The series so far:
Heaps are not necessarily the developer’s favourite child, as they are not very performant, especially when it comes to selecting data (most people think so!). Certainly, there is something true about this opinion, but in the end, it is always the workload that decides it. In this article, I describe how a Heap works when data are selected. If you understand the process in SQL Server when reading data from a Heap, you can easily decide if a Heap is the best solution for your workload.
Advanced Scanning
As you may know, Heaps can only use Table Scans to retrieve data which are requested by the client software. In SQL Server Enterprise, the advanced scan feature allows multiple tasks to share full table scans. If the execution plan of a Transact-SQL statement requires a scan of the data pages in a table, and the Database Engine detects that the table is already being scanned for another execution plan, the Database Engine joins the second scan to the first, at the current location of the second scan. The Database Engine reads each page one time and passes the rows from each page to both execution plans. This continues until the end of the table is reached.
At that point, the first execution plan has the complete results of a scan, but the second execution plan must still retrieve the data pages that were read before it joined the in-progress scan. The scan for the second execution plan then wraps back to the first data page of the table and scans forward to where it joined the first scan. Any number of scans can be combined like this. The Database Engine will keep looping through the data pages until it has completed all the scans. This mechanism is also called “merry-go-round scanning” and demonstrates why the order of the results returned from a SELECT statement cannot be guaranteed without an ORDER BY clause.
Select data in a Heap
Since a Heap has no index structures, Microsoft SQL Server must always read the entire table. Microsoft SQL Server solves the problem with predicates with a FILTER operator (Predicate Pushdown). For all examples shown in this article, I created a table with ~ 4,000,000 data records from my demo database [CustomerOrders]. After restoring the database, run the code to create the new table, CustomerOrderList.
-- Create a BIG table with ~4.000.000 rows
SELECT C.ID AS Customer_Id,
C.Name,
A.CCode,
A.ZIP,
A.City,
A.Street,
A.[State],
CO.OrderNumber,
CO.InvoiceNumber,
CO.OrderDate,
CO.OrderStatus_Id,
CO.Employee_Id,
CO.InsertUser,
CO.InsertDate
INTO dbo.CustomerOrderList
