Entry in Robert Sheldon's series on Learning MySQL. The series so far:
- Getting started with MySQL
- Working with MySQL tables
- Working with MySQL views
- Working with MySQL stored procedures
- Working with MySQL stored functions
- Introducing the MySQL SELECT statement
- Introducing the MySQL INSERT statement
The UPDATE statement enables you to modify values in your database tables, including temporary tables. With a single statement, you can update one or more rows, one or more columns, or any combination of the two. You can even update multiple tables. As you work through this article, you’ll find that the UPDATE statement is intuitive and straightforward to use, once you understand the basics of how it works.
Preparing your MySQL environment
For the examples in this article, I used the same database (travel) and tables (manufacturers and airplanes) that I used for the last few articles in this series.
Note: The examples assume that you worked through the previous article, in which case, the travel database should be set up and ready to go. If you did not, you can still follow along with this article, just know that your query results will be slightly different from the ones I show here.
To set up the travel database—if you haven’t already done so—download the MySQL_06_setup.sql file and run the SQL script against your MySQL instance. The script creates the database and tables and inserts sample data. Alternatively, you can create the database and then run the following script to create the manufacturers and airplanes tables:
CREATE TABLE manufacturers (
manufacturer_id INT UNSIGNED NOT NULL AUTO_INCREMENT,
manufacturer VARCHAR(50) NOT NULL,
create_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
last_update TIMESTAMP NOT NULL
DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (manufacturer_id) )
ENGINE=InnoDB AUTO_INCREMENT=1001;
CREATE TABLE airplanes (
plane_id INT UNSIGNED NOT NULL AUTO_INCREMENT,
plane VARCHAR(50) NOT NULL,
manufacturer_id INT UNSIGNED NOT NULL,
engine_type VARCHAR(50) NOT NULL,
engine_count TINYINT NOT NULL,
max_weight MEDIUMINT UNSIGNED NOT NULL,
wingspan DECIMAL(5,2) NOT NULL,
plane_length DECIMAL(5,2) NOT NULL,
parking_area INT GENERATED ALWAYS
AS ((wingspan * plane_length)) STORED,
icao_code CHAR(4) NOT NULL,
create_date TIMESTAMP NOT NULL
DEFAULT CURRENT_TIMESTAMP,
last_update TIMESTAMP NOT NULL
DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (plane_id),
CONSTRAINT fk_manufacturer_id
FOREIGN KEY (manufacturer_id)
REFERENCES manufacturers (manufacturer_id) )
ENGINE=InnoDB AUTO_INCREMENT=101;
Next, you need to add data to the manufacturers and airplanes tables to support the examples in this article. Start with the manufacturers table by running the following INSERT statement, which adds Beagle Aircraft Limited as a manufacturer:
INSERT INTO manufacturers (manufacturer)
VALUES ('Beagle Aircraft Limited');
SELECT manufacturer_id
FROM manufacturers
WHERE manufacturer = 'Beagle Aircraft Limited';
After the data is inserted, the SELECT statement returns the newly added value from the manufacturer_id column. If you’ve been following along exactly with the last couple of articles, the value would be 1008. If it is not, make a note of the manufacturer_id value you get here because you’ll need it for the rest of the article, starting with the following INSERT statement:
INSERT INTO airplanes
(plane, manufacturer_id, engine_type, engine_count,
wingspan, plane_length, max_weight, icao_code)
VALUES
('A.61 Terrier',1008,'piston',1,36,23.25,2400,'AUS6'),
('B.121 Pup',1008,'piston',1,31,23.17,1600,'PUP'),
('B.206',1008,'piston',2,55,33.67,7500,'BASS'),
('D.4-108',1008,'piston',1,36,23.33,1900,'D4'),
('D.5-108 Husky',1008,'piston',1,36,23.17,2400,'D5');
If necessary, replace 1008 with your manufacturer_id value and then run this statement. After you’ve done that, you should be set up to follow along with the examples in this article. Be aware, however, that a number of the following examples reference the manufacturer_id column, so if the value is not 1008 on your system, be sure to use the correct one.
The UPDATE statement syntax
The UPDATE statement in MySQL supports five clauses, two of which are required and three that are optional, as indicated in the following syntax:
UPDATE [IGNORE] table_name
SET column = value [, column = value]...
