The series so far:
- Heaps in SQL Server: Part 1 The Basics
- Heaps in SQL Server: Part 2 Optimizing Reads
- Heaps in SQL Server: Part 3 Nonclustered Indexes
The previous article Heaps in SQL Server: Part 2 Optimizing Reads described how performance could be optimized for selecting data from a heap. This article describes the possibility of achieving optimal query times for heaps with the help of nonclustered indexes.
Nonclustered Index
A nonclustered index is an index structure that is separate from the data in the table. In this way, data can be found faster than with a search of the underlying table. In general, nonclustered indexes are created to improve the performance of frequently used queries that are not covered by the clustered index or heap.
Demonstration
Since a heap does not sort data according to a key attribute, a nonclustered index can only form a reference by using the position of the data record in the heap. The position of a data record in a heap is determined by three pieces of information:
- File number
- Data page
- Slot
These three pieces of information are stored as a reference in each Nonclustered index for the actual key of the index.
To follow along with the demos, see the article Heaps in SQL Server: Part 2 Optimizing Reads. A table with approximately 4,000,000 data records is used.
This table is very often accessed by users to display orders for a specific period. Since there is no index on the [OrderDate] attribute, a table scan must always be carried out.
SELECT * FROM dbo.CustomerOrderList WHERE OrderDate = '20081220' OPTION (QUERYTRACEON 9130); GO
A table scan is used, as shown in the execution plan in Figure 1.
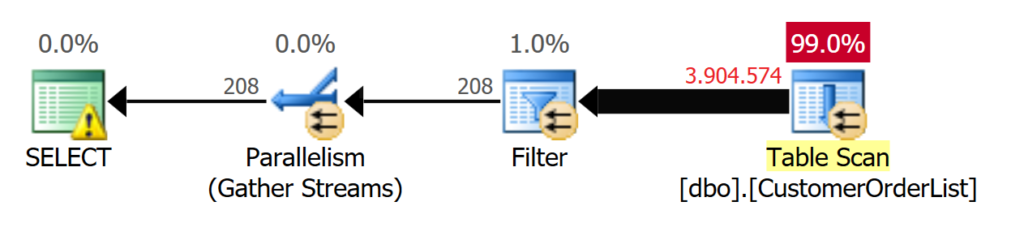
Figure 1: A TABLE SCAN is used for 208 records
The table scan may be sufficient on fast systems (0.716 seconds), and the programmer might be inclined to accept this time interval.
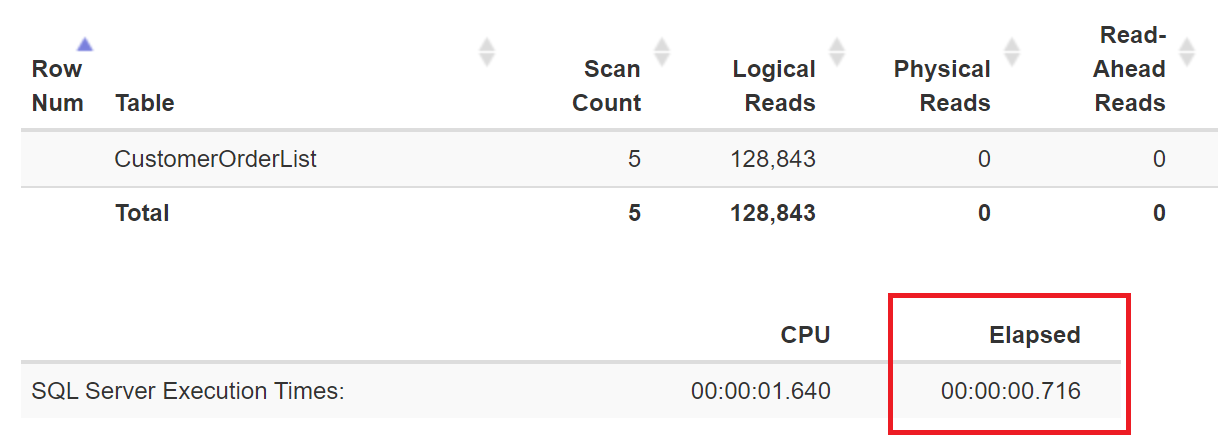
Figure 2: more than 1.6 seconds used on the CPU and 0.716 seconds elapsed
The high CPU time is due to the fact that the query uses parallel execution shown in Figure 3.