FROM CustomerOrders.dbo.Customers AS C
INNER JOIN CustomerOrders.dbo.CustomerAddresses AS CA
ON (C.Id = CA.Customer_Id)
INNER JOIN CustomerOrders.dbo.Addresses AS A
ON (CA.Address_Id = A.Id)
INNER JOIN CustomerOrders.dbo.CustomerOrders AS CO
ON (C.Id = CO.Customer_Id)
ORDER BY
C.Id,
CO.OrderDate
OPTION (MAXDOP 1);
GO
When data is read from a Heap, a TABLE SCAN operator is used in the execution plan – regardless of the number of data records that have to be delivered to the client.
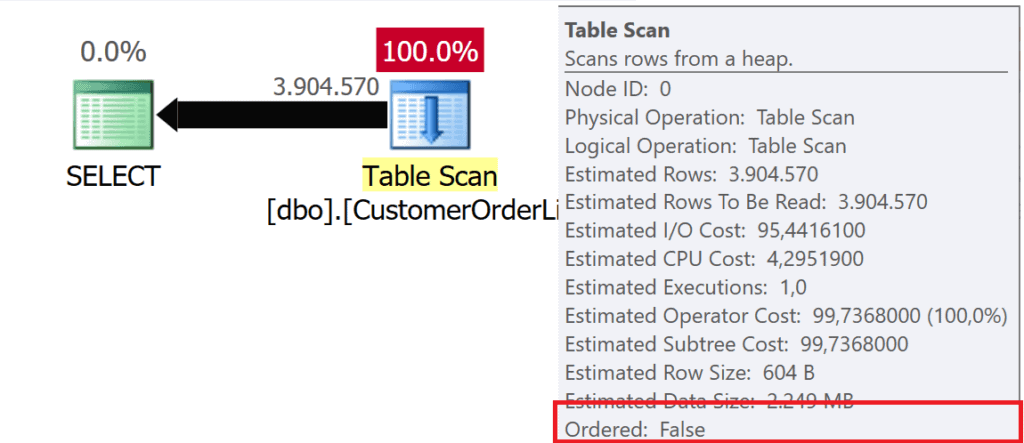
Figure 1: SELECT * FROM dbo.CustomerList
When Microsoft SQL Server reads data from a table or an index, this can be done in two ways:
- The data selection follows the B-tree structure of an index
- The data is selected in accordance with the logical arrangement of data pages
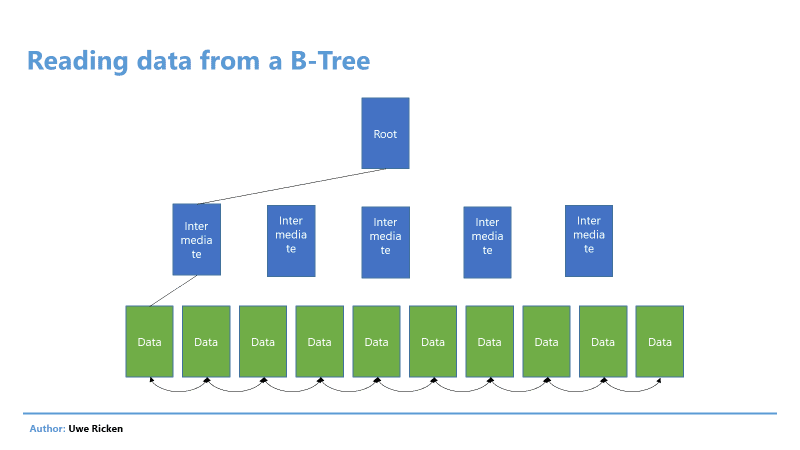
Figure 2: Reading data in a B-Tree basically follows the index structure
In a Heap, the reading process takes place in the order in which data was saved on the data pages. Microsoft SQL Server reads information about the data pages of the Heap from the IAM page of a table, which is described in the article “Heaps in SQL Server: Part 1 The Basics”.
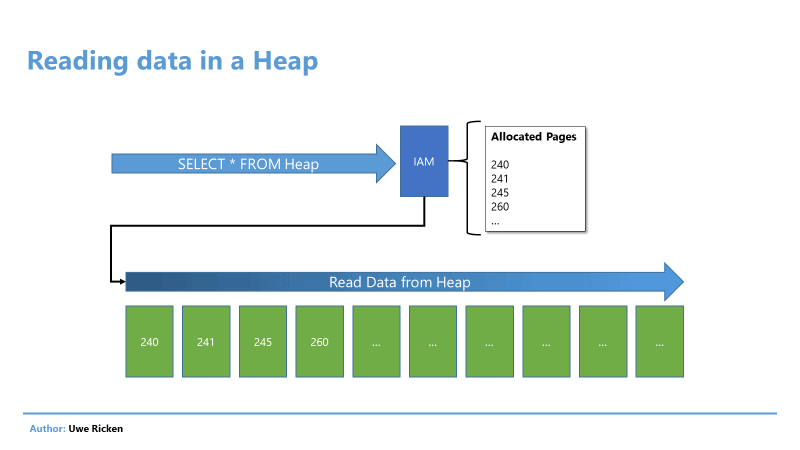
Figure 3: Reading data in a Heap follows the logical order of data pages
After the “route” for reading the data has been read from the IAM, the SCAN process begins to send the data to the client. This technique is called “Allocation Order Scan” and can be observed above all at Heaps.
If the data is limited by a predicate, the way of working does not change. Since the data is unsorted in a Heap, Microsoft SQL Server must always search the complete table (all data pages).
SELECT * FROM dbo.CustomerOrderList WHERE Customer_Id = 10; GO
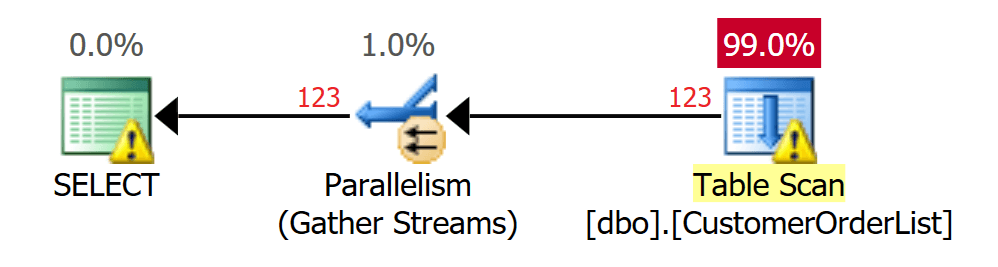
Figure 4: Scan over the whole table
The filtering is called “predicate pushdown”. Before further processes are processed, the number of data records is reduced as much as possible! A predicate pushdown can be made visible in the execution plan using trace flag 9130!
SELECT * FROM dbo.CustomerOrderList WHERE Customer_Id = 10 OPTION (QUERYTRACEON 9130); GO

Figure 5: FILTER Operator for selected data
Advantages of reading from Heaps
Heaps appear to be inferior to an index when reading data. However, this statement only applies if the data is to be limited by a predicate. In fact, when reading the complete table, the Heap has two – in my view – significant advantages:
- No B-tree structure has to be read; only the data pages are read.
