The series so far:
- Hands-On with Columnstore Indexes: Part 1 Architecture
- Hands-On with Columnstore Indexes: Part 2 Best Practices and Guidelines
- Hands-On with Columnstore Indexes: Part 3 Maintenance and Additional Options
Like other indexes, columnstore indexes require maintenance as they can become fragmented with time. A well-architected columnstore index structure that is loaded via best practices will tend not to get fragmented quickly, especially if updates and deletes are avoided.
A discussion of columnstore index structure and maintenance would not be complete without a look into nonclustered columnstore indexes, which allow the columnstore structure to be built on top of an OLTP table with a standard clustered index. Similarly, it is possible to create memory-optimized columnstore indexes. Therefore, it is worth exploring how combining these technologies affects performance and data storage.
Columnstore Index Maintenance
Like with standard B-tree indexes, a columnstore index may be the target of a rebuild or reorganize operation. The similarities end here, as the function of each is significantly different and worth considering carefully prior to using either.
There are two challenges addressed by columnstore index maintenance:
- Residual open rowgroups or open deltastores after write operations complete.
- An abundance of undersized rowgroups that accumulate over time
Open rowgroups and deltastores are the results of write operations: insert, update, and delete. A columnstore index that is primarily bulk loaded and rarely (or never) the target of updates/deletes will not suffer from this. A columnstore index that is the target of frequent updates and deletes will have an active deltastore and many rows that are flagged for deletion.
A key takeaway here is that inserting data into a columnstore index in order and avoiding other write operations will improve the efficiency of the index and reduce the need for index maintenance.
Undersized rowgroups will occur naturally over time as rows are bulk loaded in quantities less than 220 at a time. The cost of having extra rowgroups is not significant at first, but over time can become burdensome. An easy way to gauge this is to compare the number of rowgroups with the hypothetical minimum needed to store the data.
For example, the demo table from the previous article contains 23,141,200 rows. In an optimal columnstore index, we would have 23,141,200 / 1,048,576 rowgroups, or 22.069 (rounded up to 23 since we cannot have a fractional rowgroup). If in a few months this table had 25 rowgroups, then there would be little need to be concerned. Alternatively, if there were 500 rowgroups, then it would be worth considering:
- Rebuilding the index.
- Reviewing the data load process for efficiency.
We can view the state of rowgroups by querying sys.dm_db_column_store_row_group_physical_stats:
SELECT
tables.name AS table_name,
indexes.name AS index_name,
partitions.partition_number,
dm_db_column_store_row_group_physical_stats.row_group_id,
dm_db_column_store_row_group_physical_stats.total_rows,
dm_db_column_store_row_group_physical_stats.deleted_rows,
dm_db_column_store_row_group_physical_stats.state_desc,
dm_db_column_store_row_group_physical_stats.trim_reason_desc
FROM sys.dm_db_column_store_row_group_physical_stats
INNER JOIN sys.indexes
ON indexes.index_id =
dm_db_column_store_row_group_physical_stats.index_id
AND indexes.object_id =
dm_db_column_store_row_group_physical_stats.object_id
INNER JOIN sys.tables
ON tables.object_id = indexes.object_id
INNER JOIN sys.partitions
ON partitions.partition_number =
dm_db_column_store_row_group_physical_stats.partition_number
AND partitions.index_id = indexes.index_id
AND partitions.object_id = tables.object_id
WHERE tables.name = 'fact_order_BIG_CCI'
ORDER BY indexes.index_id,
dm_db_column_store_row_group_physical_stats.row_group_id;
The results provide a bit more information about rowgroups and their contents:
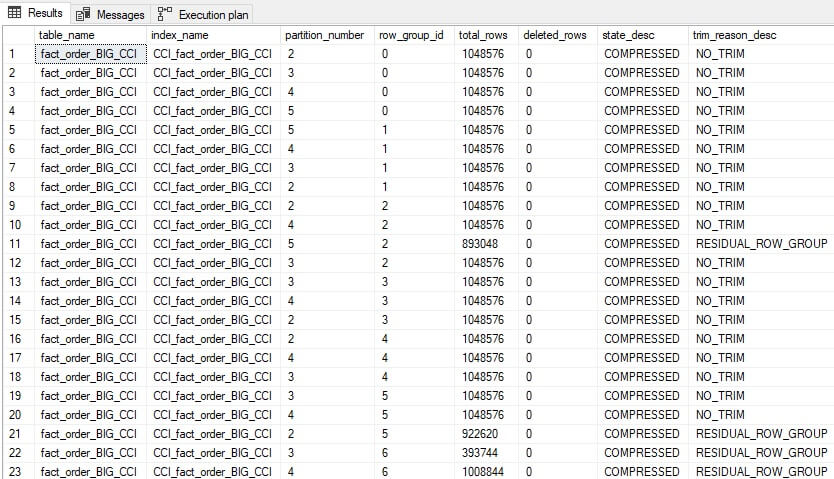
Note that the row group IDs are repeated as they are spread across 5 partitions. The combination of row_group_id and partition_number will be unique within a given columnstore index that has table partitioning enabled.
