It is easy to attach details and documentation to a SQL Server database using extended properties. In fact, you can add a number of items of information to any database objects such as tables, views, procedures or users. If you use JSON to store the information, then you can, in addition, even monitor trends by storing previous information as a back history of changes. This could include such information as the date of changes, or variables such as the size of the database or table at a particular date, with the object.
I’ll use as an example the applying of version numbers to a database. We’ll end up storing old version numbers and the date when they were applied. We’d want to do this to build up a history of when changes were made to a database. This allows us to find out various items of information as well as the current version: We can, for example, find out when, and how long, a database was at a version number.
Storing a version number for a database in JSON.
Let’s take things in easy steps.
Without a history
Imagine that you have a database called ‘AdventureWorks’ that you need to document. You might have several different facts that you need to store: a description maybe, more likely a version number. There are likely to be other facts you need to document. You might decide to store it a JSON so that you can access just part of the data.
DECLARE @DatabaseInfo NVARCHAR(3750)
SELECT @DatabaseInfo =
(
SELECT 'AdventureWorks' AS "Name", '2.45.7' AS "Version",
'The AdventureWorks Database supports a fictitious, multinational manufacturing company called Adventure Works Cycles.' AS "Description",
GetDate() AS "Modified",
SUser_Name() AS "by"
FOR JSON PATH
);
IF not EXISTS
(SELECT name, value FROM fn_listextendedproperty(
N'Database_Info',default, default, default, default, default, default) )
EXEC sys.sp_addextendedproperty @name=N'Database_Info', @value=@DatabaseInfo
ELSE
EXEC sys.sp_Updateextendedproperty @name=N'Database_Info', @value=@DatabaseInfo
You can now view this in SSMS, of course
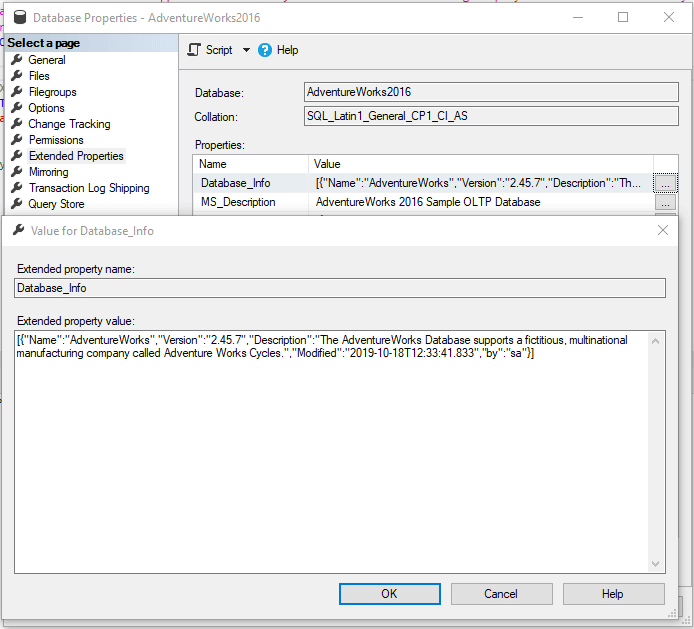
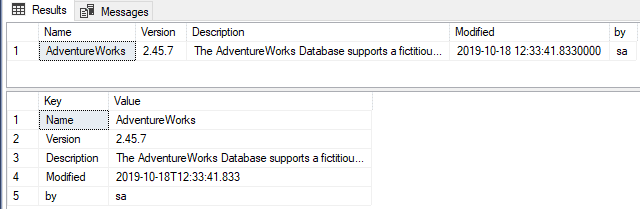
You can access it in SQL via various different techniques depending on your preferences.
You can just access the current version information, or any other value, using JSON_VALUE()
SELECT Json_Value((SELECT Convert(NVARCHAR(3760), value)
FROM sys.extended_properties AS EP
WHERE major_id = 0 AND minor_id = 0
AND name = 'Database_Info'),'$.Version') AS Version
You can get the data as a result in various forms, including a single row or one row per key. Let’s first get the JSON value from the extended property …
DECLARE @DatabaseInfo NVARCHAR(3750); SELECT @DatabaseInfo = Convert(NVARCHAR(3760), value) FROM sys.extended_properties AS EP WHERE major_id = 0 AND minor_id = 0 AND name = 'Database_Info';
.. then you can get the data as a result with a single row …
SELECT * FROM OpenJson(@DatabaseInfo) WITH (Name sysname, Version NVARCHAR(30), Description NVARCHAR(3000), Modified DATETIME2, [by] NVARCHAR(30) );
…or you can get the result with one row per key.
SELECT TheProperties.[Key], TheProperties.Value
FROM OpenJson(@DatabaseInfo) AS TheJson
OUTER APPLY OpenJson(TheJson.Value) AS TheProperties;
This data isn’t entirely secure. You need CONTROL or ALTER permissions on the object to alter it, but it can be accessed by anyone who has VIEW DEFINITION permission. We can demonstrate this now by creating a ‘headless’ user without a login and assigning just that permission. You can try this out with various permissions to see what works!
