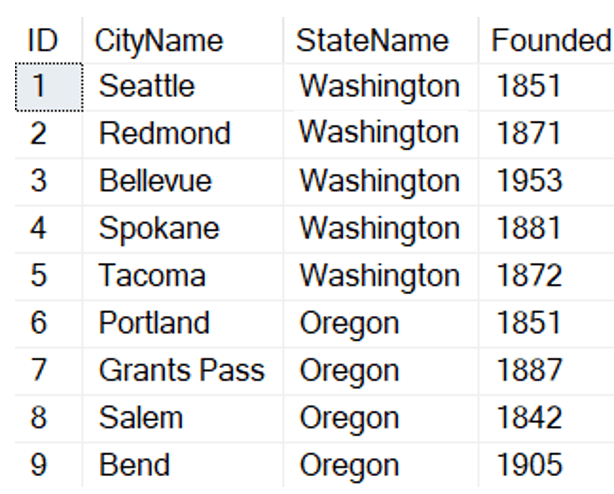
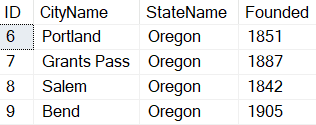
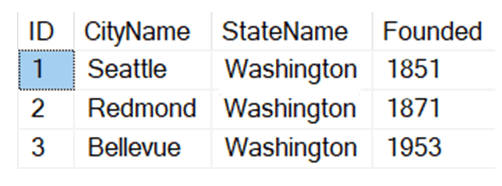
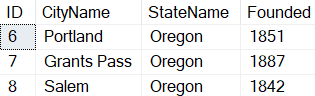
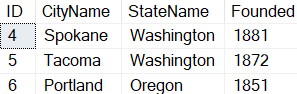
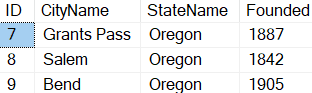If you are on SQL Server 2022 or Azure SQL Database, or have been reading up on new features, you’ve likely heard about one of the better T-SQL enhancements: a new built-in function called GENERATE_SERIES. The syntax is straightforward – it accepts arguments for start and stop, and an optional argument to indicate step (in case you want to iterate by more than 1, or backwards):
SELECT value FROM GENERATE_SERIES(<start>, <stop> [, <step>]);
A few quick examples:
/* count to 6 */
SELECT [1-6] = value
FROM GENERATE_SERIES(1, 6);
/* count by 5s to 30 */
SELECT [step 5] = value
FROM GENERATE_SERIES(5, 30, 5);
/* count from 10 to 0, backwards, by 2 */
SELECT [backward] = value
FROM GENERATE_SERIES(10, 0, -2);
/* get all the days in a range, inclusive */
DECLARE @start date = '20230401',
@end date = '20230406';
SELECT [days in range] = DATEADD(DAY, value, @start)
FROM GENERATE_SERIES(0, DATEDIFF(DAY, @start, @end));
Results:
| 1-6 (first resultset) |
step 5 (second resultset) |
backward (third resultset) |
days in range (fourth resultset) |
|||
| 1 | 5 | 10 | 2023-04-01 | |||
| 2 | 10 | 8 | 2023-04-02 | |||
| 3 | 15 | 6 | 2023-04-03 | |||
| 4 | 20 | 4 | 2023-04-04 | |||
| 5 | 25 | 2 | 2023-04-05 | |||
| 6 | 30 | 0 | 2023-04-06 |
That is some handy syntax that is quite easy to use. I dug in more about it during the beta, but…
How would we do this on older versions of SQL Server?
We’ve been generating sets since before SQL Server was SQL Server, so we’ve always found a way. Some approaches are cryptic, and some perform poorly; others are cryptic and perform poorly. I have two that I like: one that works in SQL Server 2016 and above, and one that works all the way back to SQL Server 2008. There are others (even some that will work on SQL Server 2000), but these are the two I want to focus on today.
