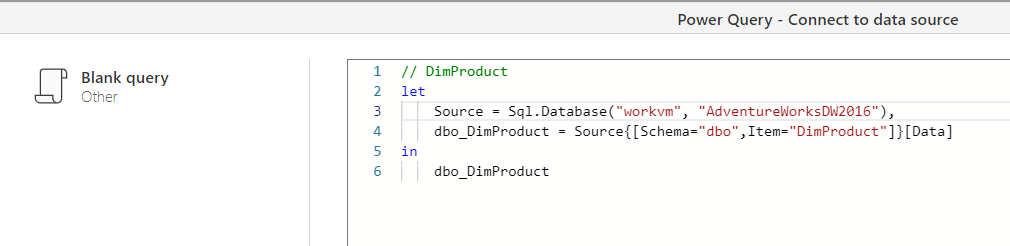
SQL Server is a powerful and feature-rich database management platform that can support a wide range of applications, but if queries are not performing well or workloads are running into deadlocks, latency issues, and other disruptions in service, no one will care about how good the platform is. Their only concern will be application performance. This article describes nine best practices for SQL Server performance tuning.
The best way to ensure that SQL Server can meet its performance requirements is to implement a robust performance tuning strategy that takes into account all aspects of the SQL Server environment. Not only does this include indexes and queries, which are often the primary targets of tuning efforts, but also the hardware infrastructure, server and database settings, log and data files, and any other components that support the environment.
In this article, I provide nine best practices for carrying out performance tuning in a SQL Server environment. Each best practice is in itself a broad enough topic to warrant its own article (or series of articles or even a book or two). For this reason, these best practices—or guidelines— should be thought of as a starting point only, with the understanding that you should delve more deeply into each topic to gain a clearer understanding of what’s involved. The guidelines are meant only to launch you on your way to effective performance tuning and provide you with a foundation for getting started.
1. Plan hardware based on performance requirements.
Performance issues can often be attributed to the hardware infrastructure that supports your SQL Server environment. The better you plan your infrastructure, the more likely you are to prevent hardware-related performance issues, which can occur with any of the following resources:
- Compute. SQL Server is a resource-intensive application that requires enough processing and memory power to manage the data and drive its workloads, whether transactional, analytical, business intelligence, bulk loads, or a fluctuating mix. When processors or memory can’t keep up, applications grow less responsive and might even stop working.
- Storage. SQL Server requires storage solutions that can handle the anticipated amounts of data while supporting the different ways in which data is being accessed. In today’s market, organizations can choose from a wide range of storage options, but only some are practical for SQL Server. Whatever organizations choose, their storage solutions must be able to deliver the necessary input/output operations per second (IOPS) while keeping latency rates to a minimum.
- Network. Performance issues can also arise if the network can’t keep up with workload demands. SQL Server might be running fine, with the queries optimized for performance, but network bottlenecks can cause long response times that slow down applications and even lead to time-outs.
When you’re planning a SQL Server implementation, you must ensure that your infrastructure can deliver the performance necessary to support all your workloads. If you’ve already implemented SQL Server and are experiencing performance issues, you should evaluate your existing hardware to determine whether it might be the source of your problems.
2. Think performance when setting up your SQL Server instance.
As with hardware, you should be thinking about performance from the start, and that includes when you’re first setting up your SQL Server instances. For example, you’ll likely want to deploy instances for different environments, such as development and production, or install SQL Server on a machine dedicated specifically for that instance.
SQL Server also includes configurable settings that you can modify to meet specific workload requirements. A good example of this is the server memory options, which let you configure the minimum and maximum amounts of server memory, as well as index creation memory and minimum memory per query. For example, you might be running several SQL Server instances on a server or cluster and want to keep them from competing with each other, in which case, you might lower the maximum memory on each instance. SQL Server provides plenty of other options as well, such as those related to parallelism and deadlock priority.
You must be careful when changing configurations. For instance, you might specify a high number of maximum worker threads, thinking it will improve performance, only to find it has brought an application to a crawl. Or you might implement backup compression and then realize that the process is using valuable CPU resources and impacting concurrent operations. You should also tread carefully when setting trace flags. Although they can be useful for troubleshooting performance, they can also disrupt operations, which is why you should thoroughly test any changes you make before implementing them into production.
3. Consider performance when configuring your databases.
SQL Server also provides various ways to address performance at the database level. For example, you can locate your log and data files on different physical drives, which can eliminate contention between files while accommodating different access patterns. In addition, you might find it useful to adjust the Autogrowth and Maxsize file settings for these files, depending on your workloads.
