You’re working in development, releasing a new version of the application. You’ve temporarily disabled constraints in the new version of the database, you’ve imported the current data, your hand is poised to enable constraints. Is it going to spring errors at you? What if it does?
Or, what if you synchronize a source with a target by changing the metadata, only to find that the process has an error saying a constraint, index or foreign key can’t be created?
How could this happen? What has happened in both cases is that the data does not comply with the constraints. Maybe you’ve added or altered some constraints, and you have tested them on a different version of the data, changing this data slightly to satisfy the new constraints but without providing your changes as a data migration script. Perhaps you’ve only tested the new or altered constraints using an artificial data set, with no troublesome duplicates or broken references? Possibly, you are working in development and staging is done by a different team. Deployment and release are often, from necessity, done by a different team to development. You release the new database version to staging, which perhaps is managed by a different team, and when they try to update the existing database to the new build, the build breaks.
Often, at this point, one or other of the teams will need to repeatedly try releasing while fixing all the bad data, one error message at a time. This isn’t going to help team bonding; you need a better way of dealing with these problems.
In this series of articles, I’ll provide a more reliable way to be able to tease out all the duplicates, the broken foreign key references or all the values that will cause CHECK constraint errors, before you run a deployment. It will not only report where the errors would occur, but which data in which tables would cause which constraints to fail.
Dealing with Data that Breaks the Build
Sometimes a database build breaks only when you try to release it to staging or, worse, to production. Up to that point everything is sweetness and light. Then you either synchronise or try to load the data. What has happened? Well, it could be that in the new version of the databases, you’ve added DEFAULT constraints, FOREIGN KEYs or unique indexes, as you should, or modified existing keys and constraints to enforce referential integrity, and do a better job at preventing ‘bad data’ from creeping into the database.
If you are very fortunate, you will have access to the real data, so you can enable constraints one at a time and, when one causes an error, fix the data that is recorded in the error, and develop the scripts to heal the data in a pre-deployment script in order to remove the duplicates and bad data and fix the broken FOREIGN KEY references that initially inspired you to do the work.
There’s nothing wrong with that sort of data migration script, of course, although it requires a lot of careful work, gathering up all the de-duplicating statements, making them idempotent, testing them, and then using them in a pre-deployment script for a release. Even after all this, new data may have been inserted into Production, since you took the backup for testing, which might still break the build. If you are importing the existing data into a new build, then you would disable all constraints, import the data, heal it in-situ with the data-migration script and then finally enable constraints.
What, though, if you can’t access the production data, for several good reasons? In this case, you’re most likely testing with an artificially generated set of data for testing or a masked copy of the production data. However, unless you are one of the wild men of IT, it isn’t the actual production data, and so doesn’t have all the real data’s failings. Now, either the Ops team will need to try to fix all the duplicates and bad data, until the build succeeds, or they will pass the baton back to you.
Unless you enjoy buying all the drinks on the Friday afternoon DevOps team meeting, you must never deliberately break the database build or release. What you need to do is to provide a way that the Ops people can check the data of the target database beforehand to make sure it will pass all the checks done by constraints and unique indexes, and that all the FOREIGN KEY references are in place. If it doesn’t, and this is the key difference, they will need a report of what data failed the new constraints, so that you can provide scripts to allow DevOps people to fix the data.
When you know what is failing, you can create the deduplication, broken FOREIGN KEY reference or data-sanitizing scripts. Then you re-test until you get a clean bill of health. Although I can’t really help with the actual de-duplication, I can, in this article, help you to generate the list of the constraints that will fail and why.
Duplicates
Duplicates are like rats: they get in unless you take active steps to stop them. Data just seems to want to reproduce itself. The grey-muzzled database developer will take elaborate steps to check for duplicates everywhere by using unique constraints, whilst the cub developers snigger amongst themselves at how impossible it would be for a duplicate to get in there anyway. The blighters always insinuate themselves wherever there are no checks against them. Duplicates, I mean, rather than cub developers. This means that every database revision seems to have more uniqueness checks, inspired by the labour of teasing duplicates out and stamping on them. If the production data has duplicates, this must be fixed before you can release new unique constraints successfully to that target database.
Constraints and Bad Data
However often I go on about CHECK constraints, there will always be a developer who will leave them out or mutter in a dignified manner about how all checks need to be done only at the application level. This attitude soon gets divine retribution. Bad data springs up like a rotting fungus over your database unless you add CHECK constraints to all your tables. This is fine but then how do you prevent the excellent and estimable habit of adding them to then interfere with a release? The constraints will stop the build if they meet bad data: it is what they are trained to do. If you don’t like that, then you must fix the bad data first.