[WHERE where_condition]
[ORDER BY order_list]
[LIMIT row_count]
The syntax does not include all the elements in an UPDATE statement, but it does provide most of them. These are ones you’ll be using the majority of the time, not only when learning about the statement, but also after you’ve mastered it. For the complete syntax check the MySQL documentation on the UPDATE statement.
Here’s a breakdown of the five clauses:
- The
UPDATE clause, one of the statement’s two mandatory clauses, specifies the table that is the target of the update. You can specify multiple tables in this clause, separating them with commas, but my focus in this article is on single-table updates. I’m saving the subject of multi-table updates for when I cover more advanced topics.
- The
SET clause, the other mandatory clause, specifies which columns to update. You can include one or more column assignments. For each assignment, specify the column name, an equal sign, and the new value. If you include multiple assignments, separate them with commas.
- The
WHERE clause determines which rows to update, based on one or more conditions. The clause works much like the WHERE clause in a SELECT statement. Although the WHERE clause is optional, you should be very careful running an UPDATE statement that that does not include one. Without a WHERE clause, the statement will update every row in the table, unless the LIMIT clause is included.
- The
ORDER BY clause specifies the order that rows should be updated. This can be useful in situations that might otherwise result in an error, as you’ll see later in the article. The ORDER BY clause is similar to the one you saw in the SELECT statement. The clause cannot be used for multi-table updates.
- The
LIMIT clause limits the number of rows that will be updated. If you include a WHERE clause, the count applies to the rows returned by that clause. This means that the statement will stop based on the number of rows that satisfy the WHERE conditions, whether or not those rows are actually updated. As with the ORDER BY clause, the LIMIT clause cannot be used for multi-table updates.
With these five clauses, you can build a wide range of UPDATE statements. Most of the time, you’ll be using the UPDATE, SET and WHERE clauses, although the ORDER BY clause and LIMIT clause can also come in handy at times.
Once you see the statement in action, you should have no problem understanding how all the clauses work and using them to update data. In fact, it’s almost too easy to update data, and if you’re not careful, you could make a significant mess of things. Data modifications can be difficult to undo, so you need to proceed cautiously, especially when you’re first learning how to use the UPDATE statement. Certainly, don’t practice in a production environment. When you do update the production environment, be sure to do it within a transaction, a topic I plan to cover later in the series.
Performing a basic update in MySQL
Now that you have a basic overview of the UPDATE statement syntax, it’s time to see the statement in action so you can get a feel for how it works. As I already mentioned, the UPDATE and SET clauses are the only required clauses, so let’s start with them.
Suppose you want to round all the values in the wingspan column in the airplanes table to whole numbers. To achieve this, you create the following UPDATE statement:
UPDATE airplanes
SET wingspan = ROUND(wingspan);
The UPDATE clause identifies airplanes as the target table, and the SET clause specifies that the values in the wingspan column should be rounded, which is achieved by using the built-in ROUND function.
That’s all it takes to update the wingspan data. However, there’s a good chance that when you try to run this statement, you’ll receive the following error:
Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column. To disable safe mode, toggle the option in Preferences -> SQL Editor and reconnect.
By default, you cannot perform an update without a WHERE clause that specifies a key column. This helps to ensure that you don’t make sweeping changes that you’ll later regret. You can disable safe mode (as the error message suggests), either permanently or temporarily. I recommend that you do it on a temporary basis to avoid any unwanted changes elsewhere.
To temporarily disable safe mode, use a SET statement to change the SQL_SAFE_UPDATES system variable to 0 prior to running your UPDATE statement and then set the variable to 1 after you run the statement, as shown in the following example:
SET SQL_SAFE_UPDATES = 0;
UPDATE airplanes
SET wingspan = ROUND(wingspan);
SET SQL_SAFE_UPDATES = 1;
The SET statements merely toggle the variable off and then on during the current session. Be aware, however, that the SET statement supports the GLOBAL option, which sets a variable at the global scope. As a general practice, do not use this option when disabling safe updates. It is much less risky to make these sorts of changes at the session level to prevent any unplanned mishaps. Use GLOBAL only if it’s essential in your circumstances.
