The #1 task that every DBA needs to be able to perform perfectly is to recover a database should it become corrupted for some reason. The recovery model of a database determines the options a DBA has when recovering a database. If a DBA can’t recover a database when a disaster strikes, then they better dust off their resume and start looking for a new line of work.
Part of a good database recovery plan is to first understand what recovery models are available. The recovery model of a database determines the types of database backups that can be taken, which in turn determines the different points in time in which a database can be restored.
Understanding the SQL Server Recovery Models
Each database within SQL Server has a recovery model setting. SQL Server has three different recovery models: Simple, Full, and Bulk-Logged. The recovery model setting determines what backup and restore options are available for a database, as well as how the database engine handles storing transaction log records in the transaction log.
The transaction log is a detailed log file that is used to record how the database is updated for each transaction. The SQL Server engine uses this log to maintain the integrity of the database. In the event that a transaction needs to be backed out, or the database crashes for some reason, the transaction log is used to restore the database to a consistent state. The recovery model for a database determines how much data the SQL Server engine needs to write to the transaction log, and whether or not a point-in-time restore can be performed. The initial recovery model setting for a new database is set based on the recovery model of the model system database. A database’s recovery model setting can be changed easily, by either using SSMS or TSQL code. To better understand the details of each one of these recovery models and how they affect the backup and restore options available, let me review each of the available recovery models.
Simple Recovery Model
The simple recovery model is the most basic of recovery models. When this recovery model is used, each transaction is still written to the transaction log. The transaction logs records will eventually be removed automatically when using the simple recovery model. That removal process happens for all completed transactions when a checkpoint occurs. Because log records are removed when a checkpoint occurs, transaction log backups are not supported when using the simple recovery model. This means point-in-time restores cannot be performed when a database has its recovery model set to SIMPLE. Because the transaction log is automatically cleaned up in this mode, this helps keep the transaction log small and from growing out of control.
With the simple recovery model, you can only perform full and differential backups. Because the simple recovery model doesn’t support using transaction log backups, you can only restore a database to the point-in-time when a full or differential backup has completed. If a database needs to support being restored to a point-in-time other than when a full or differential backup completes, then a different recovery model needs to be used.
Full Recovery Model
Just like it sounds, the full recovery model supports all the options for backing up and restoring a database. Just like the simple recovery model, all transactions are written to the transaction log, but unlike the simple recovery model, they stay in the transaction log after the transaction is completed. The transaction log records stay in the transaction log until a log backup is performed. When a transaction log backup is performed against a database that is in full recovery mode, the log records are written to the transaction log backup, and the completed transaction log records are removed from the transaction log.
Since every transaction is being written to the transaction log, the full recovery model supports point-in-time restores, meaning a database that is fully logged can be restored to any point in time. But it also means the transaction log needs to be big enough to support logging of all the transactions until a transaction log backup is run. If an application performs lots of transactions, there is the possibility that the transaction log will become full. When the transaction log becomes full, the database stops accepting transactions until a transaction log backup is taken, the transaction log is expanded, or the transaction log is truncated. Therefore, when a database uses the full recovery model, you need to ensure transaction log backups are taken frequently enough to remove the completed transactions from the transaction log before it fills up.
In addition to inserts and update transaction filling up the log, other operations like index create/alter and bulk load operations also write lots of information to the transaction log. If you find that your transaction log keeps filling up due to the index and bulk load operations (such as SELECT INTO), you might consider switching to the bulk-logged recovery model while these operations are being performed.
Bulk-Logged Recovery Model
The bulk-logged recovery model minimizes transaction log space usage when bulk-logged operations like BULK INSERT, SELECT INTO, or CREATE INDEX are executed. Bulk-logged recovery model functions similar to the full recovery model with the exception that transactions log records are minimally logged while bulk-logged operations are running. Minimal logging helps keep the log smaller, by not logging as much information.
Bulk-Logged recovery model improves the performance of large bulk loading operations by reducing the amount of logging performed. Additionally, because bulk-logged transactions are not fully logged, it reduces the amount of space written to the transaction log, which reduces the chance of the transaction log running out of space. Because bulk-logged operations are minimally logged, it affects point-in-time recoveries.
Point-in-time recoveries can still be performed when using the bulk-logged recovery model in some situations. If the database should become damaged while a minimal bulk-logged operation is being performed, the database can only be recovered to the last transaction log backup created prior to the first bulk-logged operation. When the transaction log backup contains a bulk logged operation the stopat options cannot be used. If no bulk-logged operations are performed at all while a database is using the bulk-logged recovery model, then you can still do a point-in-time restore just like you an in the full recovery model.
