This article explains the Azure Cache for Redis and its features, the data types supported, and the pricing tiers available. It will demonstrate the steps to create an Azure Redis Cache from the Azure Portal. The article will also explain how to create a simple console app and connect this app with cache and exchange data.
Prerequisites
To follow along with this article, you will need:
- Azure Account. You can create a free account here
- Visual Studio 2017 and above. You can download it from here
What is Caching?
Caching is a mechanism to store frequently accessed data in a data store temporarily and retrieve this data for subsequent requests instead of extracting it from the original data source. This process improves the performance and availability of an application. Reading data from the database may be slower if it needs to execute complex queries.
Azure Cache for Redis
The Azure Redis Cache is a high-performance caching service that provides in-memory data store for faster retrieval of data. It is based on the open-source implementation Redis cache. This ensures low latency and high throughput by reducing the need to perform slow I/O operations. It also provides high availability, scalability, and security.
When a user uses an application, the application tries to read data from the cache. If the requested data not available in the cache, the application gets the data from the actual data source. Then the application stores that data in the cache for subsequent requests. When the next request comes to an application, it retrieves data from the cache without going to the actual data source. This process improves the application performance because data lives in memory. Also, it increases the availability of an application in case of unavailability of the database. Figure 1 shows the cache workflow.
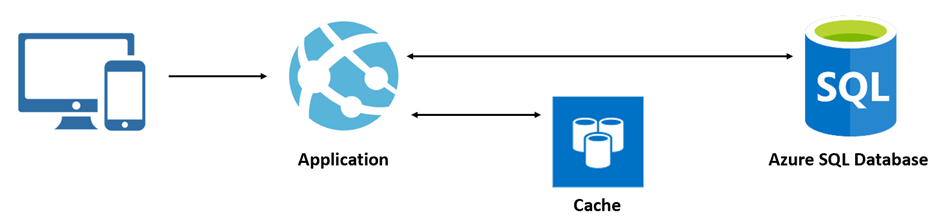
Figure 1: Cache Workflow
Features
Azure Cache for Redis has many features for management, performance, and high availability. Here are a few of the most important:
Fully Managed Service
Azure Redis Cache is a fully managed version of an open-source Redis server. i.e., it monitors, manages, hosting, and secure the service by default.
High Performance
Azure Redis cache enables an application to be responsive even the user load increases. It does so by leveraging the low latency, high-throughput capabilities of the Redis engine.
Geo-replication
Azure Redis cache allows replicating or syncing the cache in multiple regions in the world. One cache is primary, and other caches act as secondaries. The primary cache has read and write capabilities, but the secondary caches are read-only. If the primary goes down, then one secondary cache becomes primary. The significant advantage of this is high availability and reliability.
Cache Cluster
The cluster automatically shards the data in the cache across multiple Azure Cache for Redis nodes. A cluster increases performance and availability. Each shard node is made of two instances. When one instance goes down, the application still works because other instances in the cluster are running.
Data Persistence
Azure Redis cache persists the data by taking snapshots and backing up the data.
Data Types
Azure Redis Cache supports to store data in various formats. It supports data structures like Strings, Lists, Sets, and Hashes.
- Strings: Redis strings are binary safe and allow them to store any type of data with serialization. The maximum allowed string length is 512MB. It provides some useful commands like Incr, Desr, Append, GetRange, SetRange, and other useful commands.
- Lists: Lists are lists of Strings, sorted by insertion order. It allows adding elements at the beginning or end of the list. It supports constant time insertion and deletion of elements near the beginning or end of the list, even with many millions of inserted items.
- Sets: These are also lists of Strings. The unique feature of sets is that they don’t allow duplicate values. There are two types of sets: Ordered and Unordered Sets.
- Hashes: Hashes are objects, contains multiple fields. The object allows storing as many fields as required.
Pricing Tiers
Azure Redis Cache has three pricing layers with different features, performance, and budget.
- Basic: Basic cache is a single node cache which is ideal for development/test and non-critical workloads. There’s no SLA (Service Level Agreement is Microsoft’s commitments for uptime and connectivity). The basic tier has different options to choose from C0 to C6. The lowest option is C0, and this is in a shared infrastructure. Everything above C0 provides dedicated service, i.e., this does not share infrastructure with other customers.
- Standard: This tier offers an SLA and provides a replicated cache. The data is automatically replicated between the two nodes — ideal for production-level applications.