Unreferenced Foreign Keys
These are less frequent, but I’ve seen them. What happens here is that you import your data, enable constraints, and you get a message about a foreign key reference. This happens if, for example, the name of a country that is referenced in an address list or currency table is missing. Getting data right in a referenced table can be like picking up lots of tadpoles and putting them in a jar. Unless you know what failed, this can be very tricky to fix.
Checking the CHECK Constraints: First Principles
We’ll show how to do a check. The whole point of this type of test is that it must report the breakages in enough detail that you can smilingly pass to the Ops Guy a script that will heal it.
Let’s do the very simplest check: a check of constraints. We’ll do this by assembling a batch as a string. This batch will execute every constraint in the database, on the table to which it belongs, and tot up the grand total of rows that failed a constraint.
DECLARE @AllTheFailures INT; --tally of all the
--failures in the constraints
DECLARE @CheckAllYourConstraints NVARCHAR(MAX) =
'Select @RowsFailed =0;
';
SELECT @CheckAllYourConstraints =
@CheckAllYourConstraints --accumulate each query
+ N'
Select @RowsFailed=@RowsFailed+count(*) from ' --the table spec
+ QuoteName(Object_Schema_Name(CC.parent_object_id)) + N'.'
+ QuoteName(Object_Name(CC.parent_object_id)) + N' WHERE NOT '
+ definition
FROM sys.check_constraints AS CC
WHERE is_ms_shipped = 0;
--Now we have a list of select queries that will accumulate
--the total number of rows that fail the condition
EXECUTE sp_executesql @CheckAllYourConstraints,
N'@RowsFailed int output',
@RowsFailed = @AllTheFailures OUTPUT;
SELECT @AllTheFailures;
We run this in our test copy of AdventureWorks2016. It returns no rows, because all the constraints are enabled and so the rows are already well-policed by those constraints if they are in a ‘trusted’ state.
The batch that was executed was this:
Select @RowsFailed =0; Select @RowsFailed=@RowsFailed+count(*) from [Person].[Person] WHERE NOT ([EmailPromotion]>=(0) AND [EmailPromotion]<=(2)) Select @RowsFailed=@RowsFailed+count(*) from [Sales].[SalesTaxRate] WHERE NOT ([TaxType]>=(1) AND [TaxType]<=(3)) Select @RowsFailed=@RowsFailed+count(*) from [Sales].[SalesTerritory] WHERE NOT ([SalesYTD]>=(0.00)) Select @RowsFailed=@RowsFailed+count(*) from [Sales].[SalesTerritory] WHERE NOT ([SalesLastYear]>=(0.00)) Select @RowsFailed=@RowsFailed+count(*) from [Production].[Product] WHERE NOT ([SafetyStockLevel]>(0)) Select @RowsFailed=@RowsFailed+count(*) from [Sales].[SalesTerritory] WHERE NOT ([CostYTD]>=(0.00)) …and so on.
Now we’ll mangle our copy of AdventureWorks2016. Don’t worry, since it is a clone maintained by SQL Clone, I can do what I like and refresh it when I want it back to its pristine state. We’ll disable a constraint and alter the data so that when I try to reenable it, it will fail. Dave the Dev of AdventureWorks has decided that the MaritalStatus code in the employee table needs more options than M for married or S for single. What about P for Partner? He disables the CHECK constraint, CK_Employee_MaritalStatus.
ALTER TABLE humanResources.employee NOCHECK CONSTRAINT CK_Employee_MaritalStatus
Then he makes the necessary changes.
UPDATE humanresources.employee SET maritalStatus='P' WHERE BusinessEntityID=1 UPDATE humanresources.employee SET maritalStatus='P' WHERE BusinessEntityID=7 UPDATE humanresources.employee SET maritalStatus='P' WHERE BusinessEntityID=11 UPDATE humanresources.employee SET maritalStatus='P' WHERE BusinessEntityID= 14 UPDATE humanresources.employee SET maritalStatus='P' WHERE BusinessEntityID=17 UPDATE humanresources.employee SET maritalStatus='P' WHERE BusinessEntityID=18 UPDATE humanresources.employee SET maritalStatus='P' WHERE BusinessEntityID= 19
Developer Dave is just getting ready to change the constraint and enable it when he is called into an important team discussion, and he forgets.
