The series so far:
- Introduction to SQL Server Security — Part 1
- Introduction to SQL Server Security — Part 2
- Introduction to SQL Server Security — Part 3
- Introduction to SQL Server Security — Part 4
- Introduction to SQL Server Security — Part 5
-
SQL Server provides a number of tools for helping you ensure that your environment and data remain secure. Some of the most important of these come in the form of catalog views, dynamic management views (DMVs), and built-in system functions. By incorporating them into your T-SQL statements, you can retrieve important security-related information about your SQL Server environment, such as which principals are enabled, what permissions are assigned to those principals, or how auditing is implemented on database objects.
In this article, I cover a number of these views and functions and provide examples of how you can use them to retrieve details about your system’s security. I created the statements in SQL Server Management Studio (SSMS), using SQL Server 2017, although most of the information I cover can apply to SQL Server editions going back to 2014 or earlier.
Microsoft divides security-related catalog views into server-level views, database-level views, encryption-related views, and auditing-related views. I’ve taken the same approach here, providing a section for each type. Because there are fewer security-related DMVs and system functions, I’ve provided only a single section for each of them.
In all cases, I cover only a portion of the available views and functions, but enough to give you a sense of how you can use them when administering a SQL Server instance. Just be aware that Microsoft provides plenty of others, so be sure to refer to SQL Server documentation as necessary to learn about those views and functions I haven’t covered here.
Server-Level Catalog Views
SQL Server offers numerous security-related catalog views that operate at the server level. Two of the most useful are sys.server_principals and sys.server_permissions. The sys.server_principals view returns a row for each existing server principal, and the sys.server_permissions view returns a row for each assigned server permission.
You can join these views together to see the permissions granted on specific principals. For example, the following SELECT statement returns the permissions assigned to SQL logins that have been enabled:
SELECT pr.principal_id, pr.name, pe.state_desc, pe.permission_name
FROM sys.server_principals pr INNER JOIN sys.server_permissions pe
ON pr.principal_id = pe.grantee_principal_id
WHERE pr.type_desc = 'SQL_LOGIN' AND pr.is_disabled = 0;
The sys.server_principals view includes the type_desc column, which indicates the principal type. SQL Server supports six types of server principals, including SQL_LOGIN, WINDOWS_LOGIN and SERVER_ROLE. The view also returns the is_disabled column, which indicates whether a principal is enabled (0) or disabled (1). Both columns are specified in the WHERE clause to filter out all but enabled SQL logins. Figure 1 shows the results returned by the SELECT statement on my system, which includes only a few test logins.
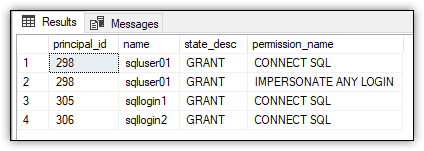
Figure 1. Permissions granted on SQL logins
You can also use the sys.server_principals view in conjunction with the sys.server_role_members view, which returns a row for each member of a fixed or user-defined server role. Because the sys.server_principals view includes all principals, including roles and logins, you can join the view to itself and to the sys.server_role_members view to retrieve the members of a specific role, as shown in the following example:
SELECT member.principal_id, member.name
FROM sys.server_role_members rm
JOIN sys.server_principals role
ON rm.role_principal_id = role.principal_id
JOIN sys.server_principals member
ON rm.member_principal_id = member.principal_id
WHERE role.name = 'sysadmin' AND member.type_desc = 'SQL_LOGIN';
The statement limits the results to the sysadmin role and to SQL logins. Self-joining the sys.server_principals view makes it possible to retrieve both the role and login names. Figure 2 shows the results I received on my system, which indicate that the only two SQL logins are members of the sysadmin role, one of which is the sa account.
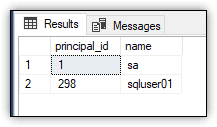
Figure 2. SQL logins in the sysadmin role
Another interesting catalog view is sys.system_components_surface_area_configuration, which returns a row for each executable object that can be enabled or disabled through SQL Server’s surface area configuration features. For example, the following statement uses the view to return a list of stored procedures included in the SMO and DMO XPs component:
SELECT database_name, schema_name, object_name
FROM sys.system_components_surface_area_configuration
WHERE state = 1 AND component_name = 'SMO and DMO XPs'
AND type_desc = 'SQL_STORED_PROCEDURE';
The type_desc column in the WHERE clause specifies the object type (SQL_STORED_PROCEDURE), and the state column indicates that the object should be enabled (1), rather than disabled (0). Figure 3 shows the results returned on my system.
