In my last article, I introduced some of the basic information about SQL Server identity columns. This article goes beyond the basics of the identity column and discusses more advanced topics. It covers how to manually insert identity values, how to avoid duplicate identity values, how to reseed the identity value, how to identify functions and variables, and more.
Manually inserting identity values
By default, it’s not possible to manually insert a value directly into an identity column value, but identity values can be manually entered if you turn on a session option. To find out what happens when you try to insert an identity value without turning on the Identity Insert property, run the code in Listing 1.
Listing 1: Attempting to insert an identity value
CREATE TABLE Widget(WidgetID INT NOT NULL IDENTITY,
WidgetName NVARCHAR(50), WidgetDesc NVARCHAR(200));
INSERT INTO Widget
VALUES (110,'MyNewWidget','New widget to test insert');
Inserting the identity value 110 into the identity column along with values for the rest of the columns in the Widget table returns the error shown in Report 1.
Report 1: Error reported when code in Listing 1 is run

The error message clearly states that you cannot explicitly insert an identify value unless you specify a column list along with the INSERT statement, and the IDENTITY_INSERT property for the Widget table is set to ON.
The IDENTITY_INSERT property is a session property that controls whether or not an identity value can be inserted. The default value for this property is OFF, but it can be turned on for the Widget table by using the code in Listing 2.
Listing 2: Turning on the IDENTITY_INSERT property
SET IDENTITY_INSERT Widget ON;
After turning ON the IDENTITY_INSERT property for the Widget table, it’s possible to run the code in Listing 3 without getting an error.
Listing 3: Code with column list required to insert identity value
INSERT INTO Widget(WidgetID,WidgetName,WidgetDesc)
VALUES (110,'MyNewWidget','New widget to test insert');
Only one table in a session can have the INDENTITY_INSERT property turned on at a time. If you need to insert identity values in more than one table, you will first need to turn OFF the IDENTITY_INSERT property on the first table using the code in Listing 4 before turning ON the IDENTITY_INSERT property for another table.
Listing 4: Turning off IDENTITY_INSERT session property
SET IDENTITY_INSERT Widget OFF;
Care must be taken when manually inserting identity values. SQL Server does not require identity values to be unique. Because of this, you need to take care when manually inserting identity values to make sure you don’t insert an identity value that already exists.
Avoiding Duplicate Identity Values
Duplicate identity values can occur in a table when inserting identity values or reseeding the identity value. Having duplicate identity values isn’t necessarily a bad thing, provided there isn’t a requirement that each identity value is unique. If all identity values need to be different, this requirement can be enforced by creating a PRIMARY KEY, UNIQUE constraint, or a UNIQUE index.
Using IDENTITY function
SQL Server provides the IDENTITY function to define an identity column when creating a new table using the SELECT statement with an INTO clause. The IDENTITY function is similar but not the same as the IDENTITY property used in a CREATE or ALTER TABLE statement. The IDENTITY function can only be used in a SELECT statement containing an INTO clause that creates and populates a new table.
Below is the syntax for the IDENTITY function:
IDENTITY (data_type [ , seed , increment ] ) AS column_name
Where:
data-type – a valid numeric data type that supports integer values other than bit or decimal.
seed – identifies the first identity value to be inserted into the table.
increment – integer value to be added to the seed value for each successive row added.
column_name – the name of the identity column that will be created in the new table.
To show how the IDENTITY function works, run the code in Listing 5.
Listing 5: Using IDENTITY function in SELECT INTO command
USE AdventureWorks2019;
GO
SELECT IDENTITY(int, 90000, 1) AS Special_ProductId,
Name AS Special_Name,
ProductNumber,
ListPrice
INTO Production.SpecialProduct
FROM Production.Product
WHERE Name like '%LL Road Frame%Black%';
-- Display new table
SELECT * FROM Production.SpecialProduct;
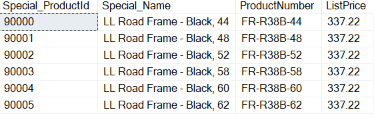
The output from Listing 5 is displayed in Report 2.
Report 2: Output when the code in Listing 5 is executed.
Peeking into Identity Column Definition and ValuesBy reviewing Report 2, you can see that the column named Special_ProductID is the identity column that was created using the IDENTITY function. The first row in this table was populated with the seed value. Each identity value for subsequent rows was calculated by adding the increment value to the identity value of the proceeding row that was inserted.
