PostgreSQL supports constraints much like any other database management system. When you need to ensure certain behaviors of the data, you can put these constraints to work. I’ve already used several of these in creating my sample database (available articles publicly on GitHub, in the CreateDatabase.sql file). I’ll explain those as we go. The constraints supported by PostgreSQL are:
- Not-Null Constraints
- Unique Constraints
- Primary Key
- Foreign Key
- Check Constraints
- Exclusion Constraints
Not-Null Constraints
One way we can ensure that our data is correct is by requiring it in the first place. If you create a table like this:
create table public.example (ID int, SomeValue varchar(50));
Because you didn’t define whether or not the columns can, or cannot, accept NULL values, then these will accept NULL values. The thing about NULL is that it’s really useful. Sometimes, people simply don’t have the information to give you, so allowing NULL is a good solution. Other times though, you absolutely need that value to be added to the rows of your table.
Let’s take the radio.radios table from the hamshackradio database as an example:
CREATE TABLE IF NOT EXISTS radio.radios
(radio_id int CONSTRAINT pkradios
PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
radio_name varchar(100) NOT NULL,
manufacturer_id int NOT NULL,
picture BYTEA NULL,
connectortype_id int NOT NULL,
digitalmode_id int NULL
);
Here I’ve used the clause NOT NULL on multiple columns to ensure that they must have information provided. In short, a radio must have a manufacturer (through the manufacturer_id column) and a name (through the radio_name column). Defining them with NOT NULL ensures that they must be filled out. You’ll also note that I use the NULL definition on the picture column. I could simply let the default take charge. For clarity, and to show intention, I use NULL instead.
So now, if I tried to insert data into the radio.radios table like this:
insert into radio.radios (manufacturer_id) values (2);
I’m going to get a very specific error:
SQL Error [23502]: ERROR: null value in column "radio_name" of relation "radios" violates not-null constraint
Detail: Failing row contains (4, null, 2, null, null, null).
It’s letting me know that I must provide a value for the radio_name column. You should note that I left out another NOT NULL column, connectortype_id. It was not included in the error since no additional checks were made after the first column, radio_name, failed it’s NOT NULL constraint check. If I were to just add the radio_name to the INSERT statement above, I’d get a new error. In short, you have to supply all columns that are marked as NOT NULL, unless those columns have default value defined (we’ll get to defaults in another article).
If I wanted to list all the constraints on a table, I could run a query like this:
select
c.conname,
ccu.table_schema,
ccu.table_name,
ccu.column_name,
c.contype,
pg_get_constraintdef(c.oid)
from
pg_constraint as c
join pg_namespace as ns on
ns.oid = c.connamespace
join pg_class as cl on
c.conrelid = cl.oid
left join information_schema.constraint_column_usage as ccu
on
c.conname = ccu.constraint_name
and ns.nspname = ccu.constraint_schema
where
ccu.table_name = 'radios';
Running this query results in the following results:

None of the NOT NULL constraints are listed. While these are considered constraints, they are only defined at the column level and don’t have any other definition outside of that. If you want to see which columns allow NULL values, you can use the following query:
select column_name from information_schema.columns where table_catalog = 'hamshackradio' and table_schema = 'radio' and table_name = 'radios' and is_nullable = 'YES';
This returns the picture and digitalmode_id columns, which, referring back to the DDL of the table, you will see matches.
Unique Constraints
Sometimes a column or set of columns in a table must be unique, that is, not allowing any duplicates. PostgreSQL provides a whole slew of mechanisms for defining a column, or columns, as unique within a table.
First, you can simply define a unique column like this:
CREATE TABLE IF NOT EXISTS public.uniqueval1
(id int not null,
myuniquevalue varchar(50) unique);
Now, only unique values will be allowed for the column myuniquevalue. However, an interesting thing has happened. Let’s look at the indexes on this table:
select i.indexname,
i.indexdef
from
pg_indexes as i
where
i.tablename = 'uniqueval1';
Running this query results in the following:

The way that PostgreSQL satisfies the unique criteria for the column is by creating a unique b-tree index. This is familiar to me as a SQL Server user. The question then becomes, why create a unique constraint at all? Why not just create a unique index? Well, you can truly do it either way. However, the documentation that using the unique constraint implies to the database might be important.
