If you are not already aware, SQL Server 2008 and SQL Server 2008 R2’s extended support will end on 9 July 2019. Microsoft has communicated this end date for a while now, including this announcement with resources on how to migrate from these two versions of Microsoft SQL Server.
What This Means
Microsoft has a defined lifecycle support policy, but there are two separate policies at the time of this article. The one SQL Server 2008 and SQL Server 2008 R2 fall into is known as the Fixed Lifecycle Policy. Under this policy, Microsoft commits to a minimum of 10 years of support, with at least five years of support each for Mainstream Support and Extended Support. What is the difference between the two? What happens when Extended Support ends?
Mainstream Support
Under Mainstream Support, customers get support both for incidents (issues with the application or system) and security updates. In addition, a customer can request product design and feature changes. If there is a bug found that isn’t security related, Microsoft may choose to fix it and release an update. Microsoft has rolled up many of these fixes into service packs and cumulative updates over the years.
Extended Support
Extended Support ends the regular incident support as well as requests for product design and feature changes unless a customer has a particular support contract now called Unified Support. Microsoft will continue to release security updates but will not typically release updates for other types of bugs. SQL Server 2008 and SQL Server 2008 R2 are in the fixed lifecycle until 9 July 2019.
Beyond Extended Support
Without being part of the Extended Support Update Program, there are no more updates, security or otherwise for your organisation once extended support ends. Only if Microsoft deems that a particular security vulnerability is sensitive enough will they decide to release a patch even for systems that are now in beyond extended support status. Microsoft has released patches a couple of times for out of support operating systems, but it should not be something you count on. I will talk more about Extended Support towards the end of this article when discussing what to do if you cannot migrate from SQL Server 2008 or SQL Server 2008 R2 in time.
Compliance Requirements
Depending on what industry standard, government regulations, and laws that apply to your organisation, you may be in a situation where you will be out of compliance should you have unsupported software. This would mean you would have to participate in the Extended Support Upgrade Program, incurring the expense of that program.
Reasons to Upgrade
If you are like me, you do not have a lot of spare time to upgrade a system for the sake of it. In IT there is always more to do than there is time to do it. Microsoft discontinuing support is a reasonable justification, but I would hope to get more out of an upgrade and the resulting chaos that always accompanies such efforts than just staying in support. The good news is that by upgrading from SQL Server 2008 or 2008 R2, there are additional features that you can put to immediate use. These features do not even require touching any applications. In addition, newer versions of SQL Server include plenty of features that would require some modification but are worth considering. Here is a list of some of this new functionality:
In Memory OLTP
Once upon a time, there was the DBCC PINTABLE() command, which allowed you to keep a table in memory for better performance. That stopped with SQL Server 2005, though the command was still present in that version of SQL Server. The idea was that SQL Server’s optimisation and fetch capabilities were robust enough to keep up with demand.
Of course, this did not hold true. As a result, Microsoft researched and developed Hekaton, which is an in-memory database option. Designed from the ground up, it doesn’t function at all like the old DBCC PINTABLE() command because how the data is stored is different. If you need the performance such an option provides, it became available with SQL Server 2014.
Columnstore Indexes
Most queries don’t require all the columns in a table. However, because a standard index is organised by row, you have to retrieve every row, and every column of every row, for each row which matches the query predicate. Conceptually, data is stored like this, with every column being kept together for a given row:
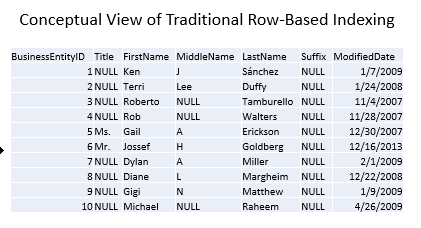
In other words, the engine is probably making a lot of extra reads to get the data you need. However, since that’s the way data is stored, you don’t have any other choice.
