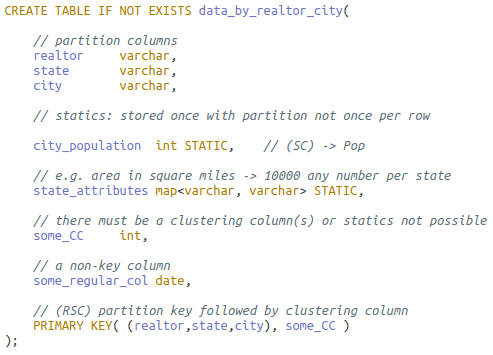
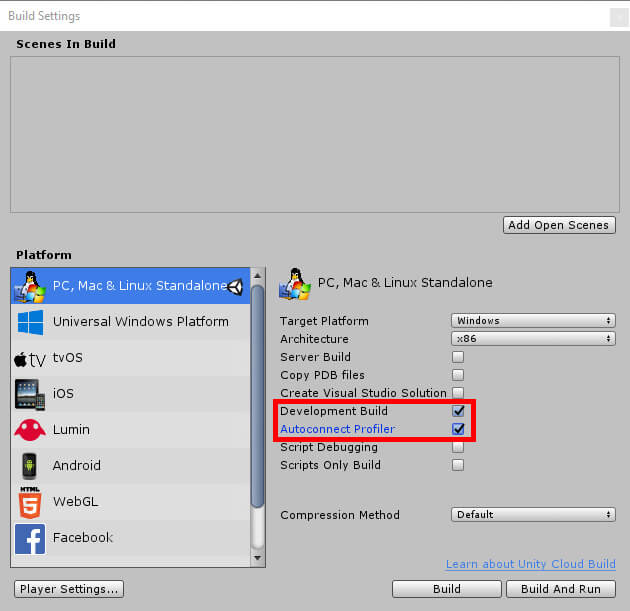
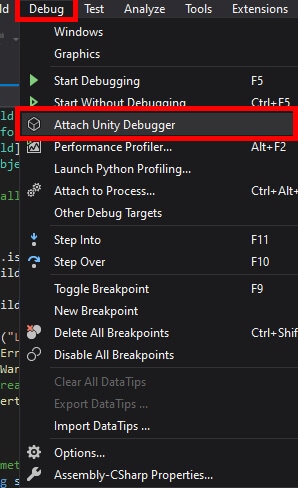
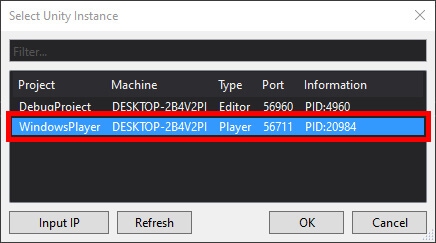
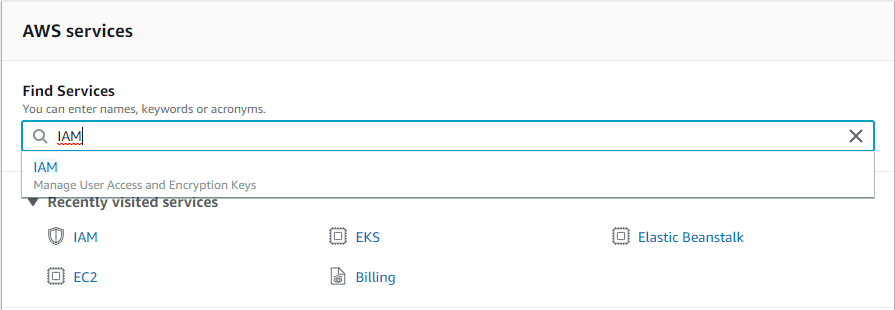
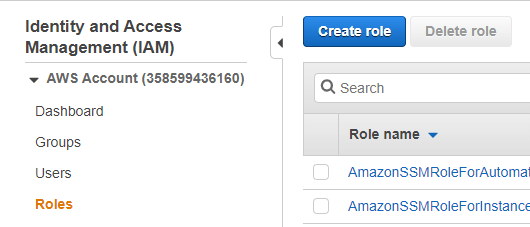
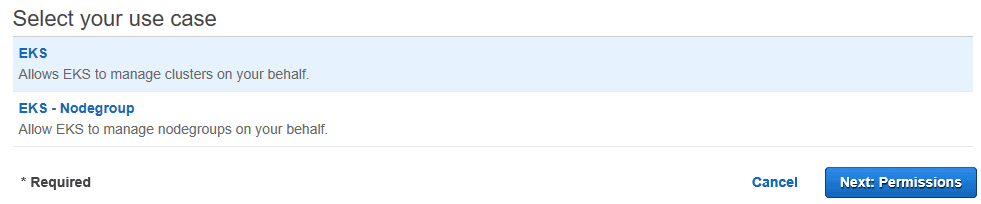
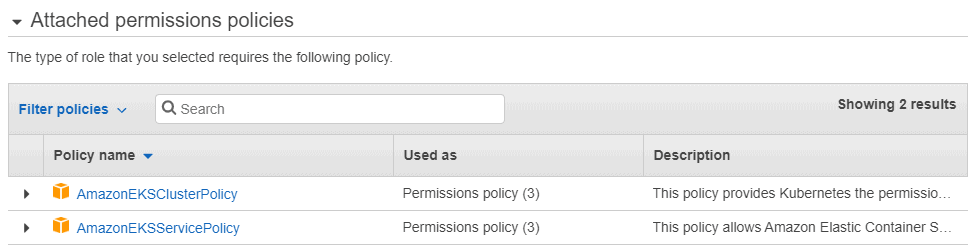
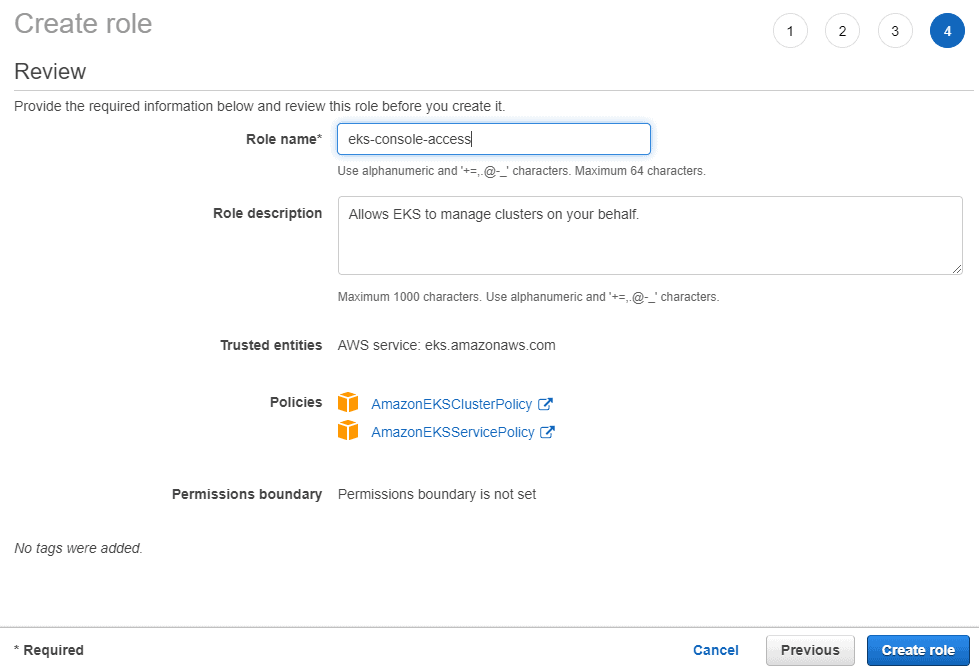
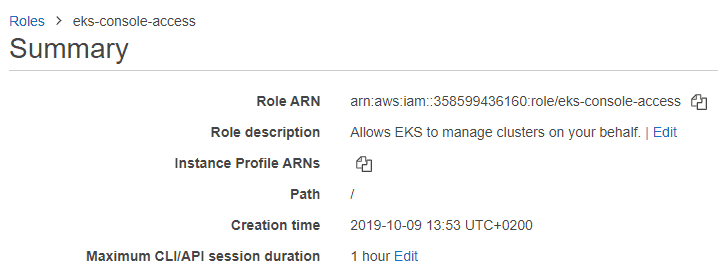
Database developers and DBAs can use many “mechanical” security mechanisms to safeguard corporate data. Robert Sheldon has written an excellent six part Introduction to SQL Server Security covering most of them. However, DBAs know that these alone are not enough, because they cannot fully secure data while ignoring human frailties: they should not merely operate a hermit kingdom.
