Microsoft introduced the first window (aka, windowing or windowed) functions with SQL Server 2005. These functions were ROW_NUMBER, RANK, DENSE_RANK, NTILE, and the window aggregates. Many folks, including myself, used these functions without realizing they were part of a special group. In 2012, Microsoft added several more: LAG and LEAD, FIRST_VALUE and LAST_VALUE, PERCENT_RANK and CUME_DIST, PERCENTILE_CONT, and PERCENTILE_DISC. They also added the ability to do running totals and moving calculations.
These functions were promoted as improving performance over older techniques, but that isn’t always the case. There were still performance problems with the aggregate functions introduced in 2005 and the four of the functions introduced in 2012. In 2019, Microsoft introduced Batch Mode on Row Store, available on Enterprise and Developer Editions, that can improve the performance of window aggregates and the four statistical functions from 2012.
I started writing this article to compare some window function solutions to traditional solutions. I found that there were so many ways to write a query that includes a column from another row that this article is dedicated to the window functions LAG and LEAD.
Include a column from another row using LAG
Including a column from another row typically means some a self-join. The code is somewhat difficult to write and doesn’t perform well. The LAG function can be used to pull in the previous row without a self-join. As long as there are adequate indexes in place, using LAG solves those problems. LEAD works the same way as LAG, except that it grabs a later row.
Here’s an example using LAG in the AdventureWorks database:
SET STATISTICS IO, TIME ON;
--LAG
SELECT PROD.ProductID, PROD.Name, SOH.OrderDate,
DATEDIFF(DAY, LAG(SOH.OrderDate)
OVER(PARTITION BY PROD.ProductID
ORDER BY SOH.OrderDate),SOH.OrderDate) AS DaysBetweenOrders
FROM Production.Product AS PROD
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY PROD.ProductID, PROD.Name, SOH.OrderDate
ORDER BY PROD.ProductID, SOH.OrderDate;
This query returns a list of products and the dates they were ordered. It uses the DATEDIFF function to compare the current order date to the prior order date determined with LAG. The OVER clause uses a PARTITION BY on ProductID to ensure that different products are not compared. The OVER clause for LAG requires an ORDER BY. It is ordered by OrderDate since that is how the rows should be lined up to find the previous date. Figure 1 shows the partial results.
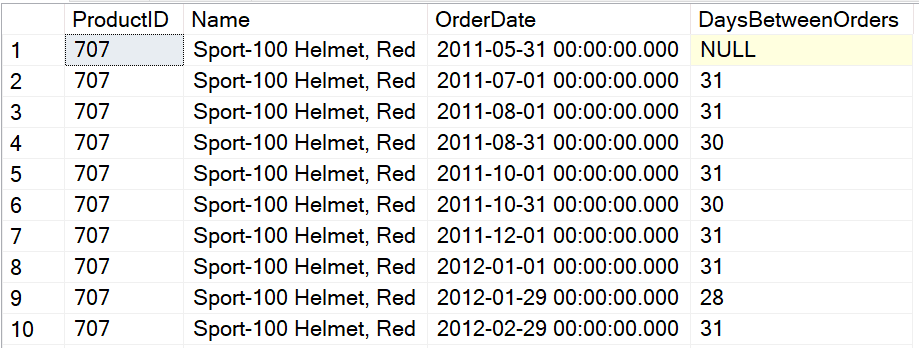
Figure 1. The partial results of the query using LAG
The query ran in under a second, about 300 ms, and required just 365 logical reads, as shown in Figure 2.

Figure 2. The logical reads of the LAG query
I tried several methods to see if it was possible to write a query that performed well without LAG. Even though the database is small, the queries took some time to run, depending on the technique.
Self-join
The self-join technique is painfully slow. Keeping the first order row of each ProductID in the results required LEFT JOINS, but this was so slow, I killed the query after a few minutes. Instead, the following query omits the NULL row for each product.
--Self-join SELECT PROD.ProductID, PROD.Name, SOH.OrderDate, DATEDIFF(DAY, MAX(SOH2.OrderDate), SOH.OrderDate) AS DaysBetweenOrders FROM Production.Product AS PROD JOIN Sales.SalesOrderDetail AS SOD ON SOD.ProductID = PROD.ProductID JOIN Sales.SalesOrderHeader AS SOH ON SOH.SalesOrderID = SOD.SalesOrderID JOIN Sales.SalesOrderDetail AS SOD2 ON SOD2.ProductID = PROD.ProductID JOIN Sales.SalesOrderHeader AS SOH2 ON SOH2.SalesOrderID = SOD2.SalesOrderID WHERE SOH2.OrderDate < SOH.OrderDate GROUP BY PROD.ProductID , PROD.Name , SOH.OrderDate , SOD2.ProductID ORDER BY PROD.ProductID, SOH.OrderDate;
The query ran in 20 seconds and had 3,103 logical reads, as shown in Figure 3.