Columnstore indexes store the data in separate segments, one column per segment. A column can consist of more than one segment, but no segment can have more than one column. At a high level, you can think of the index working like this:
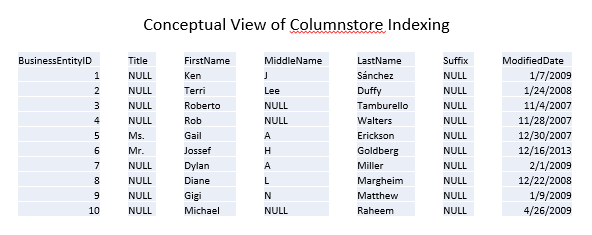
As a result, you just have to pull the segments related to the columns you care about, reading fewer pages and therefore achieving better performance. Continuing with the conceptual view, a query only wanting BusinessEntityID, FirstName, and LastName requires fewer reads because SQL Server doesn’t have to also grab data for Title, MiddleName, Suffix, and ModifiedDate simply to read in the entire row:
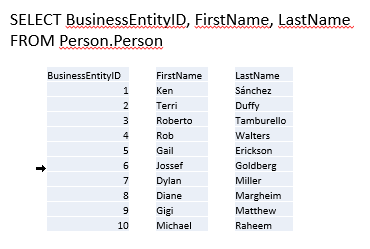
Columnstore Indexes are especially helpful in reporting and analytical scenarios with star or snowflake schema with a large fact table. The segmentation of the columns and the compression built into columnstore indexes means the query runs a lot faster than with a traditional index. However, this feature is not available until SQL Server 2012.
Availability Groups and Basic Availability Groups
If you have ever worked with traditional failover cluster instances, you understand the pains that this high availability (HA) option brings with it. The good news is that there is one instance, and all databases are highly available. The biggest bear of a requirement is the shared storage that all the nodes can access. This means you only have one set of the database files, and there is only one accessible copy of the data.
With a failover cluster instance, failover means stopping SQL Server on one node and starting it on another node. This can happen automatically, but during that failover, the SQL Server instance is unavailable.
With Availability Groups, introduced in SQL Server 2012, the HA is at the database level. Availability Groups do not require shared storage. In fact, Availability Groups do not use shared storage at all. This means you have more than one copy: at least one primary and from one to eight secondaries. These secondaries can be used for read-only access. In addition, there is technology that allows any of the partners (primary or secondary) to reach out to the other partners if a partner detects page-level corruption and get a correct page to replace the corrupted page. This feature is Automatic Page Repair.
Finally, with SQL Server 2016, Microsoft introduced Basic Availability Groups. Do you want the high availability but you do not need to access a secondary for read-only operations? Then you can take advantage of a basic availability group which only requires Standard Edition, therefore, it’s significantly cheaper.
Audit Object
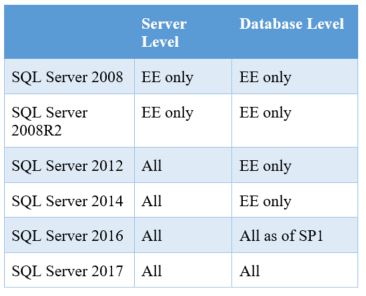
One of the easiest ways to set up auditing is with the aptly named Audit object. However, when Microsoft first introduced this feature in SQL Server 2008, Microsoft deemed it was an Enterprise Edition only feature. While you can do similar things using Extended Events (actually, the Audit object is a set of Extended Events), it is not as easy to set up.
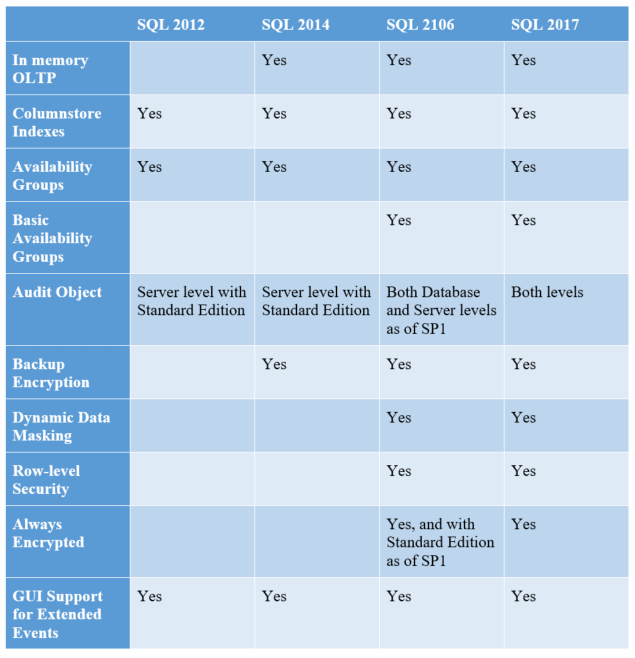
With industry’s need for auditing only growing, Microsoft has changed its stance in stages. Starting in SQL Server 2012, Microsoft enabled server-level auditing for Standard Edition. Then, in SQL Server 2016, starting with SP1, you can now use the Audit object at the database level with Standard Edition. Gaining access to Audit can be a huge benefit for compliance on our SQL Servers. I have found it helpful to have a quick chart:
Backup Encryption
When Microsoft introduced Transparent Data Encryption (TDE), it also introduced encrypted backups. However, initially, the encrypted backups were only for databases protected by TDE. TDE is an Enterprise Edition only feature. That meant you only had encrypted backups if you (a) were using Enterprise Edition and (b) had configured TDE on a particular database.
