
- On the Keep to Rows window, type 1
- Click the Ok button
- On the top menu, change the data type to Date
A date dimension should never include time. If your business needs time, you would need to create a time dimension and include date and time information in different fields
However, these sample tables don’t include time, so changing the data type just ignores the time.
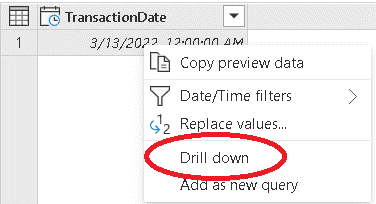
- Right-click the date value and select the item Drill down on the context menu
Even after reaching a single value, the result is still a table. The parameter for the function, on the other hand, needs to be a value. Using the Drill down option you are retrieving the date as a single value
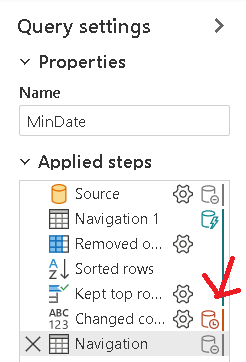
- Right-click the duplicated table you are working with and disable the option Enable Load
This query will be used only as parameter for the function, you don’t need it in the model. Besides this, if you don’t disable the load, the Power Query UI will convert the single value to table again, adding a new step to the query.
- Repeat the steps 33-43 for the 2nd duplicated query, but this time sorting the data in descending order
- Click the first duplicated table and rename it to MinDate
- Click the second duplicated table and rename it to MaxDate
The steps of these queries show some additional features. On the image below you may notice a red database symbol besides one step. This means that step will not be transformed into the native data source query. As a result, all the steps after it will also not be part of the native data source query, they will be executed by Power BI.
On this example, these are the last steps, conversion of the last value retrieved, so there is no problem at all
- Select the BuildDateDimension function
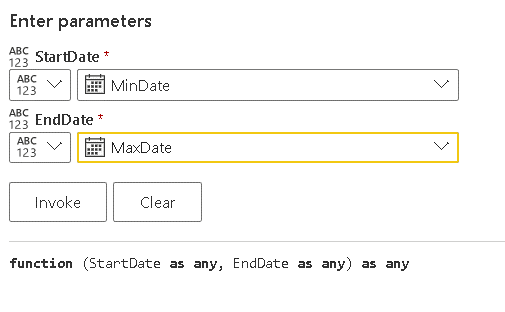
- On the button besides the StartDate parameter, change the option to query
- On the StartDate drop down, select the MinDate query
- On the button besides the EndDate parameter, change the option to query
- On the EndDate drop down, select the MaxDate query
- Click the Invoke function
A new query will be created using the M code needed to invoke the function, what will produce the date dimension
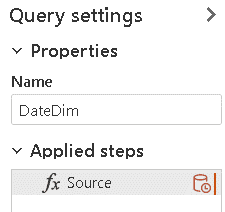
- Rename the new query as DateDim
- Click the Save button
After clicking the save button, the data will be loaded into the Datamart.
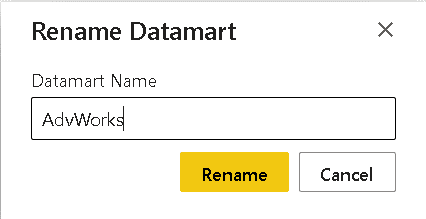
Renaming the Datamart
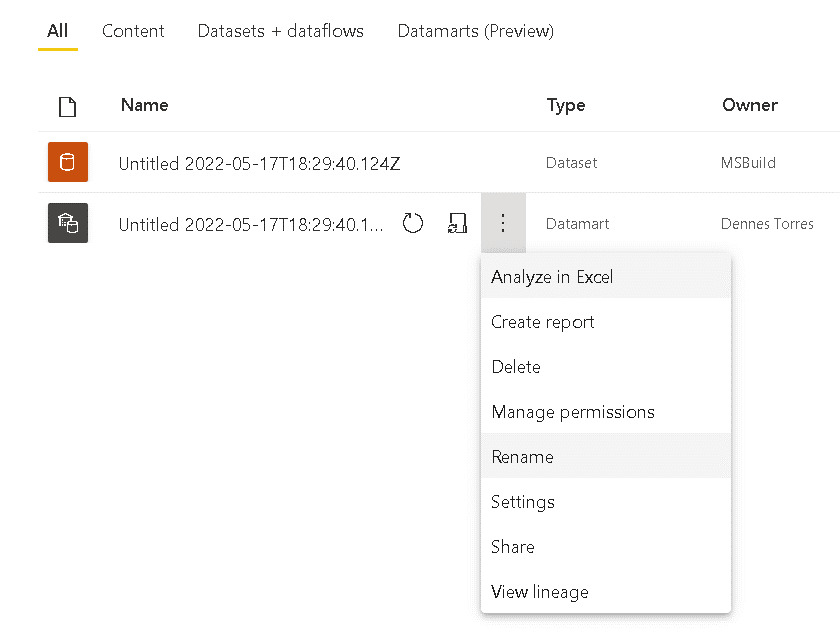
The Datamart is created with an auto-generated name. At some point you would like to rename the Datamart.
