As with any other relational data management system (RDBMS), PostgreSQL uses indexes as a mechanism to improve data access. PostgreSQL has a number of different index types, supporting different behaviors and different types of data. In addition, again, similar to other RDBMS, there are properties and behaviors associated with these indexes.
In this article I’m going to go over the different types of indexes and some index behaviors. We’ll get into what the indexes are, how they work, and how best you can apply them within your databases. I’m hoping you’ll develop an understanding of which indexes are likely to work better in each situation.
However, I won’t be covering the indexes in detail. Further, I won’t be going very far into how these indexes affects performance. I’m not yet up on performance tuning within PostgreSQL. That article is quite a way down the track from here. When you know which index to use where, you can then drill down to better understand that index, and how best to measure the performance impacts.
It is important to keep in mind that both your types of data, and your actual queries, that drive the indexes that are going to be best for your databases. This is especially true of PostgreSQL as some of the index types are very focused on specific query patterns.
There are six types of indexes:
- B-Tree
- Hash
- GIST
- SP-GIST
- GIN
- BRIN
Let’s break each of these down and talk about them.
Before we get there though, I’m storing all the scripts I generate for these articles publicly on GitHub. The file to start with is CreateDatabase.sql. You can use the script in SampleData.sql to load in some data.
B-Tree
The name for the B-Tree index within PostgreSQL is a shorthand for a multi-way balanced tree index. Basically, similar to SQL Server, the values of an index are stored on pages in a doubly-linked list. The pages are laid out in a tree, with leaf pages storing the key column data. You define the key column, or columns, in the index definition:
CREATE INDEX radios_radioname ON radio.radios(radio_name);
This default behavior lets you ignore some syntax that you’d do well to start using now, since all the other indexes you create won’t work quite this way:
CREATE INDEX radios_radioname ON radio.radios USING BTREE(radio_name);
USING BTREE tells PostgreSQL what kind of index we want to build. You’ll see other commands in other types of indexes throughout the rest of the article.
This is in part because index names within a given PostgreSQL database are unique That’s a bit of a jump for this old SQL Server person who is used to having duplicate index names since they’re dependent on the table they’re indexing.
You can make a compound key by just adding more columns:
CREATE INDEX radios_radioname_radioid ON radios.radios
USING BTREE(radio_name, radio_id);
The B-tree indexes are the only index type in PostgreSQL to support the UNIQUE definition:
CREATE UNIQUE INDEX radios_radioid_unique ON radio.radios
USING BTREE(radio_id);
This index will ensure that no duplicate values are entered in the index key column or columns.
Another behavior unique to the B-tree index is the ability to store the data in a defined order. This also can help with returning the data in the correct order. Of course, generally speaking, this benefits queries with ORDER BY clauses, although there are also other conditions and circumstances where it helps. Like SQL Server, you can pick and choose whether the values in the key are ascending or descending. You also get to decide if NULL values are stored at the beginning or end of the index. For example, this index will sort the values of the radioname column in a descending order, but put all the NULL values first:
CREATE INDEX radios_radioname ON radio.radios
USING BTREE(radio_name DESC NULLS FIRST);
One thing different from SQL Server is the fact that there is only one type of B-tree index. All tables in PostgreSQL are stored as a heap table. There are not clustered indexes defining data storage. All the B-tree indexes are secondary storage, meaning that the columns defined in the index are what get stored in the index itself. Without getting too deep into performance tuning (which, let’s remember, I’m still not ready to teach), this can lead to performance headaches since access into the heap can be random. So, you can use the INCLUDE command to create a covering index, an index that satisfies the column needs in a query, avoiding extra reads to the heap:
CREATE INDEX radios_radioid ON radio.radios
USING BTREE(radio_id) INCLUDE(radio_name);
PostgreSQL also supports what it calls Partial Indexes which SQL Server calls a Filtered Index:
CREATE INDEX radios_radioname ON radio.radios USING BTREE(radio_name) WHERE radio_name IS NOT NULL;
In this case, only the values in the radioname column that are not null will be added to the index. You can even use a partial index with the UNIQUE definition, which opens up some interesting possibilities for indexing.
Finally, you can create indexes like this:
CREATE INDEX ON radios (adioed);
However, I didn’t demo that at the start because I think it’s a poor practice. PostgreSQL will name the index for you, which is great. But you could run that script more than one time, getting duplicate indexes. At which point, PostgreSQL will name the index for you, and you’ll end up withing something that looks like this:
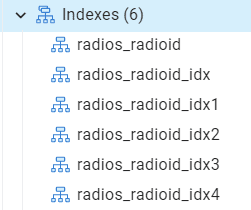
That’s the same index, five times. That means five times the storage, five times the maintenance, and five times the overhead. Not to mention a thoroughly confusing looking database. I would not recommend building your indexes in this fashion.