Figure 3. Logical reads of self-join query
The query uses the MAX function To find the previous OrderDate and filters to find rows in SOH2 with OrderDate less than the OrderDate in SOD.
Derived table
Is it possible to improve the performance of the self-join with a derived table? Here’s a query to find out:
--Derived tables
SELECT S1.ProductID, S1.Name, S1.OrderDate,
DATEDIFF(DAY,MAX(S2.OrderDate),S1.OrderDate) AS DaysBetweenOrders
FROM
(SELECT Prod.ProductID, Prod.Name, SOH.OrderDate
FROM Production.Product AS PROD
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY PROD.ProductID
, PROD.Name
, SOH.OrderDate
) AS S1
LEFT JOIN (
SELECT SOD.ProductID, SOH.OrderDate
FROM Sales.SalesOrderDetail AS SOD
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY SOD.ProductID
, SOH.OrderDate
) AS S2
ON S2.ProductID = S1.ProductID AND S1.OrderDate > S2.OrderDate
GROUP BY S1.ProductID
, S1.Name
, S1.OrderDate
ORDER BY S1.ProductID, S1.OrderDate;
I was surprised to find that this query ran in 2 seconds even though the logical reads were much higher!

Figure 4. Logical reads of derived table query
That’s quite good, though not as good as the query with LAG.
Common table expression
Another way to solve the query is with a common table expression (CTE):
--CTE WITH Products AS ( SELECT PROD.ProductID, PROD.Name, SOH.OrderDate FROM Production.Product AS PROD JOIN Sales.SalesOrderDetail AS SOD ON SOD.ProductID = PROD.ProductID JOIN Sales.SalesOrderHeader AS SOH ON SOH.SalesOrderID = SOD.SalesOrderID GROUP BY PROD.ProductID, PROD.Name, SOH.OrderDate ) SELECT P1.ProductID, P1.Name, P1.OrderDate, DATEDIFF(DAY, MAX(P2.OrderDate), P1.OrderDate) AS DaysBetweenOrders FROM Products P1 LEFT JOIN Products P2 ON P2.ProductID = P1.ProductID WHERE P1.OrderDate > P2.OrderDate GROUP BY P1.ProductID, P1.Name, P1.OrderDate;
This query also ran in 2 seconds with the same logical reads as the derived table. What’s going on here? The CTE is not saving the results to be reused – the tables are accessed twice – but the joins and some other operators are different. The optimizer was able to come up with better plans by using derived tables or a CTE.
OUTER APPLY
The APPLY operator is often used to improve the performance of queries. There are two flavors: CROSS APPLY and OUTER APPLY, similar to JOIN and LEFT JOIN. The APPLY operator can be used to solve many interesting queries, and in this case, it OUTER APPLY replaces the LEFT JOIN.
--OUTER APPLY
SELECT PROD.ProductID, PROD.Name, SOH.OrderDate,
DATEDIFF(DAY, S2.PrevOrderDate, SOH.OrderDate) AS DaysBetweenOrders
FROM Production.Product AS PROD
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
OUTER APPLY (
SELECT MAX(SOH2.OrderDate) AS PrevOrderDate
FROM Sales.SalesOrderDetail AS SOD2
JOIN Sales.SalesOrderHeader AS SOH2
ON SOH2.SalesOrderID = SOD2.SalesOrderID
WHERE SOD2.ProductID = PROD.ProductID
AND SOH2.OrderDate < SOH.OrderDate) S2
GROUP BY DATEDIFF(DAY, S2.PrevOrderDate, SOH.OrderDate)
, PROD.ProductID
, PROD.Name
, SOH.OrderDate
ORDER BY PROD.ProductID, SOH.OrderDate;
This query ran in 12 seconds and had a whopping 86,281,577 logical reads!

