Writing efficient and high-quality SQL is hard to do. Sometimes it comes down to trialling different types of queries to get one that gives you the results you want and has good performance. There are a range of ‘best practices’ or tips that are recommended for working with SQL. Many of them relate to SQL overall, and some of them are specific to Oracle SQL. In this article, I’ll explain ten of the Oracle SQL best practices to help improve your SQL queries.
1. Use ANSI Joins Instead of Oracle Joins
In Oracle SQL, there are two ways to join tables. You might be familiar with the ANSI method, which involves using JOIN keywords between tables:
SELECT emp.*, dept.* FROM emp INNER JOIN dept ON emp.dept_id = dept.id;
You can also do outer joins such as a LEFT JOIN:
SELECT emp.*, dept.* FROM emp LEFT JOIN dept ON emp.dept_id = dept.id;
There is another method which is occasionally referred to as an Oracle join, because the syntax is Oracle-specific. An inner join is done using the WHERE clause:
SELECT emp.*, dept.* FROM emp, dept WHERE emp.dept_id = dept.id;
An outer join is done by placing a (+) on the WHERE clause after the column that NULLs are allowed. For example, a LEFT JOIN can be written as:
SELECT emp.*, dept.* FROM emp, dept WHERE emp.dept_id = dept.id(+);
A RIGHT JOIN can be written by putting the symbol on the other side of the join:
SELECT emp.*, dept.* FROM emp, dept WHERE emp.dept_id(+) = dept.id;
The recommendation with writing joins is to use the ANSI style (the JOIN and ON keywords) rather than the Oracle style (the WHERE clause with (+) symbols). I’ve written about this before in my guide to joins in Oracle, and there are a few reasons for this:
- In large queries, it’s easy to forget to add a WHERE clause to join a table, causing unnecessary cartesian joins and incorrect results
- The WHERE clause should be used for filtering records, not for joining tables together. A subtle difference, but it makes the query easier to understand
- ANSI joins are arguably easier to read, as you can see which section is used for joins and which is used for filtering data.
2. Avoid WHERE Clauses with Functions
Another recommendation for working with Oracle SQL is to avoid writing WHERE clauses that use functions. In SQL, WHERE clauses are used to filter the rows to be displayed. These are often used to check that a column equals a certain value:
WHERE status = ‘A’
You may have a need to compare a column to a value that has used a function. For example:
WHERE UPPER(last_name) = ‘SMITH’
Another example could be:
WHERE ROUND(monthly_salary) > 2000
Using functions on columns in the WHERE clause should be avoided. This is because any indexes that are created on the columns themselves (e.g. last_name or monthly_salary) will not be used if a function is applied in the query, which can slow the query down a lot.
To avoid using a function on a column, consider if there’s a way to write the WHERE clause without the function. Sometimes there is, but other times you need to write the function.
If you do need to have the function on the column in the WHERE clause, consider creating a function-based index on the column. This is a type of index that is created on the result of a function applied to the column, which could be used in this query.
3. Use CASE Instead of Multiple Unions
I’ve seen several examples of queries that are looking up a range of records based on criteria. The criteria are more than just a simple WHERE clause, and depending on different types of records, the joins and other criteria might be different.
This is often implemented as several SELECT queries joined together using UNION or UNION ALL keywords. For example:
SELECT id, product_name FROM product WHERE status = ‘X’ AND created_date < TO_DATE(‘2017-01-01’, ‘YYYY-MM-DD’) UNION ALL SELECT id, product_name FROM product WHERE status = ‘A’ AND product_series = ‘WXT’;
This is a simple example, but often the different queries may include joins or lookups to other tables.
Structuring a query like this means that the tables need to be queried several times (once for each SELECT query), which is quite inefficient. There is a chance that your table will have an index on it to make it run more efficiently, but there is another method that’s worth trying. Rather than having separate queries with UNION ALL, try putting the logic inside a CASE statement inside a single SELECT:
SELECT id, product_name FROM ( SELECT id, product_name, CASE WHEN status = ‘X’ AND created_date < TO_DATE(‘2017-01-01’, ‘YYYY-MM-DD’) THEN 1 WHEN status = ‘A’ AND product_series = ‘WXT’ THEN 1 ELSE 0 END AS prodcheck FROM product ) sub WHERE prodcheck = 1;
This query would only run once on the product table and will show the same results as separate SELECT queries with a UNION ALL.
The logic to show the right records is in the CASE statement. There are several lines, one for each set of criteria, and it returns a 1 if a match is found. This logic is all inside a subquery, and the outer query filters to show only those records where that CASE is 1.
There are a few different ways to write the CASE statement, but the idea is to only have the main query and several criteria in the CASE statement, rather than separate queries. However, make sure you test both versions of the query for performance, as there may be indexes that are used with the UNION query that don’t run with the CASE query.