- If the Heap is not fragmented and has no forwarded records (described in a later article), Heaps can be read sequentially. Data is read from the storage in the order in which they were entered.
- An index always follows the pointers to the next data page. If the index is fragmented, random reads occur that are not as powerful as sequential read operations.
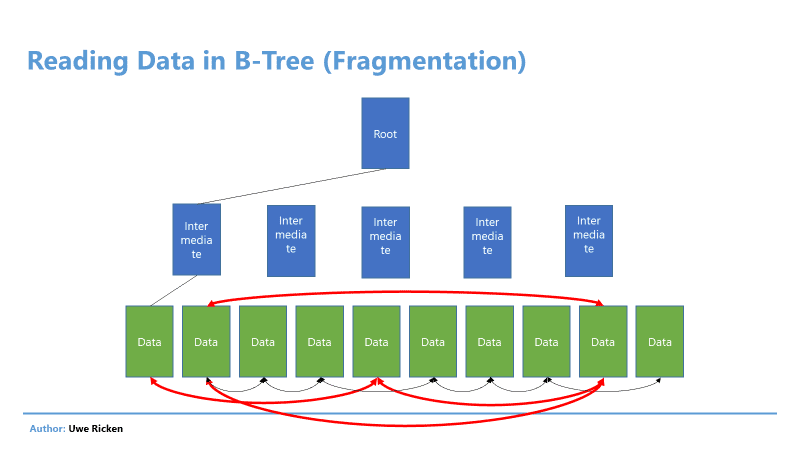
Figure 6: Reading from a B-Tree
Disadvantages when reading from Heaps
One of the biggest drawbacks when reading data from a Heap is the IAM scan while reading the data. Microsoft SQL Server must hold a lock to ensure that the metadata of the table structure is not changed during the read process.
The code shown below creates an extended event that records all the locks set in a transaction. The script only records activity for a predefined user session, so be sure to change the user session ID in the script to match yours.
-- Create an XEvent for analysis of the locking
CREATE EVENT SESSION [Track Lockings]
ON SERVER
ADD EVENT sqlserver.lock_acquired
(ACTION (package0.event_sequence)
WHERE
(
sqlserver.session_id = 55
AND mode = 1
)
),
ADD EVENT sqlserver.lock_released
(ACTION (package0.event_sequence)
WHERE
(
sqlserver.session_id = 55
AND mode = 1
)
),
ADD EVENT sqlserver.sql_statement_completed
(ACTION (package0.event_sequence)
WHERE (sqlserver.session_id = 55)
),
ADD EVENT sqlserver.sql_statement_starting
(ACTION (package0.event_sequence)
WHERE (sqlserver.session_id = 55)
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
);
GO
ALTER EVENT SESSION [Track Lockings]
ON SERVER
STATE = START;
GO
When you run the SELECT statement from the first demo, the Extended Event session will record the following activities:

Figure 7: Holding a SCH_S-Lock when reading data from a Heap
The lock is not released until the SCAN operation has been completed.
NOTE: If Microsoft SQL Server chooses a parallel plan when executing the query, EVERY thread holds a SCH‑S lock on the table.
In a highly competitive system, such locks are not desirable because they serialize operations. The larger the Heap, the longer the locks will prevent further metadata operations:
- Create indexes
- Rebuild indexes
- Add or delete columns
- TRUNCATE operations
- …
Another “shortcoming” of Heaps can be the high number of I/O if only small amounts of data have to be selected. Here, however, it is advisable to use a NONCLUSTERED INDEX to optimize these operations.
Optimize SELECT operations
As stated earlier, Microsoft SQL Server must always read the table completely when executing a SELECT statement. Since Microsoft SQL Server performs an allocation order scan, the data is read in the order of its logical locations.
Use of the TOP operator
With the help of the TOP(n) operator, you will be lucky if the affected data records have been saved on the first data pages of the Heap.
-- Select the very first record SELECT TOP (1) * FROM dbo.CustomerOrderList OPTION (QUERYTRACEON 9130); GO -- Select the very first record with a predicate -- which determines a record at the beginning of -- the Heap SELECT TOP (1) * FROM dbo.CustomerOrderList WHERE Customer_Id = 1 OPTION (QUERYTRACEON 9130, MAXDOP 1); GO -- Select the very first record with a predicate -- which determines a record at any position in -- the Heap SELECT TOP (1) * FROM dbo.CustomerOrderList WHERE Customer_Id = 22844 OPTION (QUERYTRACEON 9130); GO
The above code performs three queries using the TOP operator. The first query finds the physically first data record that was saved in the table.
