Cosmos Database (DB) is a horizontally scalable, globally distributed, fully managed, low latency, multi-model, multi query-API database for managing data at large scale. Cosmos DB is a PaaS (Platform as a Service) offering from Microsoft Azure and is a cloud-based NoSQL database. Cosmos DB is sometimes referred to as a serverless database, and it is a highly available, highly reliable, and high throughput database. Cosmos DB is a superset of Azure Document DB and is available in all Azure regions.
With Cosmos DB you can distribute the data to any number of Azure regions, i.e., the data can be replicated to the geolocation from where your users are accessing, which helps in serving data quickly to users with low latency.
Features of Cosmos DB
Globally Distributed
With Azure Cosmos DB, your data can be replicated globally by adding Azure regions with just one click.
Linearly Scalable
Linear Scalability is the ability to handle the increased load by adding more servers to the cluster. Cosmos DB can be scaled horizontally to support hundreds of millions of transactions per second for reads and writes.
Schema-Agnostic Indexing
Cosmos DB’s database engine is schema agnostic, and this enables automatic indexing of the data. Cosmos DB automatically indexes all the data without requiring schema and index management.
Multi-Model
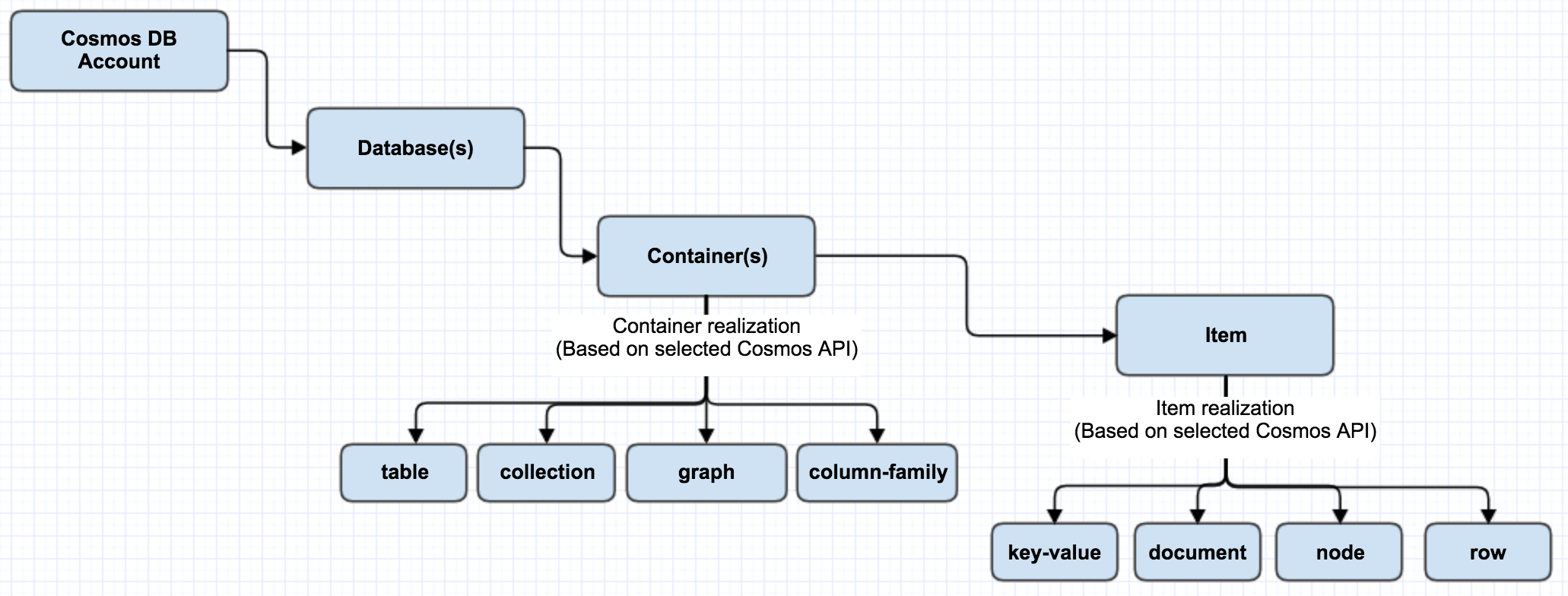
Cosmos DB is a multi-model database, i.e., it can be used for storing data in Key-value Pair, Document-based, Graph-based, Column Family-based databases. Irrespective of which model you choose for your data persistence, global distribution, provisioning throughput, horizontal partitioning, and automatic indexing capabilities are the same.