4. Minimise the Use of DISTINCT
The DISTINCT keyword in SQL allows you to return unique records in the result set by eliminating duplicate results. This seems simple, and it’s a useful command. Using DISTINCT is OK in many cases, however, it can be a symptom of a different issue. If your result set is displaying data from many different tables, you might end up getting some duplicate results. I’ve seen this many times in my queries.
It can be tempting to add a DISTINCT keyword to ensure you don’t get duplicate records. But adding a DISTINCT keyword will likely cause an expensive operation to be performed on your query, slowing it down. It will give you the results you need, but it’s masking a problem elsewhere. It could be from an incomplete JOIN, or incorrect data in a table, or some criteria you aren’t considering, which is causing the duplicate row. Fixing the issue in your query or in your data is the right solution.
5. Redesign Data Value Lists to Use Tables
Occasionally you may need to write queries that use several values as criteria. This is often done as a WHERE clause and an IN keyword:
SELECT * FROM product WHERE status IN (‘A’, ‘P’, ‘C’, ‘S’);
This query might give you the results you want. What would happen if the status values change at some point in the future, or the business rules change which means you need to adjust this list.
If this list is coded into your query, you’ll need to adjust your query. This may result in change in application code and a deployment process.
Another way to do this is to store the values in a separate table and join to this table. For example, you could have a status_lookup table which has values and categories in it, where the category defines the data you need.
Your query could then be something like this:
SELECT product.* FROM product INNER JOIN status_lookup ON product.status = status_lookup.status WHERE status_lookup.category = ‘ACTIVE’;
This way, whenever the business rules change, all you need to do is update the data in your status_lookup table, and no code changes are required. This recommendation was also suggested in the article on SQL Code Smells.
6. UNION ALL instead of UNION
There are two similar keywords in SQL that are used to combine results: UNION and UNION ALL. They are called ‘set operators’, as they work with result sets.
There are some minor differences between them. UNION ALL shows all records in both result sets, and UNION shows all records excluding duplicates.
Just to be clear, UNION removes duplicates and UNION ALL does not.
This means, in Oracle, that an extra step is performed when using a UNION to remove all duplicate rows from the result set after it is combined. It’s the same as performing a DISTINCT.
If you really need duplicates removed, then use UNION. But, if you only want to combine values and don’t care about duplicates, or want to see all values, then use UNION ALL. Depending on your query, it will give you the same results and also perform better as there is no duplicate removal.
7. Use Table Aliases
A great way to improve your queries is to use table aliases. Table aliases are names you can give to tables in your queries, to make them easier to write and work with. For example, using our earlier query on product and status_lookup tables, this is what it looks like without a table alias:
SELECT product.* FROM product INNER JOIN status_lookup ON product.status = status_lookup.status WHERE status_lookup.category = ‘ACTIVE’;
You can add table aliases by specifying a name after the table name. These table aliases are usually short (one or a few characters), and are usually an abbreviation for the full table name:
SELECT p.* FROM product p INNER JOIN status_lookup s ON p.status = s.status WHERE s.category = ‘ACTIVE’;
The table alias of p for product and s for status_lookup are included with the tables in the query. Then, anytime you refer to those tables (in the SELECT clause, the JOIN, or the WHERE clause), you can use the table alias. It makes it easier to read and write.
Also, p and s were deliberately chosen as they are abbreviations for the full table name. This is a good practice to use, especially when working on larger queries, rather than using generic letters such as a or b. It’s much easier to tell which table a field comes from if you use a descriptive alias.
8. Only Use HAVING on Aggregate Functions
The HAVING clause in Oracle SQL is used to filter records from your result set. It’s very similar to the WHERE clause. However, the WHERE clause filters rows before the aggregate functions are applied, and the HAVING clause filters rows after the aggregate functions are applied. It can be tempting to use HAVING for everything if you’re using an aggregate function, but they do different things in your query.
For example:
SELECT status, COUNT(*) FROM product WHERE status IS NOT NULL GROUP BY status HAVING COUNT(*) > 1;
This will find the count of each product status that is not NULL where there is more than one record for the status, which is likely what you want. If you write the query using only the HAVING clause, it would look like this:
SELECT status, COUNT(*) FROM product GROUP BY status HAVING status IS NOT NULL AND COUNT(*) > 1;
This may give you different results, depending on your data. It may also perform worse, as it needs to aggregate all of the data before removing it using the HAVING clause. It also implies a different set of rules.
Be sure to only use HAVING on aggregate functions and use WHERE on results you want to restrict before the aggregate.