- Premium: The Premium tier has all the standard features and, also, it provides better performance, bigger workloads, enhanced security, and disaster recovery. Backups and Snapshots and can be created and restored in case of failures. It also offers Redis Persistence, which persists data stored inside the cache. It also provides a Redis Cluster, which automatically shares data across multiple Redis nodes. Hence this allows creating workloads of bigger memory sizes and get better performance. It also offers support for Azure Virtual Networks, which gives the ability to isolate the cache by using subnets, access control policies, and other features.
Cache Invalidation
Cache Invalidation is the process of replacing or removing the cached items. If the data in the cache is deleted or invalid, then the application gets the latest data from the database and keeps it in the cache, and subsequent requests get the latest data from the cache.
There are different ways to invalidate the cache.
- An application can remove the data in the cache
- Configure the invalidation rule while setting up the cache
- Set absolute expiration – you can set a specific time period to expire the cache
- Set sliding expiration – If the data in the cache not touched for a certain amount of time, then delete the cache
Create an Azure Cache for Redis
Sign in to the Azure portal, click on the portal menu and select Create a resource menu option as shown in Figure 2.
Figure 2: Microsoft Azure Portal Menu
In the next screen, Figure 3, type Azure Cache for Redis in the search bar and hit enter. This navigates to the Azure Cache for Redis window.

Figure 3: Microsoft Azure Marketplace
In the next screen, Figure 4, Azure Cache for Redis window, click on the Create button.

Figure 4: Azure Cache for Redis window
In the next screen, Figure 5, New Redis Cache window, fill out the unique DNS name, Subscription, Resource group, Location, Pricing tier, and all required information.
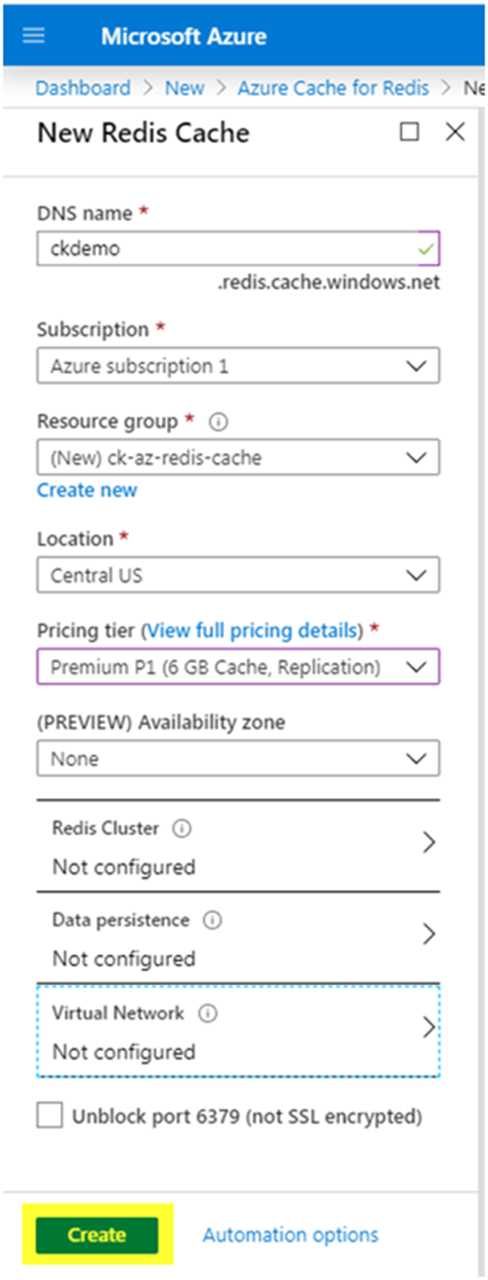
Figure 5: New Redis Cache window
Click View full pricing details. It opens a window (Figure 6) with available pricing tiers. Choosing the pricing tier is essential because this determines the performance of the cache, budget, and other features like dedicated or shared cache infrastructure, SLA, Redis cluster, data persistence, and data import and export.