The bulk-logged recovery model is a great way to minimize transaction log space and improve the performance of large bulk update operations. But keep in mind, during the time a bulk-load operation has occurred, a point-in-time restore cannot be done. Therefore once the bulk-load operations are completed, a transaction log backup should be taken. By doing this, a point-in-time recovery can be made for transactions after this new transaction log backup is taken.
Which Recovery Model is being Used?
There are multiple ways to determine which recovery model is being used. One option is to use SQL Server Management Studio tool to find the recovery model of a database. To do this, first right-click on a database, then select the “Properties” item from the drop-down. Once the database properties are displayed, select the “Options” item from the left context menu. When this is done, the window in Figure 1 will display.
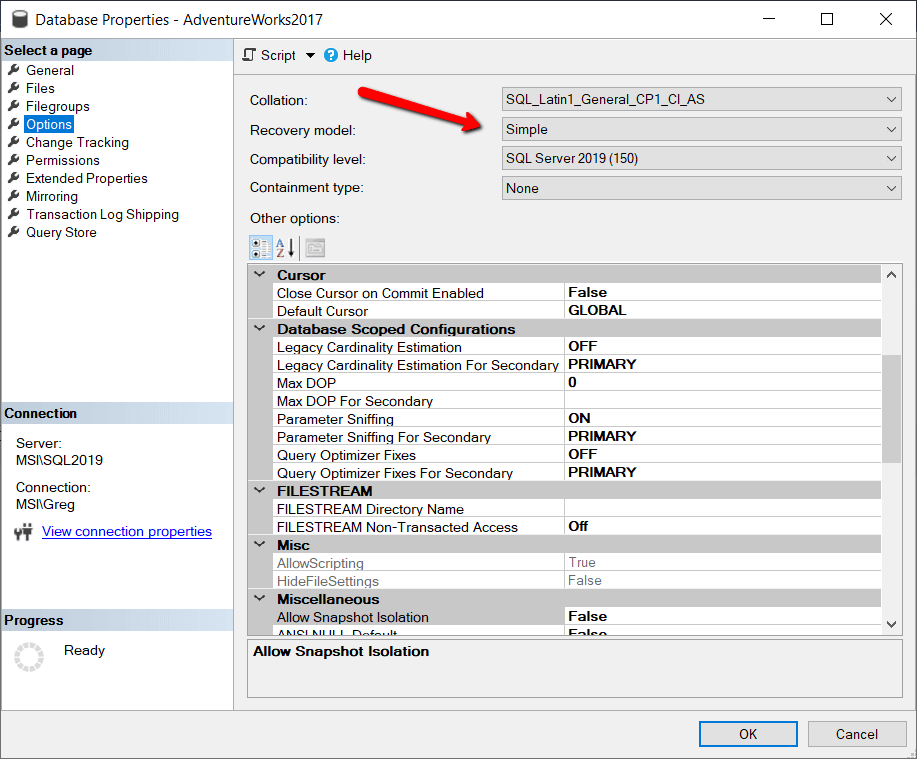
Figure 1: Recovery Model option
Figure 1 shows the Recovery Model setting of Simple for the AdventureWorks2017 database.
Another way to display the recovery options for a database is to run the TSQL code found in Listing 1.