The third-party market (including Red Gate) has offered encryption in their SQL Server backup products for years. As a result, the community asked for Microsoft to also include backup encryption as a standard function for Microsoft SQL Server without having to use TDE. As a result, Microsoft added it to SQL Server 2014.
Backup encryption is crucial because smart attackers look for database backups. If an attacker can grab an unencrypted database backup, the attacker does not have to try and break into SQL Server. The attacker gets the same payoff but with less work. Therefore, if you can encrypt the database backups, especially if you belong to a firm without a third-party backup solution, you force the attackers to use a different, hopefully, more difficult method to get to the data. The more techniques an attacker must try, the more likely you are to discover the attempted hacking.
Dynamic Data Masking
I will admit to not being a fan of data masking. Solutions implementing data masking either leave the data at rest unmasked or they store the algorithm with the masked data in some form. This makes sense since privileged users must be able to see the real data. SQL Server is no different in this regard.
However, the purpose of SQL Server’s data masking is to provide a seamless solution for applications and users who shouldn’t see the actual data. You can define the masking algorithm. You can also define who can see the real data using a new permission, UNMASK. As long as you don’t change the data type/length of the field used in order to accommodate the masking algorithm, you can implement dynamic data masking without changing the application code or a user’s query unless they’re doing something to key off of the actual data.
Microsoft introduced this feature in SQL Server 2016, and its implementation can solve typical audit points around protecting the data in a system or report. As a result, it’s a great reason to upgrade from SQL Server 2008/2008R2 if you need to meet this sort of audit requirement.
Row-Level Security
You could implement row-level security solutions in SQL Server for years using views. However, there are some issues with this, as there are information disclosure issues with these home-grown solutions. The attack is basic: a savvy attacker can execute a query which reveals a bit about how the solution was built by forcing an error. A true, integrated row-level security solution was needed. As a result, Microsoft implemented row-level security as a feature first in Microsoft Azure and then in SQL Server 2016.
Speaking from experience, getting the home-grown solutions correct can be a problem. You have to be careful about how you write your filtering views or functions. Sometimes you’ll get duplicate rows because a security principal matches multiple ways for access. Therefore, you end up using the DISTINCT keyword or some similar method. Another issue is that often the security view or function is serialised, meaning performance is terrible in any system with more than a minimal load.
While you can still make mistakes on the performance side, you avoid the information disclosure issue and the row duplication issue.
Always Encrypted
When looking at encryption solutions for SQL Server, you should ask who can view the data. The focus is typically on the DBA or the administrator. Here are the three options:
- DBAs can view the data.
- DBAs cannot view the data but OS system administrators where SQL Server is installed can.
- Neither the DBAs nor the system administrators can view the data.
System administrators are usually singled out for one of two reasons:
- The DBAs also have administrative rights over the OS. In this case, #1 and #2 are the same level of permissions, meaning the DBAs can view the data.
- The system administrators over the SQL Servers do not have permissions over the web or application servers.
If the DBAs can view the data, then you can use SQL Server’s built-in encryption mechanisms and let SQL Server perform key escrow using the standard pattern: database master key encrypts asymmetric key/certificate encrypts symmetric key encrypts data. If the DBAs cannot view the data and they aren’t system administrators but system administrators can (because they can see the system’s memory), then you can use the SQL Server built-in encryption, but you’ll need to have those keys encrypted by password, which the application has stored and uses. In either case, the built-in functions do the job, but they are hard to retrofit into an existing application, and they are not the easiest to use even if you are starting from scratch.