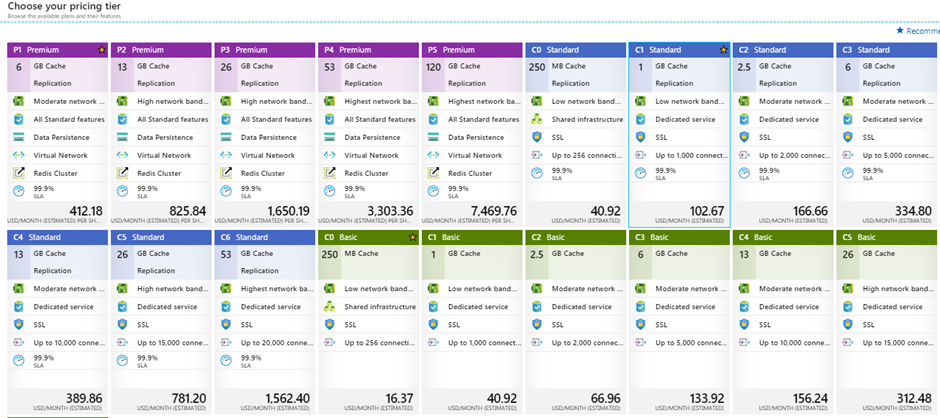
Figure 6: Pricing tier options
If you choose one of the Premium tiers, you can configure the cluster by clicking Redis Cluster (Figure 7). You can enable or disable clustering and select the shard count. Note that each shard is comprised of two instances.
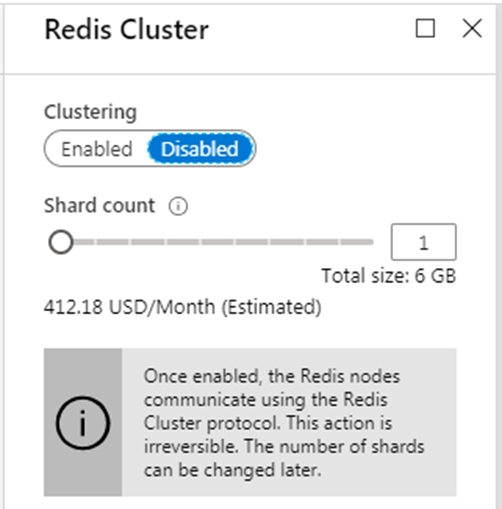
Figure 7: Redis Cluster Configuration
Data Persistence also requires the Premium tier. Figure 8 shows the configuration to persist the data stored in the cache. There are a couple of options to persist the data.
RDB (Redis database) persistence: This option persists the data by taking a snapshot of the cache. The snapshot is taken based on the frequency configured. In the case of recovery, the most recent snapshot will be used.
AOF (Append only file) persistence: This option saves the data for every writes operation. In case of recovery, the cache is reconstruct using stored write operation.
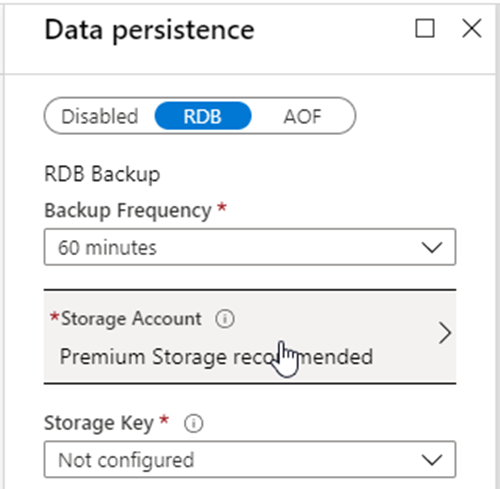
Figure 8: Data Persistence configuration
After filling out the required fields on the New Redis Cache window, click on the Create button. After a few minutes, the Azure Redis cache created and running.
Figure 9 shows the Azure Cache for Redis Overview. By default, it is secure because the Non-SSL port is disabled.
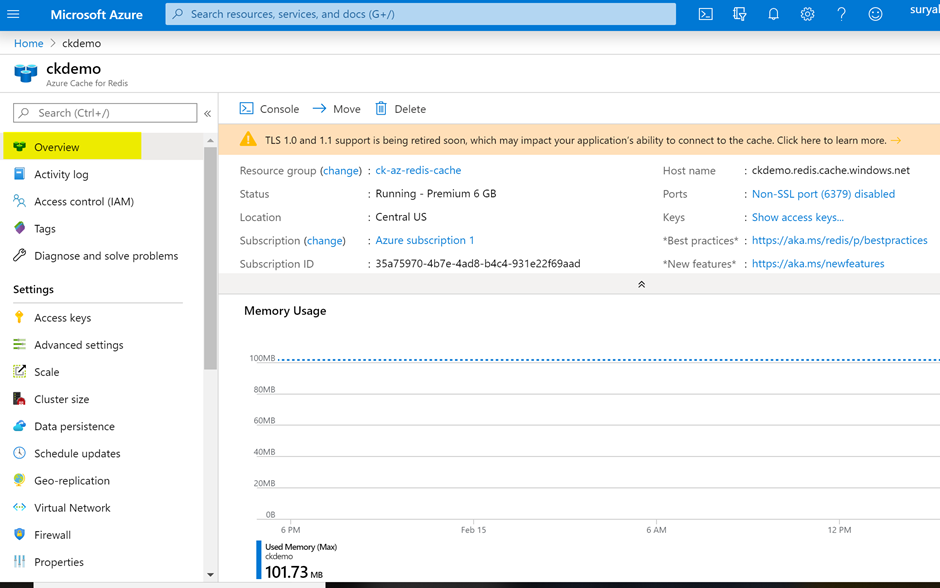
Figure 9: Overview of Azure Redis Cache
Create a Console App to Use the Cache
To try out the cache, you will create a Console app. Begin by opening Visual Studio and selecting File New Project.