This index is close to optimal, with most rowgroups full or nearly full. The data above indicates to an operator that no index maintenance is needed at this time. The trim reason tells us why a rowgroup was closed before being filled to the maximum allowed size.
We can add some churn into the index for use in the further demo below:
UPDATE fact_order_BIG_CCI
SET Quantity = 1
FROM dbo.fact_order_BIG_CCI
WHERE fact_order_BIG_CCI.[Order Key] >= 8000101
AND fact_order_BIG_CCI.[Order Key] < 8001001;
GO
DELETE fact_order_BIG_CCI
FROM dbo.fact_order_BIG_CCI
WHERE fact_order_BIG_CCI.[Order Key] >= 80002001
AND fact_order_BIG_CCI.[Order Key] < 80002501;
GO
INSERT INTO dbo.fact_order_BIG_CCI
SELECT TOP 1 * FROM dbo.fact_order_BIG_CCI
GO 100
As a reminder, these types of small write operations are not optimal for a columnstore index. Rerunning the query against sys.dm_db_column_store_row_group_physical_stats reveals some changes. Filtering by state_desc and deleted_rows reduces the rows returned, which is especially useful against a large columnstore index:
SELECT
tables.name AS table_name,
indexes.name AS index_name,
partitions.partition_number,
dm_db_column_store_row_group_physical_stats.row_group_id,
dm_db_column_store_row_group_physical_stats.total_rows,
dm_db_column_store_row_group_physical_stats.deleted_rows,
dm_db_column_store_row_group_physical_stats.state_desc,
dm_db_column_store_row_group_physical_stats.trim_reason_desc
FROM sys.dm_db_column_store_row_group_physical_stats
INNER JOIN sys.indexes
ON indexes.index_id =
dm_db_column_store_row_group_physical_stats.index_id
AND indexes.object_id =
dm_db_column_store_row_group_physical_stats.object_id
INNER JOIN sys.tables
ON tables.object_id = indexes.object_id
INNER JOIN sys.partitions
ON partitions.partition_number =
dm_db_column_store_row_group_physical_stats.partition_number
AND partitions.index_id = indexes.index_id
AND partitions.object_id = tables.object_id
WHERE tables.name = 'fact_order_BIG_CCI'
AND (dm_db_column_store_row_group_physical_stats.state_desc
<> 'COMPRESSED'
OR dm_db_column_store_row_group_physical_stats.deleted_rows > 0)
ORDER BY indexes.index_id,
dm_db_column_store_row_group_physical_stats.row_group_id;
The results are as follows:

An existing rowgroup has been updated to show that it contains 900 deleted rows. These rows will remain in the columnstore index until rebuilt. A new deltastore has been created to store the 1000 rows that were recently inserted. It is open, indicating that more rows can be added as needed. This allows the 1000 insert operations executed above to be combined into a single rowgroup, rather than lots of smaller ones.
Reorganize
A clustered columnstore index may be reorganized as an online operation. As such, this maintenance can be performed anytime without blocking access to it. This operation will take whatever is in the deltastore and process it immediately, as though the tuple mover was running and handling it.