Multi-API and Multi-Language Support
Microsoft has released SDKs for multiple programming languages including Java, .NET, Python, Node.js, JavaScript, etc. Cosmos DB has Multi API support, i.e., SQL API, Cosmos DB Table API, MongoDB API, Graph API, Cassandra API, and Gremlin API.
Multi-Consistency Support
Cosmos DB supports 5 consistency levels, i.e., Eventual, Prefix, Session, Bounded and Strong. Multi Consistency is discussed in detail later in the article.
Indexes Data Automatically
Cosmos DB indexes data automatically on ALL fields in all documents by default without the need for secondary indexes, but you can still create custom indexes. Azure’s automatic indexing capability indexes every property of every record without having to define schemas and indices upfront. This capability works across every data model.
High Availability
Cosmos DB provides 99.999% availability for both reads and writes for multi-region accounts with multi-region writes. Cosmos DB provides 99.99% availability for both reads and writes for single-region accounts. Cosmos DB automatically fails over, if there is a regional disaster. Your application may also programmatically failover if there is such a case.
Guaranteed Low Latency
Azure Cosmos DB always guarantees 10 milliseconds latency at the 99th percentile for reads and writes for all consistency levels. Data can be geographically distributed to any number of Azure regions, so the stored data can be available nearest to the customers, which reduces the possible latency in retrieving the data.
Multi-Master Support
Cosmos DB supports multi-master, which means the writes, in addition to reads, can be scaled elastically across any number of Azure regions across the world. With the multi-master feature, you can choose that all data servers act as write servers. To enable the multi-master feature for your applications, you need to enable multi-region writes. Follow these instructions to configure the multi-master feature.
Multi-master support is now available in all Azure regions.
How Cosmos DB Works
Assume you have a website that’s used by users across multiple geographic locations and the database writes are into the database located in US region (in non-multi-master mode). This database is considered as a primary. When the data is written to the US database, the users in the US location will be able to get the data faster compared to other users in other geo locations due to network latency. If the multi-master feature is enabled, the data is concurrently written to all the selected regions simultaneously.
To solve these latency issues, the data has to be replicated to the user’s nearest region so that users can fetch the data faster from the nearest region. For example, if a user is located in Mumbai, India, then this user should be able to access data from the Mumbai region. Set up read databases in the nearest region of your users and replicate the data from the primary database to this secondary read database. When data is written to the primary database, the data is replicated to read databases, which are globally distributed.