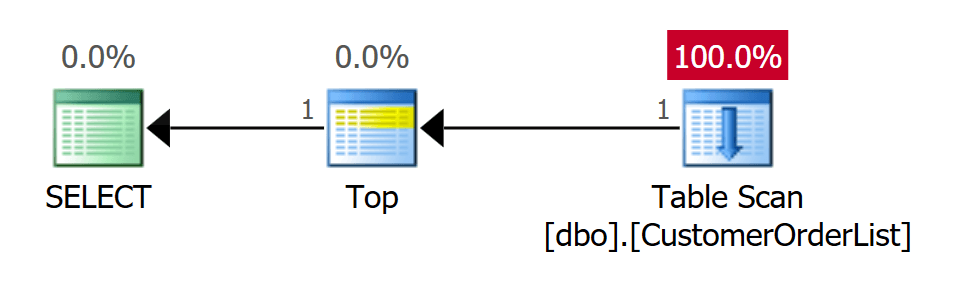
Figure 8: Table scan for determining the first data record – 1 I/O
As expected, the execution plan uses a table scan operator. It is the only operator that can be used for a Heap. However, the TOP operator prevents the table from being searched completely. When the number of data records to be delivered to the client has been reached, the TOP operator terminates the connection to the table scan, and the process is finished.
NOTE: Although only one data record is to be determined, a SCH-S lock is set on the table!
The second query also only requires 1 I/O. However, this is because the record you are looking for is the first record in the table. However, Microsoft SQL Server must use a FILTER operator for the predicate. The TOP operator terminates the subsequent operations immediately after receiving the first data record. 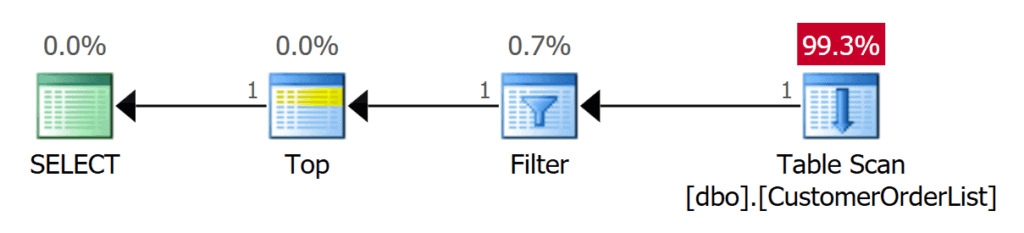
Figure 9: Search with predicate must search 1 data record
The third query uses a predicate that only finds a data record at the 1,875th position. In this situation, Microsoft SQL Server must read many more data pages before the process has the desired result set and automatically ends the process. 
Figure 10: Search with predicate must search 1,875 records
The bottom line is that a TOP operator can be helpful; in practice, this is rather not the case, since the number of data pages to be read always depends on the logical position of the data record.
Compression
Apparently, it is not possible to reduce the I/O for operations in a Heap (all data pages must always be read!), The compression of the data helps to reduce I/O.
Microsoft SQL Server provides two types of data compression for possible reduction:
- Row compression
- Page compression
NOTE: The options “ColumnStore” and “ColumnStore_Archive” are also available for data compression. However, these types of compression cannot be applied to a Heap, but only to columnstore indexes!
For Heaps and partitioned Heaps, data compression can be a distinct advantage in terms of I/O. However, there are a few special features that need to be considered when compressing data in a Heap. When a Heap is configured to compress at the page level, the compression is done in the following ways:
- The mapping of new data pages in a Heap as part of DML operations only uses page compression after the Heap has been re-created.
- Changing the compression setting for a Heap forces all nonclustered indexes to be rebuilt because the position mappings must be rewritten.
ROWorPAGEcompression can be activated and deactivated online or offline.- Enabling compression for a Heap online is done with a single thread.
The system procedure [sp_estimate_data_compression_savings] can be used to determine whether the compression of tables and / or indexes actually has an advantage.