There are times when you might need to programmatically peek into SQL Server internals to find out the seed or increment value or the value for the last identity column inserted. To find this kind of identity information, SQL Server has provided several functions for returning this information.
To find the seed value, you can use the IDENT_SEED function. This function uses the following syntax:
IDENT_SEED ( 'table_or_view' )
Even if you reseed the identity value using the DBCC CHECKIDENT command, the value returned from this function is the original seed value assigned when the identity column was first created.
A companion function named IDENT_INCR with the following syntax can identify the increment value.
IDENT_INCR ( 'table_or_view' )
To see these two functions in action, run the code in Listing 6.
Listing 6: Viewing the original seed, and increment value
SELECT IDENT_SEED('Production.SpecialProduct') AS OriginalSeed,
IDENT_INCR('Production.SpecialProduct') AS IncrementValue;
Report 3 shows the results of Listing 6.
Report 3: Output created when the code in Listing 6 is run
Finding the Last Identity Value InsertedBy looking in Report 3, you can see the OriginalSeed and IncrementValue are the same as the arguments used when creating the SpecialProduct table using the code in Listing 5.
There are times when you might need to find the last identity value inserted into a table. This is a common requirement when you have two tables with parent-child record relationships, where the child record needs to be linked to the parent record using the identity value of a parent record. There are three different ways to return the identity value of the last record inserted that are reviewed in this article: @@IDENTITY, IDENT_CURRENT, and SCOPE_IDENTITY,
@@IDENTITY
The @@IDENTITY system function returns the last identity value inserted. If the last statement that inserted an identity value inserted multiple identity values, then only the last identity value inserted is returned by this function. If no new identity values have been inserted for the session, this function returns a NULL value. If a trigger is fired due to a row being inserted, and the trigger, in turn, inserts a row in a table that contains an identity column, then the identity column inserted by the trigger will be returned.
SCOPE_IDENTITY
The SCOPE_IDENTITY function also returns the last identity value inserted, just like @@IDENTITY with one difference. The difference is that the SCOPE_IDENTITY function only returns an identity value for the last INSERT statement executed in the same session and scope. In contrast, the @@IDENTITY function returns the last identity inserted regardless of scope.
To better understand how the scope affects the identity value returned by these two functions, execute the code in Listing 7.
Listing 7: Code to show difference between SCOPE_IDENTITY and @@IDENTITY
DROP TABLE IF EXISTS TestTable1, TestTable2;
CREATE TABLE TestTable1(
ID INT IDENTITY(1,1),
InsertText1 VARCHAR(100)
);
CREATE TABLE TestTable2(
ID INT IDENTITY(100,100),
InsertText2 VARCHAR(100)
);
GO
CREATE TRIGGER MyTrigger ON TestTable1 AFTER INSERT AS
BEGIN
INSERT INTO TestTable2(InsertText2) VALUES ('Trigger Insert 1');
INSERT INTO TestTable2(InsertText2) VALUES ('Trigger Insert 2');
END
GO
INSERT INTO TestTable1(InsertText1) VALUES ('Original Insert');
GO
-- Review Identity values returned
SELECT @@IDENTITY AS [@@IDENTITY], SCOPE_IDENTITY() AS [SCOPE_IDENTITY];
The code in Listing 7 first inserts 1 record into TestTable1 table in the current scope, then 2 more records are inserted into the TestTable2 table in a different scope when the trigger is fired. After the insert and insert trigger have fired, a SELECT statement is executed to show the values returned from the @@IDENTITY and the SCOPE_IDENTITY() functions. The output when the code in Listing 7 is executed is shown in Report 4.
Report 4: Output from Listing 7
Therefore, if you want to know the last identity value regardless of scope, you can use @@IDENTITY. If you need the last identity value inserted in the current scope, you need to use the SCOPE_IDENTITY() function.By reviewing Report 4, you can see that the @@IDENTITY function returned a 200. This value is returned because the @@IDENTITY function returns that last identity value inserted, regardless of scope. The identity value for the second record was inserted into the TestTable2 table via the after insert trigger. The SCOPE_IDENTITY() function returned a 1, the identity value assigned when the record was inserted into TextTable1, which is in the same scope.