The next screen, Figure 10, is the New Project window. Select the Console App (.Net Framework), fill out the project name and location, and click on the OK button.
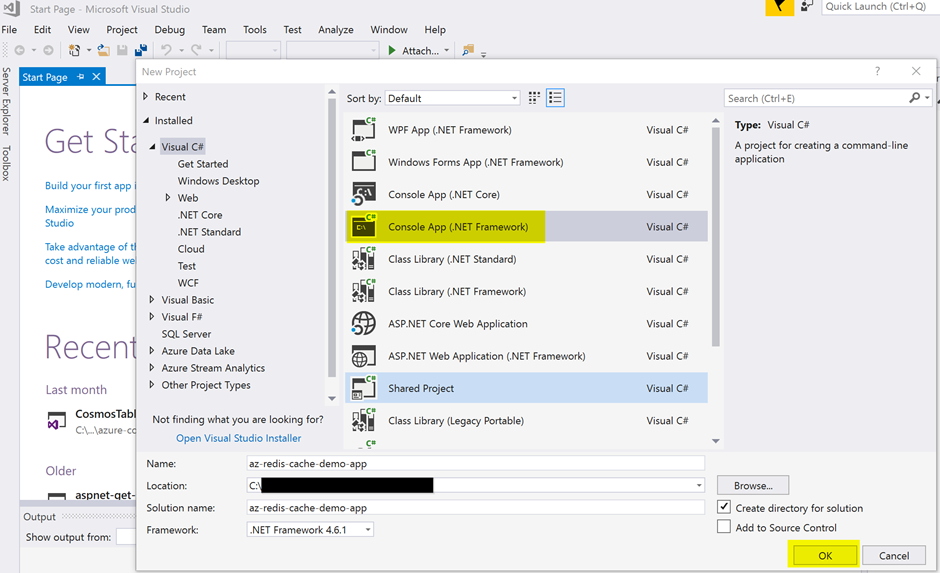
Figure 10: Visual Studio New Project
The next screen, Figure 11, shows the new console app.
Figure 11: Visual Studio Console App
To connect the Console App to the Azure Redis Cache, you need to install Microsoft.Extensions.Caching.Redis package. To install this package from Visual Studio, go to Tools NuGet Package Manager Manage NuGet Packages for solution…
Figure 12 is the NuGet Package Manager. Make sure that Browse is selected. In the search bar type Microsoft.Extensions.Caching.Redis and select the package from the displayed list. Scroll down and click on the Install button.
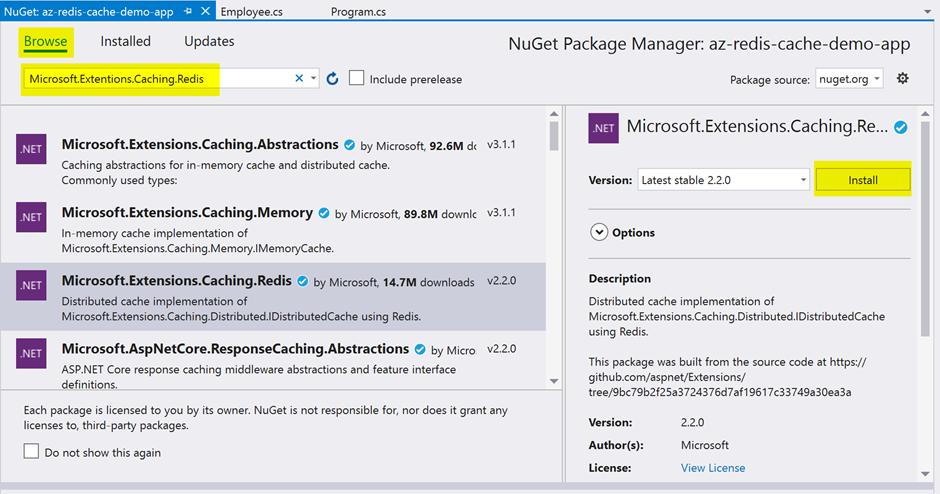
Figure 12: NuGet Package Manager
In the next screen, Figure 13, install Newtonsoft.Json package for serialization and deserialization of objects.