USE AdventureWorks2016; -- create a user CREATE USER EricBloodaxe WITHOUT LOGIN; GRANT VIEW DEFINITION ON DATABASE::"AdventureWorks2016" TO EricBloodaxe; EXECUTE AS USER = 'EricBloodaxe'; PRINT CURRENT_USER; SELECT Convert(NVARCHAR(3760), value) FROM sys.extended_properties AS EP WHERE major_id = 0 AND minor_id = 0 AND name = 'Database_Info'; REVERT; DROP USER EricBloodaxe; PRINT CURRENT_USER;
Storing a history as well
At this point, you probably decide that you really want more than this. What you really need is to be able to keep track of versions and when they happened, something like this ….
{
"Name":"MyCDCollection",
"Version":"3.4.05",
"Description":"Every book on databases for developers used to include one as an example",
"Modified":"2019-10-21T11:44:53.810",
"by":"EricBloodaxe",
"History":[
{
"Modified":"2019-10-21T11:44:03.703",
"by":"dbo",
"Version":"3.4.00"
},
{
"Modified":"2019-10-21T11:44:13.717",
"by":"GenghisKahn",
"Version":"3.4.01"
},
{
"Modified":"2019-10-21T11:44:23.733",
"by":"AtillaTheHun",
"Version":"3.4.02"
},
{
"Modified":"2019-10-21T11:44:33.763",
"by":"VladTheImpaler",
"Version":"3.4.03"
},
{
"Modified":"2019-10-21T11:44:43.790",
"by":"KaiserBull",
"Version":"3.4.04"
}
]
}
(Taken from one of the test-harnesses. You’ll notice that we are doing very rapid CI!). Here, we have a database that we are continually updating but we have kept a record of our old versions, when they happened and who did the alterations.
We can access the history like this
SELECT * FROM OpenJson(
(SELECT Json_Query((SELECT Convert(NVARCHAR(3760), value)
FROM sys.extended_properties AS EP
WHERE major_id = 0 AND minor_id = 0
AND name = 'Database_Info'),'strict $.History')))
WITH (WhenModified DATETIME2 '$.Modified',
WhoDidIt sysname '$.by',
[Version] NVARCHAR(30) '$.Version' )
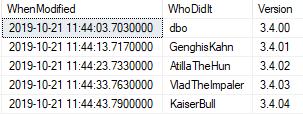
..but it would be better to add in the current version like this
DECLARE @Info nvarchar(3760)=(SELECT Convert(NVARCHAR(3760), value)
FROM sys.extended_properties AS EP
WHERE major_id = 0 AND minor_id = 0
AND name = 'Database_Info')
SELECT * FROM OpenJson(
(SELECT Json_Query(@Info,'strict $.History')))
WITH (WhenModified DATETIME2 '$.Modified',
WhoDidIt sysname '$.by',
[Version] NVARCHAR(30) '$.Version' )
UNION ALL
SELECT Json_Value(@Info,'strict $.Modified'),
Json_Value(@Info,'strict $.by'),
Json_Value(@Info,'strict $.Version')
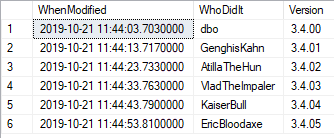
We maintain the current record where it is easy to get to and simply add an array to hold the history information. Our only headache is that we can only hold an NVARCHAR of 3750 characters (7500 of varchar characters) because extended properties are held as SQL_Variants. They need careful handling! This means that if our JSON data is larger, we have to trim off array elements that make the JSON exceed that number.
There is an error in the JSON_MODIFY() function that means that it doesn’t actually delete an array element, but merely assigns it to NULL. This can only be rectified by removing the NULL because one generally removes the oldest members of an array that you just append to by deleting element[0]. If it is NULL it still exists. Doh!
Once we have this up and running, there is a way of storing all sorts of ring-buffer information for reporting purposes that is in sorted order. Yes, you’re right, you now have a way of estimating database or table growth and performing a host of other monitoring tasks.
Because the code is rather more complicated, we’ll use a stored procedure. I’m making this a temporary procedure because I like to keep ‘utility’ code away from database code.
CREATE OR ALTER PROCEDURE #ApplyVersionNumberToDatabase
@Version NVARCHAR(30) = '2.45.7',
@Name sysname = 'AdventureWorks', --only needed the first time around
@Description NVARCHAR(3000) = --only needed the first time around
'The AdventureWorks Database supports a fictitious, multinational
manufacturing company called Adventure Works Cycles.'
as
DECLARE
@CurrentContents NVARCHAR(4000);
--get the current values if any
SELECT @CurrentContents = Convert(NVARCHAR(3750), value)
FROM fn_listextendedproperty(
N'Database_Info', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT
);
--if there is nothing there yet ...