If neither the DBAs nor anyone who can access the system’s memory is allowed to view the data, then you cannot use SQL Server’s built-in encryption. The data must be encrypted before it reaches the SQL Server. Previously, this meant you had to build an encryption solution into the application. This is not typically a skillset for most developers. That means developers are operating out of their core body of knowledge, which means they work slower than they would like. It also means they may miss something important because they lack the knowledge to implement the encryption solution properly, despite their best efforts.
Another scenario is that you may need to retrofit an existing application to ensure that the data in the database in encrypted and/or the data in flight is encrypted. Retrofitting an application is expensive. The system is in production, so changes are the costliest at this point in the application’s lifecycle. Making these changes is going to require extensive testing just to maintain existing functionality. Wouldn’t it be great if the encryption/decryption could happen seamlessly to our application? That is what Always Encrypted does.
Always Encrypted is available starting with SQL Server 2016 (Enterprise Edition) or SQL Server 2016 SP1 (opened up for Standard Edition). Always Encrypted has a client on the application server. The client takes the database requests from the application and handles the encryption/decryption seamlessly. The back-end data in SQL Server is stored in a binary format, and while SQL Server has information on how the data is encrypted: the algorithm and metadata about the keys, however, the keys to decrypt are not stored with SQL Server. As a result, the DBA cannot decrypt the data unless the DBA has access to more than SQL Server or the OS where SQL Server is installed.
Better Support for Extended Events
Extended Events were introduced in SQL Server 2008, but they were not easy to use. For instance, there was no GUI to help set up and use Extended Events. The only way to work with Extended Events was via T-SQL.
Starting with SQL Server 2012, GUI support was introduced in SQL Server Management Studio (SSMS). With each new version of SQL Server, Microsoft extends what you can monitor with Extended Events (pun intended). The ability to capture information about new features is only instrumented with Extended Events. If you are still in “Camp Profiler,” you cannot monitor these features short of capturing every T-SQL statement or batch. That is not efficient.
One of the most important reasons to move off Profiler server-side traces and towards Extended Events is performance. The observer overhead for traces is generally higher than extended events, especially under CPU load. This is especially true using Profiler (the GUI) for monitoring SQL Server activity. Another area of performance improvement is with the filter/predicate. You can set a filter just like with Profiler. However, with Extended Events, the filtering is designed to happen as quickly as possible. SQL Server will honour the filter as it considers whether or not to capture an event. If it hits the filter, it cuts out and goes no further for that particular extended event set up. This is different than the deprecated trace behaviour. While trace will still apply the filter, it does so after the event/data collection has occurred, which results in “relatively little performance savings.” With these two improvements, Extended Events should capture only the data you specify, and it should cut out if it determines you aren’t actually interested in the event because of the filters you specified, meaning less load on the system due to monitoring.
That’s why, in the majority of cases, Extended Events are more lightweight than traditional traces. They certainly can capture more, especially if you are using any of the new features introduced from SQL Server 2012 and later. This, in and of itself, may be a great reason to migrate away from SQL Server 2008. After all, the better you can instrument your production environment while minimising the performance impact, the better.
Windowing Functions, DDL We’ve Cried For, and More, All in T-SQL
With every new version of SQL Server, Microsoft will add new features as well as improve existing ones. With SQL Server 2012, Microsoft introduced a significant amount of new functionality through T-SQL. Some of this functionality applied to queries, but others applied to configuration and database schema management. Here are three at three meaningful examples.