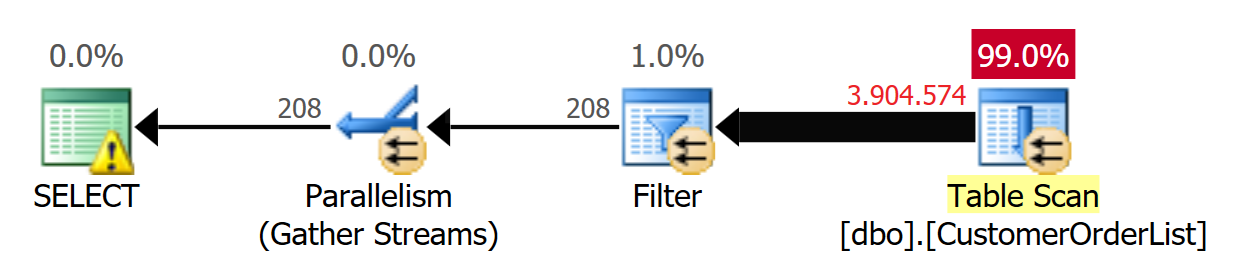
Figure 3: A parallel plan
Unfortunately, the following things are often disregarded, which are relevant regardless of the time:
- The query parallelizes and consumes the CPUs configured for MAXDOP!
- A [SCH-S] lock is kept on the table during the runtime! (See this article)
- What happens if not only one user runs the query, but there is also a web client running thousands of queries in parallel?
For the reasons mentioned above, it is advisable to optimize the query. To optimize the query, a Nonclustered index is created for the [OrderDate] attribute.
CREATE NONCLUSTERED INDEX nix_CustomerOrderList_OrderDate ON dbo.CustomerOrderList (OrderDate); GO
If you rerun the same query as in the previous example, you will get the following improvements shown in Figure 4:
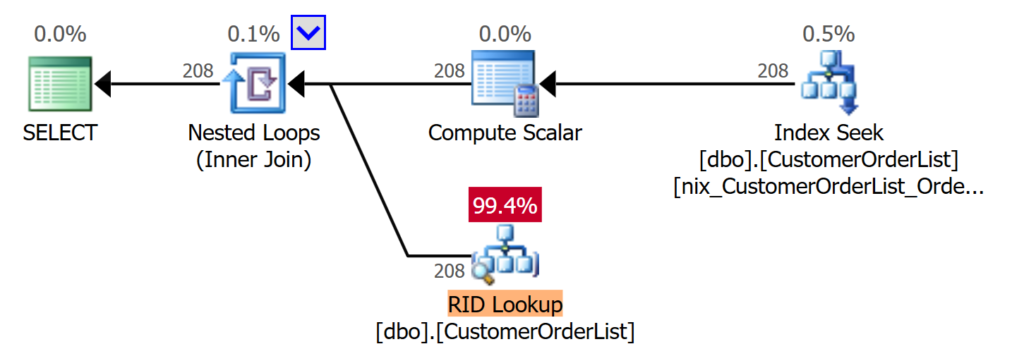
Figure 4: Less I/O by the usage of an appropriate index
Now the query no longer scans the table, and the elapsed time has also decreased dramatically as shown in Figure 5:
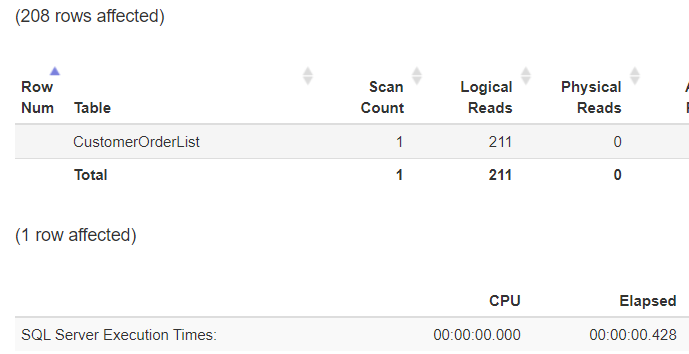
Figure 5: No excessive use of resources
Some of the disadvantages of a table scan have been eliminated by using an index:
- The query no longer parallelizes because the costs have dropped below the threshold for parallelization
- The CPU resources can no longer be measured
- Only the [SCH-S] lock is still used; however, concerning the runtime – maybe – it can be ignored.