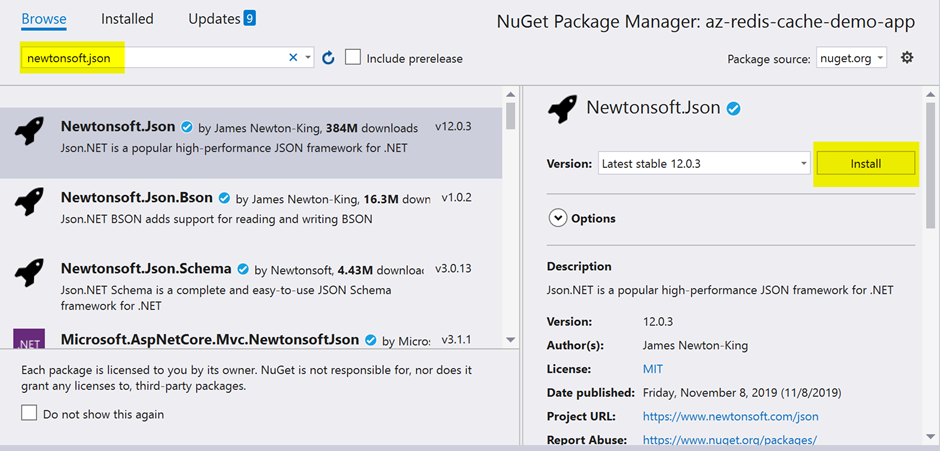
Figure 13: Install Newtonsoft.Json package
The console app can be connected to the Azure Redis Cache programmatically by using the Access keys of the Azure Redis Cache created in the Azure portal. In the next screen, Figure 14, go to the Azure Portal Redis Cache and click on the Access Keys tab and copy the Primary connection string.
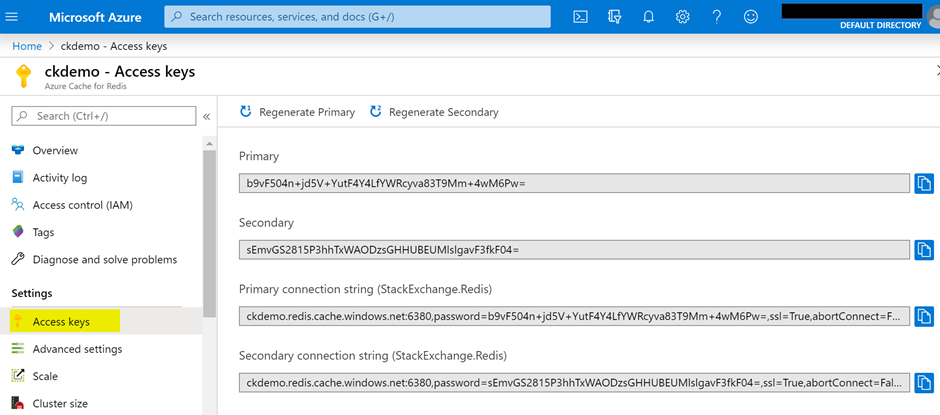
Figure 14: Access Keys from Azure Portal
Figure 15 shows the code after adding Redis cache connection string that you copied from the Azure portal to App.config file in the console app.
<appSettings>
<add key="CacheConnection"
value="<YOUR CONNECTION STRING>"/>
</appSettings>
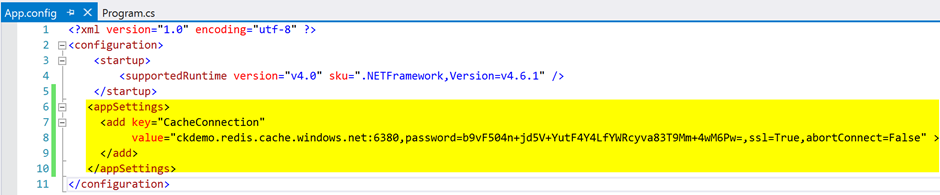
Figure 15: Configure Redis cache connection string in app.config
In real-world scenario applications, this connection string or credentials should be stored and accessed more securely.