Now we’ll rerun the code to monitor constraints. It will tell you that seven rows failed. It doesn’t tell you which rows in which table, and for which constraint. It is nice to have, but we’d want even more for the code to be useful.
If you want to play along and you don’t have SQL Clone, that is fine. We can replace the code this way once you’re done with testing.
UPDATE humanresources.employee SET maritalStatus='S' WHERE BusinessEntityID=1 UPDATE humanresources.employee SET maritalStatus='M' WHERE BusinessEntityID=7 UPDATE humanresources.employee SET maritalStatus='S' WHERE BusinessEntityID=11 UPDATE humanresources.employee SET maritalStatus='S' WHERE BusinessEntityID= 14 UPDATE humanresources.employee SET maritalStatus='S' WHERE BusinessEntityID=17 UPDATE humanresources.employee SET maritalStatus='S' WHERE BusinessEntityID=18 UPDATE humanresources.employee SET maritalStatus='S' WHERE BusinessEntityID= 19 ALTER TABLE humanResources.employee WITH CHECK CHECK CONSTRAINT CK_Employee_MaritalStatus
We can also alter what is in a constraint in order to simulate a problem
ALTER TABLE Production.Product DROP CONSTRAINT CK_Product_ProductLine;
GO
ALTER TABLE Production.Product WITH NOCHECK
ADD CONSTRAINT CK_Product_ProductLine
--CHECK (upper([ProductLine])='R' OR upper([ProductLine])='M'
-- OR upper([ProductLine])='T' OR upper([ProductLine])='S'
-- OR [ProductLine] IS NULL);
CHECK (Upper(ProductLine) = 'A'
OR Upper(ProductLine) = 'B'
OR Upper(ProductLine) = 'C'
OR Upper(ProductLine) = 'D'
OR ProductLine IS NULL
);
This constraint is set as disabled in this code; otherwise it wouldn’t execute without an error since the existing data fails the check.
You can run the test and then check that the code has picked up the problem. Then when you are finished, you can revert the change or, in my case, revert the clone.
ALTER TABLE Production.Product DROP CONSTRAINT CK_Product_ProductLine; GO ALTER TABLE Production.Product WITH NOCHECK ADD CONSTRAINT CK_Product_ProductLine CHECK (upper([ProductLine])='R' OR upper([ProductLine])='M' OR upper([ProductLine])='T' OR upper([ProductLine])='S' OR [ProductLine] IS NULL);
Which Rows Violated which Constraints?
Now we decide what we really want. I can be sure that I want a copy of all the metadata about CHECK constraints in source control with each build, generated after the first build, so I can then test all the subsequent data sets in the deployment chain to make sure they are free from ‘breaking data’.
To store this information means a JSON document because it is text-based, and this can be more versatile. We are likely to need to test data held in a different version of the database, so we abandon the idea of using the metadata directly. I also like to know more about the data that was selected as failing the test. I would like the name of the table and the name of the constraint. I need where possible, to see a good sample of the data though this isn’t possible or necessary with CHECK constraints. We need to get more serious about the tests, even if we lose some of the elegance of the code. One other thing is necessary once we decide to make it possible to run this on other versions of the database: In the case of unique indexes and FOREIGN KEY constraints, we need to check whether all the columns and tables involved are there under the same name. With CHECK constraints, all we can realistically do is to check for the table’s existence.