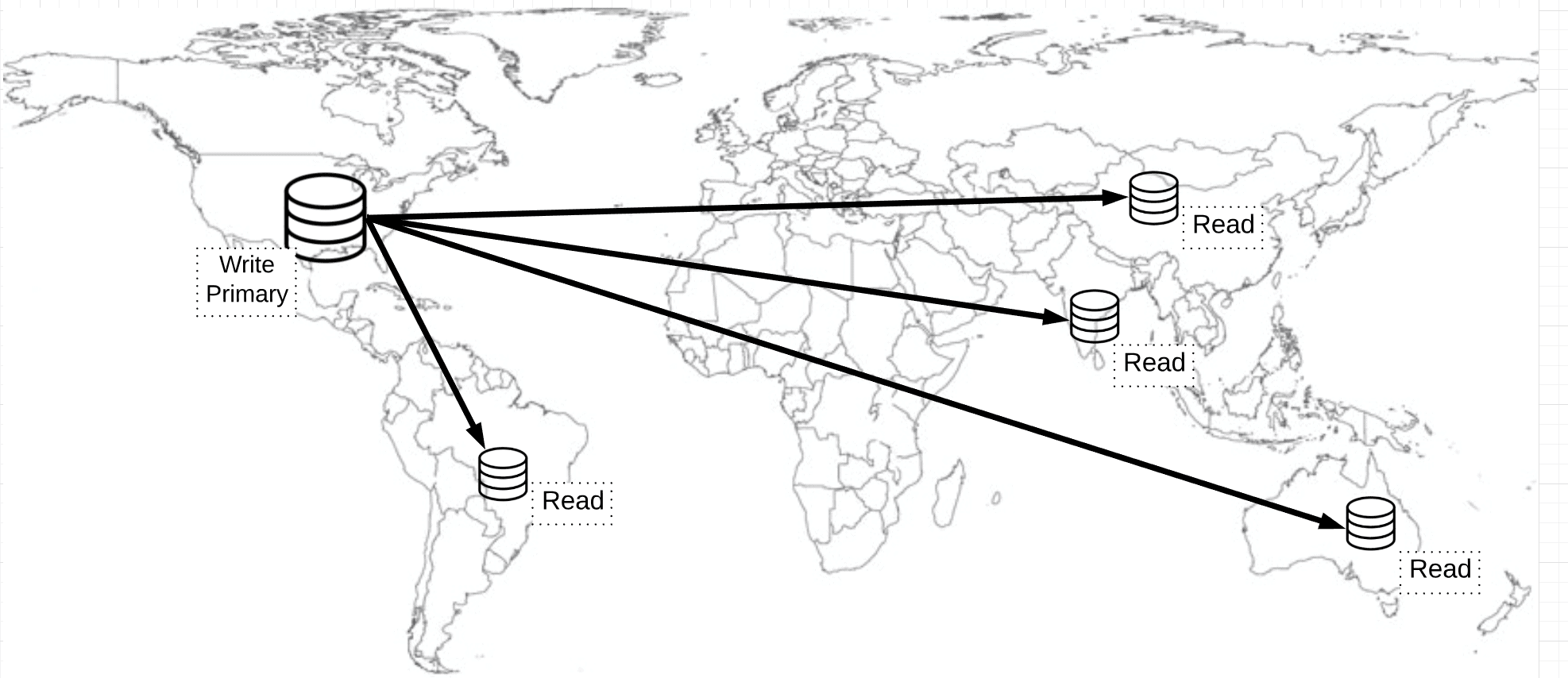
The challenge to achieving the planet scale database architecture is Consistency (Consistency is a property that indicates all replicas of the database are in sync and maintain the same state of a given object at any given point of time). For example, if the data is written to the primary database in the U.S, then it takes a few milliseconds to sync this data to other regions from the primary. During this synchronization period, users reading from the U.S get the latest data, while users from another region may get old data, i.e., the data is not consistent between primary and replicas. This is called as Eventual Consistency.