For more details on SET and global variables and settings. See Using System Variables in the MySQL Documentation.
Even at the session level, the SET statement makes it possible to execute your UPDATE statement without generating an error. You can confirm the changes by running a simple SELECT statement after executing the script above:
SELECT * FROM airplanes;
Figure 1 shows part of the results returned by the SELECT statement. Notice that the wingspan values are now all whole numbers.
 Figure 1. Rounding the values in the
Figure 1. Rounding the values in the wingspan column
In some cases, you might want to update multiple columns at the same time. For this, you need to add the additional column assignments, separating them with commas. For example, the following UPDATE statement modifies both the wingspan and plane_length columns:
SET SQL_SAFE_UPDATES = 0;
UPDATE airplanes
SET wingspan = ROUND(wingspan), plane_length = ROUND(plane_length);
SET SQL_SAFE_UPDATES = 1;
Both column assignments work the same way. You’re simply rounding the column values to whole numbers. If you were to query the airplanes table after running the UPDATE statement, your results would look similar to those shown in Figure 2.
Figure 2. Rounding the values in the wingspan and plane_length columns
By using the UPDATE and SET clauses, you can quickly update all of a column’s values. Just be careful if taking this approach. It’s all too easy to mess things up in a big way.
Adding a WHERE clause to your UPDATE statement
Most of your UPDATE statements will likely include a WHERE clause to help you better target the data that you want to modify. The WHERE clause specifies one or more conditions that narrow down the rows to be updated. For example, the following statement includes a WHERE clause that limits the updates to rows with a manufacturer_id value of 1008:
UPDATE airplanes
SET engine_type = 'piston (adg-i)'
WHERE manufacturer_id = 1008;
SELECT *
FROM airplanes
WHERE manufacturer_id = 1008;
The SET clause in this statement sets the engine_type value to piston (adg-i) for the targeted rows. The results from executing the statements should look similar to Figure 3.
Figure 3. Limiting your update to specific rows
Note: In case you’re wondering, the adg-i value is a reference to Airplane Design Group (ADG) classifications, a system used to categorize aircraft by dividing them into six groups based on their wingspans and tail heights. The lowercase i indicates that the planes in this example are in Group I. (I realize that you’d probably want to add a column for the ADG groups. The approach I took here was meant only to demonstrate these concepts.)
That said, it turns out that the B.206 airplane should actually be in Group II, which means you need to update that record without updating the others. Fortunately, you can define multiple conditions in your WHERE clause to help narrow down the rows. In the following example, the WHERE clause includes two conditions, one based on the manufacturer_id column and the other on the plane column:
UPDATE airplanes
SET engine_type = 'piston (adg-ii)'
WHERE manufacturer_id = 1008 AND plane = 'B.206';
As in the previous example, the WHERE clause limits the updates to rows with a manufacturer_id value of 1008. However, the clause also specifies that the plane value must equal B.206. The two conditions are linked together by the AND logical operator, which means that both conditions must evaluate to true for the row to be updated.
After you run the UPDATE statement, you can retrieve the same rows as before. Your results should look similar to those shown in Figure 4. Notice that the B.206 aircraft is now shown as a Group II plane.
Figure 4. Limiting your update to one specific row
You can make your WHERE clause as detailed as necessary to ensure that you’re updating the target rows and no other rows. The key is to use your logical operators correctly to ensure that your conditional logic is accurate.
Working with column values
In the first example in this article, you saw how to use the ROUND system function to round values in the airplanes table. When you update a column in this way, MySQL uses the column’s current value to create a new value. The ability to use the current value makes it possible to build on that value in ways that go beyond simply applying a function. For example, the following UPDATE statement adds 3 to the wingspan value and 5 to the plane_length value:
UUPDATE airplanes
SET wingspan = wingspan + 3, plane_length = plane_length + 5
WHERE plane_id = 344;
In this case, I used the plane_id value 344 in the WHERE clause, which I had to look up in the table. However, you might want to use a different method for finding this value, such as retrieving it through a subquery, a topic I plan to cover later in this series.
After your run this statement, you can query the airplanes table to verify the results, which should look similar to those shown in Figure 5.