Here is an example of the report we get:
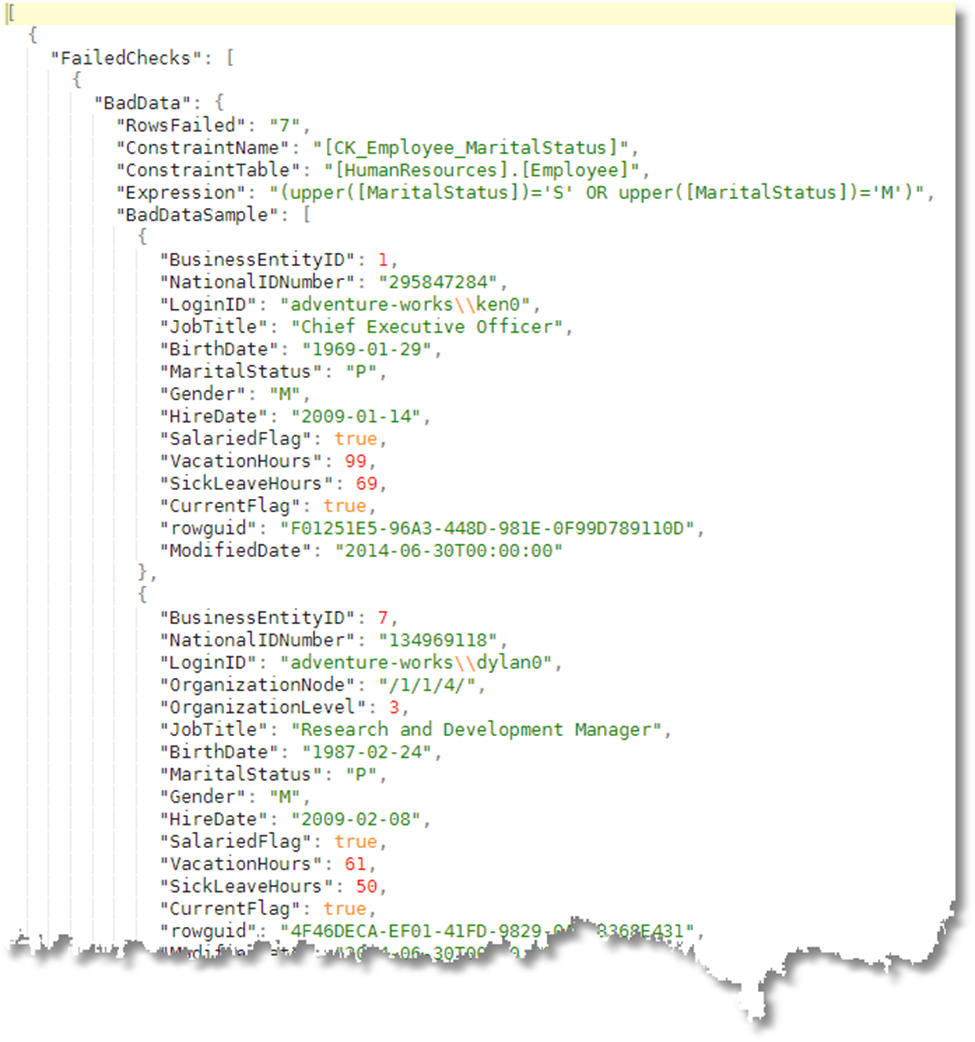
It is easy to see what is wrong in the data. That MaritalStatus column will need to be either ‘M‘ or ‘S‘ until Developer Dave fixes the constraint.
My apologies that this sort of convenience makes for more code.
DROP PROCEDURE IF EXISTS #ListAllCheckConstraints;
GO
CREATE PROCEDURE #ListAllCheckConstraints
/**
Summary: >
This creates a JSON list of all the check constraints in the database.
their name, table and definition
Author: Phil Factor
Date: 12/12/2019
Example:
- DECLARE @OurListAllCheckConstraints NVARCHAR(MAX)
EXECUTE #ListAllCheckConstraints
@TheJsonList=@OurListAllCheckConstraints OUTPUT
SELECT @OurListAllCheckConstraints AS theCheckConstraints
- DECLARE @OurCheckConstraints NVARCHAR(MAX)
EXECUTE #ListAllCheckConstraints
@TheJsonList=@OurCheckConstraints OUTPUT
SELECT Constraintname, TheTable, [definition]
FROM OPENJSON(@OurCheckConstraints) WITH
(Constraintname sysname '$.constraintname',
TheTable sysname '$.thetable',
[Definition] nvarchar(4000) '$.definition' );
Returns: >
the JSON as an output variable
**/
@TheJSONList NVARCHAR(MAX) OUTPUT
AS
SELECT @TheJSONList =
(
SELECT QuoteName(CC.name) AS constraintname,
QuoteName(Object_Schema_Name(CC.parent_object_id)) + '.'
