SQL Server computed columns provide a handy tool for building expressions into table definitions. Still, they can also lead to performance woes, especially as expressions become more complex, applications more demanding, and data sets grow larger by the minute.
A computed column is a virtual column whose value is calculated from other values in the table. By default, the expression’s outputted value is not physically stored. Instead, SQL Server runs the expression when the column is queried and returns the value as part of the result set. Although this puts more burden on the processor, it also reduces the amount of data that needs to be stored or modified when the table is updated.
In many cases, non-persistent computed columns put too much burden on the processor, resulting in slower queries and unresponsive applications. Fortunately, SQL Server provides several strategies for improving computed column performance. You can create persisted computed columns, index the computed columns, or do both.
In this article, I walk you through the process of applying these strategies so you have a better sense of the available options. For the examples, I created four similar tables and populated them with identical data, which comes from the WideWorldImporters sample database. Each table includes the same computed column, with the column persisted in two tables and indexed in two tables, resulting in the following mix:
- The Orders1 table includes a non-persisted computed column.
- The Orders2 table includes a persisted computed column.
- The Orders3 table includes an indexed, non-persisted computed column.
- The Orders4 table includes an indexed, persisted computed column.
For each table, I show you the execution plan that’s generated when querying the computed column. The column’s expression is a relatively simple one, and the data set very small. Even so, this should be enough to demonstrate the principles of creating persistent and indexed computed columns and how they can help address performance-related issues.
Creating a Non-Persisted Computed Column
Depending on your queries, you might want to use a non-persisted computed column to avoid storing data or generating indexes, or you might want to create the column as non-deterministic. For example, SQL Server will assess a scalar user-defined function (UDF) as non-deterministic if the function definition does not include the WITH SCHEMABINDING clause. In some cases, you might want to this type of function for a computed column. If you try to create a persisted computed column using the UDF, the query engine will return an error message stating that the column cannot be created, in which case, you can stick with a non-persisted column.
It should be noted, however, that UDFs present their own performance challenges. If a table contains a computed column and that column contains a UDF, the query engine will not use parallelism unless you’re running SQL Server 2019. This is true even if the computed column is not referenced in the query. For a large data set, this can bring the query to its knees. A UDF can also slow updates and impact how the optimizer assigns costs to the computed column. That’s not to say you should never use a UDF in a computed column, but you should definitely proceed with caution.
Whether or not you use a UDF, the process of creating a non-persisted computed column is fairly straightforward. The following CREATE TABLE statement defines the Orders1 table, which includes the Cost computed column.
USE WideWorldImporters; GO DROP TABLE IF EXISTS Orders1; GO CREATE TABLE Orders1( LineID int IDENTITY PRIMARY KEY, ItemID int NOT NULL, Quantity int NOT NULL, Price decimal(18, 2) NOT NULL, Profit decimal(18, 2) NOT NULL, Cost AS (Quantity * Price - Profit)); INSERT INTO Orders1 (ItemID, Quantity, Price, Profit) SELECT StockItemID, Quantity, UnitPrice, LineProfit FROM Sales.InvoiceLines WHERE UnitPrice IS NOT NULL ORDER BY InvoiceLineID;
To define a computed column, specify the column name, followed by the AS keyword and then the expression. In this case, the expression multiplies that Quantity column by Price column and then subtracts the Profit column. After the table is created, the INSERT statement populates it, using data from the Sales.InvoiceLines table in the WideWorldImporters database. You can then run the following SELECT statement.
SELECT ItemID, Cost FROM Orders1 WHERE Cost >= 1000;
The statement should return 22,973 rows or whatever you have in your WideWorldImporters database. When I ran the statement in SQL Server Management Studio (SSMS), I also generated the actual execution plan, shown in Figure 1.
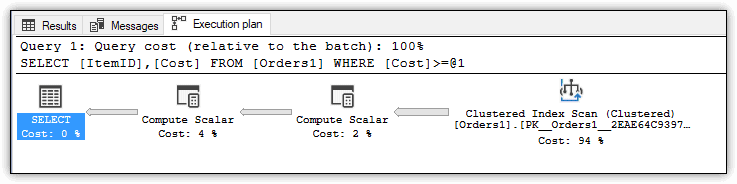
Figure 1. Execution plan for the query against the Orders1 table
The first thing to notice is that the query engine performed a clustered index scan, which is not the most efficient way to get at the target data. But this is not the only issue. If you open the properties for the Clustered Index Scan step, you can view the number of logical reads, as shown in Figure 2. To access the properties, right-click the step and click Properties. (If you don’t see the Logical Reads, upgrade to the latest SSMS version.)