Another example would if you did something like this on one server:
CREATE INDEX ON radios (radioid); CREATE INDEX ON radios (radio_name);
Followed by this on another server:
CREATE INDEX ON radios (radio_name); CREATE INDEX ON radios (radioid);
You would end up with different indexes with matching names, causing all sorts of testing and development headaches. Therefore I started by naming my indexes myself. You want to avoid headaches by following simple, straightforward coding practices.
There are quite a few more details to the behavior of B-Tree indexes within PostgreSQL, but this covers the basics.
Hash Indexes
PostgreSQL supports a hash index on any data type. A hash is just the result of a calculation made against the data in the column that will always result in the same value for the same input. The hash stored is a 4-byte value, regardless of the size of the column being indexed. That makes the hash a great choice for larger amounts of data. Think long strings, like a web address. Creating a hash index is about the same as creating a B-Tree:
CREATE INDEX bands_band_name ON radio.bands USING HASH(band_name);
However, there are lot more limits to using a Hash index than there are the B-Tree. First of all, a Hash index can only be created with a single column, ever. Sure, any data type at all, but no compound keys and no INCLUDE for a covering Hash Index.
The biggest issue with Hash indexes is hash collision, when two, nearly, but not quite, identical values get the same hash value. This is exceedingly rare, but it can happen. This is why it’s strongly suggested that Hash indexes only be made for unique, or nearly unique data. The Hash index itself doesn’t support the UNIQUE operator, but it does largely function as if it was dealing with unique values. Depending on your data size and the data within, you may never experience hash collisions. When you do though, it can lead to serious performance issues.
The values of a Hash index are stored in what is called a hash bucket. The bucket has meta data that relates the high and low values stored in the bucket. This helps to make searching for a hash value a fast operation. When there are multiple copies of the hash value, additional checks are made to identify the appropriate value, slowing down access. This is a big part of why it’s suggested that you make Hash indexes only on unique or nearly unique data. A pointer to the heap table is stored along with the hash value itself.
Hash indexes can be partial, so to assist in making them unique, you could add a WHERE clause to the index creation:
CREATE INDEX logs_log_date ON logging.logs USING HASH(log_date) WHERE log_date > '1/1/2020';
The assumption here being values greater than ‘1/1/2020' will be more unique, making the index more efficient.
Another difference from the B-Tree index is that the Hash index doesn’t support index-only scans. However, that’s good because you wouldn’t want to see a hash scan, especially in places where collisions are possible because of the overhead that would create. Also, the output from the Hash index isn’t sorted which means the data is returned based on how it gets retrieved, meaning, no ORDER BY clauses. This lack of index scans is a big reason why equality, the = operator, is the only supported operator.
If you search for PostgreSQL Hash indexes online, you might find information suggesting that they shouldn’t be used because they are not written to the Write Ahead Log (WAL). However, that’s quite old information, from version 9 of PostgreSQL. It no longer applies, so if this kind of index can help, go ahead and use it.
GiST
The Generalized Search Tree (GiST) index isn’t really an index as such. Instead, it’s an access method that allows you to define different kinds of indexes in support of different data types and the search operations for those data types. GiST indexes are used for data types that aren’t dealing with ranges or equality like B-Tree or Hash indexes, like geometric data, documents or even images. Also, the GiST indexes are extensible, in fact, the documentation on the GiST index itself is much more focused on the extensibility of the indexes within the GiST access methods. Documentation of GiST behavior is actually scattered around within the various data types that it supports, making it a little difficult to learn how GiST indexes actually work. My advice, as someone just starting the process of learning GiST, would be to not worry about this until you move away from more basic data types like VARCHAR, DATE, etc.
Data within a GiST index is stored in a balanced tree, but the interesting bits are what is stored there. Instead of starting with key values or hash values like the previously discussed indexes, the storage in GiST indexes starts with a predicate. Then, a series of childtree rows that match that predicate are stored under the predicate.
There are already a number of extensions to the GiST indexes within PostgreSQL. So, for example, if you had geographic locations stored as points, you could add an index that will help you locate information in the geometric plane:
create index logs_location on logging.logs using gist(log_location);
The syntax is basically the same. The question is whether or not the data type in question already has functionality within the PostgreSQL indexes. If not, you would have to provide the behavior as well as define the index. That goes far beyond the goal of this article, so we’ll defer it to a later (much later) date.
