Imagine that while developing or testing a SQL Server database, you get an error message mentioning a database object, and you scratch your head, and mutter ‘by the bones of the saints, what is that?’. If it is a small database, then you can glance, maybe, at the browser pane. Once it gets to any size, you’ve got to search the metadata. If you know it is a column than you can look in information_schema.Columns or in sys.columns, but if you don’t know, or if you want to know more about the column, you’re into a certain difficulty. Someone has probably explained what the column does in an extended property. What table or view is it in? what else is in the table?
Finding things in databases isn’t always straightforward. You might think that you can just search the database objects in SQL Server. No, because user types, for example are stored elsewhere, despite being schema-bound. You might want to search in the scheduled jobs too, but there is no way of working out whether the code in a job step relates to a particular database. You might think that the information_schema represented a consistent industry standard, providing a rational logical layer over the seething reality underneath. You might be wrong.
SQL Server, like all RDBMSs, grow in rather strange way, sometimes in response to the esoteric needs of a major customer, the hobbyhorse of a senior manager, or to head off an industry-trend such as NoSQL or Big Data. We have to make retrospective sense of it all.
SQL Server has the concept of a parent object. This roughly corresponds to table, view and module (aka Routine). These parent objects have child objects, which correspond to constraints, and triggers. Internal tables can be either, depending on whether they are queue messages or XML Index nodes that do, or otherwise don’t.
Columns, indexes or parameters aren’t objects. They are treated as ordered lists of attributes to one particular type. Types are schema-based but they aren’t objects. Databases have attributes that aren’t schema-based but which apply to the database as a whole, such as datafiles or dataSpaces. You see some of them in the CREATE database statements in generated scripts.
All this might seem complicated, but I’ve done it for you. I’ve created two SQL Server routines. One is a Table-valued function that list database objects and their paths, and the other is a view that lists the database attributes as well.
You might use the schemaObjects function by itself if you aren’t interested in the database properties, just the database metadata. The obvious way of searching is this. Want to find out where the database processes credit cards?
SELECT Name, path, Comment FROM SchemaObjects () WHERE Name + comment LIKE '%credit%' ORDER BY path;
…which gives you (in AdventureWorks) the following
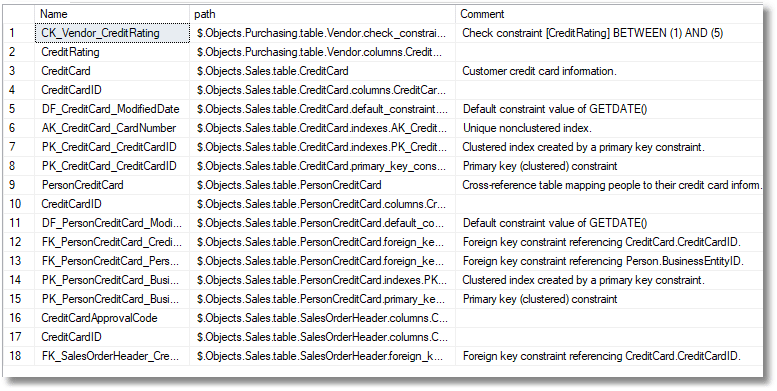
The ‘path’ column gives you a reasonable sort order, except for the order of columns. It comes in handy for searching for a specific database object type, or for, say, the foreign key for a particular table.
Here we are trying to find out all the foreign keys in person.BusinessEntityAddress
SELECT Name, path, Comment FROM SchemaObjects () WHERE path LIKE '%.foreign_key_constraint.%' AND path LIKE '%person.table.BusinessEntityAddress%';

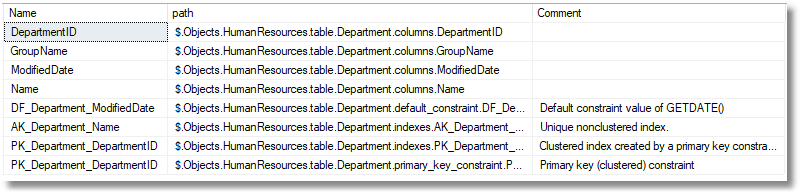
Maybe you just want to see what is in a table
SELECT Name, path, Comment FROM SchemaObjects () WHERE path LIKE '%humanresources.table.Department.%' ORDER BY path;
So here is the source of the application. If it is updated, the latest version will be in the Gloop project TheGloopSQLServerDatabaseDocumenter/SearchDatabase.sql
GO
CREATE OR ALTER FUNCTION dbo.SchemaObjects
(
/**
Summary: >
Returns all the schema objects, their name, path and so on.