My rule of thumb is that a UNIQUE constraint is there to enforce that the values in a table’s column are different from one another. A unique index is there for performance. This helps to signal to people tuning your database’s queries that the index could be removed without harm, but the constraint is part of the core business rules for the database.
The advantage to the queries that are executed is going to be the same either way. However, it will be marked and listed as a constraint as well as an index:
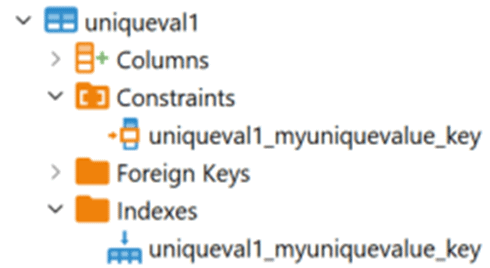
You can also do the same thing using a slightly different syntax:
create table if not exists public.uniqueval2
(id int not null,
myuniquevalue varchar(50) not null,
unique(myuniquevalue));
I have a problem with both these default approaches. It results in a default constraint name, and one in which I have no control. This affects the ability to work with your database within a source control system, so I’d change the syntax to this:
create table if not exists public.uniqueval3
(id int not null,
myuniquevalue varchar(50)
constraint uniqueval3_inameit unique not null);
or
create table if not exists public.uniqueval4
(id int not null,
myuniquevalue varchar(50),
constraint inameit unique(myuniquevalue));
In this manner I get to control the constraint names. If more than one column defines the constraint, you must use that second syntax with the definition as a column constraint.
You can also add a unique constraint to a table using ALTER:
--create a table without a constraint
create table if not exists public.uniqueval5
(id int not null,
myuniquevalue varchar(50) null);
--now add the constraint
alter table public.uniqueval5
add constraint mynewconstraint unique(id, myuniquevalue);
One point that is very important to understand here is how NULL values are handled in PostgreSQL, which may be different from other RDBMS you have worked with. A NULL value is, by definition, unknown. Since two unknown values do not equal each other, you can have, by default, multiple NULL values in your “unique” set of rows. Let’s see this in action:
create table if not exists public.nullnotunique
(id int not null,
nonuniqueval varchar(50) constraint notunique unique null
);
insert into public.nullnotunique(id,nonuniqueval)
values (1, null), (2,null), (3, 'one');
This will run without error because the NULL values are not duplicates per the definition. You can change this behavior if you are using PostgreSQL 15 or later by using unique nulls not distinct:
create table if not exists public.nullunique
(id int not null,
uniqueval varchar(50)
constraint nowunique unique nulls not distinct null);
insert into public.nullunique (id,uniqueval)
values (1, null), (2, null), (3, 'one');
Now when this query runs, you’ll immediately get an error:
SQL Error [23505]: ERROR: duplicate key value violates unique constraint "nowunique"
Detail: Key (uniqueval)=(null) already exists.
With the table definition changed using NULLS NOT DISTINCT, you now get one NULL row, and any subsequent NULL values are recognized as duplicates. You can specify the default behavior using NULLS DISTINCT.
For earlier versions, you might need to try other less straightforward solutions. For example, in the 14.5 version server I have for testing, I could add a computed column that takes the NULL value and makes it not NULL value.
ComputedUniqueeval varchar(50) GENERATED ALWAYS AS
(case when uniqueval is null
then 'impossible value'
else uniqueval END) STORED
);
Then add a filtered index on the computed column:
CREATE UNIQUE INDEX uniqueval_notnull_idx
ON public.nullunique (ComputedUniqueeval)
WHERE uniqueval IS NULL;
Of course, this is wasted space for the duplicated column and the extra index, plus the need to find an impossible value for uniqueval (and probably add a constraint to make sure that it is truly impossible.) However, almost always, implementation cost and complexity are going to be less important than data quality.