+ QuoteName(Object_Name(CC.parent_object_id)) AS thetable,
definition
FROM sys.check_constraints AS CC
WHERE is_ms_shipped = 0
FOR JSON AUTO
);
GO
DROP PROCEDURE IF EXISTS #TestAllCheckConstraints;
GO
CREATE PROCEDURE #TestAllCheckConstraints
/**
Summary: >
This tests the current database against its check constraints.
and reports any data that would fail a check were it enabled
Author: Phil Factor
Date: 15/12/2019
Example:
- DECLARE @OurFailedConstraints NVARCHAR(MAX)
EXECUTE #TestAllCheckConstraints
@TheResult=@OurFailedConstraints OUTPUT
SELECT @OurFailedConstraints AS theFailedCheckConstraints
Returns: >
the JSON as an output variable
**/
@JsonConstraintList NVARCHAR(MAX)=null,--you can either provide
--a json document or you can go and get the current
@TheResult NVARCHAR(MAX) OUTPUT --the JSON document that gives
--the test result.
as
IF @JsonConstraintList IS NULL
EXECUTE #ListAllCheckConstraints
@TheJSONList = @JsonConstraintList OUTPUT;
DECLARE @Errors TABLE (Description NVARCHAR(MAX));--to temporarily
--hold errors
DECLARE @Breakers TABLE (TheObject NVARCHAR(MAX));--the rows that
--would fail
DECLARE @TheConstraints TABLE --the list of check constraints
--in the database
(
TheOrder INT IDENTITY PRIMARY KEY, --needed to iterate
--through the table
ConstraintName sysname, --the number of columns used in the index
TheTable sysname, --the quoted name of the table wqith the schema
Definition NVARCHAR(4000) --the actual code of the constraint
);
--we put the constraint data we need into a table variable
INSERT INTO @TheConstraints (ConstraintName, TheTable, Definition)
SELECT Constraintname, TheTable, Definition
FROM OpenJson(@JsonConstraintList)
WITH --get the relational table from the JSON
(
Constraintname sysname '$.constraintname',
TheTable sysname '$.thetable',
Definition NVARCHAR(4000) '$.definition' --the mapping
);
DECLARE @iiMax INT = @@RowCount;
--to do the actual check
DECLARE @CheckConstraintExecString NVARCHAR(4000);
--make sure the table is there
DECLARE @TestForTableExistenceString NVARCHAR(4000);
--to get a sample of broken rows
DECLARE @GetBreakerSampleExecString NVARCHAR(4000);
--temporarily hold the current constraint name
DECLARE @ConstraintName sysname;
--temporarily hold the current constraint's table
DECLARE @ConstraintTable sysname;
--temporarily hold the constraint code
DECLARE @ConstraintExpression NVARCHAR(4000);
--the number of rows that fail the current constraint
DECLARE @AllRowsFailed INT;
--a sample of failed rows
DECLARE @SampleOfFailedRows NVARCHAR(MAX);
--Did the table exist in the current database
DECLARE @ThereWasATable INT;
DECLARE @ii INT = 1;--iteration variables
WHILE (@ii <= @iiMax)
--------------------start of the loop------------------
BEGIN --create the expressions we need to execute
--dynamically for each constraint
SELECT @CheckConstraintExecString = --expression that checks
--the constraint
N'SELECT @RowsFailed=Count(*) FROM ' + TheTable + N' WHERE NOT '
+ Definition, @ConstraintName = ConstraintName,
@ConstraintTable = TheTable,
@GetBreakerSampleExecString = --expression that gets
--sample of failed rows
N'SELECT @JSONBreakerData= (Select top 3 * FROM ' + TheTable
+ N' WHERE NOT ' + Definition + N'FOR JSON AUTO)',
@ConstraintName = ConstraintName, @ConstraintTable = TheTable,
@ConstraintExpression=[definition],
@TestForTableExistenceString = --expression that checks
--for the table
N'SELECT @TableThere=case when Object_id(''' + TheTable
+ N''') is null then 0 else 1 end'
FROM @TheConstraints
WHERE TheOrder = @ii;
--check that the table is there
EXECUTE sp_executesql @TestForTableExistenceString,
N'@TableThere int output', @TableThere = @ThereWasATable OUTPUT;
IF @ThereWasATable = 1
BEGIN --it is a bit safer to check the constraint
EXECUTE sp_executesql @CheckConstraintExecString,
N'@RowsFailed int output', @RowsFailed = @AllRowsFailed OUTPUT;
IF @AllRowsFailed > 0 --Ooh, at least one failed constraint
BEGIN--so we get a sample of the bad data in JSON
EXECUTE sp_executesql @GetBreakerSampleExecString,
N'@JSONBreakerData nvarchar(max) output',
@JSONBreakerData = @SampleOfFailedRows OUTPUT;
INSERT INTO @Breakers (TheObject)
SELECT--and save the sample of bad rows along with
--information about the constraint
(
SELECT
Convert(VARCHAR(10), @AllRowsFailed) AS RowsFailed,
@ConstraintName AS ConstraintName,
@ConstraintTable AS ConstraintTable,
@ConstraintExpression AS Expression,
Json_Query(@SampleOfFailedRows) AS BadDataSample
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
);
END;
END;
ELSE INSERT INTO @Errors (Description)
SELECT 'We Couldn''t find the table '
+ @ConstraintTable;
SELECT @ii = @ii + 1; -- and iterate to the next row
END;
SELECT @TheResult= -- so we construct the JSON report.