No matter how good the mechanical security, the corporate database is vulnerable to the people and processes within the organization. Often the risks of breaches to sensitive data come not through intention or malice, but ignorance or expedience.
It is easy to deal with ignorance, but the lure of expedient decisions can be harder to resist. They are, by definition, a convenient way to deliver the desired results, in the short term, when it feels like the detrimental consequences don’t matter. It is, for example, tiresome for people to have only the ‘minimum required’ permissions to access the data, just enough for the role they are supposed to fulfil. How much more convenient it would be for a member of staff to have an elevated level of access. What could go wrong?
To meet the demands of society for the curation of personal data, and the vital need of a business for the security of its data, security must take precedence to convenience. Any expediency in dealing with matters of data curation and security must be cleared with the business, even when it is legal. It must be an explicit business decision at a senior level because it comes with a quantifiable risk in monetary and reputational terms.
Addressing ignorance
The key to dealing with a lack of knowledge about data curation and security is to ask questions.
What information do I need in order to be able to secure the data resource for which I am responsible and accountable?
Where is that information within the organization?
Who are the stewards of that information?
Am I a steward of any information that would help other employees to secure the resources for which they are responsible and accountable?
How can I, as a steward, keep others up to date with the information they need?
Is the data for which I am responsible secure, and how can I be sure?
The answers to these questions provide a checklist that should form part of an operational playbook, to be applies at the start of any new project or business initiative. These checklists and playbooks will ensure the consistency and completeness of a security assessment. The checklists are auditable artifacts that demonstrate compliance with organizational security policies. Under EU GDPR Article 35, organizations handling personal data are compelled to carry out a Data Protection Impact Assessment (DPIA). There will be a large overlap between the organizational security assessment and the DPIA. The UK information commissioner’s office provides handy checklists for awareness, screening, process and evaluation of DPIAs.
Communication and collaboration
Data curation requires that data is kept secure, that only the people who should access the data can do so, and that only the data that they need for their role is provided to them. It also requires information integrity. Is the data correct, can it be checked and corrected if necessary, and is it properly disposed of when no longer needed?
Data security and information integrity are closely linked, and they are both team sports. An effective data security regime needs communication and collaboration between technical and non-technical functions within the business. This is far easier in an Agile/DevOps culture, where a team should already comprise of most of the disciplines needed for that team to operate autonomously, although there will always be a few specialist functions that need to be accessed from outside the team. Rather than be embedded in a team, these specialist functions will work generically across teams. Examples of these are HR, legal, risk and compliance.
Information integrity also requires reconciliation of information between those disciplines or functions. Each discipline or function validates the information it receives from every other discipline or function. The organization is required to know where all copies of data are held and why, and what steps are taken to ensure that it is correct. The officers of any organization are responsible for legal compliance.
The diagram below focusses on the main communication paths necessary for a good security regime. The exact functions and boundaries may differ or blur from organization to organization. As a general principle every function shown in the diagram should be listening and talking to every other function. For simplicity’s sake, non-technical business functions are not represented (except for Human Resources).