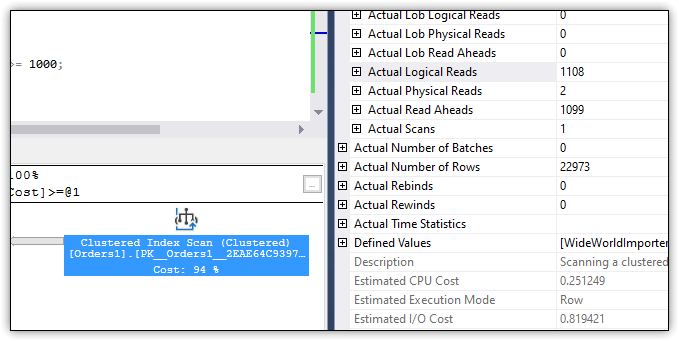
Figure 2. Logical reads for the query against the Orders1 table
The number of logical reads—in this case, 1108—is the number of pages that the query engine read from the data cache. The goal is to try to reduce this number as much as possible. For this reason, it’s good to keep this number in mind when comparing different methods of implementing a computed column—that and the fact that the query engine performed a clustered index scan.
You can also retrieve the number of logical reads by running a SET STATISTICS IO ON statement before running the SELECT statement. If you want to view the CPU and elapsed times, you can also run a SET STATISTICS TIME ON statement, or you can access the times through the properties for the SELECT step.
One other item worth noting is that the execution plan also shows two Compute Scaler steps. The first one (the one to the right) is the step taken by the query engine to run the computed column expression for each returned row. Because the column values are computed on the fly, you cannot avoid this step with a non-persisted computed column, unless you index that column.
In some cases, a non-persisted computed column will provide the performance you need without resorting to persistence or indexes. Not only does this save you storage space, but it also avoids the overhead that comes with updating computed values in the table or index. More often than not, however, a non-persisted computed column will lead to performance issues, in which case, you better start looking for an alternative.
Creating a Persisted Computed Column
One method commonly used to address performance issues is to define the computed column as persisted. With this approach, the expression is precalculated and its outputted values stored with the rest of the table data.
To qualify for persistence, the column must be deterministic; that is, the expression must always return the same results when given the same input. For example, you cannot use the GETDATE function in the column’s expression because the returned value is always changing.
To create a persisted computed column, you need to add the PERSISTED keyword to your column definition, as shown in the following CREATE TABLE statement.
DROP TABLE IF EXISTS Orders2; GO CREATE TABLE Orders2( LineID int IDENTITY PRIMARY KEY, ItemID int NOT NULL, Quantity int NOT NULL, Price decimal(18, 2) NOT NULL, Profit decimal(18, 2) NOT NULL, Cost AS (Quantity * Price - Profit) PERSISTED); INSERT INTO Orders2 (ItemID, Quantity, Price, Profit) SELECT StockItemID, Quantity, UnitPrice, LineProfit FROM Sales.InvoiceLines WHERE UnitPrice IS NOT NULL ORDER BY InvoiceLineID;
The Orders2 table is nearly identical to Orders1, except that the Cost column includes the PERSISTED keyword. SQL Server will automatically populate the column when adding rows and update the column when modifying rows. Of course, this means that the Orders2 table will store more data than Orders1, which you can verify by running the sp_spaceused system stored procedure.
sp_spaceused 'Orders1'; GO sp_spaceused 'Orders2'; GO
Figure 3 shows the data returned by the stored procedure. The amount of data in the Orders1 table is 8824 KB, and the amount of data in the Orders2 table is 12,936 KB, an extra 4112 KB to accommodate the computed values.
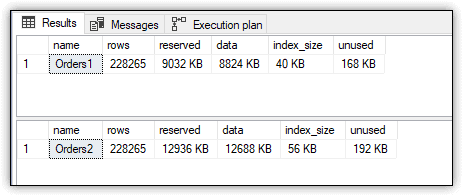
Figure 3. Comparing Orders1 and Orders2 space usage
Although these examples are based on a fairly small data set, you can see how the amount of stored data can quickly add up. However, this can be worth the trade-off if it boosts performance.