Clicking on the workspace name in the list of workspaces on the left side, you will see the Datamart and the auto-generated dataset.
On the Datamart menu, you will find a Rename command.
Once you rename the Datamart, the auto-generated dataset will be renamed at the same time.
Building the model
The fourth tab on the lower toolbar inside the Datamart is the Model tab. On this tab, you can make model configurations for the tables. It’s time to build the model.
- Click the Model tab
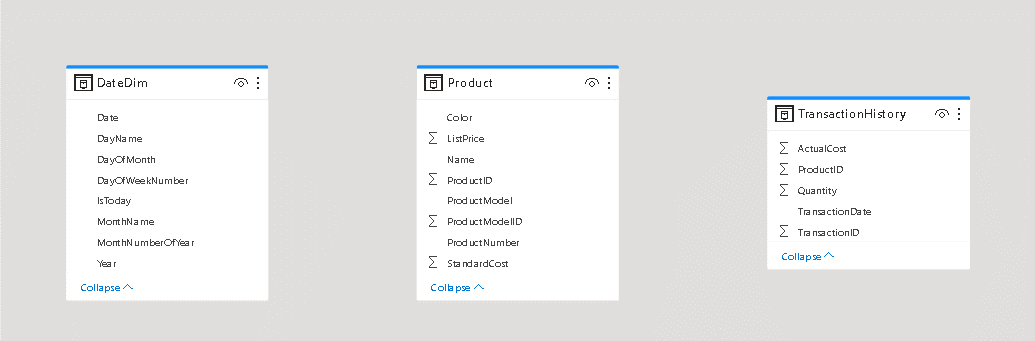
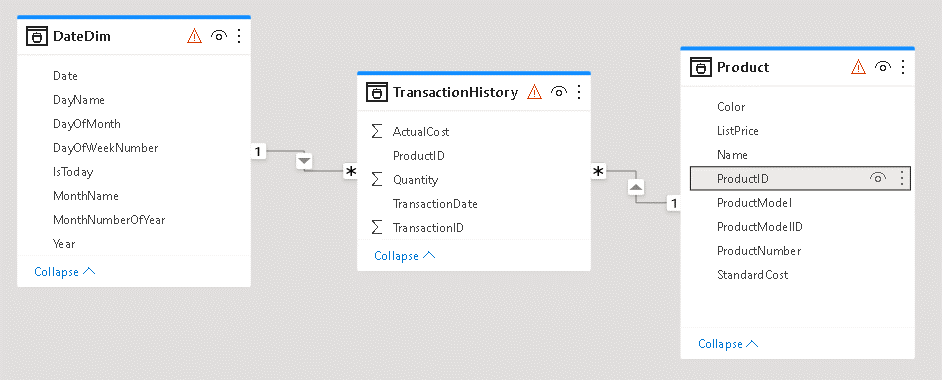
- Organize the tables, leaving the fact table, TransactionHistory, in the middle.
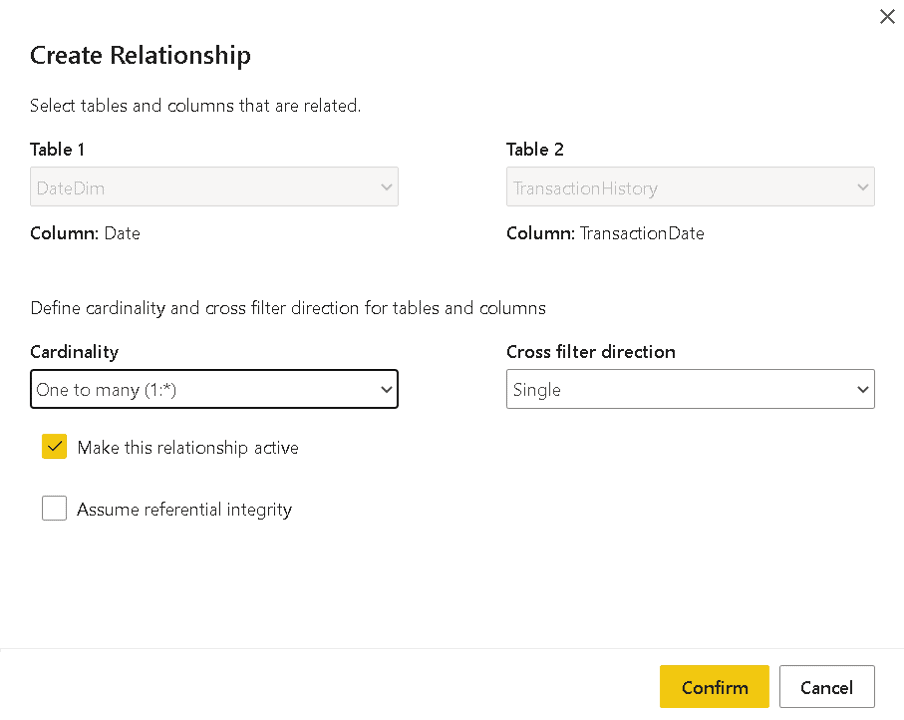
- Drag the Date field from DateDim table to the TransactionDate field in the TransactionHistory table