Author: Phil Factor
Date: Tuesday, 28 June 2022
Examples:
- Select * from SchemaObjects() order by path
- Select Name, path, Comment from SchemaObjects() where Name+comment like '%credit%' order by path
- Select Name, path, Comment from SchemaObjects() where path like '%person.table.businessentity.%'
- Select Name, path, Comment from SchemaObjects() where path like '%.foreign_key_constraint.%'
Returns: >
table
**/
) RETURNS @FoundObjects TABLE
(TableOrderType INT,
object_id INT,
minor_id INT,
TheType CHAR(2),
SQL_Name NVARCHAR(400),
"Name" sysname,
"path" NVARCHAR(400),
comment NVARCHAR(3870))
AS
BEGIN
INSERT INTO @FoundObjects
(TableOrderType, object_id, minor_id, TheType, SQL_Name, "Name",
"path", comment)
SELECT --objects
-- SQL Prompt formatting off
CASE WHEN ob.parent_object_id >0 THEN 10 ELSE 0 END AS TableOrderType,
ob.object_id, CASE WHEN ob.parent_object_id >0 THEN 1 ELSE 0 END AS minor_id, ob.type AS TheType,
CASE WHEN ob.parent_object_id>0
THEN Object_Schema_Name(ob.parent_object_id)
+ '.'+Object_Name(ob.parent_object_id)+'.'+ob.name
ELSE Object_Schema_Name(ob.object_id)+'.'+ob.name
END AS SQL_Name,ob.name AS name,
'$.Objects.'+Object_Schema_Name(ob.object_id) +
CASE WHEN ob.parent_object_id>0 THEN
CASE WHEN pa.type IN ('TF','FN','IF','FS','FT') THEN '.function'
WHEN pa.type IN ('P', 'PC','RF','X') THEN '.procedure'
WHEN pa.type IN ('U','IT') THEN '.table'
WHEN pa.type='SQ' THEN '.queue'
ELSE '.'+Lower(pa.type_desc)
END +'.' +pa.name+'.' ELSE '.'
END+
CASE WHEN ob.type IN ('TF','FN','IF','FS','FT') THEN 'function'
WHEN ob.type IN ('P', 'PC','RF','X') THEN 'procedure'
WHEN ob.type IN ('U','IT') THEN 'table'
WHEN ob.type='SQ' THEN 'queue'
ELSE
Lower(ob.type_desc)
END+'.'
--+ CASE WHEN ob.parent_object_id>0
-- THEN Object_Name(ob.parent_object_id) COLLATE DATABASE_DEFAULT+'.'
-- ELSE ''
-- END
+ ob.name AS "path",
-- SQL Prompt formatting on
Coalesce (Convert (NVARCHAR(3870), ep.value), '') AS comment
FROM
sys.objects ob
LEFT OUTER JOIN sys.objects pa
ON pa.object_id = ob.parent_object_id
LEFT OUTER JOIN sys.extended_properties ep
ON ep.major_id = ob.object_id
AND ep.class = 1
AND ep.minor_id = 0
AND ep.name = 'MS_Description'
WHERE
ob.is_ms_shipped = 0 AND ob.is_ms_shipped = 0
UNION ALL
SELECT 0, 0, xc.xml_collection_id, 'XT',
Schema_Name (xc.schema_id) + '.' + xc.name, xc.name,
'$.types.' + Schema_Name (xc.schema_id)
+ '.xml_Schema_collection.' + xc.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '') AS comment
FROM
sys.xml_schema_collections xc
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 10
AND ep.major_id = xc.xml_collection_id
AND ep.name = 'MS_Description'
WHERE xc.xml_collection_id > 65535
UNION ALL
SELECT 0, 0, UT.user_type_id, 'UT',
Schema_Name (UT.schema_id) + '.' + UT.name, UT.name,
'$.types.' + Schema_Name (UT.schema_id) + '.user_types.' + UT.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '') AS comment
FROM
sys.types UT
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 6
AND ep.major_id = UT.user_type_id
AND ep.name = 'MS_Description'
WHERE
UT.user_type_id <> UT.system_type_id
AND Schema_Name (UT.schema_id) <> 'sys';
INSERT INTO @FoundObjects
(TableOrderType, object_id, minor_id, TheType, SQL_Name, "Name",
"path", comment)
SELECT 7, F.object_id AS "OBJECT_ID", ix.index_id AS Minor_id, 'IX',
F.SQL_Name + '.' + ix.name, ix.name,
F.path + '.indexes.' + ix.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