In the next screen, Figure 16, get the Redis connection string defined in the app.config file in the program.cs file by using the ConfiguationManager class. Add the code to the Program class. The ConnectionMultiplexer class manages the connection with Azure Redis cache. Be sure to include references to System.Configuration and StackExchange.Redis.
private static Lazy<ConnectionMultiplexer> redisConnection =
new Lazy<ConnectionMultiplexer>(() =>
{
string cacheConnection =
ConfigurationManager.AppSettings["CacheConnection"].ToString();
return ConnectionMultiplexer.Connect(cacheConnection);
});
public static ConnectionMultiplexer Connection
{
get
{
return redisConnection.Value;
}
}
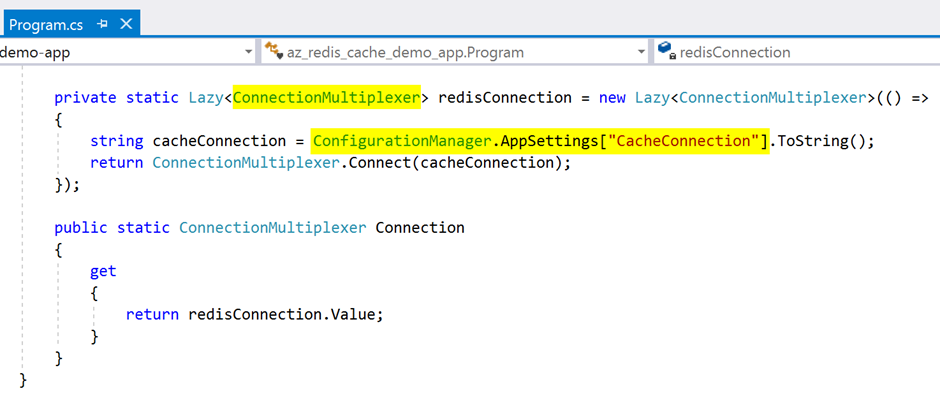
Figure 16: Managing Redis cache connection
Create a class called Employee; this acts as the data source for the console app.
The code for program.cs can be found below. First, the application gets the reference for the Redis cache database. Using that reference, the app checks whether data available in the cache. If it is available, read the data from the cache; otherwise, read the data from the actual data source and save it into the Azure Redis cache. For subsequent calls, data read from the cache.
using System;
using System.Collections.Generic;
using System.Configuration;
using StackExchange.Redis;
using Newtonsoft.Json;
namespace az_redis_cache_demo_app
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Azure Redis Cache Demo");
Console.WriteLine("----------------------");
Employee clsEmp = new Employee();
List<Employee> lstEmployees = new List<Employee>();
//Get the redis cache reference
IDatabase cache = redisConnection.Value.GetDatabase();
//Get employee data from cache
Console.WriteLine("Get employee data from Cache");
var cachedEmployees = cache.StringGet("employees");
//Check whether cache contains employee data
if(string.IsNullOrEmpty(cachedEmployees))
{
//Cache doesn't have employee data and gets the
//data from actual data source
Console.WriteLine("Employee data not available in the
cache. Get data from actual data source");
lstEmployees = clsEmp.GetEmployees();
//After getting the employee data from the actual data
//source, Save that data in cache
Console.WriteLine("Set the employee data to Cache");
cache.StringSet("employees",
JsonConvert.SerializeObject(lstEmployees));
}
else
{
//Cache contains employee data and deserializes the data
Console.WriteLine("Employee data available in the
cache. Read data from the Cache");
lstEmployees =
JsonConvert.DeserializeObject<List<Employee>>(
cachedEmployees);
}
//Print the employee data to console
foreach (var emp in lstEmployees)
{
Console.WriteLine(emp.FirstName + " " + emp.LastName
+ ", " +
emp.EmployeeId + ", " + emp.Salary + ", "
+ emp.Address);
}
Console.ReadLine();
}
private static Lazy<ConnectionMultiplexer> redisConnection
= new Lazy<ConnectionMultiplexer>(() =>
{
string cacheConnection =
ConfigurationManager.AppSettings["CacheConnection"].ToString();
return ConnectionMultiplexer.Connect(cacheConnection);
});
public static ConnectionMultiplexer Connection
{
get
{
return redisConnection.Value;
}
}
}
}
Figure 17 shows the code for the new Employee class.