Figure 5. Increasing values in the wingspan and plane_length columns
If you compare Figure 5 to Figure 4, you’ll see that the row with a plane_id value of 344 has been updated. You might have also noticed that MySQL automatically updated the parking_area column, which is a generated column that multiples the wingspan and plane_length values.
If you try to update a column with the same value it already has, MySQL is smart enough to realize the values are the same and does not change the original value. This approach could potentially reduce unnecessary overhead and minimize the impact on concurrent operations that might be trying to retrieve or modify that value at the same time. MySQL is also smart enough to recognize when you try to insert an unacceptable value into a column. For instance, the following UPDATE statement attempts to change the engine_type column to NULL:
UPDATE airplanes SET engine_type = NULL WHERE plane_id = 344;
Because the column is defined as NOT NULL, the UPDATE statement will fail and generate the following error:
Error Code: 1048. Column 'engine_type' cannot be null
You’ll also receive an error if you attempt to update a column to a value with an incorrect data type. For example, the following UPDATE statement attempts to update the max_weight column to the string value unknown:
UPDATE airplanes
SET max_weight = 'unknown'
WHERE plane_id = 344;
Not surprisingly, this statement will also fail because the max_weight column is defined with the MEDIUMINT data type. Rather than update the value, MySQL returns the following error:
Error Code: 1366. Incorrect integer value: 'unknown' for column 'max_weight' at row 1
As with inserting data, updating data requires that you’re familiar with the target columns whose values you’re trying to modify. It’s not enough just to know the data type. You must also understand how the data type is defined. For example, if you try to update the icao_code column with the string abcdef, you’ll generate an error because the column is defined as CHAR(4).
Updating foreign key columns in MySQL tables
There might be times when you want to update a value in a foreign key column. This can be tricky, however, because MySQL performs foreign key checks. For example, suppose you want to modify the manufacturer_id column in the airplanes table:
UPDATE airplanes
SET manufacturer_id = 2001
WHERE manufacturer_id = 1008;
Not surprisingly, MySQL will balk when you try to run this statement and will instead return the following error (unless you’ve included the IGNORE keyword:
Error Code: 1452. Cannot add or update a child row: a foreign key constraint fails (`travel`.`airplanes`, CONSTRAINT `fk_manufacturer_id` FOREIGN KEY (`manufacturer_id`) REFERENCES `manufacturers` (`manufacturer_id`))
You cannot update a foreign key to a value that does not exist in the referenced column. You must first make the necessary changes to the parent table. However, this too can be tricky. For example, you might try to modify the manufacturer_id value in the manufacturers table:
UPDATE manufacturers
SET manufacturer_id = 2001
WHERE manufacturer_id = 1008;
Unfortunately, this too will cause MySQL to generate an error because you cannot update a value that’s being referenced by a foreign key:
Error Code: 1451. Cannot delete or update a parent row: a foreign key constraint fails (`travel`.`airplanes`, CONSTRAINT `fk_manufacturer_id` FOREIGN KEY (`manufacturer_id`) REFERENCES `manufacturers` (`manufacturer_id`))
You can get around these issues by temporarily disabling foreign key checks within your session (or by setting the CASCADE option on the foreign key, something I’ll be discussing in a later article). To achieve this, set the foreign_key_checks system variable to 0 before running the UPDATE statements, and then set it back to 1 after running the statements:
SET foreign_key_checks = 0;
UPDATE manufacturers
SET manufacturer_id = 2001
WHERE manufacturer_id = 1008;
UPDATE airplanes
SET manufacturer_id = 2001
WHERE manufacturer_id = 1008;
SET foreign_key_checks = 1;
In this way, you can update the manufacturer_id values in both tables without generating any foreign key errors. As a reminder, avoid using the GLOBAL option in your SET statement. If you turn off foreign key checks at a global level, you’re putting the integrity of your data at risk.
After you run these statements, you can query the manufacturers table to verify your changes:
SELECT * FROM manufacturers WHERE manufacturer_id = 2001;
Figure 6 shows the data returned by this statement. As you can see, the table was updated with no problem, in part because you specified a new primary key value that did not already exist.