- On the Create Relationship window, adjust the cardinality of the relationship. It needs to be 1 to many from DateDim to TransactionHistory
- Drag the ProductId field from the Product table to the ProductId field on the TransactionHistory table
- On the Create Relationship window, adjust the cardinality of the relationship. It needs to be 1 to many from Product to TransactionHistory
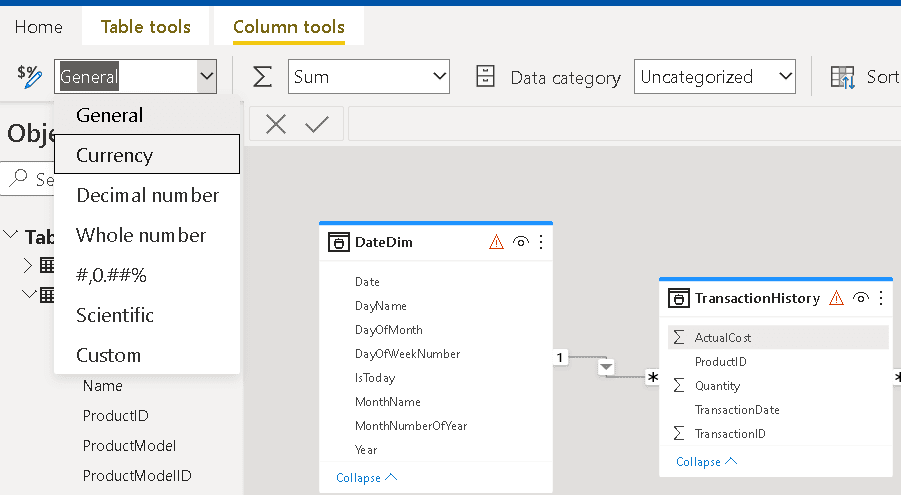
- Select the ActualCost field in the TransactionHistory table
- On the top toolbar, change the format of the field to Currency
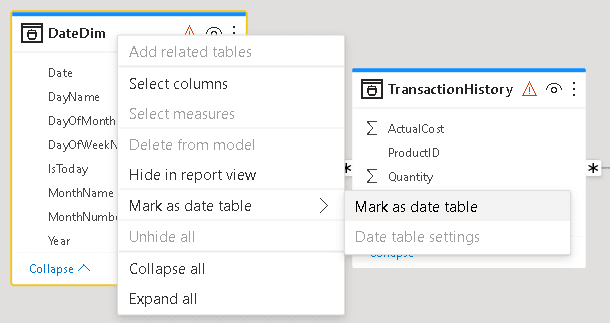
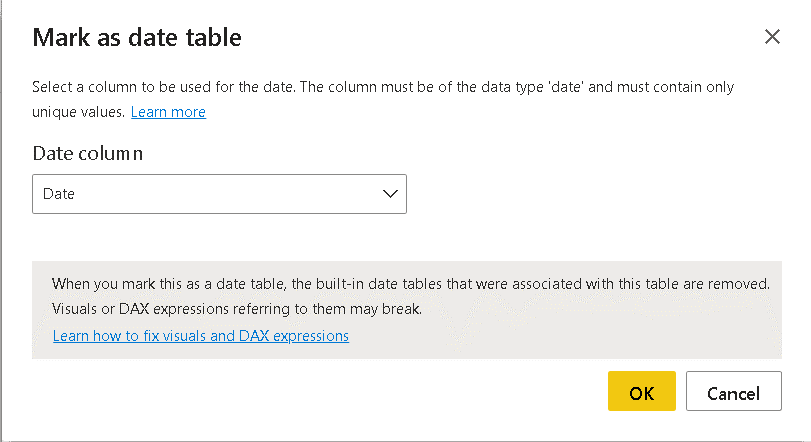
- Right click the DateDim table and click the menu item Mark as Date Table
- On the Mark as Date Table window, select the Date field
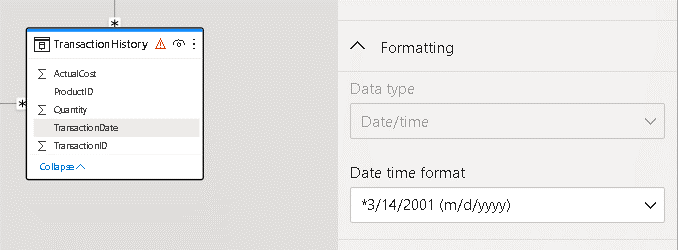
- Select the TransactionDate field in the TransactionHistory table.