One can say that nonclustered indexes for heaps can be of great advantage!
Internal structures
A Nonclustered Index (NCI) must ALWAYS store a reference to the record in the table. Since an NCI generally only contains a few attributes of the table, it must be ensured that attributes that are not used in the NCI can be determined from the table at any time. This reference is stored in a heap as RID (RowLocatorID) and has a size of 8 bytes!
Based on the demonstration above, the query took a total of 211 I/O’s to retrieve the data. If you look at the execution plan, you can see the use of the previously created index. Each index uses a tree structure with a reference to the next level. This means that data in an index can be searched quickly and efficiently. Figure 6 shows the index structure.
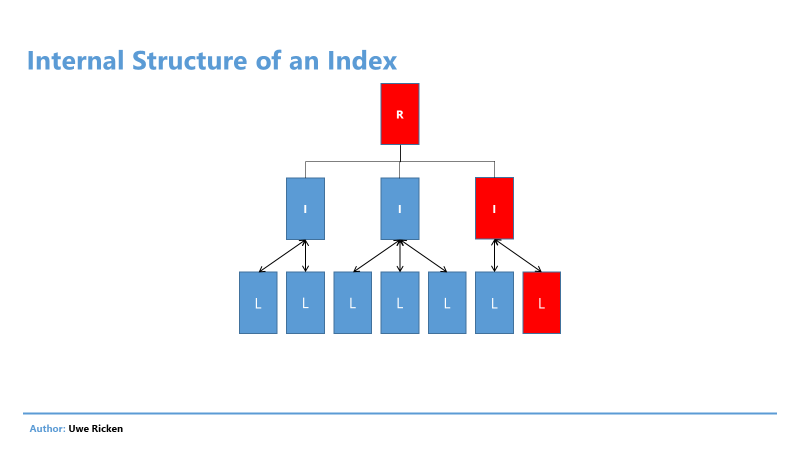
Figure 6: Lookup in B-Tree-Structure of an Index
A look at the index reveals this structure. To do this, the data page that represents the root node must first be determined.
-- Get the information about the root node of the index
SELECT P.index_id,
SIAU.total_pages,
SIAU.used_pages,
SIAU.data_pages,
SIAU.root_page,
sys.fn_PhysLocFormatter(SIAU.root_page) AS root_page
FROM sys.system_internals_allocation_units AS SIAU
INNER JOIN sys.partitions AS P
ON (SIAU.container_id = P.partition_id)
WHERE P.object_id = OBJECT_ID(N'dbo.CustomerOrderList', N'U');
GO
Get detailed information on index structures by using a system dmv to reveal the secrets as shown in Figure 7. Keep in mind that indexes with the ID = 0 or ID = 1 represent the table itself! ID = 0 is a Heap while ID = 1 represents a Clustered Index. Any other indexes are nonclustered.

Figure 7: The indexes
The root node of the index [nix_CustomerOrderList_OrderDate] is in file # 1 on data page 73.346. The content of the data page can be examined with the undocumented command DBCC PAGE.
DBCC TRACEON (3604); DBCC PAGE (0, 1, 73346, 3); GO
You can see that the index only uses the attributes specified when it was created. All other attributes must be read from the table itself!