-- Evaluate the savings by compression of data
DECLARE @Result TABLE
(
Data_Compression CHAR(4) NOT NULL DEFAULT '---',
object_name SYSNAME NOT NULL,
schema_name SYSNAME NOT NULL,
index_id INT NOT NULL,
partition_number INT NOT NULL,
current_size_KB BIGINT NOT NULL,
request_size_KB BIGINT NOT NULL,
sample_size_KB BIGINT NOT NULL,
sample_request_KB BIGINT NOT NULL
);
INSERT INTO @Result
(object_name, schema_name, index_id, partition_number,
current_size_KB, request_size_KB, sample_size_KB,
sample_request_KB)
EXEC sp_estimate_data_compression_savings
@schema_name = 'dbo',
@object_name = 'CustomerOrderList',
@index_id = 0,
@partition_number = NULL,
@data_compression = 'PAGE';
UPDATE @Result
SET Data_Compression = 'PAGE'
WHERE Data_Compression = '---';
-- Evaluate the savings by compression of data
INSERT INTO @Result
(object_name, schema_name, index_id, partition_number,
current_size_KB, request_size_KB, sample_size_KB,
sample_request_KB)
EXEC sp_estimate_data_compression_savings
@schema_name = 'dbo',
@object_name = 'CustomerOrderList',
@index_id = 0,
@partition_number = NULL,
@data_compression = 'ROW';
UPDATE @Result
SET Data_Compression = 'ROW'
WHERE Data_Compression = '---';
SELECT Data_Compression,
current_size_KB,
request_size_KB,
(1.0 - (request_size_KB * 1.0 / current_size_KB * 1.0)) * 100.0
AS percentage_savings
FROM @Result;
GO
The above script is used to determine the possible savings in data volume for row and data page compression.

Figure 11: Savings of more than 30% are possible
The next script inserts all records from the [dbo].[CustomerOrderList] table into a temporary table. Both I/O and CPU times are measured. The test is performed with uncompressed data, page compression and row compression.
ALTER TABLE dbo.CustomerOrderList REBUILD WITH (DATA_COMPRESSION = NONE); GO -- IO and CPU without compression SELECT * INTO #Dummy FROM dbo.CustomerOrderList GO DROP TABLE #Dummy; GO ALTER TABLE dbo.CustomerOrderList REBUILD WITH (DATA_COMPRESSION = PAGE); GO -- IO and CPU without compression SELECT * INTO #Dummy FROM dbo.CustomerOrderList GO DROP TABLE #Dummy; GO ALTER TABLE dbo.CustomerOrderList REBUILD WITH (DATA_COMPRESSION = ROW); GO -- IO and CPU without compression SELECT * INTO #Dummy FROM dbo.CustomerOrderList GO DROP TABLE #Dummy; GO
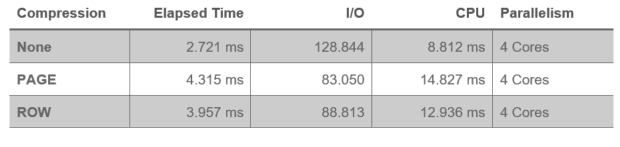
The measurements show the problem of data compression. The I/O is reduced significantly; however, the savings potential is “eaten up” by the increased CPU usage.
The bottom line for data compression is that it can certainly be an option to reduce I/O. Unfortunately, this “advantage” is quickly nullified by the disproportionate consumption of other resources (CPU). If you have a system with sufficiently fast processors in large numbers, you should consider this option. Otherwise, you should choose CPU resources; this applies all the more to systems with a large number of small transactions.
You should also check your application very carefully before using compression techniques. Microsoft SQL Server creates execution plans that take into account the estimated I/O. Is significantly less I/O generated by the use of compression, it can lead to an execution plan being changed (a HASH or MERGE operator becomes a NESTED LOOP operator). Anyone who believes that data compression saves memory (both for the buffer pool and for SORT operations) is wrong!
- Data is always decompressed in the buffer pool.
- A SORT operator calculates its memory requirements based on the data records to be processed
Partitioning
With the help of partitioning, tables are divided horizontally. Several groups are created that lie within the boundaries of partitions.
NOTE: Partitioning is a very complex topic and cannot be covered in detail in this series of articles. More information on partitioning can be found in the online documentation for Microsoft SQL Server.
A valued colleague from Norway (Cathrine Wilhelmsen (b | t), has also written a very remarkable series of articles on partitioning, which can be found here.
The advantage of partitioning Heaps can only take effect if the Heap is used to search for predicate patterns that match the partition key. Unless you’re looking for the partition key, partitioning can’t really help you find data.
For the following demo users often search for orders in the [dbo].[CustomerOrderList].
-- Find all orders from 2016
SELECT * FROM dbo.CustomerOrderList
WHERE OrderDate >= '20160101'
AND OrderDate <= '20161231'
ORDER BY
Customer_Id,
OrderDate DESC
OPTION (QUERYTRACEON 9130);
GO
Microsoft SQL Server had to search the entire table to run the query. This is noticeable in the I/O as well as in the CPU load! 