Primary Key Constraints
A primary key constraint is effectively the same as a unique constraint, with a few minor, but important differences. It’s going to be enforced by a unique index in the same manner and can be references by a foreign key constraint (which will be covered later in this article.) However, the primary key constraint is typically the columns used in a foreign key relationship, and the columns of a primary key may not allow NULL values. (Even if you define a primary key column as NULL it will be changed to NOT NULL as long as no data already exists.)
While you could dispense with the need for a primary key and simply define your key as a unique constraint or index, clarity is so important when it comes to code. Defining your structures appropriately to properly communicate how your database is designed and how it should be used. More about this in the foreign key section.
The syntax to create a primary key is very similar to creating a unique constraint:
create table if not exists public.pkexample (id int primary key not null, somevalue varchar(50));
As before though, this will result in a default name being created, so it’s better to do something like this:
CREATE TABLE IF NOT EXISTS radio.radios
(radio_id int CONSTRAINT pkradios PRIMARY KEY
GENERATED ALWAYS AS IDENTITY,
radio_name varchar(100) NOT NULL,
manufacturer_id int NOT NULL,
picture BYTEA NULL,
connectortype_id int NOT NULL,
digitalmode_id int NULL);
This will create a primary key named pkradios. You’ll also note I used an IDENTITY value here to ensure that this is a self-generating value as data gets added to the table.
As with the unique constraint examples above, you can define the primary key as a column definition. You must use that syntax if you have more than one column. You can also ALTER a table to add a primary key constraint. Other than that, the behavior of a primary key is basically identical to the unique constraint. I would still always use the primary key definition, if for no other reason, as a means of documentation.
One very interesting thing about creating primary key constraints is that if the values you are defining as the PRIMARY KEY allow NULL values, the PostgreSQL engine will attempt to fix that for you. For example, consider the following table:
create table if not exists public.badpkexample (id int null, somevalue varchar(50));
Check the results of the following metadata query:
select is_nullable from information_schema.columns where table_schema = 'public' and table_name = 'badpkexample' and column_name = 'id';
This will return YES. Meaning the column allows NULL values. After you add the following constraint:
alter table public.badpkexample
add constraint PKbadpkexample
primary key (id);
Query the metadata again and it will return NO. It has changed the column to no longer allow NULL values. If there was already data in the id column that contained NULL values, you would receive the following error message:
ERROR: column "id" of relation "badpkexample" contains null values
SQL state: 23502
Foreign Key Constraints
One of the key concepts behind a relational database is to relate one table to another in order to create meaning. Foreign keys define and control the referential integrity from one table to another. In my sample database, I have a table for radios and one for radio manufacturers. The foreign key definition between the two looks like this:
ALTER TABLE radio.radios
ADD foreign key (manufacturer_id)
references radio.manufacturers;
The primary key in radio.manufacturers consists of the manufacturer_id column. I have that same column with a matching data type in radio.radios. That allows me to create the foreign key between the two tables. You’ll note that while both tables are involved, we’re only altering the one table to add the constraint.
With the foreign key in place, I can only add manufacturer_id values to the radio.radios table where the radios.manufacturers contains that value in the primary key. Further, because of the constraint in place, I can’t delete the row with that value in the radio.manufacturers table (more on that below). This is how the foreign key constraint helps to ensure data integrity.