- On the Properties window located on the right side, under Formatting, select the date format containing only the date
- Select the Date field in the DateDim table
- On the properties window located on the right side, under Formatting, select the date format containing only the date
The newly built model will be stored in the auto-generated dataset created together in the Datamart. This dataset can become the base model for all users of the Datamart. Of course, there are many modelling features still missing, such as hierarchies and aggregation tables, but it’s a good start.
Exploratory Analysis: The Design tab
The Design tab is one of the two tabs available to allow exploring the data in the Datamart. Here’s a small example:
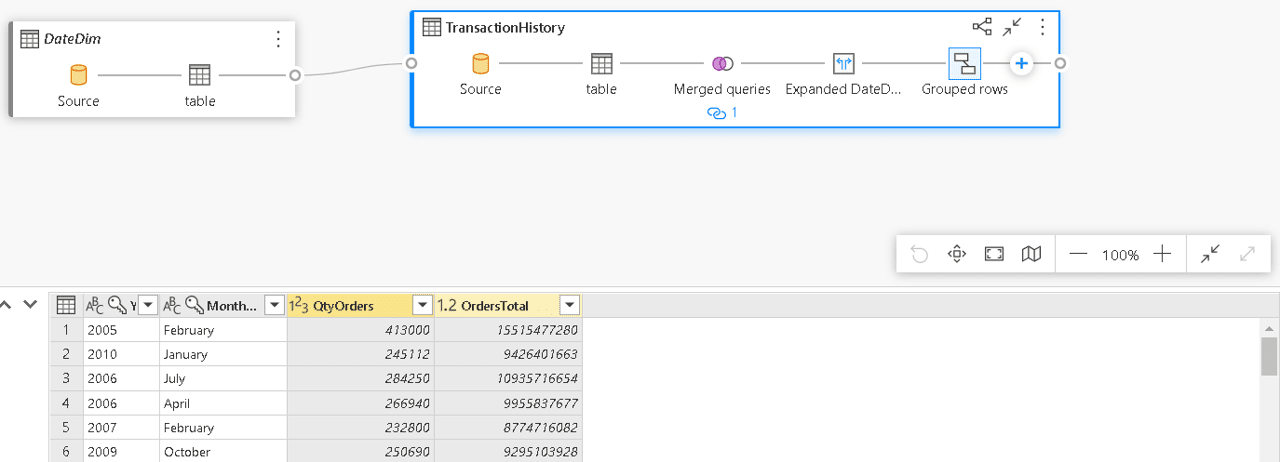
- Drag the TransactionHistory table to the middle of the Design tab
- Drag the DateDim table to the middle of the Design tab
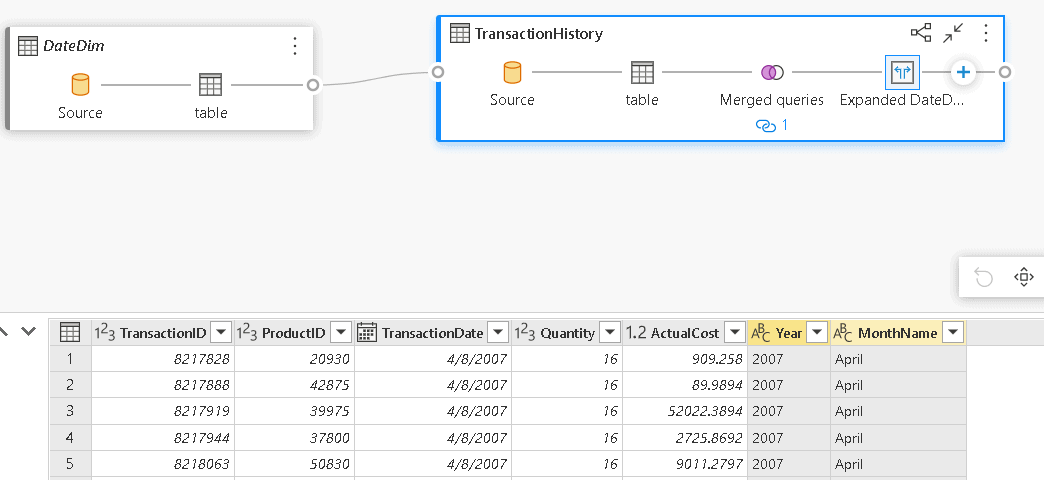
- Click the “+” sign on the TransactionHistory table and select the Merge queries option
- On the Merge window, under the Right table for merge, select the DateDim table