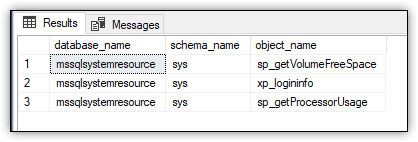
Figure 3. Stored procedures in the surface area configuration
The database_name value indicates which database contains the object. The possible values include master, msdb, and mssqlsystemresource (a read-only database that contains all the system objects).
Database-Level Catalog Views
Many of the database-level catalog views work much like their server-level counterparts, except that they’re specific to the current database. To try out some of these views, first create the Test1 database and then add the Sales schema (which will be used in later examples):
USE master;
GO
CREATE DATABASE Test1;
GO
USE Test1;
GO
CREATE SCHEMA Sales;
GO
After you create the database, you can run the catalog views within the context of that database. For example, you can use the sys.database_principals view to retrieve details about the existing database principals, and you can use the sys.database_permissions view to retrieve details about assigned database permissions. Similar to what you saw at the server level, you can join these views to see the permissions assigned to specific database principals. For example, the following SELECT statement returns certain types of permissions granted to the public role:
SELECT pm.state_desc,
pm.permission_name
FROM sys.database_permissions pm INNER JOIN sys.database_principals pr
ON pm.grantee_principal_id = pr.principal_id
WHERE pr.name = 'public' AND pm.class_desc = 'DATABASE';
The statement limits the results to permissions in the DATABASE class. However, the view can also return permissions for such classes as OBJECT_OR_COLUMN, SCHEMA, or DATABASE_PRINCIPAL, depending on what permissions have been assigned at the database level. Figure 4 shows the results that the SELECT statement returned on my system.
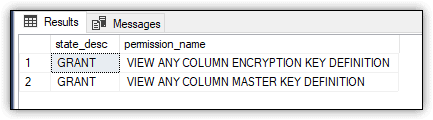
Figure 4. Database permissions granted to the public role
One way to check effective permissions without writing scripts yourself is to use Redgate’s SQL Census. It creates a report of who has access to what on your SQL Servers and makes best practice recommendations, like disabling SA accounts. It’s still in development but it’s a good starting point to check on your SQL Server permissions and undertake any necessary cleaning tasks.
SQL Server also provides database-level catalog views that do not have a server counterpart (and vice versa). For example, you can use the sys.master_key_passwords view to retrieve information about the database master key password, if the password was added by using the sp_control_dbmasterkey_password stored procedure.
To see how this works, start by creating a database master key in the Test1 database, as shown in the following example (using a stronger password than the one I’ve included here):
CREATE MASTER KEY
ENCRYPTION BY PASSWORD = 'tempPW@56789';
GO
After you’ve created the master key, use the sp_control_dbmasterkey_password stored procedure to add a credential that specifies the same password as the one used when creating the database master key:
EXEC sp_control_dbmasterkey_password
@db_name = N'Test1',
@password = N'tempPW@56789',
@action = N'add';
GO
When SQL Server tries to decrypt the database master key, it first attempts to use the service master key. If this doesn’t work, SQL Server searches the credential store for a master key credential, using that if it exists.
After you’ve created the master key credential, you can use the sys.master_key_passwords view to retrieve information about that credential:
SELECT * FROM sys.master_key_passwords;
The statement returns only the credential_id and family_guid values, as shown in Figure 5. The family_guid column displays the unique ID assigned to the database when it was originally created.
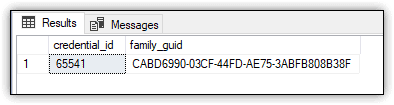
Figure 5. Configured database master key password
You can also use the sys.credentials view to retrieve credential information, as shown in the following example:
SELECT credential_id, name, credential_identity
FROM sys.credentials;
Although the sys.credentials view is a server-level catalog view, you can use it to see credentials created for database master keys. On my system, the SELECT statement returns the results shown in Figure 6.