@FoundObjects F
INNER JOIN sys.indexes ix
ON F.object_id = ix.object_id
LEFT OUTER JOIN sys.extended_properties ep
ON ep.major_id = ix.object_id
AND ep.class = 7
AND ep.name = 'MS_Description'
WHERE
ix.index_id > 0 AND ep.minor_id = ix.index_id
UNION ALL
SELECT 2, F.object_id AS "OBJECT_ID", par.parameter_id AS Minor_id, 'PA',
F.SQL_Name + '.' + par.name, par.name,
F.path + '.parameters.' + par.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
@FoundObjects F
INNER JOIN sys.parameters par
ON F.object_id = par.object_id
LEFT OUTER JOIN sys.extended_properties ep
ON ep.major_id = par.object_id
AND ep.class = 2
AND ep.name = 'MS_Description'
AND ep.minor_id = par.parameter_id
WHERE par.parameter_id > 0
UNION ALL
SELECT 3, F.object_id AS "OBJECT_ID", Col.column_id AS Minor_id, 'CO',
F.SQL_Name + '.' + Col.name, Col.name,
F.path + '.columns.' + Col.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
@FoundObjects F
INNER JOIN sys.columns Col
ON F.object_id = Col.object_id
LEFT OUTER JOIN sys.extended_properties ep
ON ep.major_id = Col.object_id
AND ep.class = 2
AND ep.name = 'MS_Description'
AND ep.minor_id = Col.column_id;
RETURN;
END;
GO
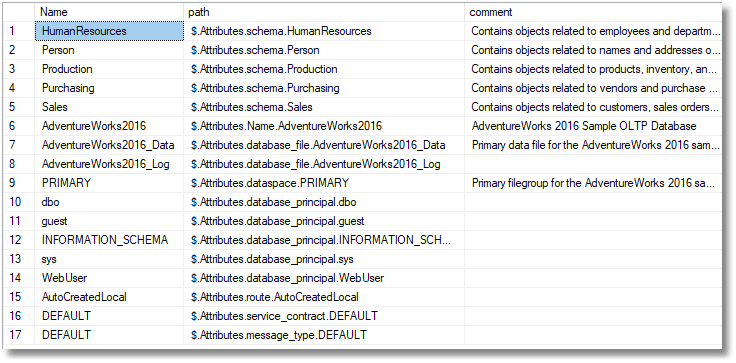
The view adds the attributes at database level. Of course, there aren’t going to be many of these in a sample database but here goes
Select * from The_Metadata where path like ‘$.Attributes%’
CREATE OR ALTER VIEW The_Metadata
/**
Summary: >
This is a view of all the database-level attributes
of the current database
Author: Phil Factor
Date: Tuesday, 28 June 2022
Database: AdventureWorks
Examples:
-Select Name, Path, Comment from The_Metadata where name+' '+comment like '%credit%' order by path
-Select * from The_Metadata where path like '$.Attributes%'
Returns: >
table
**/
AS
SELECT Name, path, comment FROM SchemaObjects ()
UNION ALL
SELECT --schemas
sch.name, '$.Attributes.schema.' + sch.name AS Attribute,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.schemas sch
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 3
AND ep.major_id = sch.schema_id
AND ep.name = 'MS_Description'
WHERE
sch.schema_id > 4 AND sch.name NOT LIKE 'DB%'
UNION ALL --Database
SELECT f.Object, '$.Attributes.Name.' + f.Object,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM (VALUES (Db_Name (), 'database')) f ("Object", "type")
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 0 AND ep.name = 'MS_Description'
UNION ALL
SELECT --Database Files
df.name, '$.Attributes.database_file.' + df.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.database_files df
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 22
AND ep.major_id = df.file_id
AND ep.name = 'MS_Description'
UNION ALL
SELECT --Data Spaces
ds.name, '$.Attributes.dataspace.' + ds.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.data_spaces ds
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 20
AND ep.major_id = ds.data_space_id
AND ep.name = 'MS_Description'
UNION ALL
SELECT --USER
dp.name, '$.Attributes.database_principal.' + dp.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.database_principals dp
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 4
AND ep.major_id = dp.principal_id
AND ep.name = 'MS_Description'
WHERE dp.type = 'S'
UNION ALL
SELECT --PARTITION FUNCTION
pf.name, '$.Attributes.partition_function.' + pf.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.partition_functions pf
