Synapse is a great data lake house tool. This means in a single tool we have resources to manage a data lake and data warehouse.
The Synapse Serverless Pool is great to manage data lakes and for a great price: around us$ 5,00 for each TB of data queried. This makes it a great choice.
For the data warehouse, on the other hand, it’s a bit different. Before Synapse, there was Azure SQL Data Warehouse. This product was rebranded as SQL Dedicated Pool. The change on the product name helped to put down an old mistake: People believe that for a Data Warehouse in the cloud they need to use Azure SQL Data Warehouse.
The idea was reduced, but a lot of people still think they need to use Synapse for a Data Warehouse. This is a mistake. A data warehouse is not related to a tool. It’s a database. Some tools may be better or worse for the data warehouse. In relation to Synapse, as the usual answer from every specialist, “It depends”.
What’s the Synapse SQL Dedicated Pool
Understanding what is the SQL Dedicated Pool is the key to understand when you need to use it or not. The most common misconception is to believe the SQL Dedicated Pool is only a simple database. It’s not.
The SQL Dedicated Pool is a MPP tool. MPP stands for Massive Parallel Processing. This is an architecture intended to break down a processing request between many processing nodes, join the processing result from the individual nodes and return the final result. It’s much more than simple parallel processing, its’s a distributed processing broke down in many physical nodes.
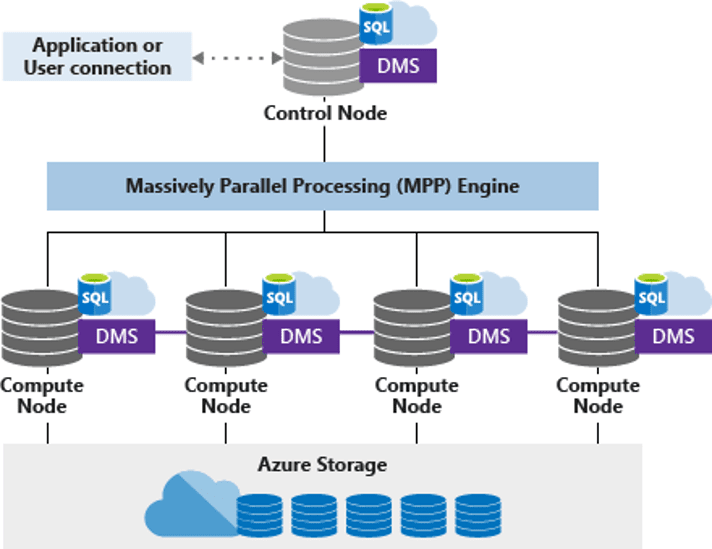
The data is stored in a structure optimized for the MPP execution. What you may see as a single database is in fact a total of 60 databases. Each table is broken down in 60 pieces. This can be a great organization for the MPP execution, but there are more details to analyse.
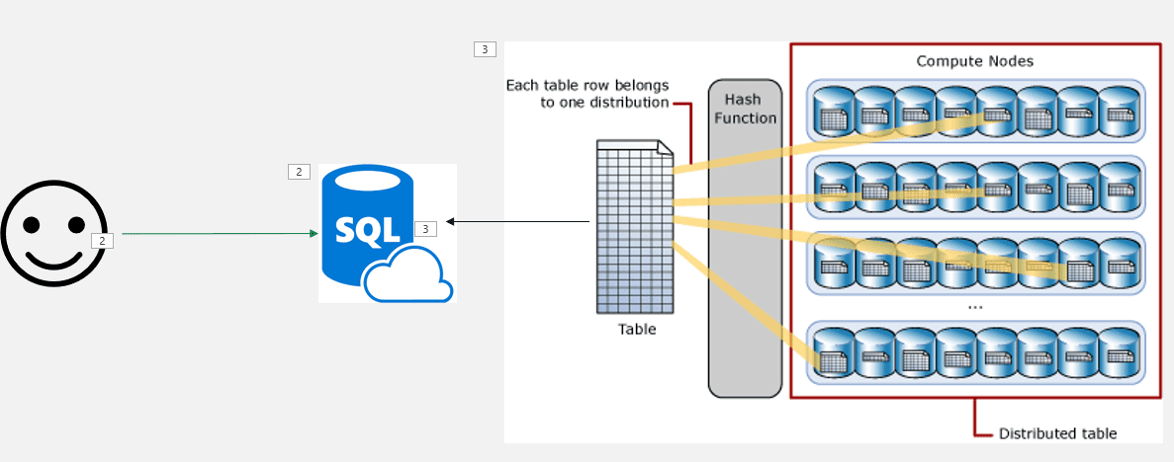
Synapse Dedicated Pool Service level
The service level of the SQL Dedicated Pool defines the number of physical nodes the dedicated pool will have. Any service level below DW 1000 will use only one node. DW 1000 is the first level with 2 nodes and the number grows up to 60 nodes.