Figure 5. Logical reads from OUTER APPLY query
OUTER APPLY is acting like a function call in this scenario calling OUTER APPLY once for each row in the outer query, which would probably not be the case if the less than operator was not involved.
It’s possible to use TOP(1) instead of MAX, but then the query inside OUTER APPLY must also be ordered, and the results are not any better.
Temp Table
Since whatever method is used needs a distinct list of ProductID, Name, and OrderDate, these rows could be stored in a temp table.
--Create temp table
DROP TABLE IF EXISTS #ProductList;
SELECT PROD.ProductID, PROD.Name, SOH.OrderDate
INTO #ProductList
FROM Production.Product AS PROD
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.ProductID = PROD.ProductID
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY PROD.ProductID
, PROD.Name
, SOH.OrderDate;
Here’s an example where the temp table was used with OUTER APPLY:
--OUTER APPLY with Temp table
SELECT PL.ProductID, PL.Name, PL.OrderDate,
DATEDIFF(DAY, PrevOrder.OrderDate, PL.OrderDate) AS DaysBetweenOrders
FROM #ProductList PL
OUTER APPLY (
SELECT MAX(PL1.OrderDate) AS OrderDate
FROM #ProductList AS PL1
WHERE PL1.ProductID = PL.ProductID
AND PL1.OrderDate < PL.OrderDate
) AS PrevOrder
GROUP BY DATEDIFF(DAY, PrevOrder.OrderDate, PL.OrderDate)
, PL.ProductID
, PL.Name
, PL.OrderDate
ORDER BY PL.ProductID, PL.OrderDate;
The temp table drastically improved the time, 1.4 seconds. The actual tables were only touched once to create the temp table. Then the temp table was scanned twice and joined with a Nested Loop.

Figure 6. Partial execution plan when using a temp table
Adding an index to the temp table might improve the performance even more. This script ran in about 700 ms.
--Indexed temp table and OUTER APPLY
CREATE CLUSTERED INDEX IDX_ProductList ON #ProductList
(ProductID, OrderDate);
SELECT PL.ProductID, PL.Name, PL.OrderDate,
DATEDIFF(DAY, PrevOrder.OrderDate, PL.OrderDate) AS DaysBetweenOrders
FROM #ProductList PL
OUTER APPLY (
SELECT MAX(PL1.OrderDate) AS OrderDate
FROM #ProductList AS PL1
WHERE PL1.ProductID = PL.ProductID
AND PL1.OrderDate < PL.OrderDate
) AS PrevOrder
GROUP BY DATEDIFF(DAY, PrevOrder.OrderDate, PL.OrderDate)
, PL.ProductID
, PL.Name
, PL.OrderDate
ORDER BY PL.ProductID, PL.OrderDate;
The self-join was also improved with the temp table, returning in just 3 seconds even while using LEFT JOIN, which wasn’t possible before.
--Self-join with temp table
SELECT PL.ProductID, PL.Name, PL.OrderDate,
DATEDIFF(DAY, MAX(PL2.OrderDate), PL.OrderDate) AS DaysBetweenOrders
FROM #ProductList AS PL
LEFT JOIN #ProductList AS PL2
ON PL2.ProductID = PL.ProductID AND PL.OrderDate > PL2.OrderDate
GROUP BY PL.ProductID
, PL.Name
, PL.OrderDate
ORDER BY PL.ProductID, PL.OrderDate;
Scalar user-defined function
The performance of user-defined scalar functions was improved in 2019 with inlining. I had hoped that the performance would not be too bad since SQL Server is running version 2019. Unfortunately, the less than operator (<) kills the performance. Even adding in an index on OrderDate didn’t help much. I killed the query after 25 seconds.
--Scalar UDF
GO
CREATE OR ALTER FUNCTION [dbo].[GetPreviousOrderDate]
(
@ProductID INT, @OrderDate DATETIME
)
RETURNS DATETIME
AS
BEGIN
DECLARE @PrevOrderDate DATETIME;
SELECT @PrevOrderDate = MAX(OrderDate)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOD.ProductID = @ProductID AND SOH.OrderDate < @OrderDate;
-- Return the result of the function
RETURN @PrevOrderDate;
END;
GO
CREATE INDEX test_index ON Sales.SalesOrderHeader (OrderDate);
GO
--Function call
SELECT PL.ProductID, PL.Name, PL.OrderDate,
dbo.GetPreviousOrderDate(PL.ProductID, PL.OrderDate)
FROM #ProductList AS PL
GROUP BY PL.ProductID
, PL.Name
, PL.OrderDate
ORDER BY PL.ProductID, PL.OrderDate;
Since I killed the query before it completed, I am not sure how long it would keep running. The execution looks simple enough, but it doesn’t show that the function is called many times.