Figure 8: The search for 2008-12-20 must continue on page 73.348
To search for orders on December 20, 2008, the attribute [OrderDate] must be used to search for the limit in which the searched date is located. The search continues in the next level on page 73.348 until the lowest level is reached.
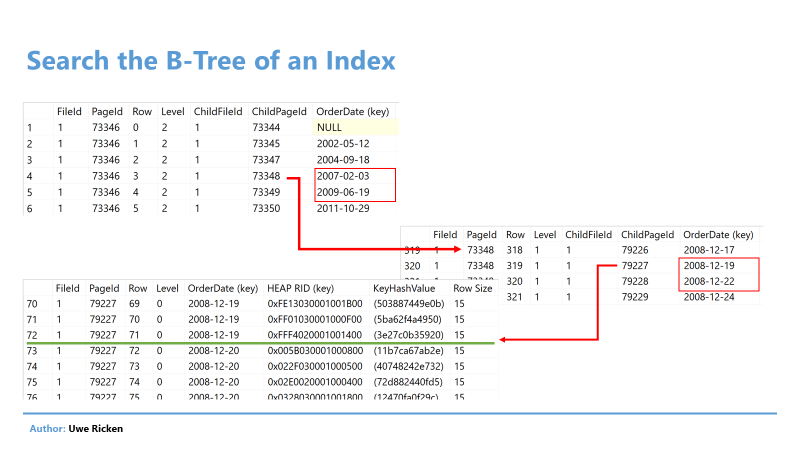
Figure 9: With 3 I/O you reach the first entry in the index
Actually, three I/O have been consumed. Considering the total number of I/O of 211, it quickly becomes clear what will happen in the next step. Since the index only stores the [OrderDate] attribute, the information of the other attributes for the data record is missing. To get this information, Microsoft SQL Server has to decode the RID to get to the data page where the record is located.
The RID is stored in the index for EVERY record and has a fixed length of 8 bytes. These 8 bytes contain all the relevant information to get to the data record.

Figure 10: Position of the data set as RID
|
Position |
Hex-Value |
shifted |
Decimal-Value |
|
Byte 1 – 4: Page |
0x005B0300 |
0x00 03 5B 00 |
219.904 |
|
Byte 5 – 6: File |
0x0100 |
0x00 01 |
1 |
|
Byte 7 – 8: Slot |
0x0800 |
0x00 08 |
8 |
The record whose [OrderDate] is represented in the index is in file #1 on data page #219.904 in slot #8.
DBCC PAGE (0, 1, 219904, 3) WITH TABLERESULTS; GO
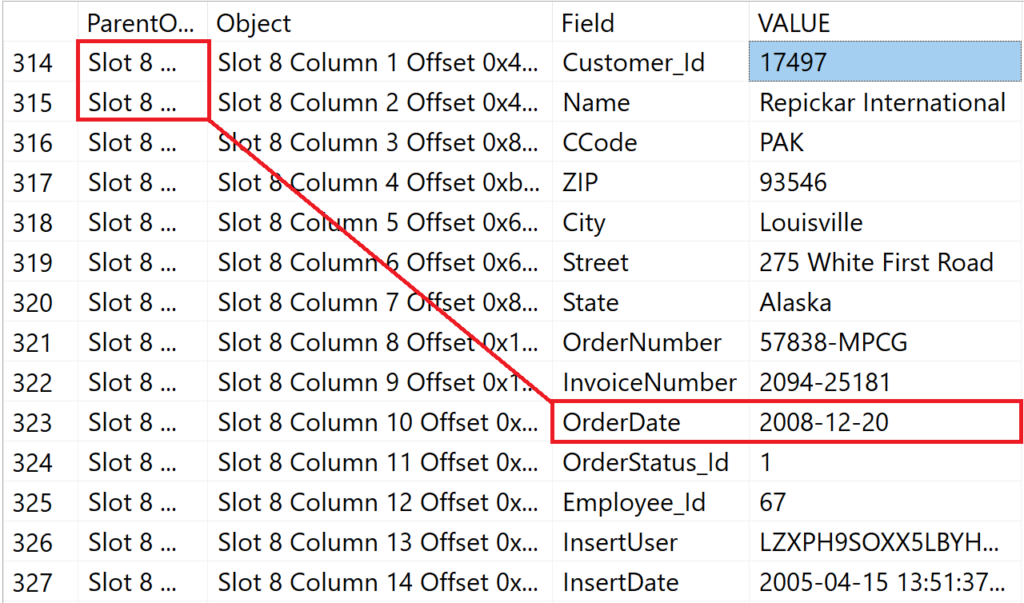
Figure 11: Contents of slot #8
The process is repeated for each record found from the index. So, the math behind the result of 211 is quite trivial: 3 I/O for the search in the index + 208 * 1 I/O for the reference in the table itself.