(SELECT
(SELECT Json_Query(TheObject) AS BadData
FROM @Breakers FOR JSON AUTO) AS FailedChecks,
(SELECT Description FROM @Errors FOR JSON AUTO) AS errors
FOR JSON PATH);
go
The first job the code does, using the temporary procedure #ListAllCheckConstraints is to create, from the development database a JSON-based list of all the check constraints that you can then use for the test. The obvious place to get this information from is the new build of the database. You don’t need any database data at this point as we’re just interested in the metadata. We just want to know what to check once you’ve imported the data and before you enable constraints.
With this data, stored as a JSON document to make it portable, we can then test the data within the target database this is done by #TestAllCheckConstraints
DECLARE @OurFailedConstraints NVARCHAR(MAX)
EXECUTE #TestAllCheckConstraints
@TheResult=@OurFailedConstraints OUTPUT
SELECT @OurFailedConstraints AS theFailedCheckConstraints
You can then run all the tests on the target database automatically, using the data in this JSON document. If the table no longer exists, it will report the fact and avoid an error by bypassing the constraint check. Ideally, the check should really be in the pre-deployment script because you may decide that you want to prevent the build from going ahead if there is bad data in a column.
Here is an error where I’ve duplicated a row. This indicates that you will not be able to enable the index AK_SalesTaxRate_StateProvinceID_TaxType or AK_SalesTaxRate_rowguid without getting an error. It is telling you what duplicates will cause the error.
[{
"duplicatelist": [{
"duplicated": {
"indexName": "AK_SalesTaxRate_StateProvinceID_TaxType",
"tablename": "[Sales].[SalesTaxRate]",
"columnlist": "[StateProvinceID],[TaxType]",
"duplicates": [{
"duplicatecount": 2,
"StateProvinceID": 1,
"TaxType": 1
}]
}
}, {
"duplicated": {
"indexName": "AK_SalesTaxRate_rowguid",
"tablename": "[Sales].[SalesTaxRate]",
"columnlist": "[rowguid]",
"duplicates": [{
"duplicatecount": 2,
"rowguid": "683DE5DD-521A-47D4-A573-06A3CDB1BC5D"
}]
}
}]
}]
You will, however, be relieved that there is no ‘errors’ array in this document. Yes, it is easy to test. Why would you be relieved? This is because, if there were errors, the routine would be telling you that for one or more of the tests, either the table or one of the columns is missing. It does this check first, and if it knows that the duplicate check couldn’t even run, it doesn’t do it. You have a minor but tedious problem if you’ve changed the table columns used in these indexes as part of the release. This is because you’ll need to amend the list to allow an automated test, but this will be a relatively minor task. The script to make changes requires judgement and is not easily automated, but an existence-check for the columns is there and the information yielded should make a repair easy.
Another concern is that you may want to only test for certain constraints. As tables get much larger, it just takes too long. You only want to do them where you are putting in a new or changed constraint. Here, the answer is simple: you store the JSON document in source control and generate a new JSON document that lists just the new or altered constraints to be tested.
Summary
One aspect of DevOps teamwork involves a sort of remote running of test software. You as a developer devise the test, it is run by someone else under circumstances you can’t directly control, and you get back a report that gives you enough information to fix any problems that come up. It is curiously like the old Sybase technique of sending queries via email to be run, but without the scary surface-area exposure.
This type of test should avoid throwing errors and should collect all the information you need to script out a solution. It should not add work for the person who runs the script.
In the next article, we’ll add the routines for foreign key references and unique constraints. Armed with these, we can tie it all together to show how it fits in with a sophisticated deployment system such as SCA.
The post But the Database Worked in Development! Preventing Broken Constraints appeared first on Simple Talk.
from Simple Talk https://ift.tt/39T9l5I
via
No comments:
Post a Comment