The way I defined the constraint in the text, it’s going to generate a default name. I can control the name by modifying the code.
alter table radio.radios drop constraint radios_manufacturer_id_fkey;
alter table radio.radios
add constraint radios_fk_manufacturer
foreign key (manufacturer_id)
references radio.manufacturers;
I can also add a foreign key as part of the table definition:
create table if not exists radio.radios
(radio_id int constraint pkradios primary key
generated always as identity,
radio_name varchar(100) not null,
manufacturer_id int not null,
picture BYTEA null,
connectortype_id int not null,
digitalmode_id int null,
constraint radios_fk_manufacturer3
foreign key (manufacturer_id)
references radio.manufacturers
);
The default behavior is for the foreign key to be checked when a row is deleted in the referenced table. If values exist, the delete is stopped. You can take direct control over this behavior and change it. For example, you can change when inside transaction process the check is made. Normally it’s made later in the process, but you can set it to happen first by using the ON DELETE RESTRICT option:
create table if not exists radio.radios
(
radio_id int constraint pkradios primary key
generated always as identity,
radio_name varchar(100) not null,
manufacturer_id int not null,
picture BYTEA null,
connectortype_id int not null,
digitalmode_id int null,
constraint radios_fk_manufacturer3 foreign key
(manufacturer_id)
references radio.manufacturers ON DELETE RESTRICT
);
That changes the default behavior. You can also command the default behavior by using the syntax ON DELETE NO ACTION, but I think that’s both wordy and unclear. Better to just use the default syntax. Let me take a moment to walk you through this diagram outlining this DELETE behavior:
So the default behavior is to find the rows to be deleted, delete them, then validate that there are no matching rows in any related tables. This is how SQL Server works as well. However, you can change where that check occurs by issuing the DELETE RESTRICT to the definition. In this case, before the transaction processing starts, you get a check to validate that no foreign key violation will occur.
All this may feel like semantics, but, there is an additional behavior that you can add to your transactions within PostgreSQL. There are quite few details to this behavior, but I’ll summarize it here. You can directly affect when some constraints, specifically UNIQUE, PRIMARY KEY, foreign key (REFERENCES) and EXCLUDE, are evaluated in an individual transaction. The default for these constraints is as outlined in each section. But you can defer all of them until later in the transaction. However, some foreign key constraints may be more likely to be violated. Those you can control through this setting, forcing them to be evaluated earlier in a transaction, saving unnecessary processing and rollbacks. Conversely, you can make all constraint checks immediate. By the way, NULL and CHECK constraints are always immediate.
We can also make it so that when a row in the radio.manufacturers table gets deleted, all associated radios also get deleted:
create table if not exists radio.radios
(radio_id int constraint pkradios primary key
generated always as identity,
radio_name varchar(100) not null,
manufacturer_id int not null,
picture BYTEA null,
connectortype_id int not null,
digitalmode_id int null,
constraint radios_fk_manufacturer foreign key
(manufacturer_id)
references radio.manufacturers on delete cascade
);
This is what CASCADE will do. However, there are implications here that are important. The radio.radios table is also referenced as a foreign key. If we start trying to delete rows from the radios table, it will fail because of those other foreign key constraints. Unless we also make all them CASCADE as well. However, at that point, you can get some pretty drastic behavioral issues within your database as locks are held while all the various tables go through their cascading deletes. Generally, this isn’t considered a good way to set things up.
For the most part, databases I have created have all used identifier values that cannot be changed, so I have rarely used the following settings, but PostgreSQL has some additional options for ON DELETE that could be helpful in some cases.
You can define ON DELETE SET NULL. This will change the column from whatever value it had, to a NULL value. Of course, the column must allow NULL values. You can also define ON DELETE SET DEFAULT. Then, whatever the default value of the column is (we have yet to cover defaults), it will be substituted for the deleted value. Once again though, that default value must meet fundamental referential integrity requirements, meaning, it has to be a value in the primary key of the radio.manufacturers table in our example.
Note: You can define a foreign key constraint that references a UNIQUE constraint, but there is one major caveat. NULL values in a column will guarantee that a match is made. As I will demonstrate in the Check Constraints section, constraints fail on a false condition, not a NULL (which any NULL value compared to another will cause)
Check Constraints
The check constraint is used to allow you to define your own data integrity rules for values in a row. It could be anything from the values in a column can only contain numbers greater than 100 to calculations between columns. The key is that all checks are made upon the insertion of a row, or on any subsequent updates, and can only access columns and values in the same row.