Figure 12: TABLE SCAN over 4,000,000 records
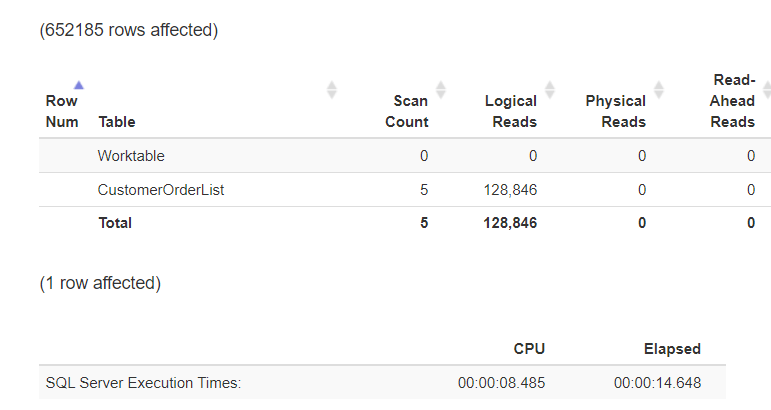
Figure 13: Statistics formatted with https://statisticsparser.com
Without an index, there is no way to reduce I/O or CPU load. A reduction can only be achieved by reducing the amount of data to be read. For this reason, the table gets partitioned so that a separate partition is used for each year.
NOTE: Partitioning is not a mandatory topic for this article, but I want to allow replay of the demos for the readers. Please excuse me that I am only describing the functionality of the code but not the partitioning as such.
In the first step, create a filegroup for every order year in the database. For a better performance, every order year is located on a separate database file.
-- We create for each year up to 2019 one filegroup
--and add one file for each filegroup!
DECLARE @DataPath NVARCHAR(256) =
CAST(SERVERPROPERTY('InstanceDefaultDataPath') AS NVARCHAR(256));
DECLARE @stmt NVARCHAR(1024);
DECLARE @Year INT = 2000;
WHILE @Year <= 2019
BEGIN
SET @stmt = N'ALTER DATABASE CustomerOrders
ADD FileGroup ' + QUOTENAME(N'P_' +
CAST(@Year AS NCHAR(4))) + N';';
RAISERROR ('Statement: %s', 0, 1, @stmt);
EXEC sys.sp_executeSQL @stmt;
SET @stmt = N'ALTER DATABASE CustomerOrders
ADD FILE
(
NAME = ' + QUOTENAME(N'Orders_' +
CAST(@Year AS NCHAR(4)), '''') + N',
FILENAME = ''' + @DataPath + N'ORDERS_' +
CAST(@Year AS NCHAR(4)) + N'.ndf'',
SIZE = 128MB,
FILEGROWTH = 128MB
)
TO FILEGROUP ' + QUOTENAME(N'P_' + CAST(@Year AS NCHAR(4))) + N';';
RAISERROR ('Statement: %s', 0, 1, @stmt);
EXEC sys.sp_executeSQL @stmt;
SET @Year += 1;
END
GO
You can see that each year has its own filegroup and file after running the script:
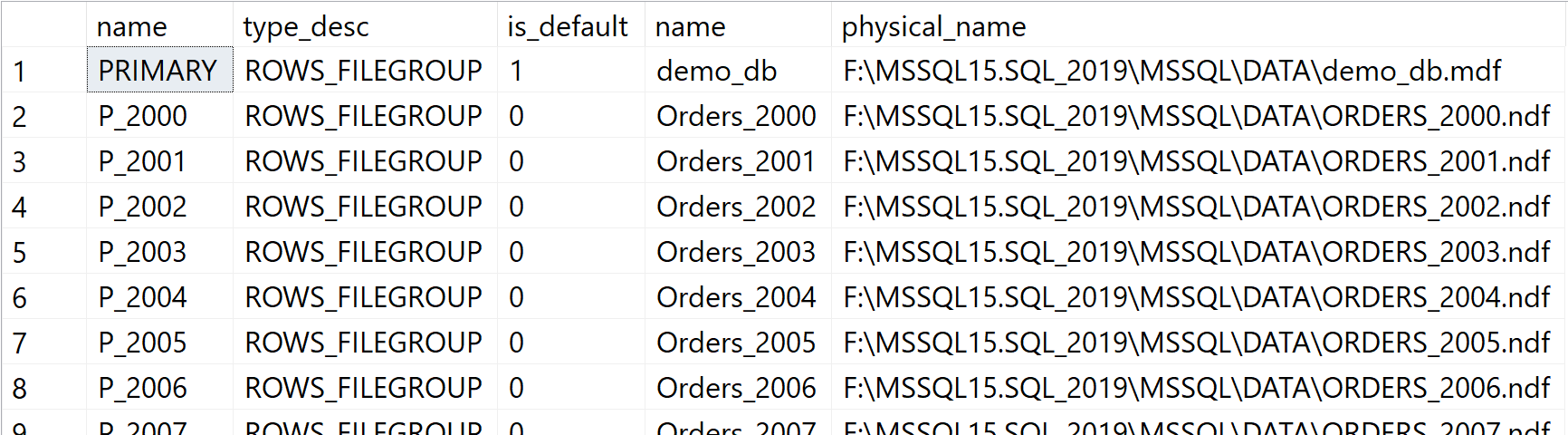
Figure 14: Each Order Year has its own database file
The next step is to create a partition function that ensures that the order year is correctly assigned and saved.
