Serverless computing is pushing C# to evolve to the next level. This is exciting because you pay-per-use and only incur charges when the code is running. This means that .NET 6 must spin up fast, do its job, then die quickly. This mantra of birth and rebirth pushes developers and the underlying tech to think of innovative ways to meet this demand. Luckily, the AWS (Azure Web Services) serverless cloud has excellent support for .NET 6.
In this article, I will take you through the development process of building an API on the serverless cloud with C#. This API will be built to serve pizzas, with two endpoints, one for making pizza and the other for tasting fresh pizzas. I expect some general familiarity with AWS and serverless computing. Any previous experience with building APIs in .NET will also come in handy.
Feel free to follow along because I will guide you through this step-by-step. If you get lost, the full sample code can be found on GitHub.
Getting the AWS CLI Tool
First, you will need the following tools:
- AWS CLI tool
- .NET 6 SDK
- Rider, Visual Studio 2022, Vim, or an editor of choice
The AWS CLI tool can be obtained from the AWS documentation. You will need to create an account then set up the CLI tool with your credentials. The goal is to configure the credentials file under the AWS folder and set an access key. You will also need to set the region depending on your physical location. Because this is not an exhaustive guide on getting started, I will leave the rest up to you the reader.
Create a New Project
I will pick the .NET 6 CLI tool because it is the most accessible to everyone. You can open a console via Windows Terminal or the CMD tool. Before you begin, verify that you have the correct version installed on your machine.
> dotnet --version
This outputs version 6.0.42 on my machine. Next, you will need the AWS dotnet templates:
> dotnet new -i Amazon.Lambda.Templates > dotnet tool install -g Amazon.Lambda.Tools
If you have already installed these templates, simply check that you have the latest available:
> dotnet tool update -g Amazon.Lambda.Tools
Then, create a new project and a test project with a region.
> dotnet new serverless.AspNetCoreMinimalAPI -n Pizza.Api \
--profile default --region us-east-1
> dotnet new xunit -n Pizza.Api.Tests
Be sure to set the correct region, one that matches your profile in the AWS CLI tool.
The dotnet CLI generates a bunch of files and puts them all over the place. I recommend doing a bit of manual clean up and follow the folder structure below in Figure 1.
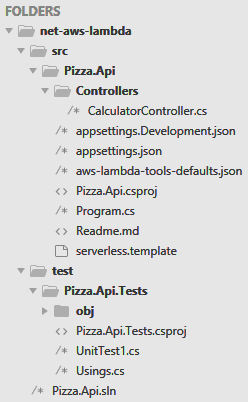
Figure 1. Folder structure
You may also create the solution file Pizza.Api.sln via:
> dotnet new sln -n Pizza.Api > dotnet sln add src\Pizza.Api\Pizza.Api.csproj > dotnet sln add test\Pizza.Api.Tests\Pizza.Api.Tests.csproj
This allows you to open the entire solution in Rider, for example, to make the coding experience much richer.
The template generated nonsense like a Controllers folder and HTTPS redirect. Simply delete the Controllers folder in the Pizza.Api folder and delete the UnitTest1.cs file that is in the Pizza.Api.Tests folder.
In the Program.cs file delete the following lines of code.
builder.Services.AddControllers(); app.UseHttpsRedirection(); app.UseAuthorization(); app.MapControllers();
The HTTPS redirect is a pesky feature that only applies to local to make life harder for developers. On the AWS cloud, the AWS Gateway handles traffic before it calls into your lambda function. Gutting dependencies also helps with cold starts. Trimming middleware like Controllers and Authorization keeps the request pipeline efficient because you get billed while the code is running. One technique to keep costs low, for example, is to use Cognito instead of doing auth inside the lambda function.
Run Your Lambda on Local
Luckily, .NET 6 makes this process somewhat familiar to .NET developers who are used to working with on-prem solutions. Be sure to have (or create) the following launchSettings.json under a Properties folder in the project:
{
"$schema": "https://json.schemastore.org/launchsettings.json",
"profiles": {
"Pizza.Api": {
"commandName": "Project",
"dotnetRunMessages": true,
"launchBrowser": false,
"applicationUrl": "http://localhost:5095",
"environmentVariables": {
"ASPNETCORE_ENVIRONMENT": "Development"
}
}
}
}
Now, go back to the console and run the app under the ..\Pizza.Api\src\Pizza.Api folder:
> dotnet watch
There should be an output telling you it is now running under the port number 5095.
