The series so far:
- Introduction to DevOps: The Evolving World of Application Delivery
- Introduction to DevOps: The Application Delivery Pipeline
- Introduction to DevOps: DevOps and the Database
- Introduction to DevOps: Security, Privacy, and Compliance
- Introduction to DevOps: Database Delivery
In the third article in this series, I discussed many of the considerations to take into account if planning to incorporate databases into your DevOps delivery pipeline. An issue I did not discuss, but is perhaps one of the most important decisions you’ll need to make, is whether to take a state-based approach or migration-based approach to deploying database updates. Both strategies offer advantages and disadvantages, and it is only by understanding how each one works and the differences between them can you make an informed decision about the best approach for your organization.
Database Updates in a DevOps Environment
Incorporating databases into the DevOps delivery pipeline has never been a simple process, nor is it one that comes naturally to most organizations, yet DevOps can offer a number of important benefits to database delivery, as long as the database team has the time and resources necessary to properly transition to the new methodologies.
Even under ideal circumstances, however, the team must still contend with a fundamental truth: A database is much different animal from an application. With applications, you don’t have to persist data, making it a lot easier to update and deploy them. It’s not so painless with databases. You can’t simply drop and replace one with a new version. You must apply your updates in a way that takes into account all the data that goes with it and what is required to preserve that data, regardless of how the database might change.
Even a relatively simple update, such as modifying a column’s data type, can result in lost or truncated data if the change is not properly handled. When it comes time to update the column definition, you’ll need to include additional logic in your scripts to ensure that the data is protected and prepared for the transformation.
When updating a database, many teams employ one of two strategies: state-based or migration-based. A state-based approach focuses on how the database should look, and a migration-based approach focuses on how the database should change. In other words, in a state-based approach, each database object is versioned as a “create” script, providing a single step between the current database state and the desired database state. Whereas in a migration-based approach, you have versions of the individual “alter” that support larger, iterative database migrations.
Although some tools may offer a hybrid experience, a team generally needs to choose one or the other. Not only does this make it easier to collaborate on a single code base, but it can also help avoid some of the complexities that come with employing both at the same time. With either approach, however, the goal is the same: to establish one source of truth for your database deployments.
State-Based Database Delivery
In the state-based approach, each developer works in dedicated non-production databases. Version control enables collaboration for multiple developers and establishes a single source of truth, while also offering the flexibility of branching. In this case, your database definition language (DDL) scripts serve as that source of truth. The scripts include definitions for every database object, including tables, views, stored procedures, functions, triggers, and any other components required to build the complete database.
The scripts are stored in a source control repository, where they’re protected and managed just like the application code. Source control ensures that developers and administrators have a complete and trusted snapshot of the database whenever its needed. Source control also makes it easier to resolve script issues if database developers check in conflicting code.
The development database serves as your foundation for migrating the target database, either by replacing it or by updating it in place to match the development database, taking whatever steps necessary to preserve the data.
To update the target database in place, you need a tool that compares the development database to the target database, or more precisely, compares the DDL scripts on which the databases are built. From this comparison, the tool generates a deployment script for applying the updates to the target database. You can then execute the script against the target database so it matches the development database, as shown in Figure 1.