CREATE PARTITION FUNCTION pf_OrderDate(DATE)
AS RANGE LEFT FOR VALUES
(
'20001231', '20011231', '20021231', '20031231', '20041231',
'20051231', '20061231', '20071231', '20081231', '20091231',
'20101231', '20111231', '20121231', '20131231', '20141231',
'20151231', '20161231', '20171231', '20181231', '20191231'
);
GO
Finally, in order to connect the partition function with the filegroups, you need the partition scheme, which gets generated with the next script.
CREATE PARTITION SCHEME [OrderDates]
AS PARTITION pf_OrderDate
TO
(
[P_2000], [P_2001], [P_2002], [P_2003], [P_2004],
[P_2005], [P_2006], [P_2007], [P_2008], [P_2009],
[P_2010], [P_2011], [P_2012], [P_2013], [P_2014],
[P_2015], [P_2016], [P_2017], [P_2018], [P_2019]
,[PRIMARY]
);
GO
When the Partition schema exists, you can now distribute the data from the table over all the partitions based on the year of the order. To move a non-partitioned Heap into a partition schema, you need to build a Clustered Index based on the partition schema and drop it afterwards.
CREATE CLUSTERED INDEX cix_CustomerOrderList_OrderDate ON dbo.CustomerOrderList (OrderDate) ON OrderDates(OrderDate); GO DROP INDEX cix_CustomerOrderList_OrderDate ON dbo.CustomerOrderList; GO
The data for the individual years are split up to 20 years and the result looks as follows
-- Let's combine all information to an overview
SELECT p.partition_number AS [Partition #],
CASE pf.boundary_value_on_right
WHEN 1 THEN 'Right / Lower'
ELSE 'Left / Upper'
END AS [Boundary Type],
prv.value AS [Boundary Point],
stat.row_count AS [Rows],
fg.name AS [Filegroup]
FROM sys.partition_functions AS pf
INNER JOIN sys.partition_schemes AS ps
ON ps.function_id=pf.function_id
INNER JOIN sys.indexes AS si
ON si.data_space_id=ps.data_space_id
INNER JOIN sys.partitions AS p
ON
(
si.object_id=p.object_id
AND si.index_id=p.index_id
)
LEFT JOIN sys.partition_range_values AS prv
ON
(
prv.function_id=pf.function_id
AND p.partition_number=
CASE pf.boundary_value_on_right
WHEN 1 THEN prv.boundary_id + 1
ELSE prv.boundary_id
END
)
INNER JOIN sys.dm_db_partition_stats AS stat
ON
(
stat.object_id=p.object_id
AND stat.index_id=p.index_id
AND stat.index_id=p.index_id
AND stat.partition_id=p.partition_id
AND stat.partition_number=p.partition_number
)
INNER JOIN sys.allocation_units as au
ON
(
au.container_id = p.hobt_id
AND au.type_desc ='IN_ROW_DATA'
)
INNER JOIN sys.filegroups AS fg
ON fg.data_space_id = au.data_space_id
ORDER BY
[Partition #];
GO
Many thanks to Kendra Little for the basic idea of this query.