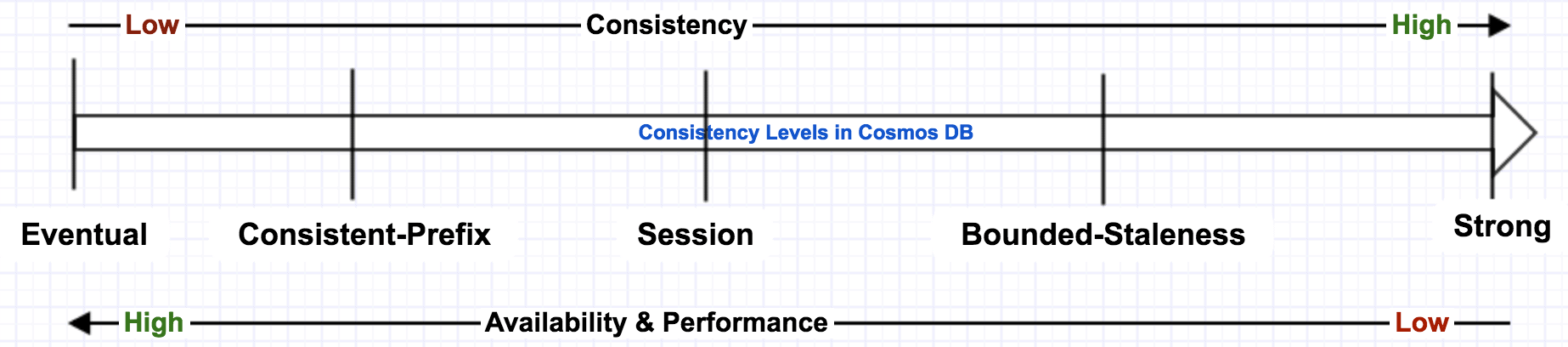
Consistency Levels in Cosmos DB
Azure Cosmos DB offers 5 consistency levels so that you can choose the right consistency level for your application.
Eventual:
In eventual consistency, the data that is written to the primary node is propagated to read-only secondary nodes, which are globally distributed, eventually. It takes some time to get the data available to the users of the readable secondary. This consistency level is suitable for applications that are not mission critical. It gives low latency and better performance, but there is a possibility that these users may see stale data for a brief period, and the data may not be in order.
Consistent Prefix:
Clients read the data in the same sequence (D, C, B, A) that has been committed (A, B, C, D). You’ll start seeing the updated data as it starts to go and the data is the right order. However, a complete data set is not guaranteed.
Session:
Committed users will see the data that they just committed. However, users in other geo locations may not be able to get this data version until replication happened. This is the most widely used consistency level.
Bounded Staleness:
It is an indicator to define how much staleness period you set. If you set staleness period as 2 hours, then even though the data is replicated to all secondary nodes, the clients still see the old value. If you set staleness=0, then it’s a strong consistency.
Strong:
Strong consistency always guarantees the latest copy of the data (i.e., highly consistent data) for clients irrespective of where they are reading from but gives a relatively low performance. This consistency level scoped to a single region. This consistency level is suitable for mission-critical applications (e.g., stock trading applications),
Eventual consistency may result in inconsistencies in the data the clients read due to the data being replicated to secondary nodes eventually, but it gives better performance. Strong consistency results in consistent data served to clients but gives poor performance.
While creating Azure Cosmos DB, you can choose the default consistency level, but this can be changed while reading the data from Cosmos DB from your application.
Consistency vs Performance on different consistency levels.
Cosmos DB Containers
Azure Cosmos DB Container is schema-agnostic and the unit of scalability. A container is horizontally partitioned and replicated across multiple regions. Based on the partition key, added items in the container and provisioned throughput are distributed automatically across a set of logical partitions. Items in the container don’t need to be similar items (e.g., Person, Vehicle, Business Entity, etc.) and they can have arbitrary schemas. Containers can have fixed or unlimited collections. Fixed collections limit you to a single partition, and don’t need a partition key set since everything is stored in a single partition. In unlimited, collections are not limited in the number of partitions.
Azure Cosmos DB allows you to set TTL (Time-To-Live) for each item in the container or set the same TTL for all the items in the container. Once the TTL is expired, those items will be deleted from the container, and the query on this container will not return the expired items. You may follow the steps outlined here to enable the TTL on items in the containers.
Following diagram outlines the relation among Cosmos DB account, Database, Collection, and Items.
Cosmos DB’s Multi-Model Capabilities
Cosmos DB supports the following five data models: Key-Value, Column-Family, Document, and Graph database models. Regardless of which data model you use, core content model of the Cosmos DB engine is based on ARS (Atom-Record-Sequence, which defines persistent layer for key-value pairs) and projects different data models in different APIs. Cosmos DB exposes the data in JSON format.