Figure 6. Updating the manufacturers table
You can also query the airplanes table to verify that the rows have been properly updated:
SELECT * FROM airplanes WHERE manufacturer_id = 2001;
Figure 7 shows the results returned by the query. As expected, the manufacturer_id values have been updated in all the target rows.
Figure 7. Updating the manufacturer_id column in the airplanes table
Chances are, you probably won’t have to update foreign key columns too frequently, but it’s good to understand what it takes to make it happen. Just know that there are other issues to be aware of, such as not trying to insert duplicate primary keys.
Updating primary key columns in MySQL tables
As with foreign keys, there might be times when you need to update the values in a primary key column. If you update a single value (as you saw above), it’s usually no problem as long as the new value conforms to the column’s requirements. However, things get trickier if updating multiple values at one time. For example, the following UPDATE statement attempts to add 1 to all plane_id values in rows that have a manufacturer_id value of 2001:
UPDATE airplanes
SET plane_id = plane_id + 1
WHERE manufacturer_id = 2001;
The statement has a good chance of failing because of the order that MySQL updates each row of data (although you can never be certain about the exact order that the database engine will choose when updating data). This is because MySQL is trying to update the original value to a value that already exists and is itself waiting to be updated. For instance, if MySQL tries to update the first row from 342 to 343 before the second row has been changed, the statement will fail and MySQL will return the following error:
Error Code: 1062. Duplicate entry '343' for key 'airplanes.PRIMARY'
You might be tempted to include the IGNORE keyword to try to get around this issue:
UPDATE IGNORE airplanes
SET plane_id = plane_id + 1
WHERE manufacturer_id = 2001;
The IGNORE keyword instructs MySQL to return a warning rather than an error and to continue with the statement’s execution instead of stopping. In this case, you’ll likely receive four warnings, along with a message indicating only one row was successfully updated:
1 row(s) affected, 4 warning(s):
1062 Duplicate entry '343' for key 'airplanes.PRIMARY'
1062 Duplicate entry '344' for key 'airplanes.PRIMARY'
1062 Duplicate entry '345' for key 'airplanes.PRIMARY'
1062 Duplicate entry '346' for key 'airplanes.PRIMARY'
Rows matched: 5 Changed: 1 Warnings: 4
If you query the airplanes table, you can see that only the last row has been updated, as shown in Figure 8. This is because the last row was the only one that did not try to update the primary key value to an existing value.
Figure 8. Using the IGNORE option when updating the plane_id column
A better solution is to include an ORDER BY clause that sorts the rows by the plane_id values, in descending order:
UPDATE airplanes
SET plane_id = plane_id + 1
WHERE manufacturer_id = 2001
ORDER BY plane_id DESC;
When you include the ORDER BY clause in this way, MySQL applies the updates starting with the last row, making it possible to increment the values by 1 without generating any errors or warnings.
Figure 9 shows what the data now looks like after running the UPDATE statement.
Figure 9. Adding the ORDER BY clause to your UPDATE statement
You probably won’t need to use the ORDER BY clause very often, but when you do, it will prove very useful.
Another clause that’s similar in this respect is the LIMIT clause, which limits the number of rows that are updated. For instance, the following update statement limits the number of rows to 3:
UPDATE airplanes
SET plane_id = plane_id + 1
WHERE manufacturer_id = 2001
ORDER BY plane_id DESC
LIMIT 3;
Because the UPDATE statement still includes the ORDER BY clause, the three rows that are updated start at the bottom and go up. Figure 10 shows the results of querying the table after the update.
Figure 10. Adding the LIMIT clause to your UPDATE statement
I suspect you’re not going to include the LIMIT clause in your UPDATE statements very often (if at all), but situations might arise in which you find it useful. For example, you might want to test an UPDATE statement that would normally modify a large number of rows. If you include the LIMIT clause while testing the statement, you’ll reduce the amount of time and processing it takes to verify that the statement is working properly.
Working with the MySQL UPDATE statement
The UPDATE statement is one of the most common statements used when working with MySQL data. In most cases, you’ll be including the UPDATE, SET and WHERE clauses. At times, you might forego the WHERE clause—at your own peril—and at other times, you might incorporate the ORDER BY clause or LIMIT clause (or both). However, the bulk of your updates will likely rely on the three primary clauses.