9. Always Specify Columns in INSERT Statements
The INSERT statement in Oracle SQL has an optional component where you specify the columns to insert data into:
INSERT INTO tablename (col1, col2… col_n) VALUES (val1, val2… val_n);
The part of the INSERT statement with the columns is the optional part. An INSERT statement without the columns will still work:
INSERT INTO product VALUES (1, ‘Large Chair’, 120.00);
However, a good habit to get into is to specify the columns in an INSERT statement. This has several benefits. First, it can prevent errors or data going into the wrong column. Without specifying the columns, there’s no guarantee which order the columns will be inserted into. This can cause errors to appear, or the data to be inserted with values in the wrong columns.
It’s also clear which columns represent which values. When you look at a statement without the columns, you’ll have to guess what the values are. If you add the columns, you know exactly which values are for each column.
Be sure to include the columns in your INSERT statement.
10. Avoid Object Names with Spaces
The final best practice I’ll recommend is to avoid using spaces in your object names. Many examples of SQL online specify object names (such as tables) that include spaces. Most of these examples are for Microsoft Access or SQL Server and include either square brackets or quotes around table names:
SELECT id, category_name FROM “Product Category”;
Using a table name with a space in it might be easier to read. However, it can cause several issues. Table names in Oracle are stored in upper case, or if they have quotes, they are stored as you enter them. This means whenever you refer to this table, you’ll need to use quotes and specify it as it was written. It’s inconvenient for you and for other developers.