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 21
AND ep.major_id = pf.function_id
AND ep.name = 'MS_Description'
UNION ALL
SELECT --REMOTE SERVICE BINDING
rsb.name, '$.Attributes.remote_service_binding.' + rsb.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.remote_service_bindings rsb
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 18
AND ep.major_id = rsb.remote_service_binding_id
AND ep.name = 'MS_Description'
UNION ALL
SELECT --Route
rt.name, '$.Attributes.route.' + rt.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.routes rt
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 19
AND ep.major_id = rt.route_id
AND ep.name = 'MS_Description'
UNION ALL
SELECT --Service
sv.name COLLATE DATABASE_DEFAULT, '$.Attributes.service.' + sv.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.services sv
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 17
AND ep.major_id = sv.service_id
AND ep.name = 'MS_Description'
WHERE sv.name NOT LIKE 'http://schemas.microsoft.com/SQL%'
UNION ALL
SELECT -- 'CONTRACT'
svc.name COLLATE DATABASE_DEFAULT,
'$.Attributes.service_contract.' + svc.name COLLATE DATABASE_DEFAULT,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.service_contracts svc
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 16
AND ep.major_id = svc.service_contract_id
AND ep.name = 'MS_Description'
WHERE svc.name NOT LIKE 'http://schemas.microsoft.com/SQL%'
UNION ALL
SELECT -- 'MESSAGE TYPE'
smt.name,
'$.Attributes.message_type.' + smt.name COLLATE DATABASE_DEFAULT,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.service_message_types smt
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 15
AND ep.major_id = smt.message_type_id
AND ep.name = 'MS_Description'
WHERE smt.name NOT LIKE 'http://schemas.microsoft.com/SQL%'
UNION ALL
SELECT -- 'assembly'
asy.name, '$.Attributes.assembly.' + asy.name COLLATE DATABASE_DEFAULT,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.assemblies asy
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 5
AND ep.major_id = asy.assembly_id
AND ep.name = 'MS_Description'
WHERE asy.name NOT LIKE 'Microsoft.SqlServer.Types'
UNION ALL
SELECT --'CERTIFICATE'
cer.name, '$.Attributes.certificate.' + cer.name, ''
FROM sys.certificates cer
UNION ALL
SELECT --'ASYMMETRIC KEY'
amk.name, '$.Attributes.asymmetric_key.' + amk.name, ''
FROM sys.asymmetric_keys amk
UNION ALL
SELECT --'SYMMETRIC KEY'
smk.name, '$.Attributes.symmetric_key.' + smk.name, ''
FROM sys.symmetric_keys smk
UNION ALL
SELECT -- 'PLAN GUIDE'
pg.name, '$.Attributes.plan_guide.' + pg.name,
Coalesce (Convert (NVARCHAR(3870), ep.value), '')
FROM
sys.plan_guides pg
LEFT OUTER JOIN sys.extended_properties ep
ON ep.class = 27
AND ep.major_id = pg.plan_guide_id
AND ep.name = 'MS_Description';
GO
Conclusion
If you are like me, you will tend to do ad-hoc searching via SQL Calls that are written for the immediate purpose. They aren’t always good for their purpose and I weas inspired to write this so as to be able to do path-based searches and to be able to see the comments (extended properties.) It is based various routines I’d needed for another purpose so it is good to pull it all into shape for this function and view.
The post Searching through a database via SQL appeared first on Simple Talk.
from Simple Talk https://ift.tt/VeCMIgG
via

 Figure 1. Retrieving all rows and columns from the
Figure 1. Retrieving all rows and columns from the