The primary benefit of reorganizing a columnstore index is to speed up OLAP queries by removing the deltastore rowstore records and moving them to the columnstore index structure. Queries no longer need to read data from the deltastore to get the data they need. In addition, since the index is highly compressed, the memory required to read the data needed to satisfy a query is smaller.
The syntax to reorganize a columnstore index is similar to that for a standard B-tree index:
ALTER INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI REORGANIZE;
Reviewing the physical stats for this index shows the following results: 
No changes! The reason that there is still an open rowgroup is that SQL Server is waiting for more rows to be added before compressing and adding it to the columnstore index. Having a large volume of tiny rowgroups would be inefficient as the ideal size is 220 rows, and the closer we can get to that magic number, the better.
We can force the tuple mover to process the deltastore, close it, and commit it to compressed data within the columnstore index by using the following variant on the reorganize statement:
ALTER INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI REORGANIZE WITH (COMPRESS_ALL_ROW_GROUPS = ON);
The results look like this:

A rowgroup that is labelled with the state TOMBSTONE indicates that it was a part of a deltastore and was forcefully compressed into a columnstore rowgroup. The residual rowgroup no longer has any non-deleted rows in it and therefore is labelled with the ominous tombstone state. These are intermediary rowgroups that will be deallocated. We can force this along with another reorganization command, and the tombstone rowgroup is gone.
Note that there is no need to force this change. Doing so demonstrates how automated processes can be started to fast-track a given result. Given time, this cleanup will occur anyway. Therefore there is no compelling reason to do this in a production environment.
The final version of the columnstore index can be viewed by removing the filters on state_desc and deleted_rows:
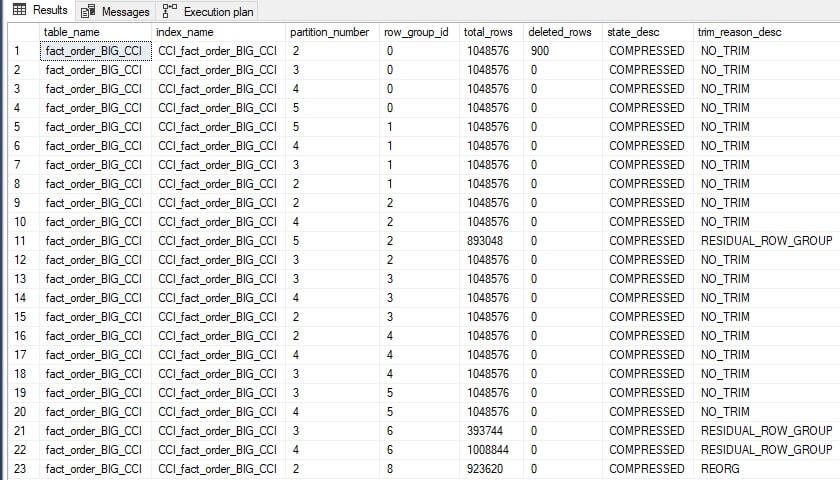
There are 23 compressed rowgroups, and the trim reason for the final rowgroup has been changed to REORG, indicating that it was opened and closed via an index reorganization process. Note that the index has the same number of rowgroups as earlier and row counts that are more than acceptable for OLAP operations.
Rebuild
Rebuilding a clustered columnstore index is an offline operation until SQL Server 2019 when the ability to rebuild online was introduced. As with a B-tree index, the rebuild will create a brand new columnstore index from the underlying data. Doing so will:
- Eliminate all data in the deltastore.
- Eliminate all deleted rows.
- Reduce the number of compressed rowgroups, if large numbers of smaller ones exist.
This operation is expensive and should be reserved for a dedicated maintenance window and only when the index has become so fragmented that no other options exist.
Note that the order of data is not changed when the columnstore index is rebuilt. Similar to when our demo table was first created, if no order is enforced, then SQL Server will build a new index on top of our data as-is. If the columnstore index table has been maintained by adding data in order over time, then odds are good that no special work will be needed to re-order it.