To take an example, in the United States the lowest possible frequency I can use as an amateur radio operator is 135.7kHz and the highest is 1300MHz or 1300000kHz. So, in my radio.bands table where I’m tracking frequencies, I could define a constraint for the frequency_start_khz column like this:
alter table radio.bands
add constraint minfrequency
check (frequency_start_khz >= 135.7);
Now I can’t accidentally add a value that is actually below my possible operating range.
To see an example of columns interacting, I should make sure that the frequency_start_khz is always below the frequency_end_khz that define the range of the band:
ALTER TABLE radio.bands
ADD CONSTRAINT startlessthanend
CHECK (frequency_start_khz < frequency_end_khz);
And I wanted to, I could make these into a single check:
alter table radio.bands
add constraint allinone
check (frequency_start_khz < frequency_end_khz
and frequency_start_khz > 135.7);
It’s really a question of deciding how you want to use your checks. I’d probably keep them separate because it makes for easier understanding of what each constraint is doing.
As with the other constraint examples throughout the chapter, you can also make the constraint a part of the table definition:
CREATE TABLE IF NOT EXISTS radio.bands
(
band_id int CONSTRAINT pkbands PRIMARY KEY
GENERATED ALWAYS AS IDENTITY,
band_name varchar(100) NOT NULL,
frequency_start_khz numeric(9,2) NOT null
CONSTRAINT minfrequency check (frequency_start_khz >135.7),
frequency_end_khz numeric(9,2) NOT NULL,
country_id int NOT NULL
);
As before, if I didn’t include a constraint name, one will be generated for me.
One thing to note about NULL values and constraints. Constraints operate slightly different from WHERE clauses. In a WHERE clause, a row is returned when a TRUE output comes. 1=1 returns TRUE, 1=2 returns FALSE, but 1=NULL is UNKNOWN. Only the TRUE value will return results. In constraints, the data fails the constraint only on a FALSE comparison.
For example, consider the following object.
create table public.nullconstraintcheck
(
id int not null,
value int NULL
);
Then you add a CHECK constraint requiring the column value to be 1.
alter table public.nullconstraintcheck
add constraint valueEquals1
check (value = 1);
It seems pretty clear which of these two following INSERT statement queries will work and which will fail.:
insert into public.nullconstraintcheck(id, value) values (1,1); insert into public.nullconstraintcheck(id, value) values (2,2);
The second will fail with the following error message:
ERROR: new row for relation "nullconstraintcheck" violates check constraint "valueequals1"
DETAIL: Failing row contains (2,2).
Note that if you run them both in the same batch, no rows will be added to the table. The following statement, however, will succeed because NULL = 1 is UNKNOWN, not FALSE.
insert into public.nullconstraintcheck(id, value) values (3,NULL);
If you need a constraint to consider NULL values in the criteria, you need to explicitly include an IS NULL expression or something similar. If you wanted to eliminate NULL values in some conditions, you need to explicitly state IS NOT NULL. For example, I will change the constraint to allow NULL values when the value of id is less than 5, but not allow NULL values 5 and up.
alter table public.nullconstraintcheck
drop constraint valueEquals1;
alter table public.nullconstraintcheck
add constraint valueEquals1
check ((value is not null and value = 1)
OR (id < 5 and value = 1));
Now you can see when you execute the following statements:
insert into public.nullconstraintcheck(id,value) values (4,NULL); insert into public.nullconstraintcheck(id,value) values (5,NULL);
The first will succeed, but the second one will not.
ERROR: new row for relation "nullconstraintcheck" violates check constraint "valueequals1"
DETAIL: Failing row contains (5, null).
I very much suggest that you test constraints thoroughly, especially when any referenced column allows NULL values.