I’m going to present both techniques as inline table-valued functions, since the logic is complicated enough to justify encapsulation, and that also happens to keep demos nice and tidy. These will be written to accommodate a series of up to 4,000 values – we can certainly go beyond that, but exceeding 8,001 values leads to the first solution requiring LOB support, which can do unpredictable things to performance. The second is capped at 4,096 values because it is the highest power of 4 that is also less than 8,001; you’ll see why that’s important in a moment.
2016+ STRING_SPLIT + REPLICATE
This one is a rather recent addition to my toolbox; I don’t recall where I first came across it, but I like it because it’s concise without being overly opaque. We determine the number of values we want in our sequence, less one – which is the stop minus the start. We use REPLICATE to generate a string that is a sequence of that many commas. Then we split that string using STRING_SPLIT, which results in { stop - start + 1 } empty strings. We then apply a ROW_NUMBER() to the output, which serves as our series. Since our starting value might not be 1, we add it to the row number, and subtract 1.
To get started, I will create a new database named GenSeries to put the sample code.
CREATE FUNCTION dbo.GenerateSeries_Split
(
@start int,
@stop int
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
SELECT TOP (@stop - @start + 1)
value = ROW_NUMBER() OVER (ORDER BY @@SPID) + @start - 1
FROM STRING_SPLIT(REPLICATE(',', @stop - @start), ',')
ORDER BY value
);
To support a range greater than 8,001 values, you can change this line:
FROM STRING_SPLIT(REPLICATE(CONVERT(varchar(max),','), @stop - @start), ',')
…but that’s not the version I’m going to test today.
2008+ Cross-Joined CTEs
This solution reaches further back into most of the unsupported versions of SQL Server you might still be clinging to but, unfortunately, it is a little more cryptic. I remember first using it in this solution after discovering this really efficient implementation by Jonathan Roberts.
CREATE FUNCTION dbo.GenerateSeries_CTEs
(
@start int,
@stop int
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
/* could work in 2005 by changing VALUES to a UNION ALL */
WITH n(n) AS (SELECT 0 FROM (VALUES (0),(0),(0),(0)) n(n)),
i4096(n) AS (SELECT 0 FROM n a, n b, n c, n d, n e, n f)
SELECT TOP (@stop - @start + 1)
value = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT) + @start - 1
FROM i4096
ORDER BY value
);
This approach uses two CTEs – one that just generates 4 rows using a VALUES constructor; the second one cross joins it to itself, however many times is necessary to cover the range of values you need to support. (In our case, we want to support 4,000 values.)
Each time you cross join the original set of 4, you produce a Cartesian product of 4^n, where n is bumped by 1 for each new reference. So if you just named it once, you’d have 4^1, which is 4. The second reference is 4^2, which is 16. Then 4^3 = 64, 4^4 = 256, 4^5 = 1,024, and 4^6 = 4,096. I’ll try to illustrate in an image:

If you only need to support 256 values, for example, then you could change that second line to stop at the 4th cross join:
i256(n) AS (SELECT 0 FROM n a, n b, n c, n d)
And if you needed more than 4,096 values – say, up to 16,384 – you would instead just add one additional cross join:
i16K(n) AS (SELECT 0 FROM n a, n b, n c, n d, n e, n f, n g)
And of course you can be more verbose and self-documenting. Technically, I would want to write the following, it’s just a lot more to digest on first glance:
i4096(n) AS
(
SELECT 0 FROM n AS n4 CROSS JOIN n AS n16
CROSS JOIN n AS n64 CROSS JOIN n AS n256
CROSS JOIN n AS n1024 CROSS JOIN n AS n4096
/* ... */
)
You could also code defensively and alter the parameters to smallint or tinyint to prevent surprises when someone uses an int value that is too large and they don’t get the full set they expect. This won’t raise an error, unless you also add additional handling, say, to divide by 0 somewhere if the range is too large. Keep in mind that someone could try to generate 100 rows by passing in a start parameter of 2,000,000,000 and a stop parameter of 2,000,000,100 – so restricting either input value instead of the difference might be unnecessarily limiting.