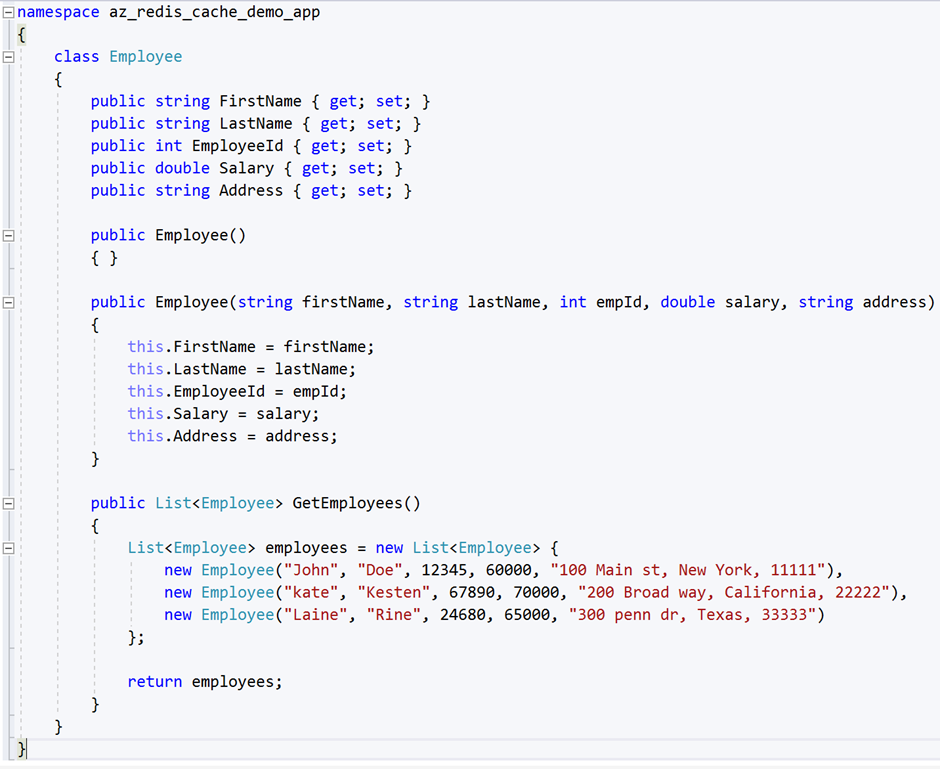
Figure 17: Employee class in the Console App
Run the application. The first time, data is not available in Redis cache, and the app gets data from the data source. See below Figure 18 for the console output.
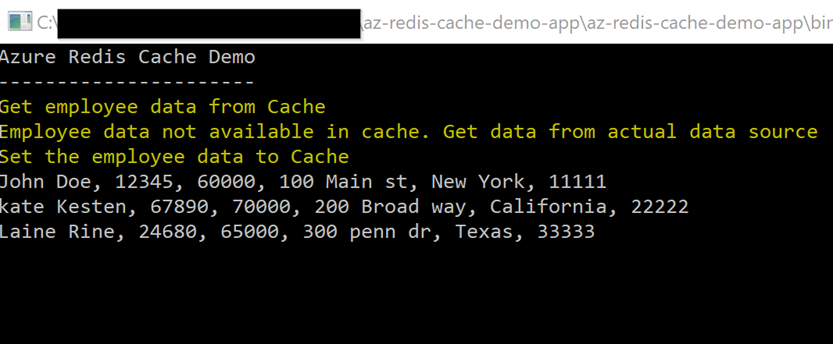
Figure 18: Console output window – first time run the application
In the next screen, Figure 19, is the result of subsequent calls. The application read the data from the Redis cache.
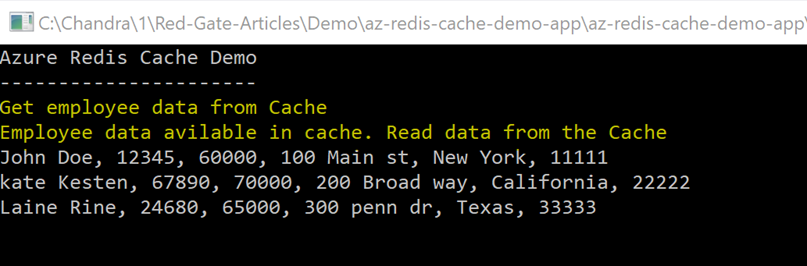
Figure 19: Console output window – Subsequent calls
You can also see the activity in the Azure Portal. Navigate to your Azure Cache for Redis and click Metrics. There you can filter the activity. In Figure 20, the metrics show that data is writing to the cache.