To see how performance might differ in this case, run the following SELECT statement.
SELECT ItemID, Cost FROM Orders2 WHERE Cost >= 1000;
The statement is the same one I ran against the Orders1 table (except for the name change). When I ran this statement, I again generated an execution plan, which is shown in Figure 4.
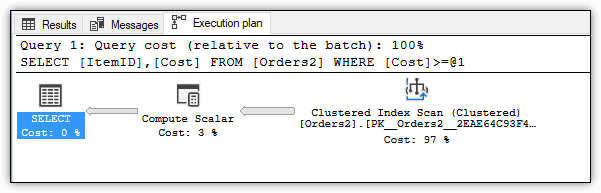
Figure 4. Execution plan for the query against the Orders2 table
Once more, the query engine starts with a clustered index scan. This time, however, there is only one Compute Scaler step because the computed column values no longer need to be calculated at runtime. In general, the fewer the steps, the better, although that’s far from being an absolute.
The second query generates 1593 logical reads, up 485 from the first table’s 1108 reads. Even so, it generally runs faster than the first query, but only by around 100 ms, sometimes much less. The CPU time is also faster, but this too is not by much. You’d likely see a much bigger difference if there were more data and more complex calculations.
Creating an Index on a Non-Persisted Computed Column
Another method that’s commonly used to improve a computed column’s performance is to index the column if you can work around the restrictions. To qualify for indexing, the column must be deterministic, and it must be precise, which means that the expression cannot use float or real data types (unless the column is also persisted). There are also other data type limitations, as well as SET option limitations. For a complete rundown on restrictions, refer to the SQL Server help topic Indexes on Computed Columns.
You can verify whether a non-persisted computed column is suitable for indexing by viewing the column’s properties. The following SELECT statement uses the COLUMNPROPERTY function to return the status of several properties of the Cost column in the Orders1 table. The properties include IsDeterministic, IsIndexable, and IsPrecise, which should all be self-explanatory.
DECLARE @id int = OBJECT_ID('dbo.Orders1')
SELECT
COLUMNPROPERTY(@id,'Cost','IsDeterministic') AS 'Deterministic',
COLUMNPROPERTY(@id,'Cost','IsIndexable') AS 'Indexable',
COLUMNPROPERTY(@id,'Cost','IsPrecise') AS 'Precise';
The SELECT statement should return a value of 1 for each property to confirm that the computed column can be indexed, as shown in Figure 5.
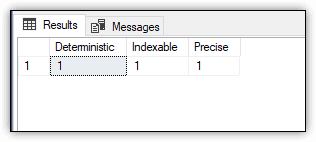
Figure 5. Verifying index suitability
After you verify eligibility, you can create a nonclustered index on that column. For this article, instead of updating the Orders1 table, I created a third table—Orders3—and included the index in the table definition, as shown in the following CREATE TABLE statement.
DROP TABLE IF EXISTS Orders3; GO CREATE TABLE Orders3( LineID int IDENTITY PRIMARY KEY, ItemID int NOT NULL, Quantity int NOT NULL, Price decimal(18, 2) NOT NULL, Profit decimal(18, 2) NOT NULL, Cost AS (Quantity * Price - Profit), INDEX ix_cost3 NONCLUSTERED (Cost, ItemID)); INSERT INTO Orders3 (ItemID, Quantity, Price, Profit) SELECT StockItemID, Quantity, UnitPrice, LineProfit FROM Sales.InvoiceLines WHERE UnitPrice IS NOT NULL ORDER BY InvoiceLineID;
I created a nonclustered covering index that includes the ItemID and Cost columns, the two columns in the query’s select list. After you build and populate the table and index, you can then run the following SELECT statement, which is similar to the previous examples.
SELECT ItemID, Cost FROM Orders3 WHERE Cost >= 1000;
Figure 6 shows the execution plan for this query, which is now using the ix_cost3 nonclustered index, rather than performing a clustered index scan.