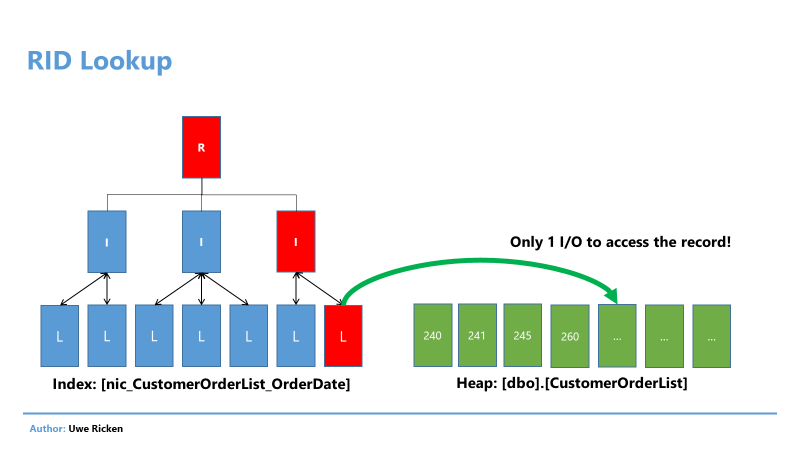
Figure 12: Access to Heap by RID
RID lookup vs. Key lookup
Contrary to a heap, Microsoft SQL Server cannot refer directly to the data page in which the record is located in the table with a clustered index. With a Clustered Index Microsoft SQL Server does not save the position of the data record in an NCI for a table with a grouped index, but the value of the key attribute of the clustered index.
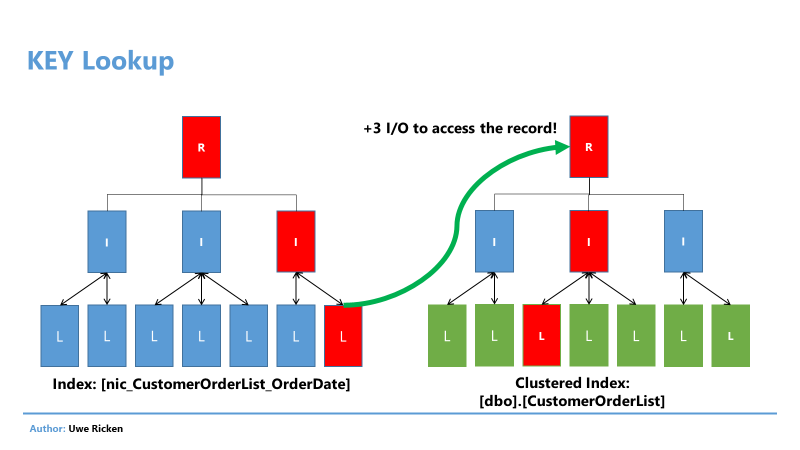
Figure 13: Additional I/O by the use of a clustered index
The advantage of using the clustered index is the maintenance of indexes rather than the performance of queries (described in a later article). Comparing the same query for a Heap with a query for a clustered index reveals the following differences in the execution plan:
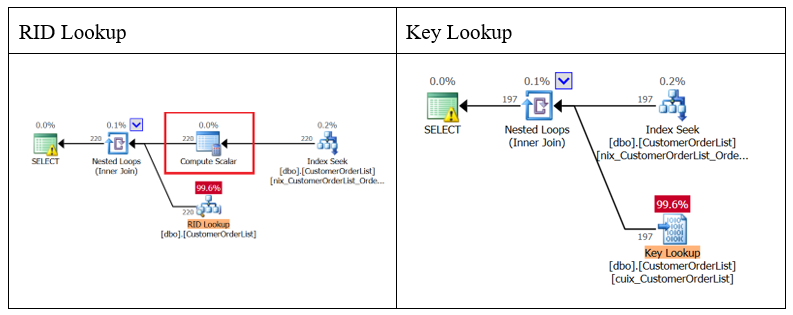
Figure 14: RID vs. Key Lookup execution plans
With a RID lookup, the RowLocatorID must be converted, which leads to a – supposedly – higher CPU load. One of the biggest problems in Microsoft SQL Server execution plans is estimating the cost of a SCALAR operation. By default, they are calculated at 0%; however, it will forget that the operator for EVERY record must be run from the previous operator.
In order to make a well-founded statement about the cost of the conversion, the following code is executed with SQLQueryStress by Adam Machanic (b | t) with four threads (number of CPU in the test machine):