The number of databases used to broke down the data is fixed, always 60. These databases will be spread among the physical nodes the dedicated pool contains. For example, if the dedicated pool has two nodes (DW 1000), each node will contain 30 databases.
The first important point is the service level: You should should never use a dedicate pool with less than DW 1000.
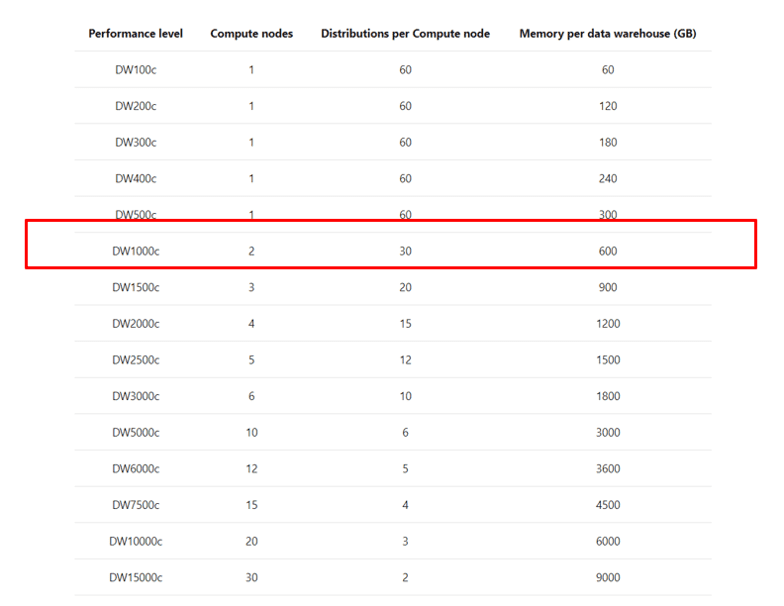
Below DW 1000, there is no real MPP. However, your data is optimized for MPP. Your data is broken down is 60 pieces. Without using a MPP, you will be losing performance instead of getting better performance.
If for any reason you believe you need a SQL Dedicated Pool below DW 1000 in production, that’s because you don’t need a SQL Dedicated Pool, a simple Azure SQL Database may do the job.
Data Volume
Synapse usually makes an interesting recommendation to us: Never use a clustered columnstore index on a table with less than 60 million records in Synapse. If we analyse this recomendation, we may discover some rules about when to use or not use Synapse.
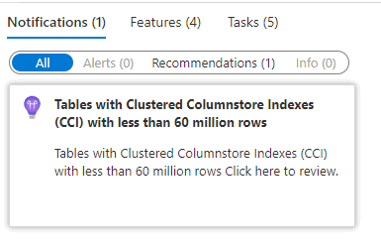
First, it’s important to better understand the columnstore indexes and how important they are.
Let’s columnstore indexes features and behaviours:
- They are specially optimized for analytical queries
- The index is compressed
- They are in memory
- Allow batch mode execution and optimization
The columnstore indexes are very important for data warehouses. We would be losing a lot by not using them. Why Synapse doesn’t recommend them for tables smaller than 60 millions ?
The physical structure of the columnstore indexes use segments with 1 million rows each. The segments are “closed” and compressed on each million records. That’s why the 60 million recomendation: Synapse breaks down each table in 60 pieces. 60 pieces with 1 million rows each makes a total of 60 millions. Any table with less than 60 million rows will have less than 1 million rows on each of their pieces, resulting in incomplete segments and affecting the work of the columnstore index.
Is this a rule to be always followed? Not at all, that’s why it’s just a recommendation. A data warehouse uses star schemas. Usually, the fact table is way bigger than the dimension tables. It’s ok if we have some small dimension tables around a very big fact table, this is not a problem. The problem is when your entire model has no table with the size which requires Synpase for a better processing.
Consumers
Synapse can be very good as a central data source for BI systems such as Power BI, Qulick and more. However, if there is no directly BI system consuming the data, if most of the consumers are other applications receiving data through ETL processes, maybe Synapse is not the better option. Data lakes could perform the same task for a lower cost in this situation.
Summary
Should you use Synapse ? Your volume of data, the need for an MPP and the consumers of your data can provide a good guidance about whether Synapse is a good choice for your solution or not.
The post Synapse Analytics: When you should use (or not use) Synapse appeared first on Simple Talk.
from Simple Talk https://ift.tt/9SzEZwV
via
No comments:
Post a Comment