IF @CurrentContents IS NULL
BEGIN --just simply write it in
DECLARE @DatabaseInfo NVARCHAR(3750);
SELECT @DatabaseInfo =
N'{"Name":"' + String_Escape(@Name, 'json') + N'","Version":"'
+ String_Escape(@Version, 'json') + N'","Description":"'
+ String_Escape(@Description, 'json') + +N'","Modified":"'
+ Convert(NVARCHAR(28), GetDate(), 126) + N'","by":"'
+ String_Escape(current_user, 'json') + N'","History":[]}'; -- empty history array
EXEC sys.sp_addextendedproperty @name = N'Database_Info',
@value = @DatabaseInfo;
END;
ELSE
BEGIN --place the current values in the history array
-- SQL Prompt formatting off
SELECT @CurrentContents=
Json_Modify(@CurrentContents, 'append $.History',Json_query(
'{"Modified":"'
+Json_Value(@CurrentContents,'strict $.Modified')
+'","by":"'
+Json_Value(@CurrentContents,'strict $.by')
+'","Version":"'
+Json_Value(@CurrentContents,'strict $.Version')
+'"}'))
--now just overwrite the current values
SELECT @CurrentContents=Json_Modify(@CurrentContents, 'strict $.Version',@version)
SELECT @CurrentContents=Json_Modify(@CurrentContents, 'strict $.Modified',
Convert(NVARCHAR(28), GetDate(), 126))
SELECT @CurrentContents=Json_Modify(@CurrentContents, 'strict $.by',current_user)
-- SQL Prompt formatting on
--if the json won't fit the space (unlikely) then take out the oldest records
DECLARE @bug INT = 10; --limit every loop to a sane value just in case...
WHILE Len(@CurrentContents) > 3750 AND @bug > 0
BEGIN
SELECT @CurrentContents =
Json_Modify(@CurrentContents, 'strict $.History[1]', NULL),
@bug = @bug - 1;
--SQL Server JSON can't delete array elements, it just replaces them
--with a null, so we have to remove them manually.
SELECT @CurrentContents=Replace(@CurrentContents,'null,' COLLATE DATABASE_DEFAULT,'')
END;
EXEC sys.sp_updateextendedproperty @name = N'Database_Info',
@value = @CurrentContents;
PRINT 'updated';
END;
The way that this works is that you only need to put in the name of the database and the description first time around, or after you’ve deleted it.
Here is how you delete it.
EXEC sys.sp_dropextendedproperty @name = N'Database_Info';
The following code be necessary the first time around, especially if you’ve used different defaults for your temporary stored procedure.
EXECUTE #ApplyVersionNumberToDatabase @Version='3.4.00',@Name='MyCDCollection', @Description='Every book on databases for developers used to include one as an example'
From then on, it is just a matter of providing the version number
EXECUTE #ApplyVersionNumberToDatabase @Version='3.5.02'
Testing it out
Here is one of the test routines that I used for the stored procedure, but without the checks on the version number, as that would be repetition.
EXEC sys.sp_dropextendedproperty @name = N'Database_Info'; EXECUTE #ApplyVersionNumberToDatabase @Version='3.4.00' WAITFOR DELAY '00:00:10' CREATE USER GenghisKahn WITHOUT LOGIN GRANT alter ON database::"AdventureWorks2016" TO GenghisKahn EXECUTE AS USER = 'GenghisKahn' EXECUTE #ApplyVersionNumberToDatabase @Version='3.4.01' REVERT DROP USER GenghisKahn WAITFOR DELAY '00:00:10' -- create a user CREATE USER AtillaTheHun WITHOUT LOGIN GRANT alter ON database::"AdventureWorks2016" TO AtillaTheHun EXECUTE AS USER = 'AtillaTheHun' EXECUTE #ApplyVersionNumberToDatabase @Version='3.4.02' REVERT DROP USER AtillaTheHun WAITFOR DELAY '00:00:10' -- create a user CREATE USER VladTheImpaler WITHOUT LOGIN GRANT alter ON database::"AdventureWorks2016" TO VladTheImpaler EXECUTE AS USER = 'VladTheImpaler' EXECUTE #ApplyVersionNumberToDatabase @Version='3.4.03' REVERT DROP USER VladTheImpaler WAITFOR DELAY '00:00:10' -- create a user CREATE USER KaiserBull WITHOUT LOGIN GRANT alter ON database::"AdventureWorks2016" TO KaiserBull EXECUTE AS USER = 'KaiserBull' EXECUTE #ApplyVersionNumberToDatabase @Version='3.4.04' REVERT DROP USER KaiserBull WAITFOR DELAY '00:00:10' -- create a user CREATE USER EricBloodaxe WITHOUT LOGIN GRANT alter ON database::"AdventureWorks2016" TO EricBloodaxe EXECUTE AS USER = 'EricBloodaxe' EXECUTE #ApplyVersionNumberToDatabase @Version='3.4.05' REVERT DROP USER EricBloodaxe
Conclusion
Extended properties are useful for development work but wonderful for reporting on a database or monitoring a trend. If you use JSON to store the data, they can act as miniature tables, or more correctly ring buffers. They have a variety of uses and are easy to create and remove without making any changes to the database whatsoever. This is because Extended properties and their values are either ignored as changes by humans and deployment/comparison tools, or you can easily configure them to be ignored: They do not affect the version)
The post Associating Data Directly with SQL Server Database Objects. appeared first on Simple Talk.
from Simple Talk https://ift.tt/34mhnkn
via