The Auto-Shutdown policy is another important policy to ensure our virtual machines don’t expend more than what we planned for them. If we have a time window to use the virtual machines, the auto-shutdown policy can deactivate them at the right time.
We need to discover the deep internal details about the auto-shutdown configuration before creating the policy. The method we can use is to set this configuration and export the virtual machine as a template. We change the configuration to on and off, export and check the difference.
After testing the export template you will discover that Azure creates an object of type Microsoft.DevTestLab/schedules when the auto-shutdown configuration is defined. Azure creates this object the first time we enable the auto-shutdown configuration. However, when we disable it, Azure doesn’t drop the object, it only disables it. Azure enables the existing object again when the auto-shutdown configuration.
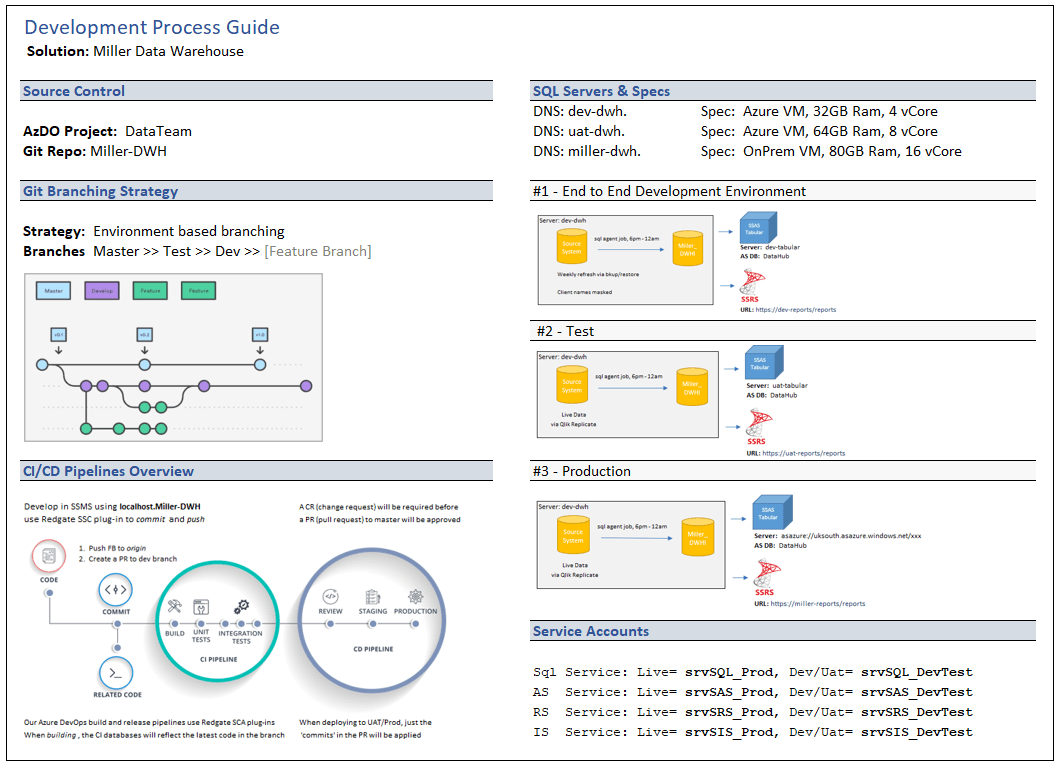
Schedules and Properties
We need to check the Microsoft.DevTestLab/schedules. We will test the property targetResourceId to ensure the schedule belongs to the correct machine machine and the status property to check if the schedule object is enabled or not.
The policy require us to use the full name of the fields. The documentation about the full name of the fields is not always available. It’s a challenge to find them. After a lot of research, I discovered the full name of the fields:
Status: Microsoft.DevTestLab/schedules/status
TargetRersourceId: Microsoft.DevTestLab/schedules/targetResourceId
A few weeks ago I wrote about parameterizing Azure policies. We can apply the same concepts to the auto-shutdown policy. The local IT teams will choose to enable the auto-shutdown configuration automatically or only audit when the configuration is enabled or not. The policy will allow them to choose between AuditIfNotExists or DeployIfNotExists
The policy will be like this:
{
"parameters": {
"effect": {
"type": "String",
"metadata": {
"displayName": "Effect",
"description": "Enable or disable the execution of the policy"
},
"allowedValues": [
"DeployIfNotExists",
"auditIfNotExists",
"Disabled"
],
"defaultValue": "DeployIfNotExists"
}
},
"policyRule": {
"if": {
"allOf": [
{
"field": "type",
"equals": "Microsoft.Compute/virtualMachines"
}
]
},
"then": {
"effect": "[parameters('effect')]",
"details": {
"type": "microsoft.devtestlab/schedules",
"roleDefinitionIds": [
"/providers/Microsoft.Authorization/roleDefinitions/9980e02c-c2be-4d73-94e8-173b1dc7cf3c"
],
"existenceCondition": {
"allOf": [
{
"field": "Microsoft.DevTestLab/schedules/targetResourceId",
"equals": "[field('id')]"
},
{
"field": "Microsoft.DevTestLab/schedules/status",
"equals": "Enabled"
}
]
},
"deployment": {
"properties": {
"mode": "incremental",
"name": "Default",
"template": {
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"vmName": {
"defaultValue": "devMaltaStation",
"type": "String"
}
},
"variables": {
"rId": "[resourceId('Microsoft.Compute/virtualMachines', parameters('vmName'))]",
"schName": "[concat('shutdown-computevm-',parameters('vmName'))]"
},
"resources": [
{
"type": "Microsoft.DevTestLab/schedules",
"apiVersion": "2018-09-15",
"name": "[variables('schName')]",
"location": "northeurope",
"properties": {
"status": "Enabled",
"taskType": "ComputeVmShutdownTask",
"dailyRecurrence": {
"time": "0000"
},
"timeZoneId": "Central European Standard Time",
"notificationSettings": {
"status": "Disabled",
"timeInMinutes": 30,
"notificationLocale": "en"
},
"targetResourceId": "[variables('rId')]"
}
}
]
},
"parameters": {
"vmName": {
"value": "[field('name')]"
}
}
}
}
}
}
}
}
Once created and assigned, you can check the policy to verify the result or apply remediation. I wrote a bit about this on the blog about evaluating Azure Policy tenant-wide
Summary
The auto-shutdown policy is one more important policy we should use in our Azure environment. Making it as a parameterized policy is one additional benefit for our environment.
The post Creating Azure Policy to setup Virtual Machine Auto-Shutdown appeared first on Simple Talk.
from Simple Talk https://ift.tt/V16GfHL
via