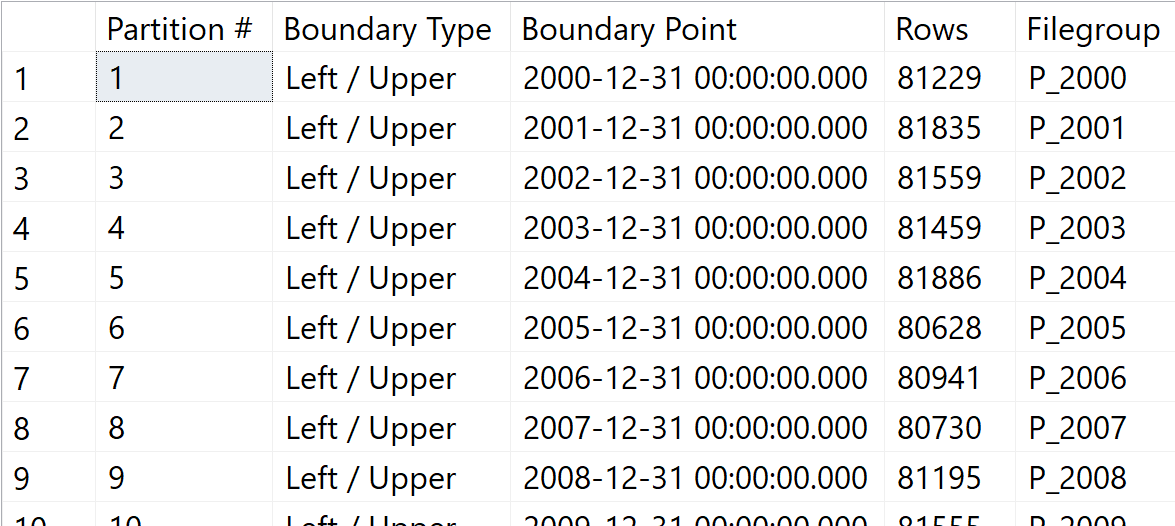
Figure 15: Heap with partitioned data
If the previously executed query is carried out based on partitioning on the predicate column, this results in a completely different runtime behaviour:
-- Find all orders from 2016
SELECT * FROM dbo.CustomerOrderList
WHERE OrderDate >= '20160101'
AND OrderDate <= '20161231'
ORDER BY
Customer_Id,
OrderDate DESC
OPTION (QUERYTRACEON 9130);
GO
Microsoft SQL Server uses the boundaries for the partitions to identify the partition in which the values to be found can appear. Other partitions are no longer considered and are, therefore, “excluded” from the table scan. 
Figure 16: Excluding unneeded partitions
The runtime has not changed significantly (the number of data records sent to the client has not changed!), but you can see very well that the CPU load has been reduced by approximately 25%.
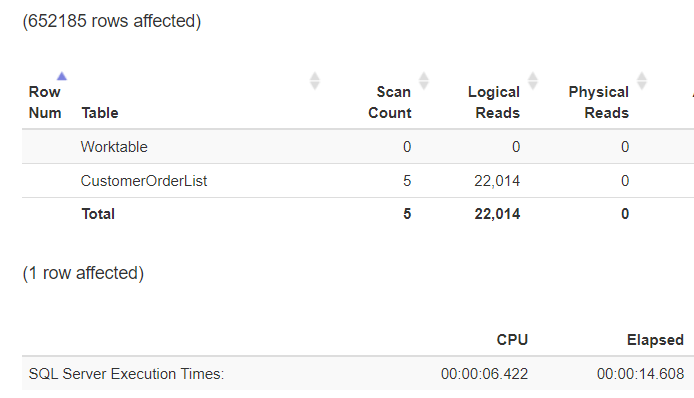
Figure 17: Decreased logical reads due to eliminated partitions
If the whole workload is focused on I/O and not on the CPU load, the last possibility for reduction is to compress the data at the partition level!
ALTER TABLE dbo.CustomerOrderList REBUILD PARTITION = 17 WITH (DATA_COMPRESSION = ROW); GO
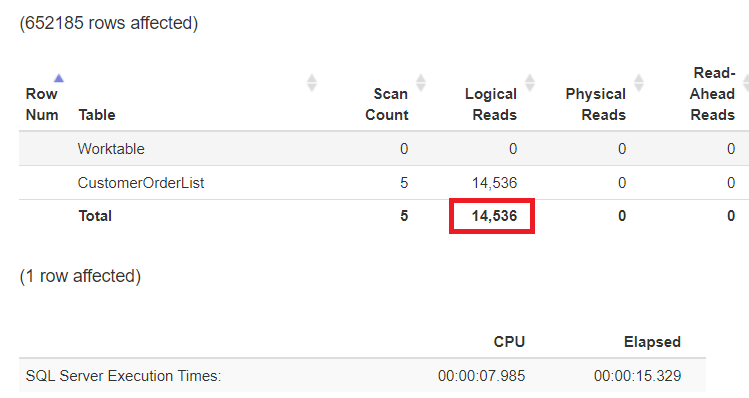
Figure 18: Logical reads with partitioning and compression turned on
Summary
Heaps are hopelessly inferior indexes when it comes to selectively extracting data. However, if – for example a data warehouse – large amounts of data have to be processed, a Heap might perform better. Hopefully, I have been able to demonstrate the requirements and technical possibilities for improvements when you have to (maybe will) deal with Heaps.
The post Heaps in SQL Server: Part 2 Optimizing Reads appeared first on Simple Talk.
from Simple Talk https://ift.tt/2YSVbNu
via
No comments:
Post a Comment