- On the Merge window, in the TransactionHistory table, select the TransactionDate field
- On the Merge window, in the DateDim table, select the Date field
- Click the Ok button
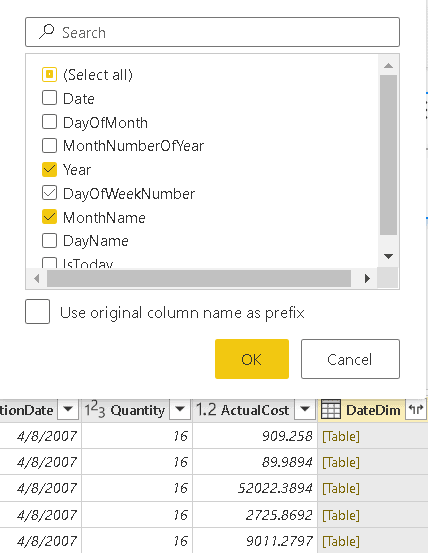
- On the lower window with the table visualization, click the Expand button besides the new DateDim column
- On the window with the field names to expand, uncheck all the fields and check only Year and MonthName
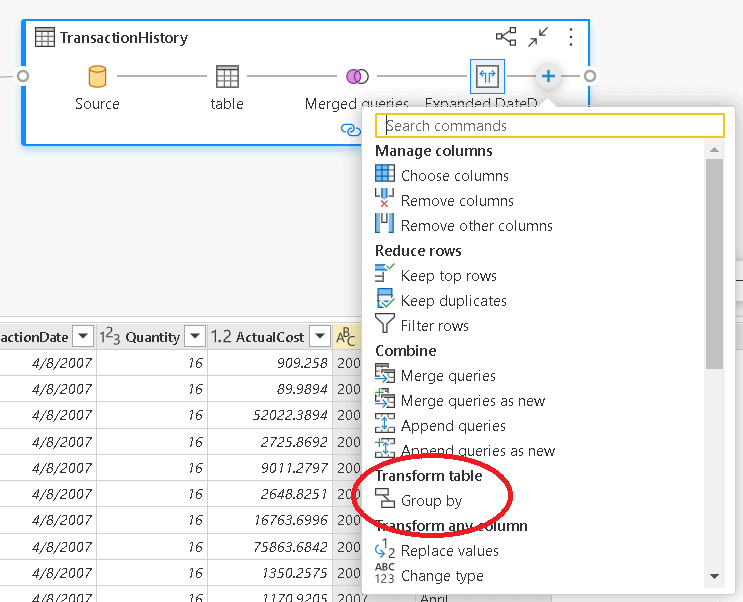
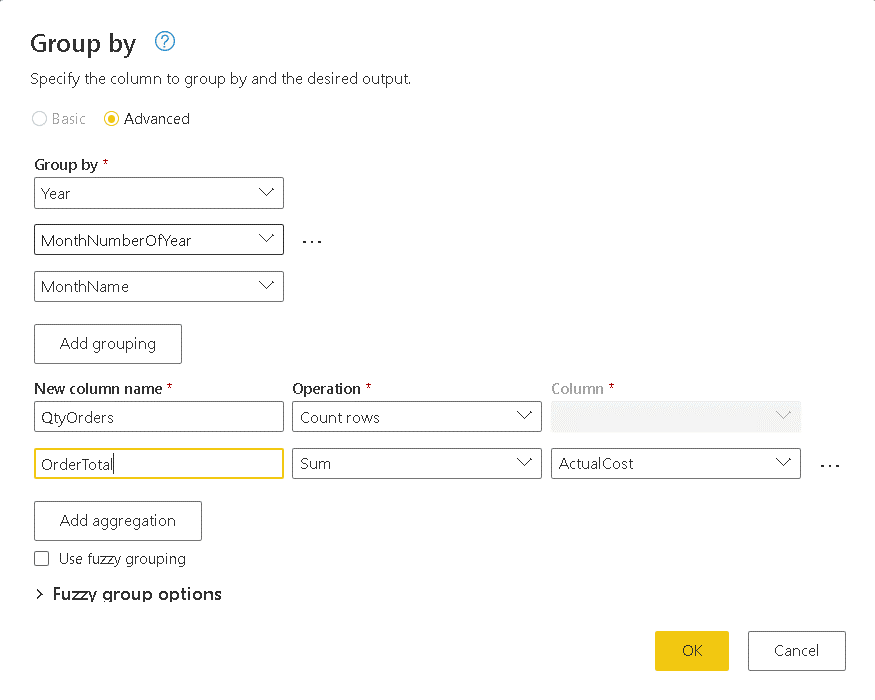
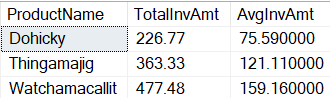
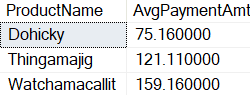
- On the merged query, click the “+” sign and select the Group By option
- On the Group By window, select the option Advanced
- On the Group By window, click the Add Grouping button once to complete 3 grouping fields
- On the Group By window, click the Add aggregation button once to complete 2 aggregation fields
- On the Group By window, select Year, MonthNumberOfYear and MonthName as the 3 grouping fields
- Under New Column Name, type QtyOrders
- On Operation drop down to the right of QtyOrders, select Count Rows
- On the 2nd New Column Name, type OrdersTotal