SQL Server also lets you configure settings at the database level, just like you can at the server level. For example, you can enable or disable the Auto Create Statistics and Auto Update Statistics options, as well as set up asynchronous statistics updates. You can also change the database compatibility level, which can be useful after you’ve updated SQL Server to a newer version.
When addressing performance issues at the database level, you’re not limited to user databases and their properties. You might also be able to boost performance by optimizing the tempdb system database, which can impact performance in unexpected ways, such as causing metadata contention or object allocation contention. One way to optimize the database is to locate its files on disks separate from the user databases or the underlying operating system. Other approaches include adjusting the number of tempdb data files or their sizes.
4. Design your databases with performance in mind.
A proper database design is essential to ensuring data integrity, but it can also play an important role in performance. For example, a normalized database can improve performance by reducing the amount of redundant data, which can simplify write operations and, in some cases, read operations, particularly if only one table is involved. In some cases, however, your queries might benefit from a little denormalization if used judiciously.
When designing a database, also be sure to choose the most appropriate data types for your data, such as using char instead of varchar for string values that are all two characters. You should also consider the type of data you actually store in SQL Server. For example, it’s often better to store the image path in a database than the image itself. The appropriate use of foreign keys and other constraints can also benefit performance.
In addition to tables, you should also take into account how other database objects can impact performance. For instance, you can often avoid complex queries by putting those queries in views and then indexing the views (keeping in mind best indexing practices). Another example is the stored procedure, which can often deliver better performance than a comparable query. However, be sure to follow best practices when creating your stored procedures, such as including the SET NOCOUNT ON clause or not using the sp_ prefix when naming the procedures.
5. Build indexes to improve performance, not make it worse.
Some organizations, especially those without experienced DBAs, are often tempted to keep adding indexes to their tables in the hope of improving performance, only to discover that performance has steadily worsened. Proper indexing calls for a much more subtle approach, one that takes into account the data itself and the types of queries being performed.
The guidelines for proper indexing are quite extensive, far too many to cover here, but here are a few considerations to bear in mind:
- Base indexes on the columns that are being queried, especially those in joins and query predicates.
- When creating an index on multiple columns, base the column order on how the columns are queried.
- Don’t create indexes on small tables unless you can clearly demonstrate their benefits.
- Don’t index a column that has relatively few unique values.
- Check indexes regularly for fragmentation, then rebuild or reorganize them as necessary.
- Identify unused or underutilized indexes and remove them to avoid unnecessary overhead.
- Sort indexes based on how the data is being queried.
- Verify that your queries are using the indexes as expected.
- Use covering indexes or filtered indexes where appropriate, keeping in mind the types of queries you’re supporting.
These are only some of the considerations to take into account when creating indexes on your tables and views. Proper indexing must be approached very carefully, or it can seriously undermine performance, rather than helping it along.
6. Create queries to maximize performance.
One of the most important steps you can take to improve SQL Server performance is to optimize your T-SQL queries, an undertaking so complex and nuanced that entire books have been written on the subject. The diligent database developer needs to take into account a number of considerations, including the following:
- Retrieve only the fields you need and avoid using SELECT * in your queries.
- Include the schema name when calling a database object.
- Include the SET NOCOUNT ON clause in your queries unless you need to know the number of rows affected by a query.
- Avoid implicit conversions that cause the query engine to convert data unnecessarily.
- Reduce the number of queries per session, where possible, and keep transactions short.
- Understand the differences between temporary tables, table variables, and common table expressions, and know when to use one over the other.
- Use joins instead of correlated subqueries.
These are but a sampling of the many guidelines to keep in mind when optimizing your T-SQL queries. In addition, your scripts should undergo careful code reviews and be fully tested before being implemented into production. Developers should also modify their queries in small increments rather than make sweeping changes all at once, so they have a clear understanding of what worked and what did not.
7. Keep your SQL Server environment up-to-date.
This best practice might be one that seems to go without saying, but the importance of keeping hardware, software, and firmware current cannot be overstated. Where possible, you should consider updating to a more recent version of SQL Server to take advantage of new performance-related features. For example, Microsoft introduced memory-optimized tempdb metadata in SQL Server 2019, which can improve performance for workloads that rely heavily on the tempdb database.