Exclusion Constraints
An exclusion constraint is a bit like a unique constraint, but it’s different. Basically an exclusion constraint guarantees that if any two rows are compared, using the expressions defined in the constraint, that not all comparisons will return TRUE, at least one has to return FALSE or NULL. The idea is to get to a place where you can define more complex constraints across multiple columns in a table.
Let’s note right up front, if the columns you’re comparing are using only equality operators, then the exclusion constraint is exactly the same as a unique constraint. So, the idea here is that when you have a more complex comparison than straight equality, but you still want unique data based on the comparison, whatever it may be, you’ll be using an exclusion constraint.
Before you try to create exclusion constraints, be aware that there limits on the data types that can be used. If you’re interested in dates, text, stuff like that as things that may limit a row, which is very standard, you need to run one command first:
CREATE EXTENSION btree_gist;
This allows you to put constraints on standard scalar data types as opposed to arrays, geometry, and other more complex types. In this series of articles, I have tried to stick to what is strictly “in the box” in terms of PostgreSQL functionality, meaning, no extensions, and this does violate that goal. See, there are simply tons of extensions. Some, like btree_gist, are free and fairly fundamental to some behaviors. Others cost money, but add amazing behaviors. I’m currently trying to learn the core of PostgreSQL, not all possible extensions. However, constraints on standard data types is very likely, so I’ve gone ahead and broke my own rule in this instance.
With that in place, if we take the logging.logs table:
CREATE TABLE IF NOT EXISTS logging.logs
(log_id int CONSTRAINT pklogs PRIMARY KEY
GENERATED ALWAYS AS IDENTITY,
log_date timestamptz NOT NULL,
log_callsign text,
log_location point NOT NULL);
I’m going to define a constraint where the log_date, log_callsign can be the same, as long as the log_location changes. This would be useful for a contest like Parks on the Air where you can talk to the same people, but your location has to change, meaning, you’re in a different park. That constraint would be defined like this:
alter table logging.logs
add constraint uniquecontact exclude
using gist (log_date with =,
log_callsign with =,
log_location with ~=);
I can then add some data to the table:
INSERT INTO logging.logs
(log_date,log_callsign,log_location)
VALUES
('12/21/2022','KC1KCE','35.952, -96.152'),
('12/21/2022','KC1KCE','35.957, -96.127');
And that’s going to work fine. Even though the log_date and the log_callsign are the same, the log_location is different. If I then try to add this:
INSERT INTO logging.logs
(log_date,log_callsign,log_location)
VALUES
('12/21/2022','KC1KCE','35.952, -96.152');
I will get the following error:
SQL Error [23P01]: ERROR: conflicting key value violates exclusion constraint "uniquecontact"
Detail: Key (log_date, log_callsign, log_location)=(2022-12-21 00:00:00-06, KC1KCE, (35.952,-96.152)) conflicts with existing key (log_date, log_callsign, log_location)=(2022-12-21 00:00:00-06, KC1KCE, (35.952,-96.152)).
While you can get into some complex stuff with this constraint, it’s worth noting that the exclusion constraint isn’t the greatest performing constraint. Where possible, it’s recommended to use unique constraints if you can since they will perform better. However, when you have specific requirements, the exclusion constraint can make things better.
Conclusion
Those are all the constraint types within PostgreSQL. You should absolutely take advantage of these to ensure that your data is as clean as possible. Functionally, if you’re used to another RDBMS like SQL Server, most of these constraints are going to be very familiar, as are the behaviors of the constraints. A few things like the ability to control how NULL values are resolved in a unique constraint, or the very concept of exclusion constraints will be new. Overall though, I’m impressed with the functionality that is possible with the constraints in PostgreSQL.
The post PostgreSQL Constraints: Learning PostgreSQL with Grant appeared first on Simple Talk.
from Simple Talk https://ift.tt/wEkr3oi
via
No comments:
Post a Comment