Figure 6. Credential associated with the Test1 database master key
The results indicate that I have only one credential created on my SQL Server instance, the one for the Test1 database master key. Notice that the credential_id value shown here is the same value shown in Figure 5.
SQL Server also provides the sys.database_scoped_credentials view, which returns a row for each database-scoped credential in the database. The following SELECT statement uses the view within the context of the Test1 database:
SELECT * FROM sys.database_scoped_credentials;
The SELECT statement returns no rows for Test1. This is because the credential created for the database master key exists at the server level, not the database level.
Encryption-Related Catalog Views
The security-related catalog views also include about a dozen specific to SQL Server’s encryption features. One of these views is sys.certificates, which you can use to retrieve details about the certificates that exist in a database. To see the view in action, first create a certificate named Cert1 in the Test1 database, using the subject customer credit cards (or whatever subject you want to use):
USE Test1;
GO
CREATE CERTIFICATE Cert1
WITH SUBJECT = 'customer credit cards';
When you create a certificate without specifying a password, SQL Server uses the database master key to encrypt the certificate, which means that a master key must already exist. (You created the key in the previous section.) You can now use the sys.certificates view to retrieve information about the certificate:
SELECT name CertName,
certificate_id cert_id,
pvt_key_encryption_type_desc encrypt_type,
issuer_name
FROM sys.certificates;
Figure 7 shows the results returned on my system. Notice that the encryption type is ENCRYPTED_BY_MASTER_KEY.
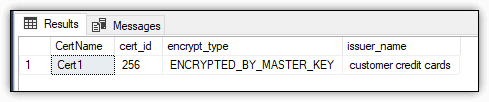
Figure 7. Cert1 certificate in the Test1 database
SQL Server also lets you add asymmetric and symmetric keys to your database. If you’ve added either type of key, you can use the sys.asymmetric_keys or sys.symmetric_keys view to return details about them. For example, suppose you create the following asymmetric key in the Test1 database:
CREATE ASYMMETRIC KEY Akey1
WITH ALGORITHM = RSA_2048
ENCRYPTION BY PASSWORD = 'tempPW@56789';
GO
The statement adds an asymmetric key named Akey1, using RSA encryption and password protection. You can now use the sys.asymmetric_keys view to retrieve information about the new key:
SELECT name key_name,
pvt_key_encryption_type_desc encrypt_type,
algorithm_desc,
key_length
FROM sys.asymmetric_keys;
Figure 8 shows the results returned by the SELECT statement.
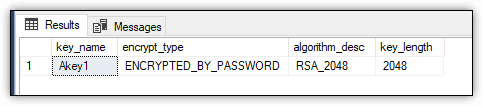
Figure 8. Akey1 asymmetric key in the Test1 database
The SELECT statement returns the key name, encryption type, algorithm, and key length, all of which were specified when creating the asymmetric key.
Auditing-Related Catalog Views
The final category of security-related catalog views includes those specific to SQL Server’s auditing features. If you’ve implemented auditing, these views can be particularly handy, especially the sys.server_audits and sys.database_audit_specifications views. The sys.server_audits view returns information about server audit objects, and the sys.database_audit_specifications view returns information about database audit specifications.
To see both views in action, start by creating and enabling the SrvAudit1 audit and the DbSpec1 database specification in the Test1 database:
USE master;
GO
CREATE SERVER AUDIT SrvAudit1
TO FILE (FILEPATH = 'C:\DataFiles\audit\');
GO
ALTER SERVER AUDIT SrvAudit1
WITH (STATE = ON);
GO
USE Test1;
GO
CREATE DATABASE AUDIT SPECIFICATION DbSpec1
FOR SERVER AUDIT SrvAudit1
ADD (SCHEMA_OBJECT_CHANGE_GROUP),
ADD (SELECT, INSERT, UPDATE, DELETE
ON Schema::Sales BY public)
WITH (STATE = ON);
GO
After you’ve created your server audit object, you can use the sys.server_audits view to view that object, specifying the audit name in your WHERE clause, as shown in the following example:
SELECT audit_id,
name audit_name,
create_date,
type_desc,
is_state_enabled is_enabled
FROM sys.server_audits
WHERE name = 'SrvAudit1';
The statement returns the results shown in Figure 9. Notice that the type_desc value is FILE, indicating that the audit log is saved to the file system rather than to the Security or Application log. The figure also indicates that the audit is enabled. (The is_enabled value is 1.)