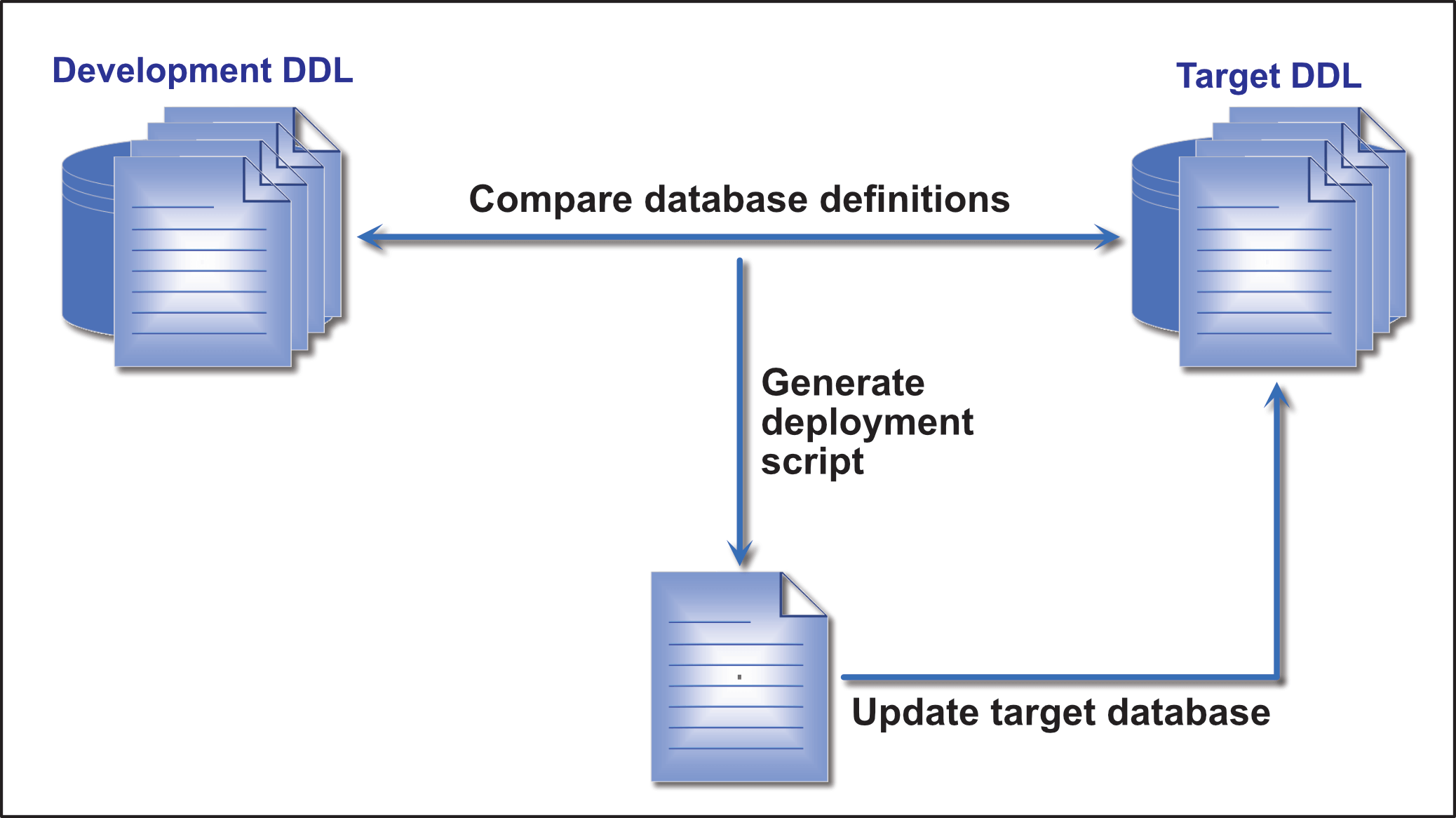
Figure 1. State-based database delivery
Before running the deployment script, you should have in place a process for testing and reviewing the script’s code to ensure that running it will not result in unintended consequences. Successful teams usually run multiple non-production environments—such as QA, User Acceptance, and Staging—to validate that deploying the database results in the desired changes and does not cause defects or performance problems..
After you run the script, the data structures in both databases should be identical. This will change, if course, when the next round of development starts. At this point, however, the two databases are at the same state, or version.
Several database management tools take a state-based approach to database updating or take a hybrid approach that incorporates state-based functionality. Redgate’s SQL Source Control, a SQL Server Management Studio plug-in, is one example of a hybrid solution that incorporates state-based functionality. SQL Source Control stores the current state of each database object in source control, providing the single source of truth for database development. SQL Source Control leverages the SQL Compare engine to compare the development database to the target database and, from this comparison, generates the deployment script necessary to update the target database. Microsoft’s SQL Server Data Tools in Visual Studio is another hybrid solution that incorporates state-based features.
A state-based approach to database delivery can offer the DevOps teams a number of benefits. The current database is always in source control and available to anyone who needs to build the database, either from scratch or to provide a baseline for upgrading the target database. This approach also makes it easier to find and respond to conflicts, as well as audit change histories. In addition, the state-based approach can make database deployments quicker and easier, while enabling multiple developers to work on the same database.