Regardless of which clauses you use, you should understand how they all work to ensure that you’re modifying your data as effectively as possible, while ensuring the accuracy of those updates. Fortunately, the UPDATE statement is fairly easy to understand and use, so you should have no problem getting started.
The post Introducing the MySQL UPDATE statement appeared first on Simple Talk.
from Simple Talk https://ift.tt/n8Frqto
via
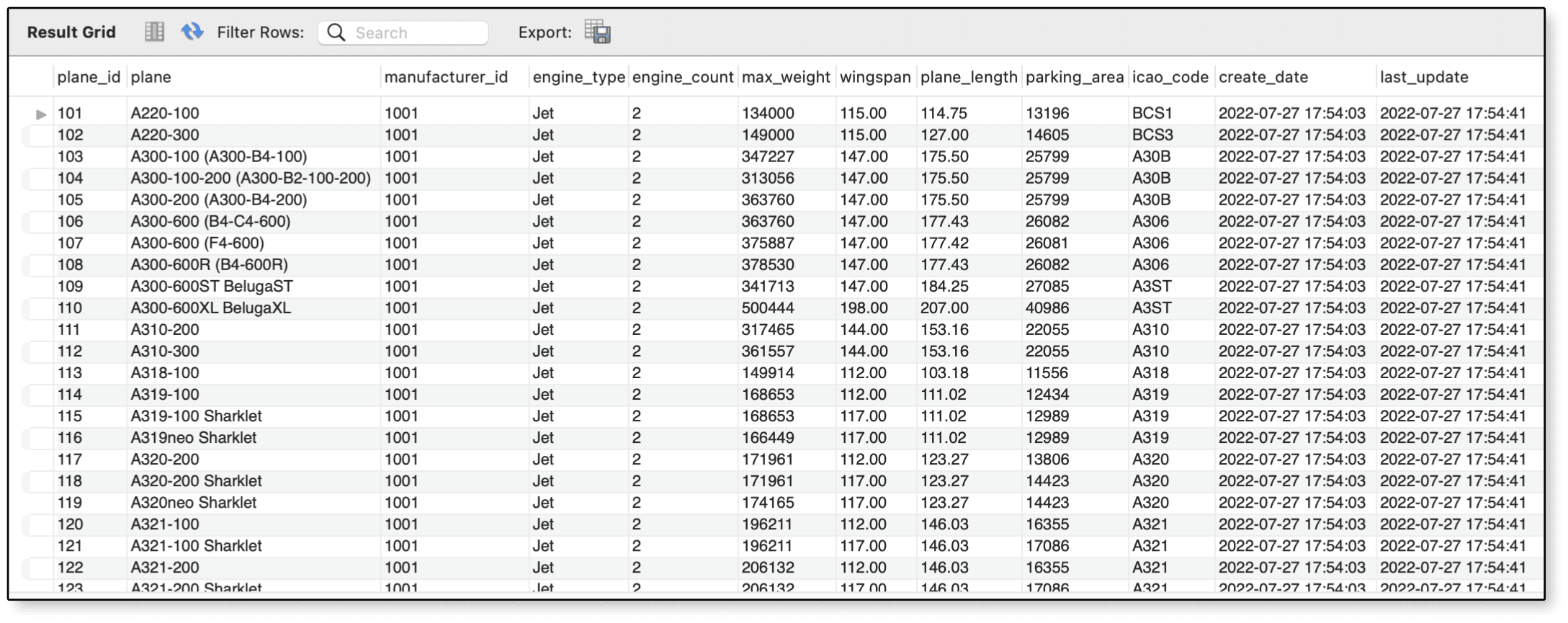 Figure 1. Rounding the values in the
Figure 1. Rounding the values in the 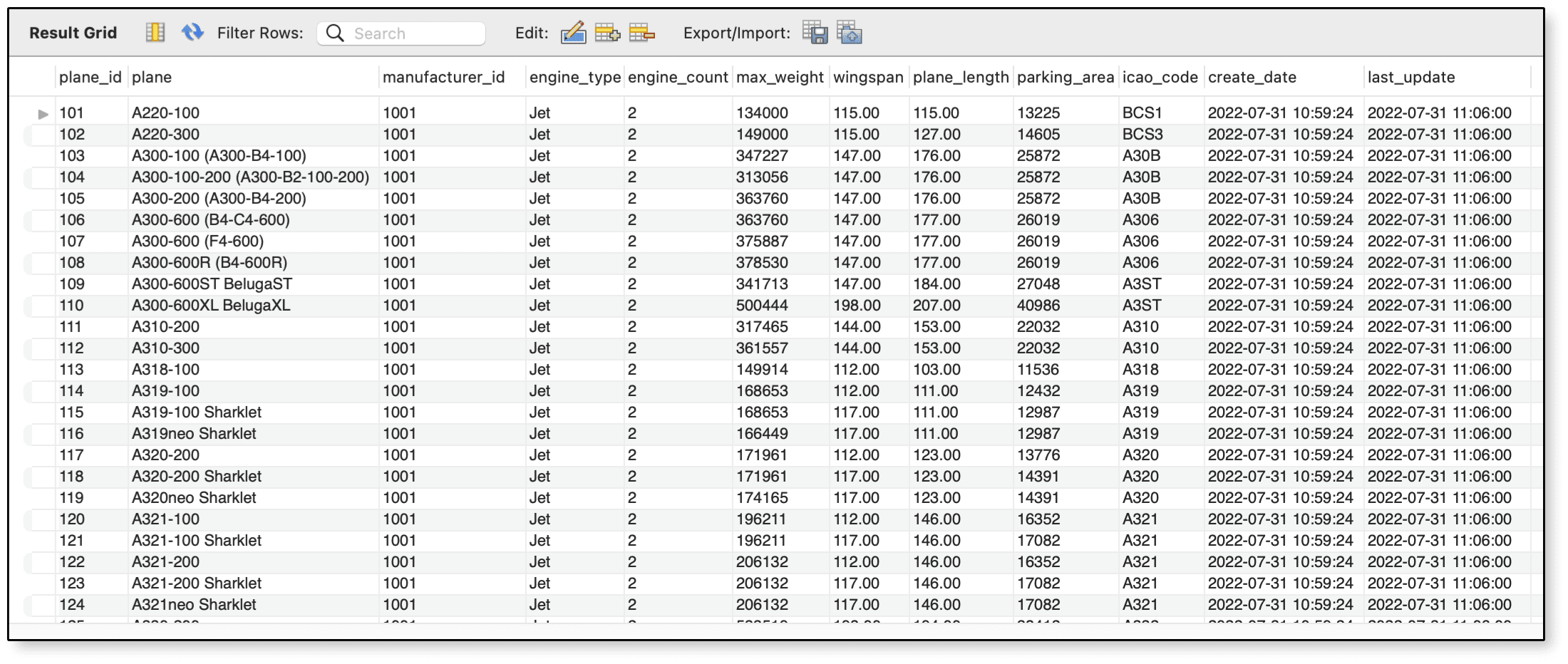 Figure 2. Rounding the values in the