- On the Operation drop down to the right of OrdersTotal, select Sum
- On the Column drop down, to the right of Sum operation, select ActualCost
- Click Ok button
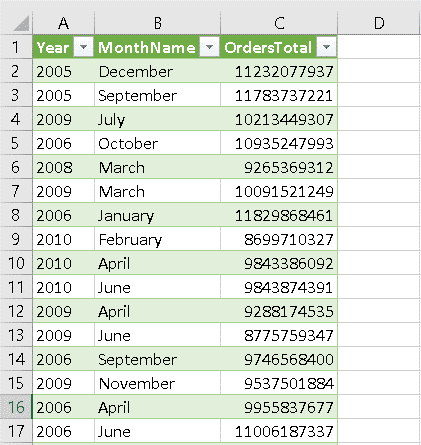
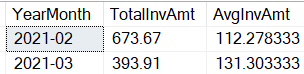
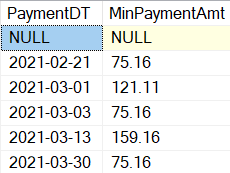
As a result, you have the total of the orders by month
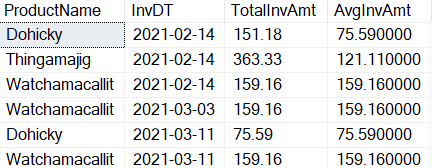
Exploratory Analysis: The SQL tab
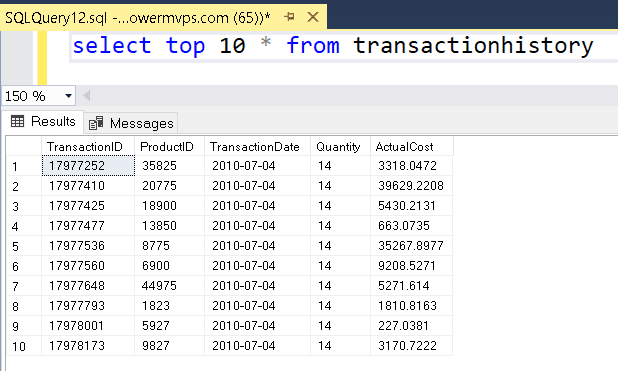
The 2nd tab which allows exploratory analysis is the SQL table. You can execute SQL statements over the Datamart
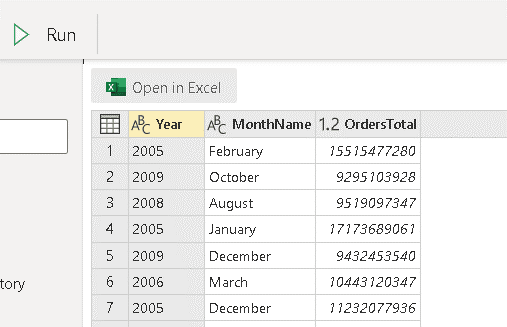
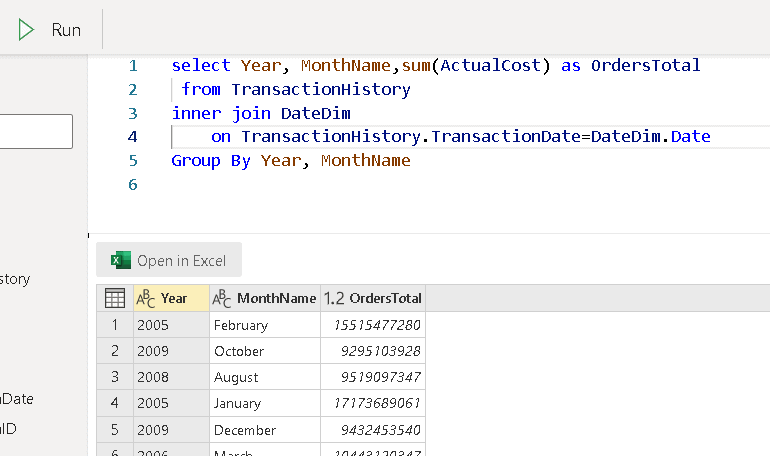
Type the following statement on the SQL tab:
select Year, MonthName,sum(ActualCost) as OrdersTotal
from TransactionHistory
inner join DateDim
on TransactionHistory.TransactionDate=DateDim.Date
Group By Year, MonthName
Click the Run button to execute the query
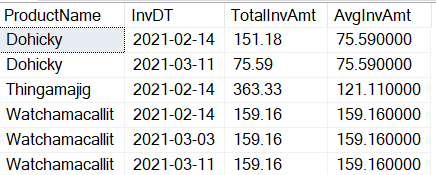
At the moment I’m writing this article, the results window still has a small secret. You can view the results together with the SQL statement, but you need to resize the window from top to bottom for that.