Despite these benefits, state-based methodologies also come with a significant limitation. The deployment scripts are unable to understand the data context of a database change, which can be particularly problematic when it comes to table refactoring. Although the comparison process will detect changes to table definitions, it does not know how to properly handle the data. For example, if you change the name of a table in the development database, the deployment script will create a new table and delete the old one, but it’s unable to make reliable assumptions about what to do with the data during the transition.
Because these types of issues can occur, DBAs must carefully test and review the deployment scripts and create additional scripts—with manually or automatically—to ensure all the data is properly preserved during the upgrading process. Unfortunately, this can add to the complexity of the overall operations and undermine some of the benefits of the DevOps process.
Migration-Based Database Delivery
Migration-based methodologies for upgrading databases take a much different approach than state-based by focusing on how a database should change, rather than how the final product should look. Instead of starting with an ideal state and bringing the target database up to that state, you start with the initial seed database (the base database) and then create a series of migration scripts that apply changes to the database in a specified sequence until the database reaches the desired state, or designated version. In this sense, the initial DDL scripts used to create the seed database, along with the applicable migration scripts, become the one source of truth for deploying that particular version.
Migration scripts might update table definitions, transform data, modify lookup values, add stored procedures, or carry out any number of other operations. Figure 2 provides a simplified overview of this process, with the seed database represented as “state 1.”
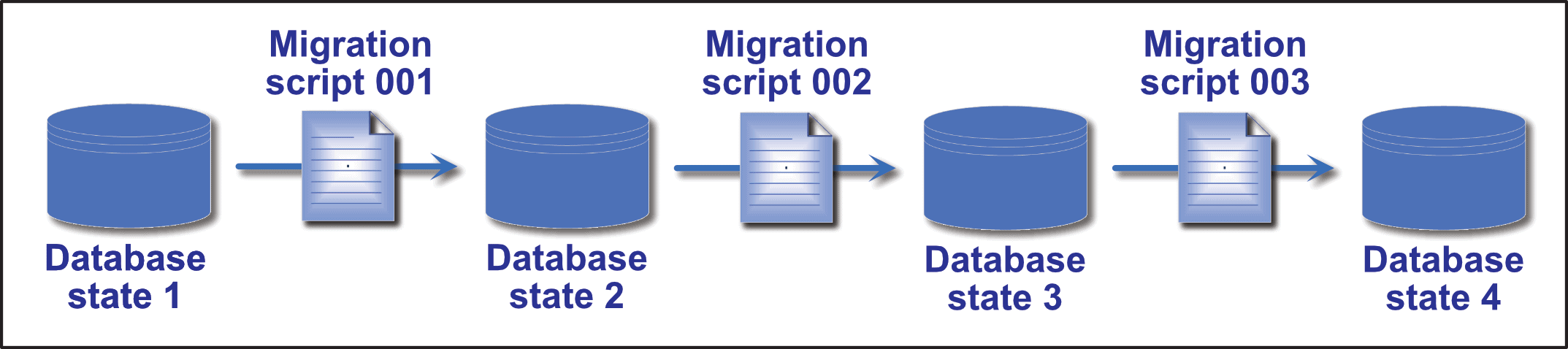
Figure 2. Migration-based database delivery
To better understand how migration-based delivery works, consider the example of replacing a phone number column with two columns, one for the area code and the other for the main number. The first migration script (001) is applied to the database to bring it up to state 2. The script adds the two columns to the table. The second migration (002) brings the database to state 3. The script retrieves the data from the original column, transforms the data, and inserts it into the two new columns. The third migration script (003) removes the original phone number column, bringing the database to state 4.
If the migration scripts are not applied in the correct order, errors can occur and data can be lost. For instance, if you run migration script 003 before the others, the column will be deleted before the new columns are created and the data transformed and inserted.
Of course, most of your scripting will be far more complex than the example shown here, with several operations rolled into a single script. Even so, the principles remain the same. Dependencies exist between scripts and running them according to their defined sequence is essential.
For this reason, an effective migration-based strategy necessitates that all migration scripts be carefully written, reviewed, tested, applied, and managed. This requires well-defined procedures that are used consistently throughout the database development and delivery cycles. Developers and administrators should be able to build a specific database version at any time by creating the initial seed database (or using the same version of an existing database) and then applying the migration scripts in the correct order.