Figure 2. Rounding the values in the  Figure 3. Limiting your update to specific rows
Figure 3. Limiting your update to specific rows Figure 4. Limiting your update to one specific row
Figure 4. Limiting your update to one specific row Figure 5. Increasing values in the
Figure 5. Increasing values in the 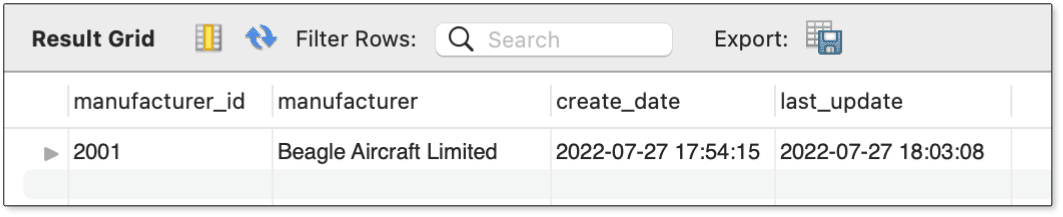 Figure 6. Updating the
Figure 6. Updating the  Figure 7. Updating the
Figure 7. Updating the  Figure 8. Using the
Figure 8. Using the  Figure 9. Adding the
Figure 9. Adding the  Figure 10. Adding the
Figure 10. Adding the