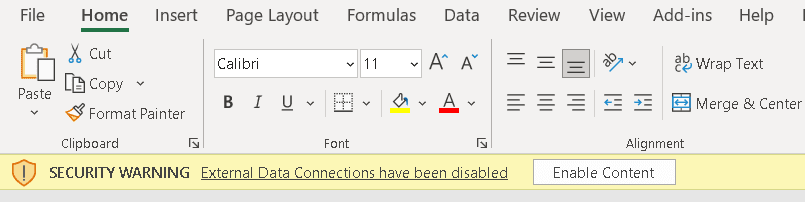
The user can click the Excel button to open the query result in Excel
An Excel file will be downloaded. Once you open it, you will need to click the button Enable Editing. After that, a second message will appear, and you will need to click the button Enable Content.
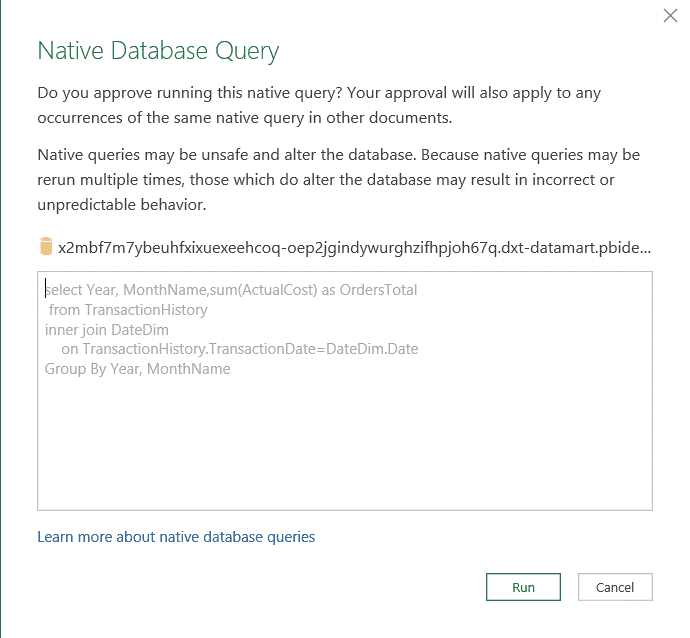
Excel will connect directly to the Azure SQL Database and execute the query. The user using Excel needs permission to connect to the underlying Azure SQL Database.
On the Native Database Query window, click the Run button. The query will be executed, and the result inserted in Excel.
Yes, you have access to SQL
The Power BI Datamarts underlying technology is an Azure SQL database. After all the exploratory analysis features mentioned above, the icing on the cake is a direct connection to Azure SQL Database.