Windowing Functions
Window(ing) functions compute aggregations based on defined partitions. SQL Server 2008 and 2008R2 did have windowing functions using OVER() and PARTITION BY for ranking and aggregates. With SQL Server 2012 You get LAG() and LEAD(). You can also do more with aggregate functions. For instance, imagine the scenario where you had to report the order total for each order, but you also had to show the previous order total (LAG) and the next order total (LEAD). You might have another requirement, which is to show a running total. All of this can be put into a simple query:
SELECT SalesOrderID, OrderYear, OrderMonth, OrderDay, OrderTotal,
LAG(OrderTotal, 1, 0) OVER (ORDER BY SalesOrderID) AS PreviousOrderTotal,
LEAD(OrderTotal, 1) OVER (ORDER BY SalesOrderID) AS NextOrderTotal,
SUM(OrderTotal) OVER (ORDER BY SalesOrderID ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS RunningTotal
FROM
-- This subquery is to aggregate all the line items for an order
-- into a single total and simplify the year, month, day for
-- the query
(SELECT SOH.SalesOrderID, YEAR(SOH.OrderDate) AS 'OrderYear',
MONTH(SOH.OrderDate) AS 'OrderMonth', DAY(SOH.OrderDate) AS 'OrderDay',
SUM(SOD.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail AS SOD
JOIN Sales.SalesOrderHeader AS SOH
ON SOD.SalesOrderID = SOH.SalesOrderID
GROUP BY SOH.SalesOrderID, SOH.OrderDate) SalesRawData;
The neatest function is SUM() because of the ORDER BY in the OVER() clause. Note that the query uses the keyword ROWS in the framing clause. This is new to SQL Server 2012, and the use of ROWS here tells SQL Server to add up all the rows prior to and including the current one. Since SQL Server is gathering the data at one time, the single query performs faster than having multiple queries trying to gather, re-gather, and calculate the same information. In addition, the data is all on the same row:
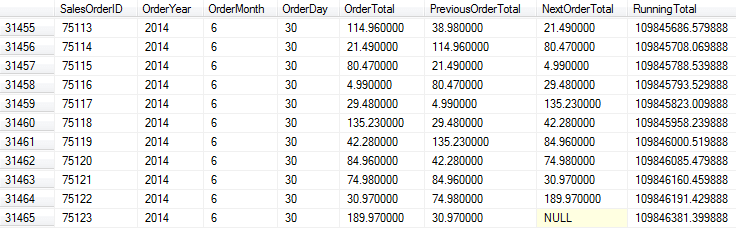
There are more window functions around rank distribution as well as the RANGE clause, which is similar in use to ROWS. SQL Server 2012 greatly expanded SQL Server’s window function support.
User-Defined Server Roles
When SQL Server 2005 debuted, it introduced a granular access model. A DBA could apply security to almost every object or feature of SQL Server. Microsoft pushed for the use of the new security model over the built-in database and server roles. However, at the time some server-level functionality keyed in on whether a login was in a role like sysadmin rather than checking to see if the login had the CONTROL permissions. As a result, DBAs stayed primarily with the roles that came with SQL Server.
The other issue was that SQL Server didn’t permit user-defined roles at the server level. Therefore, if a DBA wanted to implement a specific set of permissions at the server level using the granular model, that could be done, but it wasn’t tied to a role. This conflicted with the best practice of creating a role, assigning permissions to a role, and then granting membership to that role for the security principals (logins or users, in SQL Server’s case). DBAs could carry out this best practice at the database level, but not at the server level. With SQL Server 2012, server level user-defined roles are now possible. Therefore, it’s now possible to follow this best practice. However, you need to segment your permissions at the server level; you can create a role, assign the permissions, and then grant membership.
DROP IF EXISTS
A common problem DBAs face when handling deployments is when a script wants to create an object that already exists or the script wants to drop an object that isn’t there. To get around it, DBAs and developers have typically had to write code like this:
IF EXISTS(SELECT [name] FROM sys.objects WHERE name = ‘FooTable’) DROP TABLE FooTable;
Note that each of these statements must have the correct name. As a result, a DBA or developer putting together a deployment script updating hundreds of objects would need to verify each IF EXISTS() statement. Without third-party tools which do this sort of scripting for you, it can be cumbersome, especially in a large deployment. All that IF EXISTS() does is check for the existence of the object. Therefore, the community asked Microsoft for an IF EXISTS clause within the DROP statement that did the check and eliminated the need for this type of larger, more error-prone clause. Microsoft added this feature in SQL Server 2016. Now, you can simply do this:
DROP TABLE IF EXISTS FooTable;
If the table exists, SQL Server drops it. If the table doesn’t exist, SQL Server moves on without an error.