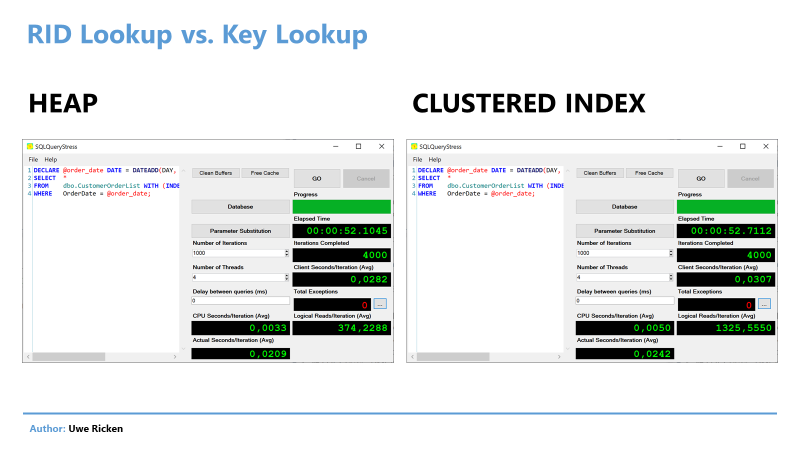
Figure 15: Heap vs Clustered index performance
In a direct comparison, the heap “wins” in all disciplines. Particularly interesting in this comparison is the fact that the CPU load of 3.3 ms/iteration is significantly behind the CPU load of the clustered index of 5 ms.
Another – not to be underestimated – difference is the I/O per iteration. Of course, the heap can score here because it requires one I/O each to access the table; there are 3 I/O in the clustered index.
Summary
Why do developers from the Microsoft SQL Server environment so much resist heaps? Many blog articles by renowned SQL Server experts repeatedly point out that it would be advantageous to provide a table with a clustered index. In the past, I always followed these recommendations until I read two articles that made me “rethink”:
|
Author |
Article |
|
Markus Wienand |
|
|
Thomas Kejser |
I can only suggest rethinking the “general” approach to using clustered indexes. I do not want to deny that there are situations in which a clustered index makes sense and is also mandatory; it’s definitely not required for pure SELECT operations. The principle when choosing data is to index the attributes that are used as predicate and / or as JOIN operators.
The post Heaps in SQL Server: Part 3 Nonclustered Indexes appeared first on Simple Talk.
from Simple Talk https://ift.tt/2FCrGtm
via
No comments:
Post a Comment