I often see recursive CTEs suggested for set generation, since they are a little less cryptic than this, and are somewhat self-documenting (if you already understand recursive CTEs, I suppose). I do like recursive CTEs generally, and have offered them up in many posts and answers, but they’re not ideal for broad consumption in this context unless you will never retrieve more than 100 rows (say, generating the days for a monthly report). This is because you will need a MAXRECURSION query hint to produce more than 100 values; since you can’t put that hint inside a function, it means you have to put it on every outer query that references the function. Ick! So much for encapsulation.
So how do they perform?
I thought about the simplest test I can do to pit different number generation techniques against each other, and the first that came to mind involves pagination. (Note: This is a contrived use case and not intended to be a discussion about the best ways to paginate data.)
In the GenSeries database, I will create a simple table with 4,000 rows:
SELECT TOP (4000) rn = IDENTITY(int,1,1),* INTO dbo.things FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX cix_things ON dbo.things(rn);
Then I created three stored procedures. One that uses the split approach:
CREATE OR ALTER PROCEDURE dbo.PaginateCols_Split
@PageSize int = 100,
@PageNum int = 1
AS
BEGIN
SET NOCOUNT ON;
DECLARE @s int = (@PageNum-1) * @PageSize + 1;
DECLARE @e int = @s + @PageSize - 1;
WITH r(rn) AS
(
SELECT TOP (@PageSize) rn = value
FROM dbo.GenerateSeries_Split(@s, @e)
)
SELECT t.* FROM dbo.things AS t
INNER JOIN r ON t.rn = r.rn;
END
One that uses stacked CTEs:
CREATE OR ALTER PROCEDURE dbo.PaginateCols_CTEs
@PageSize int = 100,
@PageNum int = 1
AS
BEGIN
SET NOCOUNT ON;
DECLARE @s int = (@PageNum-1) * @PageSize + 1;
DECLARE @e int = @s + @PageSize - 1;
WITH r(rn) AS
(
SELECT TOP (@PageSize) rn = value
FROM dbo.GenerateSeries_CTEs(@s, @e)
)
SELECT t.* FROM dbo.things AS t
INNER JOIN r ON t.rn = r.rn;
END
And one that uses GENERATE_SERIES directly:
CREATE OR ALTER PROCEDURE dbo.PaginateCols_GenSeries
@PageSize int = 100,
@PageNum int = 1
AS
BEGIN
SET NOCOUNT ON;
DECLARE @s int = (@PageNum-1) * @PageSize + 1;
DECLARE @e int = @s + @PageSize - 1;
WITH r(rn) AS
(
SELECT TOP (@PageSize) rn = value
FROM GENERATE_SERIES(@s, @e)
)
SELECT t.* FROM dbo.things AS t
INNER JOIN r ON t.rn = r.rn;
END
Then I created a wrapper that will call each of them with a defined page number – this way I could test the beginning, middle, and end of the set (pagination often sees tanking performance as the page number gets higher). This table is hardly a performance nightmare but if I ran the procedures enough times I would hopefully see some variance.
CREATE OR ALTER PROCEDURE dbo.PaginateCols_Wrapper @PageNum int = 1 AS BEGIN SET NOCOUNT ON; EXEC dbo.PaginateCols_Split @PageNum = @PageNum; EXEC dbo.PaginateCols_CTEs @PageNum = @PageNum; EXEC dbo.PaginateCols_GenSeries @PageNum = @PageNum; END
If you execute this procedure, you will see 3 output sets that contain rows from sys.columns. If you vary the @pagenum parameter value, you will see different pages of data from that set, but each three will be the same results. The only difference is the series generating code.