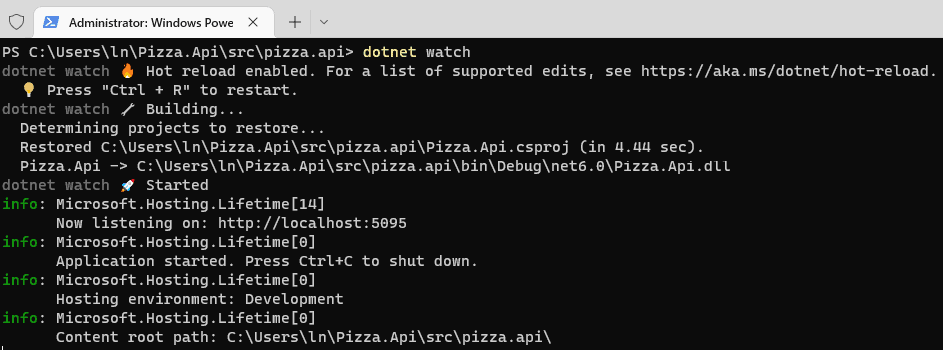
This watcher tool automatically hot reloads, which is a nice feature from Microsoft, this is to keep up with code changes on the fly without restarting the app. This is mostly there for convenience, so I recommend keeping an eye out to make sure the latest code is actually running.
Then, use CURL to test your lambda function on local, make sure the -i flag remains lowercase or try –include:
> curl -X GET -i -H "Accept: application/json" http://localhost:5095
With the AWS tools, developers who are familiar with .NET should start to feel more at home. This is one of the niceties of the ecosystem, because the tools remain identical on the surface.
The one radical departure so far is using the minimal API to host an endpoint and I will explore this topic next.
Make a Pizza
To make a pizza, first, you will need to install the DynamoDB NuGet package in the project. (If you are not acquainted with Amazon DynamoDB, you can get more information here)
In the same Pizza.Api folder, install the dependency:
> dotnet add package AWSSDK.DynamoDBv2
Also, this project requires a Slugify dependency. This will convert a string, like a pizza name, into a unique identifier we can put in the URL to find the pizza resource in the API.
To install the slugify dependency:
> dotnet add package Slugify.Core
With lambda functions, one goal is to keep dependencies down to a minimum. You may find it necessary to copy-paste code instead of adding yet another dependency to keep the bundle size small. In this case, I opted to add more dependencies to make writing this article easier for me.
Create a Usings.cs file in the Pizza.Api directory in src and put these global usings in:
global using Amazon; global using Amazon.DynamoDBv2; global using Amazon.DynamoDBv2.DataModel; global using Pizza.Api; global using Slugify;
Now, in the Program.cs file wire up dependencies through the IoC container:
builder.Services.AddSingleton<IAmazonDynamoDB>( _ => new AmazonDynamoDBClient(RegionEndpoint.USEast1)); builder.Services.AddSingleton<IDynamoDBContext>(p => new DynamoDBContext(p.GetService<IAmazonDynamoDB>())); builder.Services.AddScoped<ISlugHelper, SlugHelper>(); builder.Services.AddScoped<PizzaHandler>();
Note your region can differ from mine. I opted to use the DynamoDB object persistence model via the Amazon.DynamoDBv2.DataModel namespace to keep the code minimal. This decision dings cold starts a bit, but only a little. Here though, I am paying the cost of latency to gain developer convenience.
The DynamoDB object persistence model requires a pizza model with annotations so it can do the mapping between your C# code and the database table.
Create a PizzaModel.cs file, and put this code in:
namespace Pizza.Api;
[DynamoDBTable("pizzas")]
public class PizzaModel
{
[DynamoDBHashKey]
[DynamoDBProperty("url")]
public string Url { get; set; } = string.Empty;
[DynamoDBProperty("name")]
public string Name { get; set; } = string.Empty;
[DynamoDBProperty("ingredients")]
public List<string> Ingredients { get; set; } = new();
public override string ToString() =>
$"{Name}: {string.Join(',', Ingredients)}";
}
Given the table definition above, create the DynamoDB table via the AWS CLI tool:
> aws dynamodb create-table --table-name pizzas \
--attribute-definitions AttributeName=url,AttributeType=S \
--key-schema AttributeName=url,KeyType=HASH \
--provisioned-throughput ReadCapacityUnits=1,WriteCapacityUnits=1 \
--region us-east-1 --query TableDescription.TableArn --output text
The url field is the hash which uniquely identifies the pizza entry. This is also the key used to find pizzas in the database table.