Listing 1: Code to Display Recovery Model
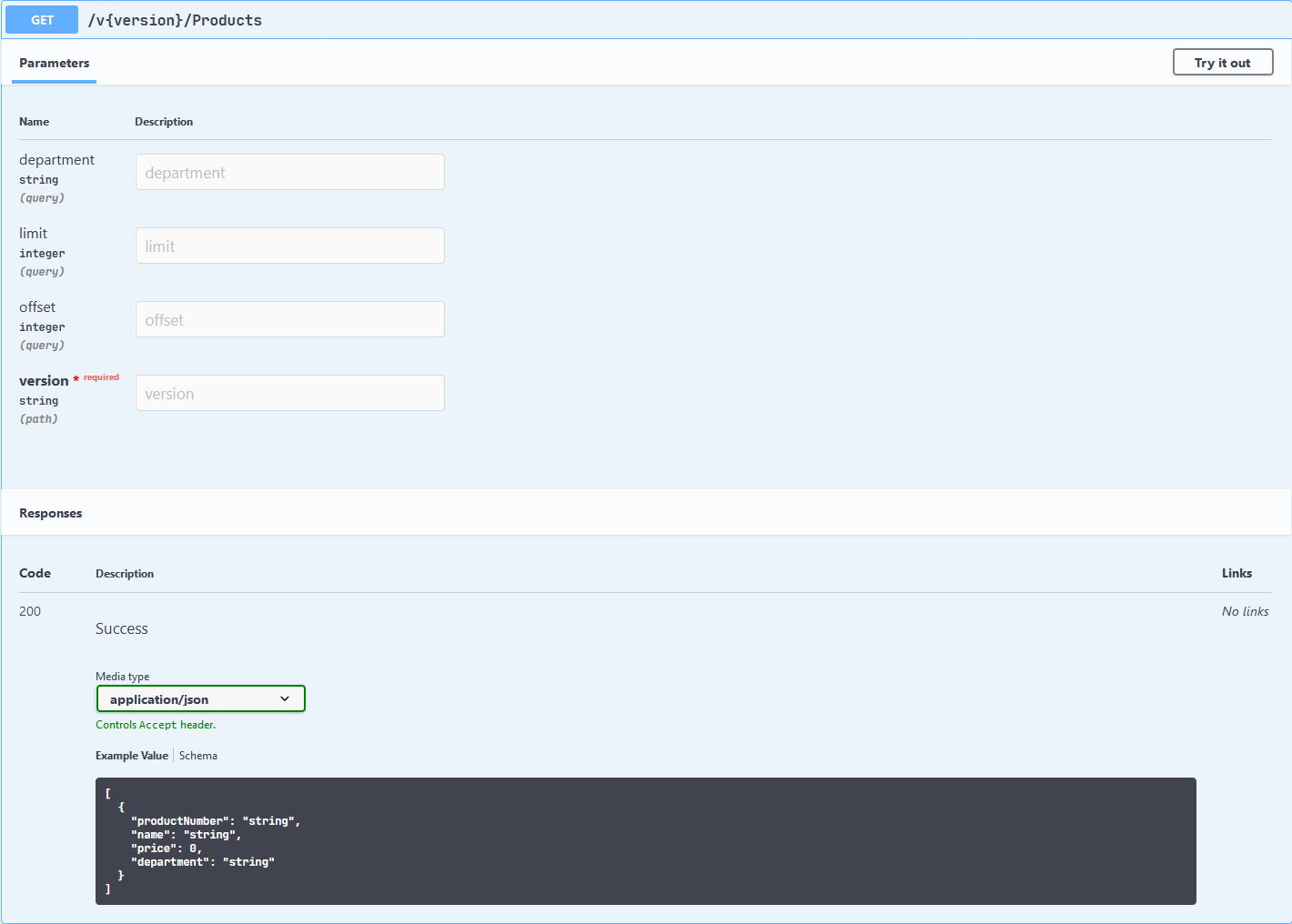
SELECT name, recovery_model_desc FROM sys.databases WHERE name = 'AdventureWorks2017' ;
Changing the Recovery Model
Over time the recovery model for a database might need to change. This might occur when an application requires more or fewer recovery options for a given database. If the recovery model needs to be changed, it can easily be changed by running the code in Listing 2.
Listing 2: Changing the recovery model with TSQL code
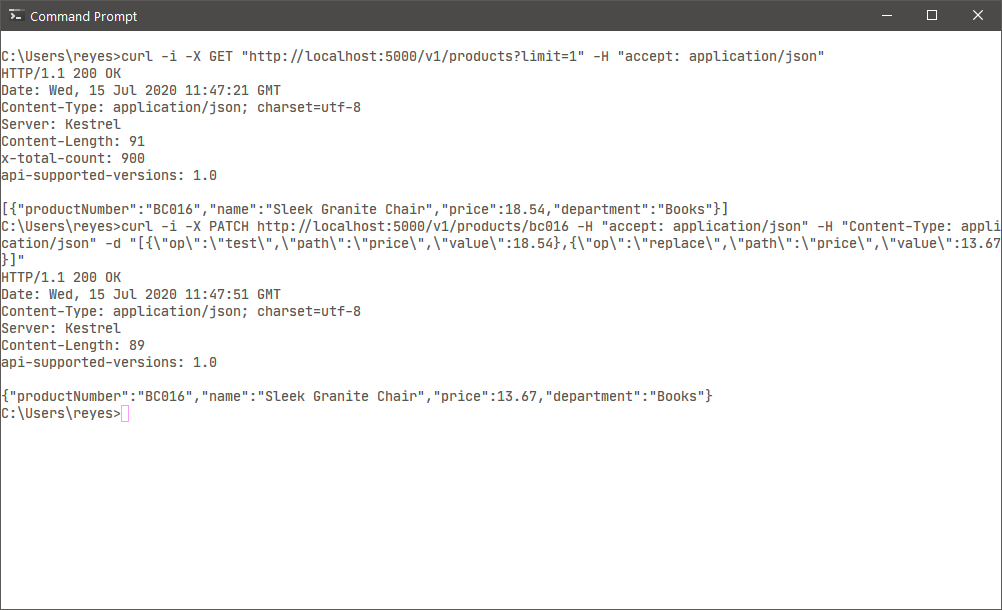
USE master; GO ALTER DATABASE AdventureWorks2017 SET RECOVERY FULL; GO
In Listing 2, the database recovery model of the AdventureWorks2017 database was changed to FULL. Additionally, the Database Properties page of SSMS, as shown in Figure 1, can be used to change the database recovery model of a database. To change the recovery model, just select the correct option for the Recovery Model field and then click on the OK button.