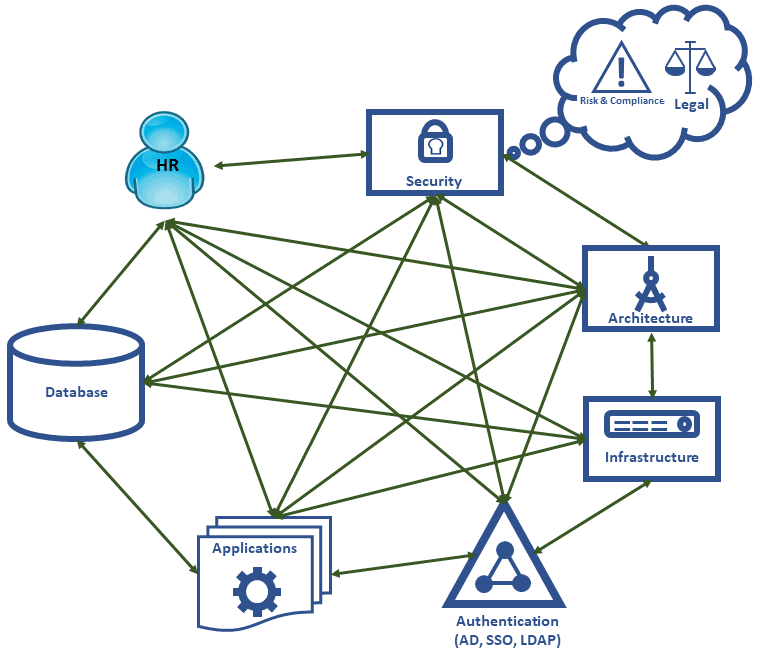
For any of these functions, security by obscurity is not a good strategy. If the way in which information is secured is opaque, then it is as opaque to people who should be guarding that information as it is to those people we wish to guard against: possibly more so. We must consider what artefacts are useful to help each function build systems that are secure. The following table provides examples but does not represent a definitive list of useful security artefacts:
|
Artefact |
Description |
|---|---|
|
Employee directory |
|
|
Database roles and permissions documentation |
A list of the database roles and what they are intended to represent. Thanks to Dr Codd’s rule 4 this does not have to be a static or offline document; it can be a dashboard or report driven directly from the database server. |
|
Database access log |
A facility to allow the analysis of patterns of behavior that are potential indicators of undesirable activity.
|
|
Data Catalog |
|
|
Applications catalog |
The current technical state of the organization:
|
|
Active Directory structure |
|
|
Network and infrastructure diagram |
|
|
Architectural road map |
Represents the future technical state of the organization. In effect this is what the future applications catalogue is intended to be. |
|
Software vulnerability log |
A collated list of software vulnerabilities for items in either the applications catalogue or architectural roadmap. |
|
Security policies and procedures |
Policies must be clear, unambiguous and written to help employees comply with any regulatory regime. These are most helpful when in the form of checklists or operational playbooks. |
Having identified business functions and useful artefacts that will help those functions secure the information within the organization, we can now explore the roles each function plays in maintaining those artefacts.
Human Resources
HR are important actors in any security theatre. They are the first to know if an employee’s status has changed and they are privy to several items of information that are useful in securing data.
- A list of current and active employees
- A list of, and process for, starters, leavers and job changers. Mandatory for PCI-DSS and/or ISO27001 compliance.
- A list of employees who are absent, sick or on holiday (ASH)
- A list of employees on “Gardening Leave”
- Organizational structure, job roles and line management
There must be a reconciliation process between HR’s records and the logins in the following systems:
- Active Directory
- Email systems
- Databases
- Applications including SaaS
Another important HR role in information security is to ensure that there is ongoing staff education. GDPR article 47 “Binding Corporate Rules” states that rules should specify that appropriate data protection training should be given to personnel having permanent or regular access to personal data. There must be dialogue between HR and the security and governance function to determine what form security training should take, and to provide an audit trail of who has had such training, the recency of that training, and the level of training provided.
As HR has access to some of the most personal of data, they must include themselves in any training. The other technical areas should be able to signal what training they require to ensure that what they build is secure.
It may be beneficial for HR to have the capability to deactivate user accounts given they will be the first to know if an employee has left the organization. It may also be judicious to disable logins when employees take annual leave or have extended periods of absence. This would not just be for security purposes but to help to safeguard the mental health of the employees on leave.
Development teams and infrastructure
The consequences of not having an application catalog were demonstrated back in 2003 by the SQL Slammer worm. Organizations with patched and up-to-date SQL Servers found their networks brought to a standstill by network traffic caused by the worm trying to propagate. Their suffering was caused by unpatched applications, of which they knew nothing, acting as attack vectors. If there had been a catalog, these applications could have been patched.