Next, create the PizzaHandler.cs file, and put in a basic scaffold:
namespace Pizza.Api;
public class PizzaHandler
{
private readonly ISlugHelper _slugHelper;
private readonly IDynamoDBContext _context;
private readonly ILogger<PizzaHandler> _logger;
public PizzaHandler(
IDynamoDBContext context,
ISlugHelper slugHelper,
ILogger<PizzaHandler> logger)
{
_context = context;
_slugHelper = slugHelper;
_logger = logger;
}
public async Task<IResult> MakePizza(PizzaModel pizza)
{
throw new NotImplementedException();
}
public async Task<IResult> TastePizza(string url)
{
throw new NotImplementedException();
}
}
This is the main file that will serve pizzas. The focus right now is the MakePizza method.
Before continuing, create the PizzaHandlerTests.cs file under the test project:
namespace Pizza.Api.Tests;
public class PizzaHandlerTests
{
private readonly Mock<IDynamoDBContext> _context;
private readonly PizzaHandler _handler;
public PizzaHandlerTests()
{
var slugHelper = new Mock<ISlugHelper>();
_context = new Mock<IDynamoDBContext>();
var logger = new Mock<ILogger<PizzaHandler>>();
_handler = new PizzaHandler(
_context.Object,
slugHelper.Object,
logger.Object);
}
}
The test project should have its own Usings.cs file, add these global entries:
global using Moq; global using Amazon.DynamoDBv2.DataModel; global using Microsoft.Extensions.Logging; global using Slugify;
Also, install the Moq dependency under the Pizza.Api.Tests project:
> dotnet add package Moq
You will also need the Slugify and Amazon.DynamoDBv2 packages seen in the Pizza.Api project as well. First, I like to unit test my code to check that my reasoning behind the code is sound. This is a technique that I picked up from my eight-grade teacher: “test early and test often”. The faster the feedback loop is between code you just wrote and a reasonable test, the more effective you can be in getting the job done.
Inside the PizzaHandlerTests class, create a unit test method:
[Fact]
public async Task MakePizzaCreated()
{
// arrange
var pizza = new PizzaModel
{
Name = "Name",
Ingredients = new List<string> {"toppings"}
};
// act
var result = await _handler.MakePizza(pizza);
// assert
Assert.Equal("CreatedResult", result.GetType().Name);
}
There is a little quirkiness here because the Results class in minimal API is actually hidden behind private classes. The only way to get to the result type is via reflection, which is unfortunate because the unit test is not able to validate the strongly typed class. Hopefully in future LTS (Long Term Support) releases the team will fix this odd behaviour.
Now, write the MakePizza method in the PizzaHandler to pass the unit test:
public async Task<IResult> MakePizza(PizzaModel pizza)
{
if (string.IsNullOrWhiteSpace(pizza.Name)
|| pizza.Ingredients.Count == 0)
{
return Results.ValidationProblem(new Dictionary<string, string[]>
{
{nameof(pizza), new []
{"To make a pizza include name and ingredients"}}
});
}
pizza.Url = _slugHelper.GenerateSlug(pizza.Name);
await _context.SaveAsync(pizza);
_logger.LogInformation($"Pizza made! {pizza}");
return Results.Created($"/pizzas/{pizza.Url}", pizza);
}
With minimal API, you simply return an IResult. The Results class supports all the same behaviour you are already familiar with from the BaseController class. The one key difference is there is a lot less bloat here which is ideal for a lambda function that runs on the AWS cloud.
Finally, go back to the Program.cs file and add new endpoints right before the app.Run.
using (var serviceScope = app.Services.CreateScope())
{
var services = serviceScope.ServiceProvider;
var pizzaApi = services.GetRequiredService<PizzaHandler>();
app.MapPost("/pizzas", pizzaApi.MakePizza);
app.MapGet("/pizzas/{url}", pizzaApi.TastePizza);
}
One nicety from minimal API is how well this integrates with the existing IoC container. You can map requests to a method, and the model binder does the rest. Those of you familiar with Controllers should see code that reads identical in the PizzaHandler.
Then, make sure the dotnet watcher CLI tool is running the latest code and test your endpoint via CURL:
> curl -X POST -i -H "Accept: application/json" ^
-H "Content-Type: application/json" ^
-d "{\"name\":\"Pepperoni Pizza\",\"ingredients\":[\"tomato sauce\",\"cheese\",\"pepperoni\"]}" http://localhost:5095/pizzas
Feel free to play with this endpoint on local. Notice how the endpoint is strongly typed, if you pass in a list of ingredients as raw numbers then validation fails the request. If there is data missing, validation once again kicks the unmade pizza back with a failed request.
You may be wondering how the app running on local is able to talk to DynamoDB. This is because the SDK picks up the same credentials used by the AWS CLI tool. If you can access resources on AWS, then you are also able to point to DynamoDB using your own personal account with C#.