Figure 7. The execution plan for the scalar UDF
Table-valued functions
I’ve often heard someone say, “just turn it into a table-valued function” when UDF issues arise. However, it’s still possible to do “bad things” with table-valued functions as well. There are two types of table-valued functions, multi-statement and inline. Multi-statement table-valued functions (MSTVF) can have loops, IF blocks, and table variables, so they do not scale well.
Inline table-valued functions (ITVF) only allow a single query. Of course, the function could contain a poorly written query, but generally, you will see better performance with these. In this case, however, the performance is still not as good as using LAG. Note that the call to the ITVF also uses OUTER APPLY.
--Inline table-valued function
GO
CREATE OR ALTER FUNCTION dbo.ITVF_GetPrevDate
(
@ProductID INT, @OrderDate DATETIME
)
RETURNS TABLE
AS
RETURN
(
-- Add the SELECT statement with parameter references here
SELECT MAX(SOH.OrderDate) AS PrevOrderDate
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOD.ProductID = @ProductID
AND SOH.OrderDate < @OrderDate
)
GO
SELECT PL.ProductID, PL.Name, PL.OrderDate,
DATEDIFF(DAY,IGPD.PrevOrderDate,PL.OrderDate) AS DaysBetweenOrders
FROM #ProductList AS PL
OUTER APPLY [dbo].[ITVF_GetPrevDate] (PL.ProductID,PL.OrderDate) IGPD
ORDER BY PL.ProductID, PL.OrderDate;
The ITVF takes about 12 seconds to run with over 59 million logical reads when using the temp table.

Figure 8. The logical reads for the ITVF
Cursor
I debated whether to include a section on cursors because I don’t want to encourage anyone to start with a cursor solution. However, I remembered other situations when a cursor solution performed better compared to other techniques, so I decided to include it. Cursors are another tool in your T-SQL toolbox. They may be at the bottom of the box and a bit rusty from disuse, but a tool, nonetheless.
One important thing to note about running the cursor solution is to turn off the Actual Execution Plan (or any other method you might be using to capture execution plans) and Statistics. With those turned off, the script took about 2 seconds to run!
--Cursor
--Important! Also turn off Actual Execution Plan
SET STATISTICS IO, TIME OFF
GO
ALTER TABLE #ProductList
ADD DaysBetweenOrders INT;
GO
DECLARE @LastProductID INT, @ProductID INT;
DECLARE @LastOrderDate DATETIME, @OrderDate DATETIME;
DECLARE @DaysBetweenOrders INT;
DECLARE Products CURSOR FAST_FORWARD FOR
SELECT p.ProductID, P.OrderDate
FROM #ProductList AS P
ORDER BY p.ProductID, P.OrderDate
;
OPEN Products;
FETCH NEXT FROM Products INTO @ProductID, @OrderDate;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @LastProductID = @ProductID BEGIN
SET @DaysBetweenOrders = DATEDIFF(DAY,@LastOrderDate,@OrderDate);
UPDATE #ProductList SET DaysBetweenOrders = @DaysBetweenOrders
WHERE ProductID = @ProductID AND OrderDate =@OrderDate;
END;
SELECT @LastOrderDate = @OrderDate, @LastProductID = @ProductID;
FETCH NEXT FROM Products INTO @ProductID, @OrderDate;
END
CLOSE Products;
DEALLOCATE Products;
SELECT P.ProductID
, P.Name
, P.OrderDate
, P.DaysBetweenOrders
FROM #ProductList AS P
ORDER BY P.ProductID, P.OrderDate;
How LAG compares to other techniques?
There are probably even more ways to write the query (once someone in a presentation insisted that a view would always outperform LAG), but it’s not likely that any other method runs faster than LAG when you need a column from the previous row. Here are the results for each technique:
|
Technique |
Indexed temp table? |
Time |
Logical reads |
|
LAG |
No |
300 ms |
365 |
|
Self-join |
No |
20 sec |
3,103 |
|
Derived table |
No |
2 sec |
127,723 |
|
Common table expression |
No |
2 sec |
127,730 |
|
OUTER APPLY |
No |
12 sec |
86,281,577 |
|
OUTER APPLY |
Yes |
700 ms |
57,358 |
|
Self-join |
Yes |
3 sec |
452 |
|
Scalar UDF |
Yes |
Killed the query |
Unknown |
|
Inline table-valued function |
Yes |
12 sec |
59,622,091 |
|
Cursor |
Yes |
2 sec |
Unknown |
As long as OUTER APPLY had the pre-aggregated temp table to work with, it performed almost as well as LAG. Otherwise, the other methods ran in 2 seconds or more.
For this specific problem, LAG performed the best. The lesson to learn here is that there are many ways to write a query, so try other techniques when you experience issues with performance.
If you like this article, you might also like Introduction to T-SQL Window Functions
The post How LAG compares to other techniques appeared first on Simple Talk.
from Simple Talk https://ift.tt/3tnZXBt
via
No comments:
Post a Comment