Ways to Migrate
Hopefully, you have gotten the go-ahead to migrate from your old SQL Server 2008/2008R2 instances to a new version. The next question is, “How?” One of the biggest concerns is breaking an existing application. There are some techniques to minimise these pains.
DNS is Your Friend
One of the chief concerns I hear about migrating database servers is, “I have to update all of my connections.” Sometimes this is followed by, “I’m not sure where all of them are, especially on the reporting side.” Here is where DNS can help.
I recommend trying to use “friendly” names in DNS that don’t refer to the server name, but to a generic name. Say there is an application called Brian’s Super Application. Rather than pointing to the actual server name of SQLServer144, you create an alias in DNS (a CNAME record in DNS parlance) called BriansSuperApp-SQL which is an alias to SQLSErver144. Then you can point the application to that friendlier name. If, at any point, the IP address on SQLServer144 changes, the CNAME will always be a reference to SQLServer144, meaning the client will get the correct IP address. Moreover, if you need to migrate to another SQL Server, say SQLServer278, simply change the alias. Point BriansSuperApp-SQL to SQLServer278, and the clients are repointed. You don’t have to change any connection information. This is an example of loose coupling applied to infrastructure.
But what if there are already applications configured to point directly to SQLServer144? Again, DNS can help. If you can migrate the databases and security from SQLServer144 to a newer SQL Server and then bring SQLServer144 off-line, you can use the same trick in DNS. Only instead of having a reference to BriansSuper-SQL that points to SQLServer278, you will delete all DNS records for SQLServer144 and then create a DNS record called SQLServer144 that points to SQLServer278. I have used this trick a lot in migrations, but it does require all the databases to move en masse to a single replacement server and the old server to be completely offline to work.
Remember Compatibility Levels
If your application requires a compatibility level of SQL Server 2008 or 2008R2, keep in mind that newer versions of SQL Server can support databases set to older versions of SQL Server via ALTER DATABASE. The compatibility designation for both SQL Server 2008 and 2008R2 is 100. All supported versions of SQL Server allow you to run a database in this compatibility mode. Therefore, you should be able to deploy to SQL Server 2017 (or 2019, if it is out by the time you are reading this).
Data Migration Assistant
What if you’re not sure if you can migrate from SQL Server 2008? Is there functionality that will break in the new version? Can you move the database to Azure? Trying to answer these questions can be a daunting task. However, Microsoft does have the Data Migration Assistant to assess your databases’ readiness to upgrade or move to Azure. Previously, DBAs would assess SQL Server Upgrade Advisor. Data Migration Assistant is extremely easy to use. First, you’ll need to create a project and tell DMA what you’re attempting to do:
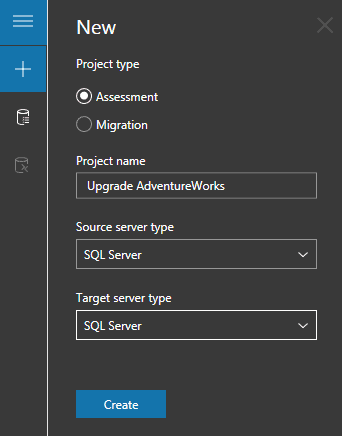
In this case, the assessment is for a SQL Server to SQL Server migration (on-premises). Then, you’ll need to tell DMA what to connect to and what to assess. Once DMA has verified it can connect and access the databases you’ve chosen, you’ll indicate what you what DMA to look at:
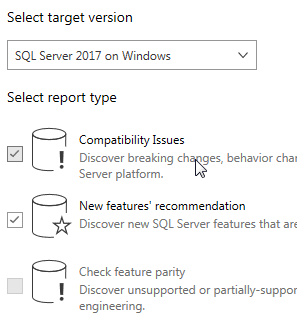
Here, the target specified is SQL Server 2017 and DMA is being instructed to not only look at compatibility issues but also to examine any new features that might be helpful. DMA will churn away and return its assessment:
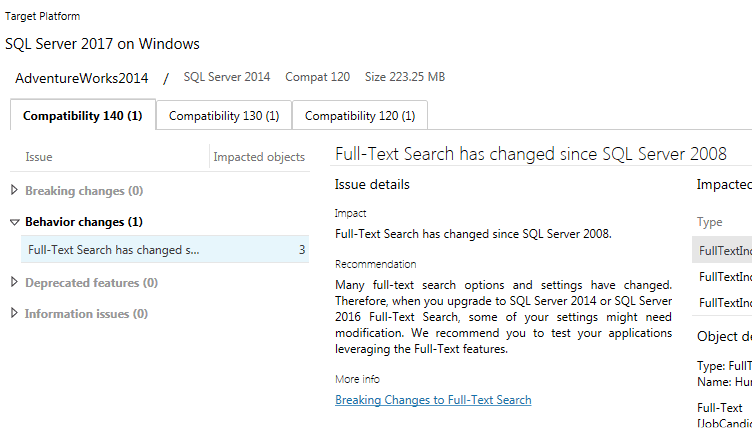
In this case, DMA noticed that Full-Text Search objects exist in the database. While DMA evaluated a SQL Server 2014 system and DB, note that DMA still flags a SQL Server 2008 issue. Like with any tool recommendations, you’ll need to consider whether the information presented applies in your case. Here, because DMA is looking at a SQL Server 2014 DB running on SQL Server 2014, there’s no issue with upgrading the database to a SQL Server 2017 instance.