Restoring Databases Using Each Recovery Model
The recovery model determines the kind of backups that can be taken for a database, which in turn determines what options you have for recovering a corrupted database. Let me explore how each recovery model might affect the restore options for a common problem that occurs, which causes a database to become corrupted. The common problem I will explore is when a TSQL programmer incorrectly updates a database and then asks the DBA to restore the database to some point-in-time prior to the database being corrupted by the erroneous update process. In the real world, a DBA will more than likely be required to perform more database restores due to someone running code that corrupts a database than having a database become corrupt due to a hardware failure. In the sections below, I will explore at least one option that could be used to recover a corrupted database due to a programming error for each of the different recovery models.
Simple Recovery Model
When a database is using simple recovery model, you can use full backup or a full and a differential backup to restore a database when it becomes corrupted, like in the event of a programming error. Since transaction log backups cannot be taken while using the simple recovery model, no point-in-time recoveries can be performed except for the end of a differential if available. Therefore, to recover a corrupted database, you need to restore the full database backup and possibly a differential database back that was taken just prior to the corruption occurring. Restoring full and differential backups leave the database in the state it was in when the backups were taken. All updates performed to the database since these backups completed will be missing from the database along with the updates performed by the programming error.
Full Recovery Model
Unlike the simple recovery model, the full recovery model offers multiple ways to recover from a bad update or deletion corrupting the database. The first option is to use the last full backup. If the full backup is used, then the recovered database would lose the same amount of updates as the simple recovery model restore in the prior section.
Another option is to use the point-in-time recovery options available with the full recovery model. Doing a point-in-time recovery means a DBA can recover the database to the point-in-time (to the minute) just before the erroneous update statements were performed. Any updates that were done to the database after the full backup but before the restore point will not be lost, unlike when using the simple recovery model.
In order to restore a database to a point in time after the full backup, a database needs at least one transaction log backup taken after the full backup. If a transaction log has not been taken prior to the corruption occurring, then the only option to remove the database corruption would be to restore the database using only the last full backup. In this case, the amount of data loss would be the same as the simple recovery model.
Keep in mind other options could be used to restore to a point-in-time after the full backup. One of those options would be to use a differential backup. A differential backup is a backup that contains all the changes to a database since the last full backup.
Bulk-Logged Recovery Model
Just like with the full recovery model, the bulk-logged recovery model does support point-in-time restores, as long as the point in time of the recovery is not contained within a transaction log backup that contains a bulk-logged operation. Therefore, if a database gets corrupted by a programming error while using the bulk-logged recovery model, a DBA could still recover the database as long as the corruption occurs before or after the transaction log backup that contains a bulk-logged operation. If the update does occur while a bulk-logged operation is being performed, then the best a DBA can do is to restore to the point-in-time of the last transaction log backup taken prior to the bulk-logged operation. Even though a DBA might not be able to restore to any point in time covered by a transaction log backup when the transaction log backup contains a bulk-logged operation, at least they are able to perform point-in-time recoveries as long as the transaction log doesn’t contain any bulk-logged operations.
Recovery Models
The recovery model of a database determines what backup/restore options are available. It also tells SQL Server how the transaction log should be managed. The recovery model also determines what recovery options are available for a database. With the simple recovery model, the only point that a database can be restored to is the last full backup or a differential. Whereas the full and bulk-logged recovery models allow a database to be recovered to a point after the full backup using a point-in-time restore. It is important to make sure each database on an instance has the appropriate recovery model setting based on the backup and restore requirements of the applications that use a database. Only by understanding the application backup and recovery requirements can the recovery model be set appropriately. If you want to understand more about backups and recovering a database using the different recovery models then, I’d suggest you consider reading about backup and restore options available in the Microsoft documentation that can be found here.
The post Understanding SQL Server Recovery Models appeared first on Simple Talk.
from Simple Talk https://ift.tt/3jk5rHg
via