Even if you decide not to upgrade to a newer SQL Server release, you should still regularly update your SQL Server instances and the underlying Windows operating system to benefit from any recent performance enhancements. In addition, you should consider updating any hardware that might be starting to drag performance down. Even if you don’t replace the hardware, you should certainly keep the supporting software and firmware up-to-date.
8. Leverage SQL Server tools to optimize performance
SQL Server offers a variety of tools to help improve performance. Anyone trying to optimize a SQL Server environment should take advantage of these tools where it makes sense, especially since they’re included with the licensing fees. Here are some of the tools that SQL Server provides:
- The Microsoft Database Engine Tuning Advisor (DTA) will analyze your databases and provide recommendations for how to optimize query performance. You can use the tool to troubleshoot a specific query, tune a set of queries across multiple databases, manage storage space and perform what-if analysis of design changes.
- SQL Server Query Store lets you capture a history of queries, execution plans, and runtime statistics, which you can then review to gain insight into database usage patterns and query plan changes. Query Store can help you identify and fix query performance regressions caused by plan changes, as well as identify and tune resource-consuming queries.
- SQL Server Extended Events is a lightweight performance monitoring system that lets you collect the data needed to identify and troubleshoot performance problems. When creating an extended events session, you can specify which events to track and how to store the event data. In this way, you can collect exactly the information you need about your SQL Server environment and then view the information in a format that best suits your needs.
- SQL Server Management Studio (SSMS) includes several options for viewing details about a query’s execution. You can display a query’s actual execution plan, which contains runtime information such as resource usage metrics or runtime warnings, or you can use the Live Query Statistics feature to view real-time data about the query execution process. SSMS also let you view client statistics about queries and their related network packets.
- SQL Server provides a rich assortment of dynamic management views (DMVs), many of which can help identify performance issues. For example, you can use the sys.dm_os_wait_stats DMV to view the waits encountered by executed threads, which can help you diagnose performance issues with SQL Server and specific queries. SQL Server offers both server-scoped and database-scoped DMVs.
The better you understand how to use the tools that SQL Server provides, the more effectively you can identify and address performance issues. Be aware, however, that some tools or features might not be available to older SQL Server or SSMS editions. In addition, the tools mentioned here are not the only ones available. For example, you can download Microsoft’s Database Experiment Assistant (DEA), an A/B testing solution for SQL Server upgrades.
It’s definitely worth digging around to see what other tools and features might help you address performance issues. Even the error logs can sometimes be useful in identifying potential performance problems.
9. Monitor, monitor, monitor.
Ongoing monitoring is essential to delivering consistent performance across all SQL Server databases and instances. But it’s not enough to simply collect telemetry from your systems. You must also be able to use the collected data to diagnose performance issues and get at their root cause. A monitoring solution can alert you to potential issues, help you identify bottlenecks, and reveal trends that might point to performance problems occurring over a specific period of time.
There are no hard-and-fast rules that dictate exactly what you should monitor, and certainly you should design your monitoring strategy to meet your specific circumstances. That said, there are areas that typically warrant your attention. For example, you’ll likely want to monitor index fill factors, fragmentation, and usage. You might also benefit from monitoring metrics such as CPU, memory, I/O, and buffer cache usage, as well as metrics related to the log and data files. You should also consider tracking metrics specific to your queries.
To properly monitor you SQL Server environment, you will need a monitoring solution that can track the metrics you require, without impacting application performance or database operations. The solution should be able to track all relevant metrics, generate timely notifications, and provide you with the insights you need to understand and resolve your performance issues quickly and efficiently. You might consider Microsoft’s System Monitor (a.k.a. Performance Monitor), which is available for free, but many administrators prefer a solution that offers more robust features, such as Redgate’s SQL Monitor.
Performance tuning as an ongoing effort
Performance turning is not a one-off operation that you perform early on and forget about until everything crashes. It is an ongoing effort that requires careful attention to all aspects of the SQL Server environment throughout its lifespan. Performance tuning includes the infrastructure that hosts the environment, the queries that access the data, the indexes that support the queries, the server and database settings that impact performance, and everything in between.
When tuning the environment, however, you should proceed with caution, making changes in manageable steps and thoroughly testing those changes before implementing them into production. Above all, performance tuning should not be treated as an afterthought, but rather as an integral part of your management and optimization efforts that begins when first setting up your SQL Server environment and continues until the environment is put out of commission.
The post SQL Server performance tuning: Nine best practices appeared first on Simple Talk.
from Simple Talk https://ift.tt/3c41Uvg
via