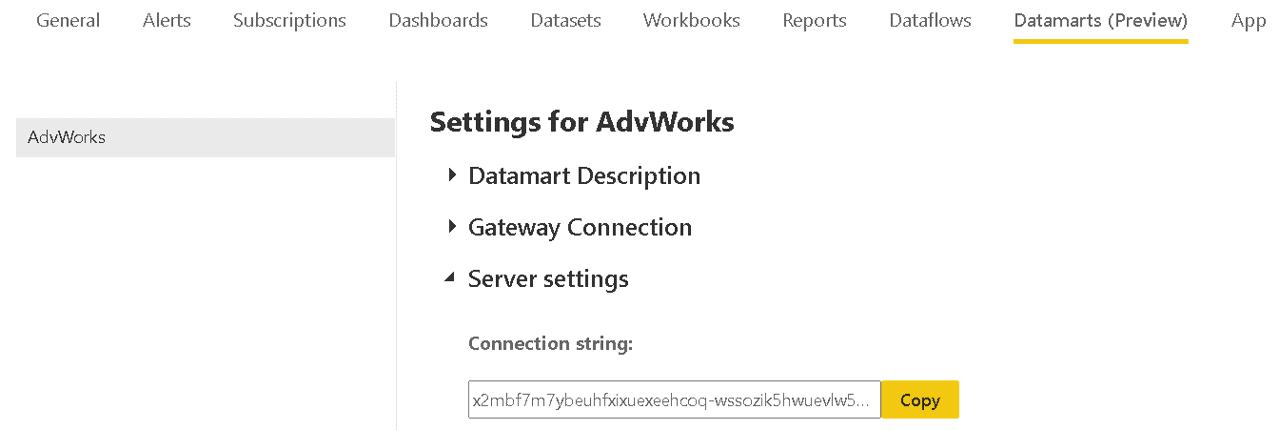
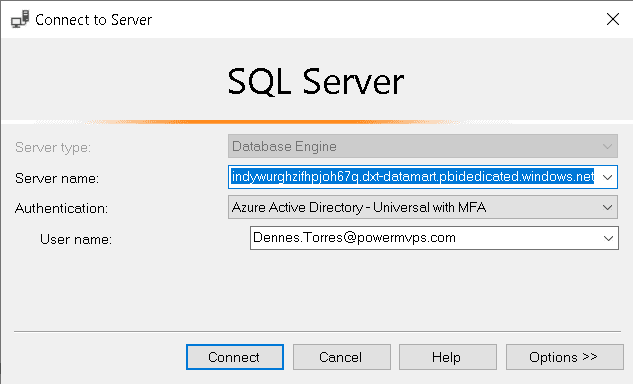
First, you need to locate the connection string for the Azure SQL Database. In the Datamart settings, under Server Settings, you can find the connection string and copy it to be used for connection in another application. For example, you can use SSMS, paste this connection on SSMS connection string to access the Azure SQL Database.
The authentication is made with Active Directory – Universal with MFA. The login is the Power BI login.
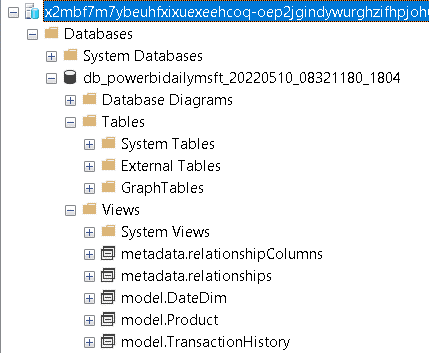
You may notice there are no tables in the database, only views. All the tables created in the model appear as views. The database is completely read only, but the ability to connect to the Datamart using any tool capable to connect to SQL is a very powerful feature.
On my blog about Power BI and ETL, one of my arguments was the fact the ETL in Power BI was only capable to save the data to Power BI. The evolution of the technology always makes the borders between different technologies more difficult to find. I may need to update that article soon.
Using the Datamart to build reports
The Datamart should become the central single source of truth for one area of the company. Whether the Datamart is built using a top-down or bottom-up approach, it’s still a central single source of truth.
For example, if the Datamart is using the bottom-up approach, it will be the central point to integrate all user’s data sources, such as excel, sharepoint lists and many kinds of data sources starting from a small spreadsheet and growing in an uncontrolled rate. It will not be the central point for the entire company, but for one company branch, for example.
On the other hand, in a top-down approach the Datamart is built as a subset of the company data warehouse. This subset may be focused on one branch, and it will be the single source of truth to this branch.
These are some important points which makes the Datamart a good local single point of truth:
- Calculations which in other ways would be made using DAX formulas and turn the model slower, can be done using physical tables and result in a better model
- The model stored in the auto-generated dataset can be used as a base for all local reports and additional models.
- There are many features for exploratory analysis, including direct SQL access to the data
There are three different methods to use the Datamart:
- Use the portal to create reports based on the auto-generated dataset
The reports will be using the auto-generated dataset directly. Depending on the number of different departments using the auto-generated dataset, this may not be the best solution
- Create reports directly accessing the underlying Azure SQL connection
This is a very good solution, but every report solution using this direct connection would need to build the model again, without re-using the model already built in the auto-generated dataset
- Use Power BI desktop to create reporting solutions using the auto-generated dataset as a source
This is probably the best solution for the use of the Datamart. You will be able to re-use the model built in the auto-generated dataset and customize it with additional information needed.
Summary
The Datamarts are more than a very powerful feature, it’s also a critical point in the Power BI evolution. More consistent data exploration tools and consistent tools to create a local single source of truth. It has the potential to change the architectures used to build in Power BI, and I believe everyone all will be looking forward to the new features to come.
The post Datamarts and exploratory analysis using Power BI appeared first on Simple Talk.
from Simple Talk https://ift.tt/ZOizBoW
via




![An image showing Queries [3] bigProduct, bigTransactionHistory, and SalesLT ProductModel](https://www.red-gate.com/simple-talk/wp-content/uploads/2022/05/graphical-user-interface-text-application-email-2.png)