SP-GIST
The Space Partitioned GiST, or SP-GIST is quite a lot like a GiST index in that it’s built to support a completely customizable set of data. In this case, the function is similar to a GiST index, but, the storage is partitioned so that data that lends itself to grouping through partitioning is going to benefit more from an SP-GIST index, as a SQL Server DBA, think, partition elimination. The data types supported out of the box are pretty similar to GiST, including geometric data like my example above. In fact, in this case, I’d probably pick that again for the syntax example:
create index logs_location on logging.logs using spgist(log_location);
The most interesting aspect of both GiST and SP-GIST is the extensibility. I’m not getting into that here. I’m still learning how to query these things. However, another interesting aspect is how GiST is focused first on operations, while SP-GIST is certainly focused on operations, but it’s the partitioning of the data that’s going to be the determining factor for this to be a superior choice when choosing indexes.
GIN
A Generalized Inverted Index (GIN) is effectively indexing for arrays. PostgreSQL has a number of different array data types. We can argue over whether or not arrays are an appropriate way to store data, the fact is, arrays within PostgreSQL work pretty well and offer up quite a bit of functionality. Plus, everyone is storing data in JSON or YAML. So you’re going to see array data types in use. Why not find a way to make your array faster?
The GIN index is effectively just a B-Tree index with a few wrinkles. The real interest is down at the page level. Instead of storing a key value and a tuple identifier (TID), the location on the heap where the data is stored, you get what is called a posting list. This is a list of all the values that match the key, and then a pointer to the TID. Although, that can get a little more complicated because as you get more and more duplicate values, you may get what is called a posting tree. This is, effectively, a way to extend a page into a set of pages, all of which have the TID value, a kind of B-Tree inside the B-Tree.
While arrays, especially JSON, is probably the primary purpose of the GIN index, you can also use it for full text searches. The same concepts apply as if you were looking through an array. After all, a big text document can be thought of as just a big array of text.
I currently don’t have a full text column in my sample database, so we’ll just index one of the arrays:
create index parksontheair_contacts on logging.parksontheair
using GIN(contacts);
You can’t use INCLUDE columns because nothing is getting stored at the page level except the PID or the posting list. You can have a multi-column GIN index through, which will make the index much more selective at the key level, while making it quite a bit bigger at the leaf level. In fact, the one big weakness that GIN indexes seem to have universally acknowledged is that they are slow when it comes to UPDATE statements. There are several workarounds, which I’m still not prepared to understand, let alone explain, that can help to mitigate this issue. For more information, check out this introduction.
BRIN
The Block Range Index (BRIN) is for storing ordered data range values, think dates. So when you have naturally grouped data that is likely to be returned as a set, postal codes come to mind, you have an index that is going to help you out. Further, when you’re trying to eliminate sets, say, give me dates less than a certain value, again, the BRIN index can help you out. Just remember, it is very much about ranges to data, not individual point lookup values which are better suited to a B-Tree index.
So, if you’re looking at range queries, BRIN is your friend. I know that a B-Tree can support them too, but, within limited types of queries, again, think ordered sets, BRIN not only outperforms the B-Tree, but usually takes up about 1% of the space. You read that correctly, a 99% space saving. Approximately. All the tests I’ve seen with large data sets bears this out.
The syntax is not going to shock you:
create index logs_log_date on logging.logs using BRIN(logs_log_date);
Since logs are always going to be, for the most part, entered in order, and accessed by date, this proves to be a useful index.
My editor, Louis Davidson, correctly pointed out, to a degree, the BRIN index is sort of like a clustered B-Tree index in SQL Server. The similarities are clear, the order of the data, and therefore where you start a seek or a scan, is determined by the index. The key difference is still the fact that this index doesn’t determine data storage. The data is still back in the heap.
Conclusion
To really see the benefits of indexes, you’re going to want to see examples. However, I’m still just scratching the surface on my learning of PostgreSQL. I’m just not ready to tell you what’s happening in an EXPLAIN plan yet. However, just talking about the types of data and queries supported does give you some indications as to how an index can benefit behaviors within PostgreSQL. As with other database systems, you can add more than one index to a given table to assist in performance. Just know that, as with other database systems, this can lead to additional overhead in terms of storage and processing as the data gets changed over time.
The post Index Types in PostgreSQL: Learning PostgreSQL with Grant appeared first on Simple Talk.
from Simple Talk https://ift.tt/DrFLTMg
via
No comments:
Post a Comment