Now AdventureWorks is a tiny, relatively simple database. You wouldn’t expect DMA to find much if anything. For your databases, especially large and complex ones, expect DMA to churn for a while and to have more recommendations and warnings.
What If You Can’t?
You may be in a situation where you cannot make a move by the deadline. What are your options? There are three:
Extended Security Updates
The first option, especially if you have to stay with on-premises SQL Servers, is to join the Extended Support Update program mentioned earlier. This is a pricy option, but it is the only way to maintain support for on-premises SQL Servers. Keep in mind, though, that in order to enroll in this program, Microsoft may very well ask for a migration plan on how and when you will move to supported versions of SQL Server.
Microsoft Azure
If you have the option of moving to a VM in Azure, then you will have additional coverage for three more years, as Microsoft indicated in a post on the Microsoft Azure blog. Microsoft has promised extended security updates at no extra cost if you are running on an Azure VM. In addition, the blog includes a reminder that a managed instance in Azure is another option for customers.
Again, you have to have the capability of moving to Azure. However, if you already in Azure or if you have been preparing to establish a presence, then an Azure VM may be a solution if you cannot migrate off SQL Server 2008 or 2008R2.
Go Without Support
The last option is to continue to run SQL Server 2008 or SQL Server 2008 R2 with no support. Your organisation may reason that Microsoft SQL Server has been relatively secure with only a handful of patches. There are a couple of issues, however.
The first issue is “you don’t know what you don’t know.” Someone may find a vulnerability tomorrow that is critical, easily exploitable, and which adversaries seize upon quickly. This was the case with SQL Slammer in the SQL Server 2000 days.
The second issue is around compliance. Some regulations, industry standards, and laws require systems to be running on supported, patched software. If your organisation is required to comply in such a manner, then going without support means the organisation is knowingly violating compliance and risks being caught. This is not just an immediate issue. After all, many regulations and laws can result in penalties and fines well after the period of non-compliance.
An organisation should only choose to go without support after a proper risk assessment. I know of cases where organisations decided to continue on NT 4 domains because they could not migrate to Active Directory. Other organisations have had key software that only ran on Windows 95, SQL Server 6.5, or some other ancient software. They could not find a proper replacement for that essential software and the business risk was more significant not to have the software or its functionality than running unsupported operating systems or software. However, those were informed decisions made after considering which was the greater risk.
Conclusion
With SQL Server 2008 and 2008 R2 extended support ending, it’s time to move off those database platforms. Even if you’re not required to upgrade from a GRC perspective, there’s a lot of functionality in the newer versions of SQL Server you can leverage for the benefit of your organisation. Microsoft has provided tools and guidance for upgrading. One example is the Data Migration Assistant. Microsoft has also provided additional documented guidance in SQL Docs to cover your migration scenario. If you can’t upgrade, but you require support, there are two paths you must choose from. The more costly option is to enter the Extended Support Upgrade program. The other path is to deploy to SQL Server 2008 instances in Microsoft Azure, as these will remain under support until 2022.
The post The End of SQL Server 2008 and 2008 R2 Extended Support appeared first on Simple Talk.
from Simple Talk http://bit.ly/2L9a60H
via