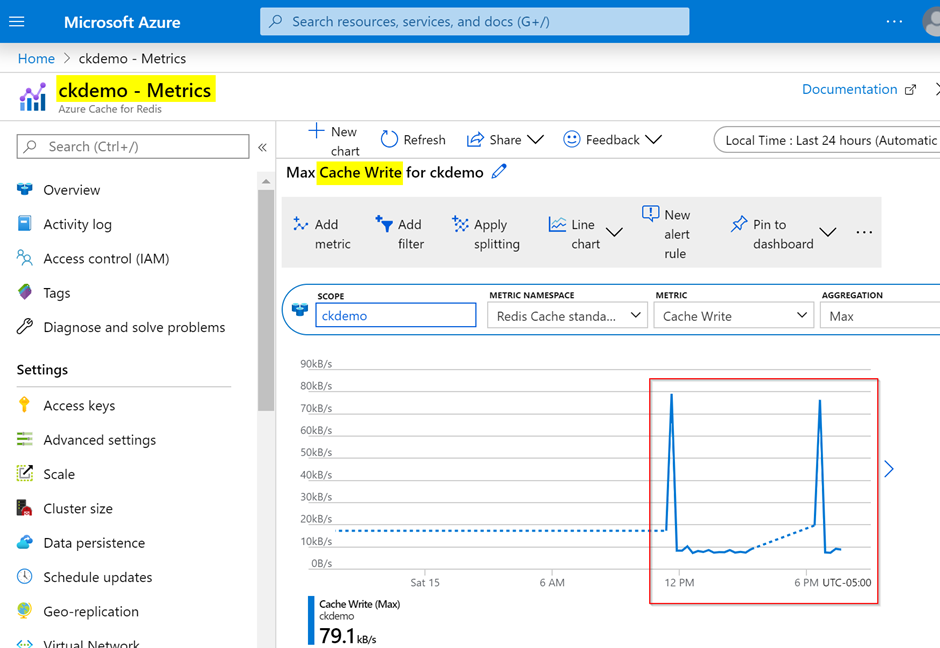
Figure 20: Redis cache write metrics from the Azure portal
In the next screen, Figure 21, Azure portal Redis cache metrics confirm that data is reading from the cache.
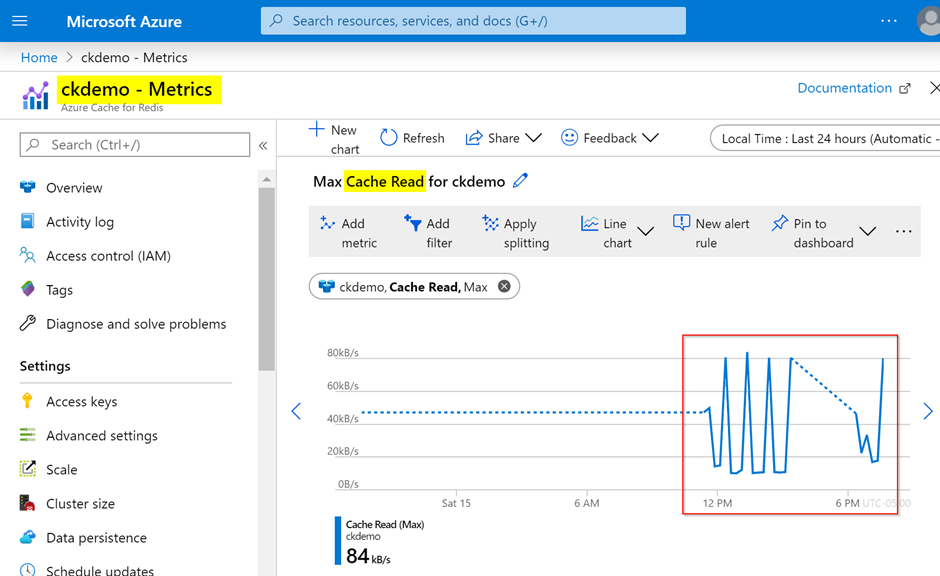
Figure 21: Redis cache read metrics from the Azure portal
Conclusion
This article explained the Azure Cache for Redis basics and demonstrated how to provision the Redis cache in the Azure Portal. It then showed how to connect it with a console app and read the data from the cache. In this way, Azure Cache for Redis allows reading data from the cache without going to the actual data source.
Reference Links
- Click here for Azure Cache for Redis documentation
- Click here for Redis open source documentation
- Click here for Azure cache features, pricing and azure portal login
The post Overview of Azure Cache for Redis appeared first on Simple Talk.
from Simple Talk https://ift.tt/397H1Ma
via