I turned on Query Store, and always want to remind you that QUERY_CAPTURE_MODE = ALL is not a production-friendly option – but quite handy if you want to make sure you capture every instance of every query:
ALTER DATABASE GenSeries SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, QUERY_CAPTURE_MODE = ALL /* Do not do this in production! */ );
I didn’t want to run the procedures a bunch of times manually; I like using sqlstresscmd because I can run tests hundreds of thousands of times without guilt about overwhelming a poor UI, or waiting for results to render, or battling resource conflicts and poisoning the test as a result. It runs the queries, discards the results, and that’s it.
I configured a JSON file called GenSeries.json like this, to run each procedure 10,000 times across 16 threads. It took about 5 minutes to run on average:
{
"CollectIoStats": true,
"CollectTimeStats": true,
"MainDbConnectionInfo":
{
"Database": "GenSeries",
"Login": "sa",
"Password": "$tr0ng_P@$$w0rd",
"Server": "127.0.0.1,2022"
},
"MainQuery": "EXEC dbo.PaginateCols_Wrapper @PageNum = 1;",
"NumIterations": 10000,
"NumThreads": 16,
"ShareDbSettings": true
}
Then ran it using the following:
sqlstresscmd -s ~/Documents/GenSeries.json
Then I collected the average runtimes from Query Store:
SELECT qt.query_sql_text,
avg_duration = AVG(rs.avg_duration/1000.0)
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
WHERE qt.query_sql_text LIKE N'%dbo.things%'
AND qt.query_sql_text NOT LIKE N'%sys.query_store%'
GROUP BY qt.query_sql_text;
When I wanted to switch to the middle or the end of the set, I ran this query to clear Query Store data. (Note: you will need to capture the results from Query Store each time before executing this statement as this clears everything from Query Store):
ALTER DATABASE GenSeries SET QUERY_STORE CLEAR;
Then I changed the MainQuery line appropriately to run tests for the middle and the end. For rows 1,901 – 2,000:
"MainQuery": "EXEC dbo.PaginateCols_Wrapper @PageNum = 20;",
And for rows 3,901 – 4,000:
"MainQuery": "EXEC dbo.PaginateCols_Wrapper @PageNum = 40;",
Here are the timing results in milliseconds (click to enlarge):

In these tests, the split approach was the winner, but the new built-in function is right on its heels. The stacked CTEs, while much more backward-compatible, have become a bit of an outlier.
I would love to see some flat lines in there, of course, since there shouldn’t be any penalty for jumping ahead to any page; but, not the point today. I do plan to revisit some of my old pagination techniques in a future article.
Conclusion
As the title suggests, I’m pretty happy with the syntax of GENERATE_SERIES so far, and I hope you get to try it out sooner than later! The performance of the split approach is slightly better, but both are still relatively linear and, for the simplicity of the implementation, I’d be inclined to use the newer syntax in most cases. At this scale, we’re talking about single-digit milliseconds anyway, so maybe not all that telling other than “this is worth testing.”
And to reiterate, this wasn’t meant to show that any of these methods might be better for pagination specifically – it was a completely manufactured scenario where the table just happened to have contiguous row numbers to join to the output. This was more a demonstration of how easy it is to swap GENERATE_SERIES into places where you’re using more convoluted methods today.
Further reading
As far as series generation goes, there are other options out there, too, including some from Paul White, Itzik Ben-Gan, and others in this 6-part Number series generator challenge from 2021. In particular, there is an interesting solution from Paul White (dbo.GetNums_SQLkiwi) in solutions part 4, but it does require a little concentration, and is version-limiting (it requires a table with a clustered columnstore index). You should do more thorough testing with his and other approaches from that series, with your data and workload, especially if your primary objective is squeezing performance. Some solutions will only be options if you are on modern versions and/or have some leeway in implementation (some CLR solutions might be interesting as well).
The post GENERATE_SERIES: My new go-to to build sets appeared first on Simple Talk.
from Simple Talk https://ift.tt/D8qQF7I
via