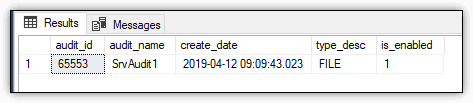
Figure 9. SrvAudit1 audit created on the server
You can then use the sys.database_audit_specifications view to view information about the database audit specification:
SELECT database_specification_id dbspec_id,
name spec_name,
create_date,
is_state_enabled is_enabled
FROM sys.database_audit_specifications;
The statement returns the results shown in Figure 10.
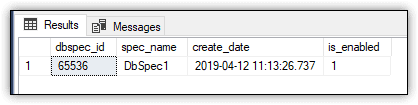
Figure 10. DbSpec1 database audit specification
SQL Server also provides several other catalog views specific to auditing, but their use depends on how you’ve configured auditing on your SQL Server instance. For example, if you create server audit specifications, you can use the sys.server_audit_specifications view to retrieve information about those specifications.
Dynamic Management Views
As with catalog views, SQL Server offers DMVs specific to auditing. One of these views is sys.dm_audit_actions, which lets you retrieve event-related information about audit actions and audit groups. For example, the following SELECT statement uses the view to return the IDs and names of the actions or groups with a class_desc value of LOGIN and a covering_parent_action_name value of LOGIN_CHANGE_PASSWORD_GROUP:
SELECT action_id,
name action_name
FROM sys.dm_audit_actions
WHERE class_desc = 'LOGIN' AND
covering_parent_action_name = 'LOGIN_CHANGE_PASSWORD_GROUP';
The class_desc column refers to the object class that the audit action applies to. The covering_parent_action_name column is the audit action or group that contains the row’s audit action. On my system, the SELECT statement returned the results shown in Figure 11.
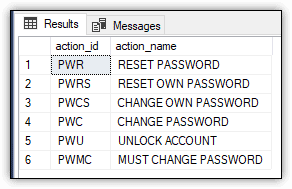
Figure 11. Audit actions in the audit log
Another DMV specific to auditing is sys.dm_server_audit_status view, which returns information about server audit objects. In the following example, the SELECT statement uses the view to retrieve the ID, name, status, and file size of each defined audit:
SELECT audit_id,
name audit_name,
status_desc,
audit_file_size
FROM sys.dm_server_audit_status;
The only audit I had defined on my system when I ran this statement was the one created in the previous section, giving me the results shown in Figure 12.
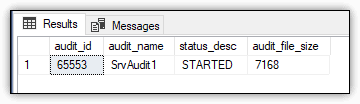
Figure 12. SrvAudit1 audit status
Security-related DMVs are not limited to auditing. SQL Server also provides several views specific to encryption, such as the sys.dm_database_encryption_keys view, which returns details about a database’s encryption state and its encryption keys.
You can see how the view works by setting up Transparent Data Encryption (TDE) on the Test1 database. For this, you need to take the following steps:
- Create a database master key in the
master database, if the key doesn’t already exist.
- Create a certificate in the
master database for securing the master key.
- Create a database encryption key in the
Test1 database.
Normally, there would be an additional step to enable TDE on the Test1 database, but that’s not necessary to demonstrate how the sys.dm_database_encryption_keys view works.
To create a database master key in the master database, run the following CREATE MASTER KEY statement, providing a much more robust password, of course:
USE master;
GO
CREATE MASTER KEY
ENCRYPTION BY PASSWORD = 'tempPW@56789';
GO
You can then use the sys.symmetric_keys catalog view to view information about the master database key:
SELECT name mkey_name,
symmetric_key_id mkey_id,
key_length,
algorithm_desc
FROM sys.symmetric_keys;
Figure 13 shows the results returned by the SELECT statement on my system. When you create a database master key in the master database, SQL Server also adds a service master key.
