Organizations are under greater pressure than ever to deliver applications faster and more efficiently. One approach they’ve taken to improve delivery is lean software development, an application delivery methodology that focuses on minimizing waste and increasing efficiency. Another approach is DevOps, which bridges the gap between development and operations in order to deliver software faster, more frequently, and more reliably. DevOps is often considered both a philosophy and practice that includes the tools necessary for application delivery.
DevOps has been described as an evolution of Agile methodology, an approach similar in many ways to lean software development. DevOps has also been portrayed as a type of lean development system that merges development and operations into a unified effort.
The relationship between DevOps and lean software development has been explained in other ways as well, but the two remain separate disciplines (just like Agile). However, DevOps and lean development share similar goals and can effectively complement each other. In fact, when used together, DevOps and lean software development can provide an organization with many important business benefits.
Lean software development
Lean software development has its roots in the Toyota Production System, an approach to automobile manufacturing that focused on minimizing waste, optimizing production, and increasing customer value. In 1993, Dr. Robert Charette co-opted the Toyota approach by introducing the concept of lean software development, focusing on risk reduction and building solutions for customer use.
Ten years later, Mary Poppendieck and Tom Poppendieck published their seminal book Lean Software Development: An Agile Toolkit. The book further formalized the concept of lean application delivery, adopting the same philosophy that revolutionized manufacturing. In their book, the authors outlined seven key principles for how to approach lean software development:
- Eliminate waste. Waste includes anything that doesn’t directly add customer value or add knowledge about how to more effectively deliver that value. Waste can refer to unnecessary features, duplicate efforts, inefficient processes or other unproductive practices.
- Amplify learning. Software development should be treated as an ongoing learning process that’s available to all team members. Learning can take many forms, such as training, code reviews, project documentation, pair programming, or knowledge sharing.
- Decide as late as possible. Software development requires a flexible mindset that encourages team members to keep their options open until they’ve gathered the data necessary to make proper decisions. And the longer they wait, the more informed those decisions. Deciding late also makes it easier to accommodate new and evolving circumstances.
- Deliver as fast as possible. Development teams should release software as often as they can, with short deployment cycles that provide them with continuous feedback. Not only does this improve the product faster, but it also provides development teams with more information for making informed decisions. And it helps eliminate waste.
- Empower the team. The development team should be able to make technical decisions about the product without being bogged down by external approval processes. The team needs to be treated with respect and have the freedom to make the choices necessary to deliver software as fast and effectively as possible. Ongoing learning is an essential component of team empowerment.
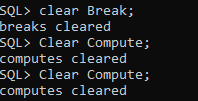
- Build integrity in. Accelerated application delivery should not come at the expense of the application’s integrity or quality. Fast does not mean sloppy. Customers should get an application that’s easy to use, works as it’s supposed to work, and includes the features they expect. The right tools can help ensure integrity by automating repetitive tasks, implementing comprehensive testing, and providing ongoing monitoring and feedback.
- See the whole. Software development is immersed in endless detail. Even so, development teams should also understand the big picture. They should be familiar with the project’s goals, the application’s users, the value that the application provides, and any other information that offers insights into what they’re trying to achieve as a team and organization.
The lean approach to software development has much in common with Agile methodology. In fact, the two are sometimes treated as one and the same, even though they came about in different ways. Agile got its official start in 2001 when a group of developers published the Manifesto for Agile Software Development, which is built on four core values:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
The group of developers also published a set of twelve principles, which stand behind the Manifesto:
- Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
- Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.
- Deliver working software frequently, from a couple of weeks to a couple of months, with a preference for the shorter timescale.
- Business people and developers must work together daily throughout the project.
- Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
- The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
- Working software is the primary measure of progress.
- Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
- Continuous attention to technical excellence and good design enhances agility.
- Simplicity—the art of maximizing the amount of work not done—is essential.
- The best architectures, requirements, and designs emerge from self-organizing teams.
- At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
From these principles, it’s easy to see how lean software development and Agile are similar in many ways. For example, they both embrace changing requirements and more frequent software delivery. In fact, one could argue that Agile is an expression of lean software development principles. They certainly share similar goals, even if they emphasize different aspects of application delivery.
DevOps and lean software development
As with Agile, it could be argued that lean software development principles lie at the core of DevOps. It could also be said that DevOps is the next step in the evolution of lean and agile software development. Certainly, a symbiotic relationship exists between these methodologies, even if they can each stand on their own. Consider Amazon’s description of DevOps:
DevOps is the combination of cultural philosophies, practices, and tools that increases an organization’s ability to deliver applications and services at high velocity: evolving and improving products at a faster pace than organizations using traditional software development and infrastructure management processes. This speed enables organizations to better serve their customers and compete more effectively in the market.
DevOps enables development and operation teams to collaborate in order to deliver software more effectively. Together, the teams employ continuous integration and delivery practices that automate and standardize release cycles while optimizing application lifecycles and accelerating deployments.