Depending on the type of application, use an appropriate data model. If an existing MongoDB or Cassandra Database based applications are to be migrated to Cosmos DB, it requires minimal to no code changes in application code. If an application requires a relationship between entities, then a graph data model works better. Each of the supported data models has an API to integrate with Cosmos DB. The data model is determined based on the selected API for the database. You have to choose the most relevant API for your application at the time of creating the container (i.e. “database instance”). Based on the chosen API, the desired data model (graph, key-value, document or column) is projected on the underlying data store. Because of the way the data is stored and retrieved, you can use only one API against a container; multiple APIs usage is not possible.
Take a look now into each of the data models.
Key-Value Pair Data Model (Table API):
In this data model, each entity consists of a key and a value pair. The value itself can be a set of key-value pairs. This is very similar to a table in a relational database where each row has the same set of columns. The Key-Value pair solution is supported on standard Azure table API. This Table API is primarily helpful for existing Azure Table Storage customers in migration to Cosmos DB.
Column-Family Data Model:
This data model supports Cassandra API. Existing Cassandra implementations can be easily and quickly moved to Cosmos DB and use column family format, which is used in Cassandra. Column Family data model is similar to key-value data model except that the items in the data model adhere to the defined schema.
Document Data Model:
This model supports SQL API and MongoDB APIs; both of these APIs give the document data model. These two APIs are different, though they are similar in data modeling. SQL API allows building transactional stored procedures, triggers, and user-defined functions. SQL API stores entities in JSON in a hierarchical key-value document. MongoDB API stores in BSON (Binary encoded version of JSON, which extends JSON with additional data types and multi-language support).
SQL API works with Document DB protocols, whereas MongoDB API works with MongoDB APIs. Both these APIs allow interacting with the documents in the database. If you already have a MongoDB solution and you want to make it scale out or globally aware, you can switch to Cosmos DB and use MongoDB API for interacting with the documents.
The max document size in Cosmos DB is 2 MB unlike the max document size of 16MB in MongoDB.
Graph Data Model:
Graph database implements a collection of interconnected entities and relationships. Microsoft has chosen to use Gremlin API from Apache Tinkerpop open source project. Gremlin API allows you to interact with a Graph database globally scaled and provides a graph traversal language, which enables to efficiently query across many relationships exist in a graph database.
Best Practices in Using Cosmos DB for Better Performance
- Partition Key: Partition Key acts as a logical partition of your data. There are logical and physical partitions in Cosmos DB. Each Partition has a limit of 10GB. If this limit is exceeded per partition, “Partition key reached maximum size of 10 GB” error will be thrown. If you see this error, then it indicates that you have reached the limit for your partition in the collection. To resolve this issue, you have to recreate the collection and choose your partition key such that all the data items stored against that key are under the 10 GB limit and transfer your data from old collection to new.
- Getting data from the same partition will be much faster than getting data from multiple partitions. Cross-partition queries add latency.
- Use Table API for migrating existing Azure Table Storage customers into Cosmos DB quickly. Document Data model SQL API is more capable than Table API.
- Cosmos DB document size is limited to 2 MB and is not supposed to be used for content storage. For larger payload storage, use Azure Blob Storage instead.
- To get better performance, relax consistency as needed.
- Tune indexing policy appropriately for faster writes.
- Cosmos DB is rate limited. If you have set low RU (Read Units)/s and executing a large query, the results from Cosmos DB may be slow.
Summary
Understanding Cosmos DB’s features such as multi-model, multi API and different levels of consistency levels helps in selecting the right API and model for your application. Choosing the right API model and the right level of consistency for your application will help improve the performance of the queries. This article discusses different features and consistency levels of Cosmos DB and also some of the best practices.
The post Overview of Azure Cosmos DB appeared first on Simple Talk.
from Simple Talk http://bit.ly/2IOfQvN
via
No comments:
Post a Comment