Every database change must be reflected in the migration scripts. As a result, the number of scripts can get quite large, leading to more complex script management and their application. It can also result in unnecessary steps. For example, a table might be added in one migration script, updated in another script, and then dropped in a later script. If the scripts are changing numerous objects, this can add considerable overhead. For this reason, some database teams periodically create new seed databases that incorporate all the changes up to that point, thus providing a new baseline.
Because managing migration scripts is so important to an effective migration-based strategy, many organizations turn to management tools that can help with this process. For example, Redgate’s SQL Change Automation, which works directly with Visual Studio or SSMS, leverages the SQL Compare engine to auto-generate numerically ordered migration scripts, which can then be run sequentially to update a database from one version to the next. SQL Change Automation is a hybrid tool that also tracks the state of the database in a schema model. This enables easy branching and merging, just like in a state-based model.
One of the biggest advantages of the migration-based strategy over the state-based approach is that development teams have much more control over the update process. Developers can write scripts that define exactly how the changes should be implemented and how the data should be preserved. In this way, they can incorporate the proper data logic directly into their scripts. They know exactly what is being done and how changes are being implemented every step of the way. The migration-based approach is also conducive to DevOps delivery methodologies because deployments can be repeated across environments.
Like the state-based approach, however, the migration-based approach also comes with its own challenges. One of these is complexity. The greater the number of database objects and more frequent the changes, the greater the number of migration scripts, resulting in more complicated script management and an increased risk of conflict and misapplication.
The challenge is even greater if the development team branches the application and then tries to merge it back together. Unless the tools being used can handle these changes, the merge will likely generate conflicts, forcing developers to review all migration scripts manually on a line-by-line basis.
In addition, the larger the database and greater number of scripts, the more time it takes to deploy the database, a problem exacerbated by redundant and unnecessary operations that can occur as a result of frequent changes. For example, a table might be re-indexed multiple times for each deployment because of the progression of changes to the column structure as scripts are applied to the target database.
This doesn’t mean that migration-based methodologies are not appropriate for large databases, but it does mean that managing and reviewing the scripts can become a substantial undertaking, undermining some of the benefits that come with incorporating databases into the DevOps pipeline.
Striking a Balance
Both the state-based approach and migration-based approach can offer a number of advantages to development teams that want to incorporate databases into their DevOps processes. Unfortunately, both approaches also come with significant challenges, which can make it difficult to know the best way to proceed. To complicate matters, you’ll often run up against diehard advocates on both sides of the aisle extoling the virtues of one approach, while disparaging the suitability of the other.
The fact is, neither approach offers an ideal solution. For this reason, some vendors build features into their tools to help get around the specific limitations of either strategy, such as the hybrid tools mentioned above. I’ve already pointed to two such tools: SQL Source Control and SQL Change Automation. SQL Source Control, for example, lets you create pre- and post-deployment scripts for handling changes such as column splits, which are difficult to manage with a pure state-based strategy. And SQL Change Automation includes the Programmable Objects feature for handling “last one in wins” scenarios, which can be problematic in a migration-based approach.
In addition to picking flexible tools, database teams should also take into account the databases themselves. For instance, teams working on databases with a larger number of objects that change frequently might gravitate toward state-based methodologies because of the simplified upgrade path. That said, no one approach will likely be a perfect fit for your organization, so you’ll have to settle for the one that comes the closest to meeting your needs.
However, there’s nothing to prevent you from switching from one strategy to another at some point in the database lifecycle. For example, you might take a state-based approach early in the development process, when the database is new and rapidly changing, and then switch to a migration-based approach when the database becomes more stable.
Perhaps before too long, other viable alternatives will become available for deploying databases in a DevOps environment. Database DevOps is a dynamic field that’s finally making headway in application delivery, and this area has become ripe for innovation. Along with changing attitudes, we’ll likely see advancements in technologies and methodologies to help drive database DevOps into the future. Until then, you’ll have to make do with the tools at hand and know that whatever approach you take will require careful planning and implementation and a fair amount of patience.
The post Introduction to DevOps: Database Delivery appeared first on Simple Talk.
from Simple Talk https://ift.tt/2OWAtJ2
via
No comments:
Post a Comment