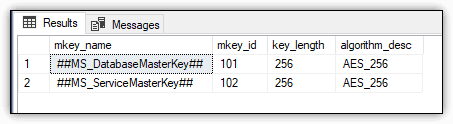
Figure 13. Database and service master keys
The next step is to create a certificate in the master database for securing the master key. You can do this easily enough by running the following CREATE CERTIFICATE statement:
CREATE CERTIFICATE TdeCert
WITH SUBJECT = 'TDE certificate';
GO
To verify that the certificate has been created, you can use the sys.certificates view, as shown in the following example:
SELECT name cert_name,
certificate_id,
pvt_key_encryption_type_desc encrypt_type,
issuer_name
FROM sys.certificates
WHERE issuer_name = 'TDE certificate';
Because the master database on my system includes only one certificate, the SELECT statement returns only one row, which is shown in Figure 14.
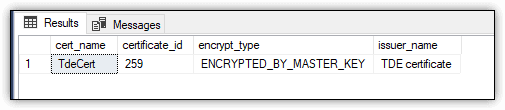
Figure 14. TdeCert certificate in the master database
The final step is to create a database encryption key in the Test1 statement. For this, you can use the following CREATE DATABASE ENCRYPTION KEY statement, specifying the TdeCert certificate you created in the master database:
USE Test1;
GO
CREATE DATABASE ENCRYPTION KEY
WITH ALGORITHM = AES_256
ENCRYPTION BY SERVER CERTIFICATE TdeCert;
When you run this statement, you should receive the following warning about backing up the certificate:
Warning: The certificate used for encrypting the database encryption key
has not been backed up. You should immediately back up the certificate
and the private key associated with the certificate. If the certificate
ever becomes unavailable or if you must restore or attach the database
on another server, you must have backups of both the certificate and
the private key or you will not be able to open the database.
This completes the steps you need to take to prepare your database to try out the sys.dm_database_encryption_keys view. The following SELECT statement uses the view to retrieve the encryption state, key algorithm, key length and encryption type of the database encryption key:
SELECT encryption_state,
key_algorithm,
key_length,
encryptor_type
FROM sys.dm_database_encryption_keys
WHERE DB_NAME(database_id) = 'Test1';
If you’ve been following along, the statement should return the results shown in Figure 15.
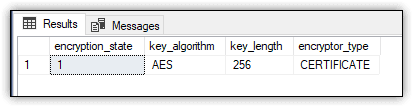
Figure 15. Database encryption key for the Test1 database
I realize that this is a long way to go about testing the sys.dm_database_encryption_keys view, but SQL Server supports only a handful of security-related DMVs, and I wanted to be sure you got to see some of them in action. That said, the TDE example I used here is actually based on one I created for the Simple Talk article Encrypting SQL Server: Transparent Data Encryption (TDE), which provides more specific information about enabling TDE on a SQL Server database.
Security-Related Functions
In addition to the catalog views and DMVs, SQL Server provides a number of security-related system functions. For example, you can use the sys.fn_builtin_permissions table-valued function to return details about the server’s built-in permission hierarchy or a subset of that hierarchy, as shown in the following SELECT statement:
SELECT class_desc,
covering_permission_name,
parent_class_desc
FROM sys.fn_builtin_permissions(DEFAULT)
WHERE permission_name = 'DELETE';
In this case, the sys.fn_builtin_permissions function takes DEFAULT as an argument, which means the function will return a complete list of built-in permissions. However, the WHERE clause limits those results to the DELETE permission. Figure 16 shows the results that were returned on my system.
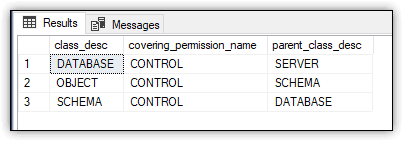
Figure 16. Built-in DELETE permissions on the SQL Server instance
SQL Server also provides a number of system functions for working with user and login accounts. To demonstrate how some of these work, first create the sqllogin1 login and then create the sqluser1 user in the Test1 database, based on the sqllogin1 login:
USE Test1;
GO
CREATE LOGIN sqllogin1
WITH PASSWORD = 'tempPW@56789';
GO
CREATE USER sqluser1 FOR LOGIN sqllogin1;
GRANT SELECT, INSERT, DELETE
ON SCHEMA::Sales TO sqluser1;
GO
The script also includes a GRANT statement that assigns the SELECT, INSERT, and DELETE permissions to sqluser1 on the Sales schema. You can verify these permissions by running the fn_my_permissions table-valued function within the security context of sqluser1:
EXECUTE AS USER = 'sqluser1';
SELECT permission_name
FROM fn_my_permissions ('Sales', 'SCHEMA');
REVERT;
GO
The EXECUTE AS USER statement changes the security context to sqluser1, and the REVERT statement changes the security context back to the original user. Because the SELECT statement runs under the context of sqluser1, it returns the results shown in Figure 17, which verify the permissions assigned to that user.