The columnstore index we have been tinkering with thus far can be rebuilt like this:
ALTER INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI REBUILD WITH (ONLINE = ON);
Note again that the ONLINE option is not available prior to SQL Server 2019. For this table, the rebuild takes about 2 minutes. Reviewing all rowgroups in the table reveals the following:
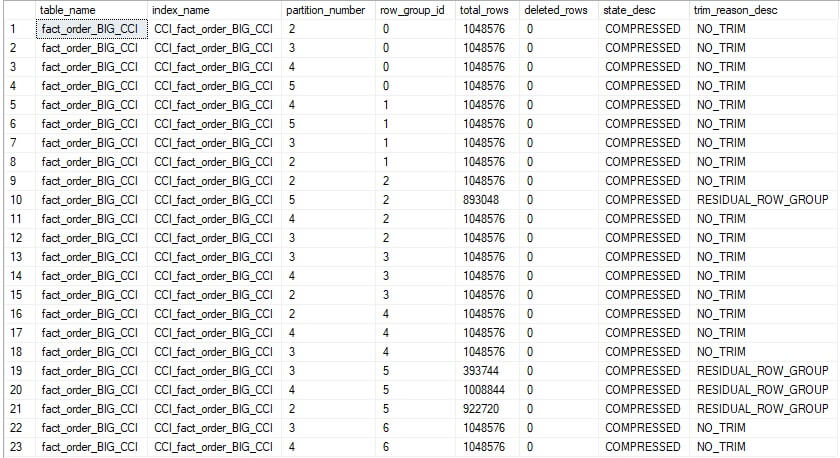
The deleted rows are gone, and rows from other rowgroups were pushed into the vacancy left behind. While there are still some rowgroups that are not completely full, this index is quite efficiently structured overall.
If table partitioning is in use, then index rebuilds become significantly less expensive as the active partition(s) can be targeted for a rebuild and the rest ignored. In a table where a large portion of the data is old and unchanged, this can save immense system resources, not to mention time!
The syntax to rebuild a specific partition is as follows:
ALTER INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI REBUILD PARTITION = 5 WITH (ONLINE = ON);
When executed, the rebuild will only target partition 5. If this is the active partition and the others contain older static data, then this will be the only partition with fragmentation, assuming no unusual change has occurred on older data. The rebuild of partition 5 shown above took about 20 seconds to complete.
The simplest way to measure when a columnstore index needs a rebuild is to measure the quantity of deleted rows and compare it to the total rows for each partition. If a partition contains 1 million rows of which none are deleted, then it’s in great shape! If a partition contains 1 million rows, of which 200k are flagged for deletion, then a rebuild would be a good idea to remove those soft-deleted rows from the index.
The following query groups columnstore index metadata by table, index, and partition, allowing for a relatively simple, but useful view of fragmentation:
SELECT
tables.name AS table_name,
indexes.name AS index_name,
partitions.partition_number,
SUM(dm_db_column_store_row_group_physical_stats.total_rows)
AS total_rows,
SUM(dm_db_column_store_row_group_physical_stats.deleted_rows)
AS deleted_rows
FROM sys.dm_db_column_store_row_group_physical_stats
INNER JOIN sys.indexes
ON indexes.index_id =
dm_db_column_store_row_group_physical_stats.index_id
AND indexes.object_id =
dm_db_column_store_row_group_physical_stats.object_id
INNER JOIN sys.tables
ON tables.object_id = indexes.object_id
INNER JOIN sys.partitions
ON partitions.partition_number =
dm_db_column_store_row_group_physical_stats.partition_number
AND partitions.index_id = indexes.index_id
AND partitions.object_id = tables.object_id
WHERE tables.name = 'fact_order_BIG_CCI'
GROUP BY tables.name, indexes.name, partitions.partition_number
The results of this query are as follows:
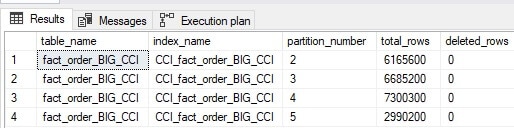
This specific example provides insight into an index that requires no maintenance. If the count of deleted rows was high enough, though, then a rebuild of that partition could save storage, memory, and make queries against that data faster. Note that deleted_rows includes both rows that were deleted and those that were updated, since an update is modelled as a delete followed by an insert.