Keep in mind that both the @@IDENTITY and SCOPE_IDENTITY() functions return the last identity value inserted without considering which table the identity value was inserted. If you need to know the last identity value inserted for a specific table, you should use the IDENT_CURRENT() function.
IDENT_CURRENT
The IDENT_CURRENT() function returns the last identity value inserted for a specific table, regardless of which session or scope it was inserted. Using the IDENT_CURRENT() function, you can easily determine the last identity value created for a specific table as shown in the code Listing 8.
Listing 8: Determining Last Identity values inserted into TestTable1, and TestTable2
SELECT IDENT_CURRENT('TestTable1') AS IdentityForTestTable1,
IDENT_CURRENT('TestTable2') AS IdentityForTestTable2;
When the code in Listing 8 runs, you will see the output in Report 5.
Report 5: Output when Listing 8 is run
Consecutive ValuesThe @@IDENTITY and SCOPE_IDENTITY() functions do not require a table name to be passed as a parameter, so you can not easily identify which tables the identity value returned came from. In contrast, the IDENT_CURRENT() requires a table name to be passed. Therefore, if you want to know the last identity value inserted for a specific table regardless of session or scope, you should consider using the IDENT_CURRENT() function.
When inserting multiple rows into a table with an identity column, there is no guarantee that each row will get consecutive values for the identity column. This is because other users might be inserting rows at the same time. If you really need to get consecutive identity values, you need to ensure your code has an exclusive lock on the table or use the SERIALIZE isolation level.
You might also find that identity values are not always consecutively assigned. One reason this occurs is when a transaction is rolled back. When a rollback occurs, any identity values rolled back will not be reused. Another reason you might have gaps is because of how SQL Server caches identity values for performance reasons.
Identity Caching for Performance Reasons
To finding the next identity value, SQL Server requires some machine resources to peek at the internals to find that value. Therefore to optimize performance and to save on machine resources, SQL Server caches available identity values. By caching available identity values, SQL Server doesn’t have to figure out the next available identity value when a new row is inserted.
Identity cache was introduced in SQL Server 2012. The problem with identity caching is that when SQL Server aborts or is shut down unexpectedly, SQL Server loses track of the values stored in the internal cache. When the cached values are lost, those identity values will never get used. This can cause gaps in identity values.
A new database configuration option was introduced with SQL Server 2017 named IDENTITY_CACHE to help with the identity gap issues that the caching feature can cause. The IDENTITY_CACHE option is ON by default but can be turned OFF. By having it OFF, SQL Server doesn’t cache identity values; thereby, identity values will not get lost when SQL Server crashes or is shut down unexpectedly. Of course, when turning off identity caching, there will be a performance hit.
To identify the current IDENTITY_CACHE setting for a database, run the code in Listing 9.
Listing 9: Displaying IDENTITY_CACHE setting for the current database
SELECT * FROM sys.database_scoped_configurations
WHERE NAME = 'IDENTITY_CACHE';
The output of running Listing 9 against a SQL Server 2017 database is shown in Report 6.
Report 6: The output of Listing 9
Listing 10: Turning off Identity Caching
The IDENTITY_CACHE value in Report 6 is set to 1, which means the identity cache is enabled. To disable the identity cache for the current database, run the code in Listing 10.
ALTER DATABASE SCOPED CONFIGURATION SET IDENTITY_CACHE=OFF;
If you find lots of gaps in your identity values, and that is a problem, you might consider disabling identity caching.
Drawbacks of identity columns
Identity columns are a great way to automatically populate a numeric integer column with a different number every time a new row is inserted. Still, there are a few drawbacks to using identity columns:
- Only one identity column can be defined per table.
- An identity column cannot be altered or deleted once it has been created.
- Identity columns are not unique by default. To make them unique, you need to define a primary key, or a unique constraint, or a unique index.
The SQL Server identity column
Identity columns are a great way to automatically populate a numeric column with an ever-increasing number value when a row is inserted into a table. But identity columns have some inherent issues, like they might contain duplicates or have gaps in their values. One big drawback of an identity column is that there can only be one identity column on a table. Suppose you need to have a column automatically populated with different numeric values, but the issues and features of a identity column don’t meet your needs. In that case, you might consider looking at the sequence number feature available in SQL Server.
The post Working with SQL Server identity columns appeared first on Simple Talk.
from Simple Talk https://ift.tt/3i3sVlA
via