One of the most popular books on DevOps is Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations, written by Dr. Nicole Forsgren, Jez Humble, and Gene Kim. When working on their book, the authors used rigorous statistical methods to determine the best way to measure software delivery performance. They discovered that high-performance delivery can be predicted by four key metrics:
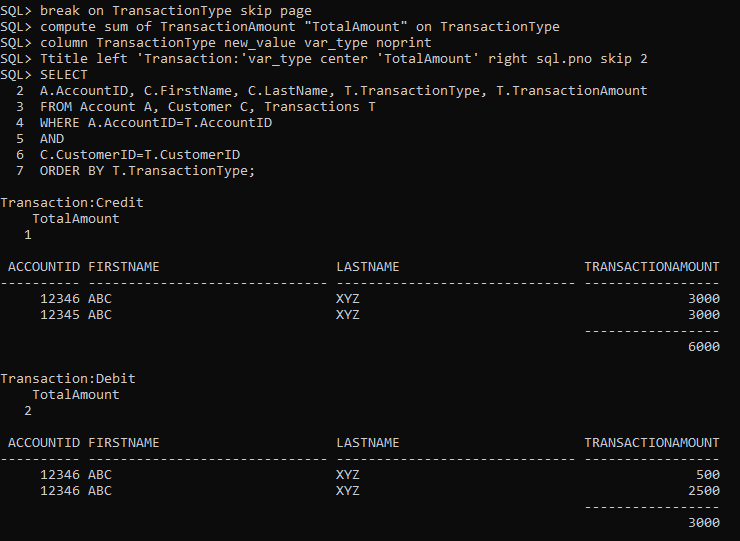
- Lead time. The time from code commit to running the application in production; the shorter the time, the better.
- Deployment frequency. The number of times the application is deployed during a specified time period; the higher the rate the better.
- Mean time to restore. The average time it takes to recover from an incident; the shorter the time, the better.
- Change fail percentage. The percentage of changes to production that fail; the lower the rate, the better.
These four metrics dovetail nicely with lean software development and its emphasis on faster deployments, reduced waste and building integrity into application delivery. Both lean software and DevOps seek to remove any barriers that might prevent teams from delivering applications as quickly and smoothly as possible while maximizing customer value. Because the two share many of the same goals, DevOps can effectively encompass lean software development principles while adding the benefits of integrated development and operations.
DevOps provides an efficient mechanism for applying lean development principles on a consistent and ongoing basis. Lean software development emphasizes the importance of minimizing waste, optimizing production, and increasing customer value—all characteristics integral to an effective DevOps operation. A DevOps team that embraces lean development principles recognizes the importance of prioritizing customer value, while continuously improving and optimizing their operations, which means eliminating waste wherever possible.
Business value of lean DevOps
Many DevOps teams already incorporate lean development principles into their operations, treating the application delivery process as a natural extension of those principles. Other teams might need to take specific steps to create an environment more friendly to lean software development, such as stepping up their efforts to reduce waste or emphasizing customer value over other priorities.
Regardless of how they approach lean DevOps, organizations stand to benefit in a number of important ways. For example, incorporating lean principles into DevOps can lead to more streamlined operations and increased productivity. Lean DevOps calls for ongoing feedback and optimization, coupled with team collaboration and participation. As a result, operations continuously improve and become more efficient, providing team members with the time they need to focus on important tasks, learn new skills and bring innovation to the table, which in turn help to improve operations even further.
Along with greater efficiency, organizations also benefit from less waste. Lean DevOps attempts to eliminate any activities, features, processes or other practices that do not contribute directly to application delivery. This also includes reducing duplicate efforts and automating repetitive manual tasks by deploying proper tools and processes. Plus, eliminating waste can help streamline operations and increase productivity.
Lean DevOps also means faster and more frequent deployments. Not only do customers benefit from regular updates, but developers get more immediate feedback on their changes. At the same time, these changes are deployed in smaller chunks, making it easier to address issues when they arise. Not only does this shorten the time-to-market, but it also results in greater customer satisfaction, giving organizations an edge over their competition. In addition, because deployments are broken down into small chunks, rollbacks and resolutions can be carried out more quickly, reducing the overall risks to the project.
Lean DevOps also results in greater agility, making it easier for team members to respond to changing business strategies and customer requests. The team can react more quickly to new regulations, changes in the competitive landscape, technological concerns, and other challenges. This flexibility goes hand-in-hand with more frequent deployments, leading to an even greater competitive edge.
Another advantage of lean DevOps is increased job satisfaction. An effective DevOps team relies on open communication and collaboration, along with ongoing learning. These can help create a more conducive and inviting work environment. In addition, because team members are empowered to make decisions and innovate, they experience less of the frustration that comes from being at the mercy of a bureaucratic chain of command. In addition, repetitive, manual tasks are automated, and feedback is quick and ongoing. This enables team members to perform their jobs more effectively, while being able to see immediate results for their efforts, adding to the overall satisfaction.
When taken together, these benefits translate to greater profitability. Software is delivered faster and more efficiently, without the waste the comes with traditional development methodologies. This can help reduce overall development costs and increase productivity. At the same time, organizations can respond more quickly to shifting trends and customer expectations, improving the bottom line even further, especially if organizations can deliver products and features faster than their competition. Plus, greater job satisfaction can lead to lower turnover, which itself can represent a significant saving.
Making DevOps leaner
Lean software development has its roots in automobile manufacturing. DevOps doesn’t go back nearly as far, emerging more recently as a way to improve the application delivery process. Even so, both approaches can benefit software development in numerous ways, and together they can offer even greater business value. Not only can they help improve operations and reduce waste, but they can also lead to faster deployments, increased agility, and fewer risks—all of which translate to greater profitability and the organization’s long-term stability.
The post Business value of lean software development and DevOps appeared first on Simple Talk.
from Simple Talk https://ift.tt/3uucofi
via