Additional Index Maintenance Notes
In general, a common plan for index maintenance is as follows:
- Perform an index reorganization with the
compress_all_row_groupsoption on after any large data load, or on a semi-regular basis. This is inexpensive, online, and will generally keep an index defragmented enough for efficient use for quite a long time. - Perform infrequent index rebuilds on heavily fragmented partitions (if partitioned) or the entire index (if not). Perform this online, if available, as it will eliminate the need for either a maintenance window or data trickery to avoid a maintenance window.
If a columnstore index is loaded solely via inserts (no deletes or updates) and the data is consistently inserted in order, then fragmentation will occur very slowly over time, and index rebuilds will be rarely (if ever) needed.
OLAP databases are uniquely positioned to take advantage of this fact, as their data loads are typically isolated, primarily inserts, and performed at designated intervals. This differs from OLTP databases, that are often the target of deletes, updates, software releases, and other operations that can quickly cause heavy fragmentation.
Nonclustered Columnstore Indexes
The discussion of columnstore indexes thus far has focused on clustered columnstore indexes that target a primarily OLAP workload. SQL Server also supports nonclustered columnstore indexes. A table may only have one columnstore index on it at a time, regardless of whether it is clustered or nonclustered. A nonclustered columnstore index functions similarly to a clustered columnstore index in terms of architecture, data management, the deltastore, and other nuances discussed thus far in this article.
To illustrate the effects of a nonclustered columnstore index, consider the following query:
SELECT
SUM([Quantity])
FROM dbo.fact_order_BIG
WHERE [Order Date Key] >= '1/1/2016'
AND [Order Date Key] < '2/1/2016';
This is executing against a table without a columnstore index, but with a nonclustered index on [Order Date Key]. When executed, there is a bit of waiting, and the result is returned. The following is the IO for the query:

That sort of IO is not acceptable against a busy OLTP table and will cause latency and contention for other users that are reading and writing data to this table. If this is a common query, then a nonclustered columnstore index can address it:
CREATE NONCLUSTERED COLUMNSTORE INDEX NCI_fact_order_BIG_Quantity ON dbo.fact_order_BIG ([Order Date Key], Quantity);
By choosing only the columns needed to satisfy the query, the need to maintain a larger and more expensive structure on top of an OLTP data store is avoided. Once complete, the IO for the test query above is significantly reduced:

Note that while IO is 1/10th of the previous cost and the query executed much faster, IO is still high and the details above indicate that no segments were skipped.
Similar to the clustered columnstore index, data order bit us here. If the underlying table were ordered primarily by [Order Date Key], then segments could be skipped as part of query execution. Without that implicit ordering, the efficiency of a nonclustered columnstore index is hindered far more than it would have been if a clustered columnstore index were used.
This poses a challenge to a database architect: Is placing a nonclustered columnstore index on top of an OLTP workload worth the effort? Would a covering index be better? This question can be tested:
DROP INDEX NCI_fact_order_BIG_Quantity ON dbo.fact_order_BIG; CREATE NONCLUSTERED INDEX NCI_fact_order_BIG_Quantity ON dbo.fact_order_BIG ([Order Date Key]) INCLUDE (Quantity);
The new index sorts on [Order Date Key] and adds Quantity as an include column. The following is the IO after this change

A covering nonclustered B-tree index provided more efficient coverage of this query than the nonclustered columnstore index.
Ultimately, the challenge presented here is to separate OLAP and OLTP workloads. Even if a nonclustered columnstore index can be built that is well-ordered and satisfies a query efficiently, it will become fragmented quickly if write operations target the table with frequent inserts, updates, and deletes. The best possible solution to this problem is to separate heavy OLAP workloads from OLTP into their own databases and tables.