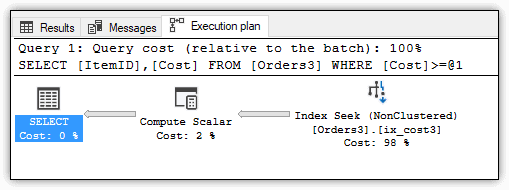
Figure 6. Execution plan for the query against the Orders3 table
If you view the properties for the Index Scan step, you’ll discover that the query now performs only 92 logical reads, and if you view the properties for the SELECT step, you should find that the CPU and elapsed times are lower. The difference isn’t significant, but again, this is a small data set.
Another item worth noting is that the execution plan does not include two Compute Scaler steps as you saw in the first query. Because the computed column is indexed, the values have already been calculated. This eliminates the need to calculate the values at runtime, even though the column has not been persisted (at least not directly).
Creating an Index on a Persisted Computed Column
You can also create an index on a persisted computed column. Although it means adding data and maintaining an index, there are some circumstances when doing both might be useful. For example, you can create an index on a persisted computed column even if it uses float or real data types. This approach can also be useful when working with CLR functions and the query engine can’t verify whether they’re deterministic or precise.
The following CREATE TABLE statement creates the Orders4 table. The table definition includes both the persisted Cost column and the ix_cost4 nonclustered covering index.
DROP TABLE IF EXISTS Orders4; GO CREATE TABLE Orders4( LineID int IDENTITY PRIMARY KEY, ItemID int NOT NULL, Quantity int NOT NULL, Price decimal(18, 2) NOT NULL, Profit decimal(18, 2) NOT NULL, Cost AS (Quantity * Price - Profit) PERSISTED, INDEX ix_cost4 NONCLUSTERED (Cost, ItemID)); INSERT INTO Orders4 (ItemID, Quantity, Price, Profit) SELECT StockItemID, Quantity, UnitPrice, LineProfit FROM Sales.InvoiceLines WHERE UnitPrice IS NOT NULL ORDER BY InvoiceLineID;
Once the table and index have been created and populated, you can run the following SELECT statement, which is the same one used in the previous examples.
SELECT ItemID, Cost FROM Orders4 WHERE Cost >= 1000;
Figure 7 shows the execution plan that the query engine used to retrieve the data. As with the previous example, the query starts with a nonclustered index seek.
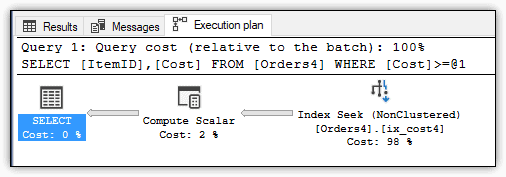
Figure 7. Execution plan for the query against the Orders4 table
This query also performs only 92 logical reads, just like the previous one, resulting in fairly similar performance. The main difference between these two computed columns—and between the indexed and non-indexed columns—is the amount of storage and index space they use, which you can verify by running the sp_spaceused stored procedure.
sp_spaceused 'Orders1'; GO sp_spaceused 'Orders2'; GO sp_spaceused 'Orders3'; GO sp_spaceused 'Orders4'; GO
Figure 8 shows the results generated by the four statements. As expected, the persisted computed columns store more data, and the indexed columns create larger indexes.
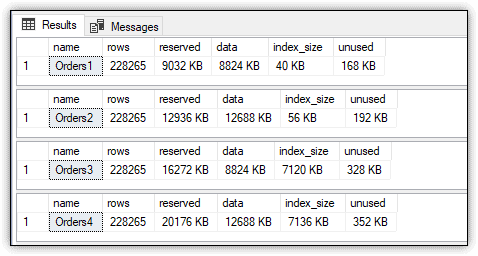
Figure 8. Comparing space usage for all four tables
Chances are, you won’t index persisted computed columns unless you have an overriding reason to do so. As with many database decisions, your choice will likely be based on your queries and the nature of your data.
Working with SQL Server Computed Columns
A computed column is not your typical table column and must be handled carefully to ensure that its implementation doesn’t degrade application performance. Most performance issues can be resolved by either persisting or indexing the column, but either approach must be weighed against the additional disk storage and how data is being updated. When data is modified, the computed column values must be updated in the table or index—or both if you’ve indexed a persisted computed column. You’ll have to take it on a case-by-case basis to determine which strategy best fits your requirements, but chances are, you’ll be doing one or the other.
The post Computed Column Performance in SQL Server appeared first on Simple Talk.
from Simple Talk https://ift.tt/2Zq9L0a
via
No comments:
Post a Comment