Another reason is that it’s harder to refer to this table in queries. You’ll have to specify it with quotes, and probably need to use a table alias to ensure your queries are correct.
It’s much better to specify the object names without spaces. You can use underscores instead:
SELECT id, category_name FROM product_category;
You should follow your team’s naming conventions, which would include tables and other objects, which has been written about here.
From Oracle 12c, the maximum length for an object name was increased from 30 characters to 32,000 characters. This means you’ll have a lot more room to come up with a great name for a table. This doesn’t mean you should be excessive, but just choose a name that represents what you are creating, without using spaces.
Summary
So, there are my top 10 best practices for working with Oracle SQL. Some of them are applicable to all types of SQL, but many of them are Oracle specific.
The post 10 Best Practices for Writing Oracle SQL appeared first on Simple Talk.
from Simple Talk https://ift.tt/2LG5mfJ
via
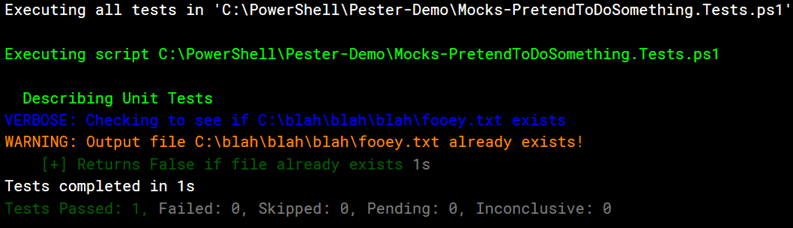
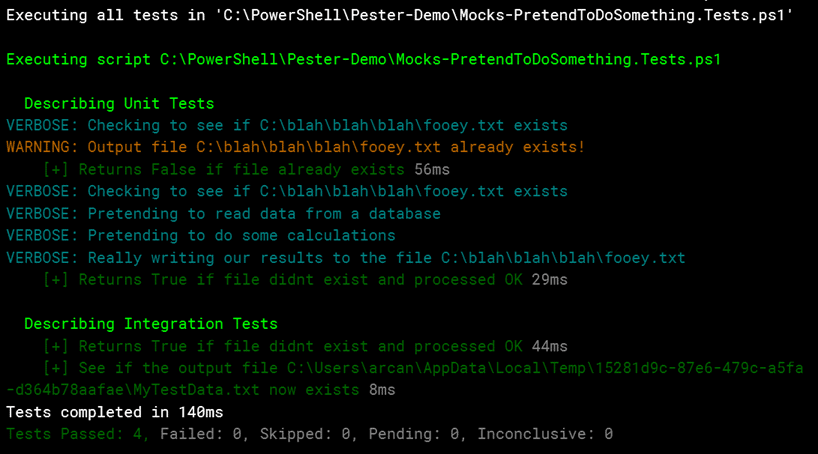
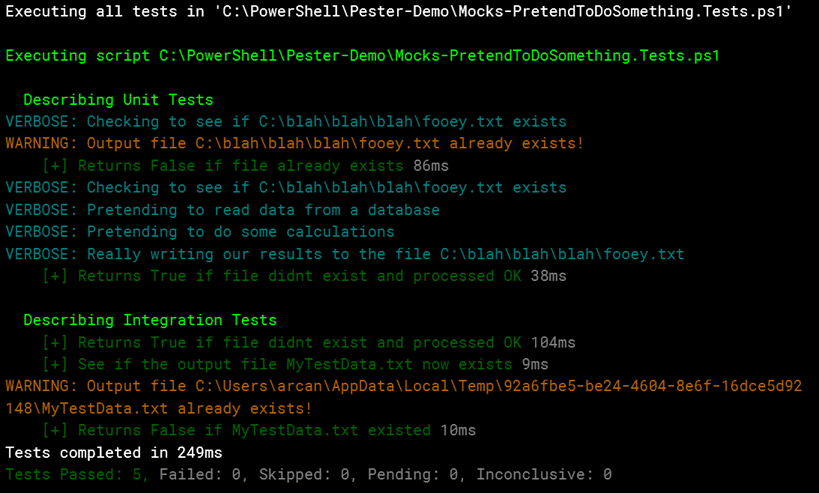
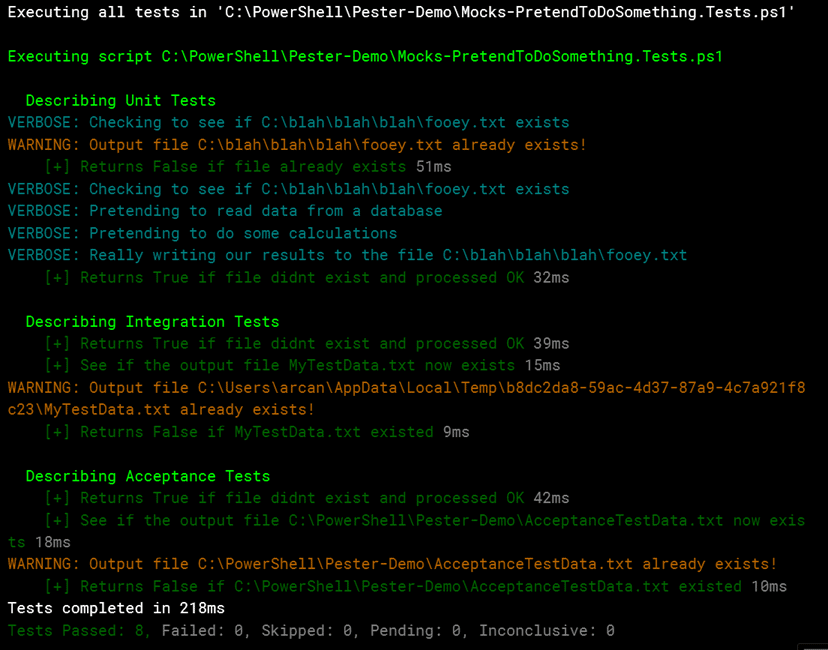
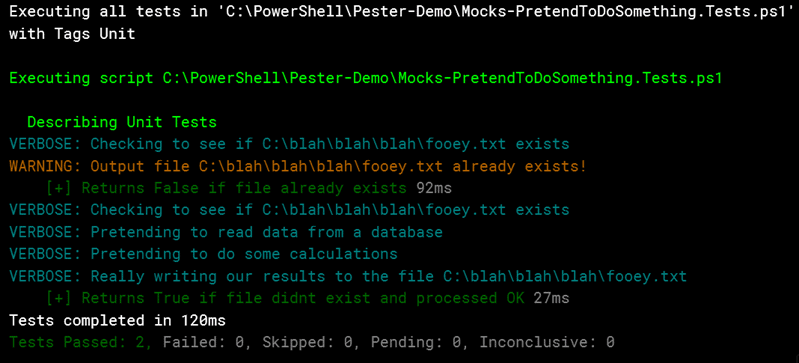
 button in the toolbar. When you do, in the output you’ll see only the unit tests were executed.
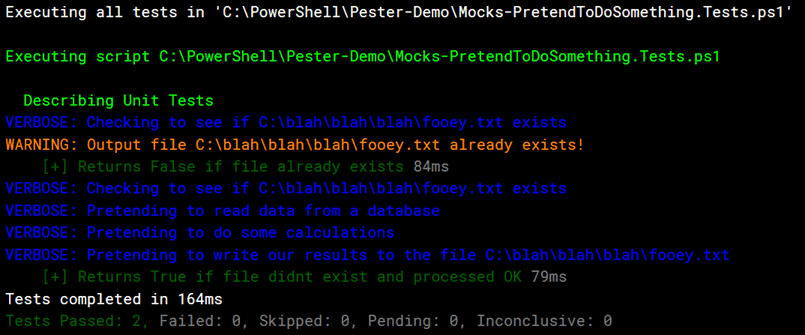
button in the toolbar. When you do, in the output you’ll see only the unit tests were executed.