The test query above filtered a single column and returned one other. Typically, the hole that administrators and developers fall into with OLAP against OLTP is that it is never just one column. Once reporting against OLTP data ensues, there often ends up being many analytics against many columns that result in the creation of many covering indexes to handle each scenario. Eventually, an OLTP table becomes overburdened by covering indexes and hefty reporting queries that cause contention against critical OLTP workloads.
While nonclustered columnstore indexes exist and can provide targeted relief for expensive OLAP queries, they require heavy testing prior to implementing to ensure that they are efficient, ordered, and can outperform a classic covering index. It is also necessary to ensure that an OLTP database does not become overburdened with OLAP workloads over time.
This is a significant challenge that many administrators and developers struggle with regularly. Ultimately, if reporting data and queries can be separated into their own data store, then we can properly implement a clustered columnstore index. Data can then be architected and ordered to optimize solely for OLAP workloads without the need to be concerned for the impact of those analytics against other real-time transactions.
Memory-Optimized Columnstore Indexes
Because columnstore indexes are compact structures, the ability to natively store them in-memory becomes possible. The example table in this article was 5GB when stored via a classic B-tree clustered index. While not massive, this is also not trivial. If the table were to grow by 5GB every year, then reading the entire thing into memory may not be worth it. Alternatively, the 100MB used for the columnstore index is trivial with regards to memory consumption.
If reporting against a columnstore index requires speed, then converting it into a memory-optimized table is an option for potentially improving performance. Note that data compression in-memory is not as efficient as on disk. As a result, results may vary depending on available memory. Typically, memory-optimized data size will be at least double the size of a disk-based columnstore index.
On a server with limited memory, this will pose a challenge, and testing will be necessary to determine if this is a worthwhile implementation of memory-optimized tables or not. The following is the basic T-SQL syntax needed to create a new memory-optimized columnstore index table:
CREATE TABLE dbo.fact_order_BIG_CCI_MEM_OPT (
[Order Key] [bigint] NOT NULL
CONSTRAINT PK_fact_order_BIG_CCI_MEM_OPT
PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 100000),
[City Key] [int] NOT NULL,
[Customer Key] [int] NOT NULL,
[Stock Item Key] [int] NOT NULL,
[Order Date Key] [date] NOT NULL,
[Picked Date Key] [date] NULL,
[Salesperson Key] [int] NOT NULL,
[Picker Key] [int] NULL,
[WWI Order ID] [int] NOT NULL,
[WWI Backorder ID] [int] NULL,
[Description] [nvarchar](100) NOT NULL,
[Package] [nvarchar](50) NOT NULL,
[Quantity] [int] NOT NULL,
[Unit Price] [decimal](18, 2) NOT NULL,
[Tax Rate] [decimal](18, 3) NOT NULL,
[Total Excluding Tax] [decimal](18, 2) NOT NULL,
[Tax Amount] [decimal](18, 2) NOT NULL,
[Total Including Tax] [decimal](18, 2) NOT NULL,
[Lineage Key] [int] NOT NULL,
INDEX CCI_fact_order_BIG_CCI_MEM_OPT CLUSTERED COLUMNSTORE)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
Note that a primary key is required on all memory-optimized tables. Now, this table can be loaded with test data:
INSERT INTO dbo.fact_order_BIG_CCI_MEM_OPT
SELECT
[Order Key] + (250000 * ([Day Number] +
([Calendar Month Number] * 31))) AS [Order Key]
,[City Key]
,[Customer Key]
,[Stock Item Key]
,[Order Date Key]
,[Picked Date Key]
,[Salesperson Key]
,[Picker Key]
,[WWI Order ID]
,[WWI Backorder ID]
,[Description]
,[Package]
,[Quantity]
,[Unit Price]
,[Tax Rate]
,[Total Excluding Tax]
,[Tax Amount]
,[Total Including Tax]
,[Lineage Key]
FROM Fact.[Order]
CROSS JOIN
Dimension.Date
WHERE Date.Date <= '2013-04-10';
This insert executes for about ten seconds on my local server and throws the following error:

Ouch! Reducing the date range should allow for a test data set to be created without running my server out of memory. To do this, ‘2013-04-10’ will be replaced with ‘2013-02-01’. The result is a table that can be queried like before using a test query:
SELECT
SUM([Quantity])
FROM dbo.fact_order_BIG_CCI_MEM_OPT
WHERE [Order Date Key] >= '2016-01-01'
AND [Order Date Key] < '2016-02-01';
The results are returned with zero IO:

As expected, querying a table that resides in memory results in zero reads. Despite that, it still takes time to read data from memory, and therefore this is not a freebie! Here is the storage footprint for the table:
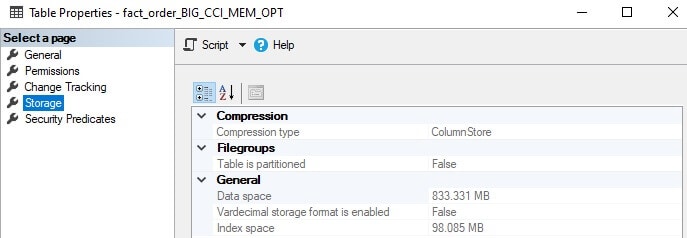
Another Ouch! More space is consumed for 15 days of data than for the entire clustered columnstore index implemented on disk earlier. While additional optimization is possible, the overhead for maintaining the primary key on the data is not cheap, and it is hard to justify this cost unless there will be other uses for the memory-optimized data as well.
Because a columnstore index is relatively small to start with, much of it can fit into the buffer cache and be available in memory to service queries against it. The memory-optimized columnstore index will need to outperform its counterpart when in the cache, which is possible, but less impressive.
While this can trigger a lengthy discussion of memory-optimized objects, we are better served by avoiding it as the benefits will be limited to highly niche cases that are out of the scope of a general columnstore index dive.
When considering a memory-optimized columnstore index, the following will assist in making a decision:
- Is speed currently acceptable? If so, do not put into memory.
- Is extra memory available for the table, if a memory-optimized option is chosen?
- Can the active partition be segregated and placed in memory and the rest of a table on disk?
- Can the table benefit from
SCHEMA_ONLYdurability? I.e., is the table disposable if the server is restarted? - Can testing validate that a memory-optimized table will perform significantly better?
Memory-optimized tables were built by Microsoft to specifically address the problem of highly concurrent OLTP workloads. One of the greatest selling points of memory-optimized tables is the elimination of locking, latching, and deadlocks. These should rarely be concerns for large OLAP workloads. With this in mind, putting a columnstore index into memory will rarely be worth the effort. In some special cases, it will provide speed boosts, but significant testing is needed to confirm this.
In addition, all of the various limitations imposed on memory-optimized objects apply here, which may also sway one’s opinion to use them. This page provides up-to-date details on what features are supported or not for memory-optimized tables:
Conclusion
The more I explored columnstore indexes, the more I appreciated them. Many of the optimizations and tweaks that can allow for OLAP data loads to be processed even faster are not well documented. Still, they can significantly improve the speed of data loads, archiving processes, and reporting. This is a feature that will continue to grow in popularity as data continues to grow and will add value to any organization that wants to maintain control over their reporting data.
There is no room here for “set it and forget it”. Implementing columnstore indexes should be treated with the same level of care as architecting new OLTP tables. The results will perform well, even for massive quantities of data. In addition, maintenance, upgrades, and software releases will be faster, easier, and less risky.
Columnstore is one of my favorite features in SQL Server. It has revitalized how OLAP data is stored and accessed, allowing for billions of rows of data to be efficiently stored and quickly accessed in ways that previously were challenging to achieve without moving data into other analytics tools. The biggest bonus of retaining OLAP data in SQL Server is that we (the developers, administrators, and analysts) can keep control over analytic data architecture and ensure optimal performance as organizational and software changes continually happen.
The post Hands-On with Columnstore Indexes: Part 3 Maintenance and Additional Options appeared first on Simple Talk.
from Simple Talk https://ift.tt/2WGTJxz
via
No comments:
Post a Comment