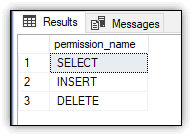
Figure 17. Permissions granted to sqluser1
SQL Server also provides a number of scaler functions for verifying a user’s identity, including the following:
- The
SUSER_NAME function returns the user’s login identification name.
- The
SUSER_ID function returns the user’s login identification number.
- The
SUSER_SID function returns the user’s login security identification number (SID).
- The
USER_NAME function returns the user’s database user account name.
- The
USER_ID function returns the user’s database user identification number.
For each of these functions, you can provide a parameter value or you can provide no value, in which case the function uses the current user or login account. You can test this out by calling the functions within the security context of sqluser1:
EXECUTE AS USER = 'sqluser1';
SELECT SUSER_NAME() login_name,
SUSER_ID() login_id,
SUSER_SID() login_sid,
USER_NAME() dbuser_name,
USER_ID() dbuser_id;
REVERT;
GO
Figure 18 shows the results I received on my system. Notice that the results list the correct user name and the login name associated with that user.

Figure 18. User and login names and IDs for sqluser1
SQL Server also provides the IS_MEMBER scalar function for verifying whether the current user is the member of a specified group or role. For example, the following SELECT statement uses the function to determine whether sqluser1 is a member of the db_owner role:
EXECUTE AS USER = 'sqluser1';
SELECT USER_NAME() dbuser_name,
CASE
WHEN IS_MEMBER('db_owner') = 1 THEN 'member'
WHEN IS_MEMBER('db_owner') = 0 THEN 'not member'
WHEN IS_MEMBER('db_owner') = NULL THEN 'not valid'
END AS is_member;
REVERT;
GO
The IS_MEMBER function can return only one of three values:
- If
0 is returned, the user is not a member of the specified group or role.
- If
1 is returned, the user is a member of the specified group or role.
- If
NULL is returned, the group or role is not valid.
Figure 19 shows the results returned by the SELECT statement. As expected, the user is not a member of the db_owner role (unless you added the user to the role).
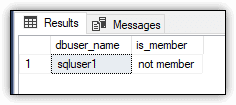
Figure 19. Verifying sqluser1 membership
Another fun built-in function is PWDCOMPARE, which lets you compare an existing password to a specified password. In this way, you can test for blank passwords or inadequate or common passwords, such as pa$$word.
To try out the function, first create the sqllogin2 login with a blank password (not in a production environment):
CREATE LOGIN sqllogin2
WITH PASSWORD = '' , CHECK_POLICY = OFF;
GO
Next, run the following SELECT statement, using the PWDCOMPARE function in the WHERE clause to return any logins with a blank password:
SELECT principal_id,
name login_name
FROM sys.sql_logins
WHERE PWDCOMPARE('', password_hash) = 1;
The first argument passed into the PWDCOMPARE function is the unencrypted password, which in this case is an empty string. The second argument tells the function to use the password encryption hash. The function returns a 1 if the specified password matches the user’s actual password. Otherwise, the function returns 0. In this case, the WHERE clause specifies that the function must return 1 for the row to be returned. Figure 20 shows the results I received on my system.
Figure 20. Comparing login passwords
The SELECT statement should return only the sqllogin2 login. If your results include other logins, you might want to reevaluate your current security strategy.
SQL Server Security Views and Functions
SQL Server provides a number of security-related catalog views, DMVs, and system functions in addition to what I covered here, and you certainly should take the time to learn about what’s out there. These views and functions can be very useful when trying to understand and troubleshoot security on a SQL Server instance. The more familiar you are with what’s available, the easier it will be for you to do your job and the more effectively you can ensure the security of your data.
The post Introduction to SQL Server Security — Part 5 appeared first on Simple Talk.
from Simple Talk http://bit.ly/2Iz5osA
via