In an organization that has adopted a DevOps culture, most of the attributes mentioned earlier as part of an application catalogue are part of the software build. Practices that make the job of assembling such a catalog far easier, and even automatic, include:
- Infrastructure as code
- Configuration management
- Continuous integration and delivery
- Use of source control
A DevOps culture also addresses the consequences of involving network and infrastructure specialists too little and too late. Such late involvement threatens security because it means that the security infrastructure must be put together with avoidably imperfect knowledge, and in unnecessary haste.
Just as HR has a “starters and leavers” process, so an application catalog needs an “adopters and deprecators” process for the applications it holds. Applications need attention at all stages in their lifecycle. If an application is deprecated, then this represents an opportunity to reduce the attack surface area for the organization:
- Removal of database logins for the application and possibly even databases
- Removal of service accounts from Active Directory
- Deprecation of infrastructure
- Tightening of firewalls, network rules
Architects and architecture
In an Agile organization many of the disciplines that have traditionally been part of the architect role have been devolved, so they become part of the day to day tasks of the development teams.
Even so, it remains a primary duty of anyone aspiring to be an architect to control the technical diversity within an organization. The application catalog provides the means to monitor whether this is being achieved. For example, it will reveal that the organization is running multiple versions of the same application, library or framework, or ‘different’ libraries or frameworks that do more-or-less the same thing.
All complex systems have vulnerabilities. If you are using three ORM frameworks, then you have three sets of vulnerabilities to worry about. You also limit your internal pool of expertise to help address those vulnerabilities.
There is a cyclic relationship between the architectural roadmap and the applications catalog:
- Architects use the applications catalog to form an architectural roadmap for the organization and to help design and plan future systems.
- When implementing the architectural roadmap, much of the underlying detail that emerges should propagate through to the applications catalog.
The roadmap will also inform all parties as to what training needs to be incorporated into the plan.
Discussions regarding security tend to focus on blocking illegitimate activity. However, security also means ensuring that legitimate activity continues to take place. The architects also need to think about what performance metrics need to be available to ensure that applications, database and infrastructure folk build a system that is both secure and reliable.
Security and governance
In a post GDPR world, a new business idea may seem to be technically easy to execute, but will be on shaky ground, or maybe even quicksand, regarding laws and regulation.
- Does the proposed feature depend on personal data that the organization has consent to use?
- Is the data required for the feature necessary for the organization to carry out its primary business?
This is one of the reasons that a security and governance function inevitably has a proactive role. They must be subject matter experts advising on how to avoid introducing vulnerabilities and explaining what is required to implement good security practice.
GDPR article 25 requires us to build in data protection by design and default. It is far easier to build secure systems when security is a foundation stone of the design. You are likely to create more problems than you solve by attempting to secure something in retrospect.
Once again, the importance of an applications catalog, as well as a data catalog, becomes apparent. Its importance is in the detailing of the applications, libraries and frameworks in use within the organization and the versions and patch levels for each.
A fundamental duty of the security and governance function is to keep up to date with threats and vulnerabilities that might affect the organization, such as those arising from:
- Software used by the organization, whether it be apps, libraries or frameworks
- Tools and techniques that can invalidate security safeguards.
- Legal and regulatory change, such as GDPR
- Changing business requirements that may bring the organization under new regulatory bodies
- Social engineering approaches to defeating security, such as phishing.
- Organizational restructuring
Again, there should be cyclic relationship between the architectural roadmap and the work undertaken to identify vulnerabilities. The expertise of the security and government specialists informs the architectural roadmap, and so the architectural roadmap informs security and governance specialists as to what new software and tools will be required.
In the event of a vulnerability or threat, a security and governance function would provide an early warning for application developers, database teams and for those responsible for the network infrastructure. All parties should work closely together to ensure those vulnerabilities are addressed.
As vulnerabilities and threats are a moving target, they also have an important role in determining how security training should be updated so that people have the information they need to address new threats. Emerging training needs should be a feedback loop to HR.