Taste a Pizza
With a fresh pizza made, time to taste the fruits of your labor.
In the PizzaHandlerTests class, add this unit test:
[Fact]
public async Task TastePizzaOk()
{
// arrange
_context
.Setup(m => m.LoadAsync<PizzaModel?>("url", default))
.ReturnsAsync(new PizzaModel());
// act
var result = await _handler.TastePizza("url");
// assert
Assert.Equal("OkObjectResult", result.GetType().Name);
}
This only checks the happy path; you can add more tests to check for failure scenarios and increase code coverage. I’ll leave this as an exercise to you the reader, if you need help, please check out the GitHub repo.
To pass the test, put in place the TastePizza method inside the PizzaHandler:
public async Task<IResult> TastePizza(string url)
{
var pizza = await _context.LoadAsync<PizzaModel?>(url);
return pizza == null
? Results.NotFound()
: Results.Ok(pizza);
}
Then, test this endpoint via CURL:
> curl -X GET -i -H "Accept: application/json" http://localhost:5095/pizzas/pepperoni-pizza
Onto the Cloud!
With a belly full of pizza, I hope nobody feels hungry, deploying this to the AWS cloud feels seamless. The good news is that the template already does a lot of the hard work for you so you can focus on a few key items.
First, tweak the serverless.template file and set the memory and CPU allocation. Do this in the JSON file:
{
"Properties": {
"MemorySize": 2600,
"Architectures": ["x86_64"]
}
}
This sets a memory allocation of 2.5GB, with a x86 processor. These allocations are not final because you really should do monitoring and tweaking to figure out an optimal allocation for your lambda function. Increasing the memory blindly does not guarantee best results, luckily there is a nice guide from AWS that is very helpful.
Before you can deploy, you’ll need to create an S3 bucket which is where the deploy bundle will go. Note that you may need to provide your own name for the S3 bucket:
> aws s3api create-bucket --acl private --bucket pizza-api-upload \
--region us-east-1 --object-ownership BucketOwnerEnforced
> aws s3api put-public-access-block --bucket pizza-api-upload \
--public-access-block-configuration "BlockPublicAcls=true,IgnorePublicAcls=true,BlockPublicPolicy=true,RestrictPublicBuckets=true"
Then, deploy your app to the AWS cloud via the dotnet AWS tool:
> dotnet lambda deploy-serverless --stack-name pizza-api --s3-bucket pizza-api-upload
Unfortunately, the dotnet lambda deploy tool does not handle role policies for DynamoDB automatically. Login into AWS, go to IAM, click on roles, then click on the role the tool created for your lambda function. It should be under a logical name like pizza-api-AspNetCoreFunctionRole-818HE2VECU1J.
Then, copy this role name, and create a file dynamodb.json with the access rules:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"dynamodb:DescribeTable",
"dynamodb:GetItem",
"dynamodb:PutItem",
"dynamodb:UpdateItem"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
Now, from the Pizza.Api project folder, grant role access to DynamoDB via this command:
> aws iam put-role-policy --role-name pizza-api-AspNetCoreFunctionRole-818HE2VECU1J \
--policy-name PizzaApiDynamoDB --policy-document file://./dynamodb.json
Be sure to specify the correct role name for your lambda function.
Finally, taste a pre-made pizza via CURL. Note that the dotnet lambda deploy tool should have responded with a URL for your lambda function. Make sure the correct GATEWAY_ID and REGION go in the URL.:
> curl -X GET -i ^ -H "Accept: application/json" https://GATEWAY_ID.execute-api.REGION.amazonaws.com/Prod/pizzas/pepperoni-pizza
I recommend poking around in AWS to get more familiar with lambda functions.
The API Gateway runs the lambda function via a reverse proxy. This routes all HTTPS traffic directly to the kestrel host, which is the same code that runs on local. This is a bit more costly because the lambda function routes all traffic, but the developer experience is greatly enhanced by this. Go to S3 and find your pizza-api-upload bucket, notice the bundle size remains small, around 2MB. The dotnet AWS tool might be doing some trimming to keep cold starts low. Also, look at CloudWatch and check the logs for your lambda function. You will find cold starts in general are below .5 sec, this is great news! In .NET 6, the AWS team has been able to make vast improvements which I believe will continue in future LTS releases. Lastly, note the VM that executes the lambda runs on Linux, this is another area of improvement that is also possible in .NET 6.
Conclusion
AWS lambda functions with C# are now production ready. The teams from both Microsoft and AWS have made significant progress in .NET 6 to make this dream a reality.
The post AWS Lambdas with C# appeared first on Simple Talk.
from Simple Talk https://ift.tt/mg8Q1JC
via