Organizational behavior needed to build secure systems
If we accept that organizational security is a team sport, then we must consider the organizational behaviors needed to nurture a team mentality. Consider Patrick Lenceoni’s 5 dysfunctions of a team and what threat these dysfunctions pose when securing the organization. In this case each team member is an organizational function.
Trust
Team members need to trust in each other, and that other team members are competent. They need to feel that it is safe to admit to knowledge gaps and to ask for help from other team members, but also that they can hold each other to account and in turn be held to account themselves. Without trust, scarce resources are wasted because teams:
- Build isolated fortresses, without covering the grey areas in between, resulting in security vulnerabilities in the overall systems
- Build features to guard against the perceived incompetence of other team members rather than features to guard against real threats
- Create unnecessary complexity, making system security difficult to test and verify
Dealing constructively with conflict
Conflict, in the positive sense, can be the action of holding each other to account or drawing attention to vulnerabilities. If conflict is avoided, due to fear of political ramifications, then the risk is that security is weakened because critical information and feedback is withheld.
Attention to results
The desired outcome is a secure, appropriately accessible corporate data asset. The organization needs to decide how it can measure the implementation and effectiveness of the security regime intended to deliver that outcome. This includes what “KPIs” are and how they are presented.
If the organization identifies the security regime it wants, without identifying and quantifying the KPIs it will use to prove it has achieved it, then team members will tend focus on just the KPIs that indicate their individual behavior rather than KPIs that indicate the success or failure of the team as a whole.
Commitment to act
The clearest, most informative security dashboard on Earth is of no use unless there is commitment to act on the information presented. This requires commitment from each team member:
- To define appropriate processes in response to measures that indicate action is needed
- To enact those processes promptly when required
- To log actions taken and communicate that action to the team
Accountability
Each team member must be accountable for:
- Providing the information that allows others in their team to fulfil their security obligations.
- Making clear what information is required from other teams and departments
- Highlighting when that information is not forthcoming
Measurement, surveillance and monitoring
Most security breaches are internal to the organization and are often unintended, or caused by employee complacency, or both. Employees already have legitimate access to organizational systems so are already within the company’s security perimeter. For this reason, there needs to be robust and continual monitoring and logging of items such as the following:
- Changes to data
- Changes to infrastructure configuration
- Changes to application versions patch levels
- Changes to permissions
- Changes to role membership (both Active Directory and database)
- Logins and logouts
As with any measurement regime, we can only recognize and detect abnormal behavior if we have a baseline for what constitutes normal behavior. The thresholds for “abnormal” require careful definition; too high and threats are missed, too low and the system “cries wolf” and is soon ignored.
Monitoring SQL Server Security: What’s Required?
A monitoring tool must help us defend against both known and unknown avenues of attack. It must be adaptable, monitor a diffuse collection of metrics, and then help us determine the reason for any sudden change in the patterns of access.
The purpose of any alert, report or dashboard is to support a decision or be a clear call to action. Brevity and clarity should be the guiding principles with the recipient being the arbiter of what is useful.
Third party security specialists should carry out both external and internal penetration testing on the system. They will flush out vulnerabilities that would only otherwise be found by hostile parties, and their testing will verify the effectiveness of systems intended to spot anomalous behavior. Penetration testing should show up in the logs and trigger appropriate alerts.
Another important consideration is the perceived neutrality of the third party. Audits can uncover painful truths and receiving those truths from a neutral third party can be more palatable; if not, it is rarely frowned upon to shoot an external messenger.
Summary and recap
- Data security must ensure that legitimate people have access to the information they need, as well as preventing malicious actors from gaining access.
- Information integrity is essential to ensure that data can be both checked and corrected, and that data curation complies with the law.
- You must be able to prove that data security is not being compromised. It is no longer enough to claim you didn’t know about a breach.
- Collaboration and corroboration both aid the implementation of an effective security regime
- Housekeeping tasks help manage the security surface area thus making anomalies easier to spot
- Security by obscurity is not a good strategy. It is as likely, if not more likely, to hide vulnerabilities as it is to act as a preventative measure
- Database applications must, by design, allow the organization to meet the required standards of data security and information integrity.
The post Database Security, People and Processes appeared first on Simple Talk.
from Simple Talk https://ift.tt/2Q594DJ
via