This article explains what Snowflake data warehouse is and how it is different from other traditional data warehouses. This article will cover how to create virtual warehouses and different types of tables, how to handle semi-structured data, how to profile queries, and the benefits of clustering keys. Practical demonstrations of the concepts explained will be provided throughout the article.
Snowflake is a cloud-based solution only, with no on-premises version that you can purchase and install. For more information on cloud versus on on-premises, check my blog here.
What Is Snowflake?
Snowflake is a cutting-edge cloud-based data warehousing platform that stands out for its ability to efficiently store and analyse vast volumes of data. What sets Snowflake apart is its innovative architecture, which effectively separates storage and compute operations. Unlike traditional database solutions like Teradata and Oracle, Snowflake eliminates the need for installing, configuring, and managing hardware or software. It operates entirely on public cloud infrastructure. However, what truly distinguishes Snowflake and makes it unparalleled is its exceptional architecture and robust data sharing capabilities.
At its core, Snowflake Data Cloud is a fully managed, cloud-native solution that allows users to store and manage structured and semi-structured data from various sources in a central location. With Snowflake, organizations can scale up or down as needed to meet changing demand, without worrying about infrastructure or maintenance.
Moreover, Snowflake is available on multiple cloud platforms, including AWS, Azure, and Google Cloud Platform, providing users with the flexibility to choose the cloud provider that best suits their needs. In traditional databases compute and storage resources are limited. In those databases, increases in storage and compute resources must be applied together, as they are tightly coupled.
Snowflake solves the problem of tight coupling: customers can add compute and storage to their data warehouses independently from each other, and storage is virtually unlimited. You pay for what you use, and you don’t need to manage any hardware or software, as it is all fully managed by snowflake.
Snowflake is an incredibly versatile platform that excels in numerous data-related domains, including data warehousing, data engineering, data lakes, data science, and data application development. It seamlessly integrates with popular visualization tools like Tableau and Power BI, allowing users to create visually stunning and interactive dashboards. These dashboards provide a comprehensive view of data, enabling users to easily identify trends, patterns, and anomalies. With Snowflake’s integration capabilities, organizations can unlock the full potential of their data and make data-driven decisions with enhanced clarity and understanding.
How Can You Access Snowflake?
To access Snowflake, open your browser to https://www.snowflake.com. To access a free 30-day trial, no credit card required, just provide your personal details, and choose a cloud provider, and your account will be ready within minutes. The free trial is a great option for initial learning. I won’t go into more detail about the free trial setup here, but I can share more in the comments if anyone requires. However, it is very easy to set up.
What Is Unique About the Snowflake Architecture?
In this section I will share some of the ways that Snowflake’s architecture is unique (or certainly not common to most database management systems.
The Snowflake architecture represents a new architecture that was designed and built from the ground up. It is considered a hybrid of traditional shared-disk and shared-nothing database architectures, and it does not copy any traditional database architecture.
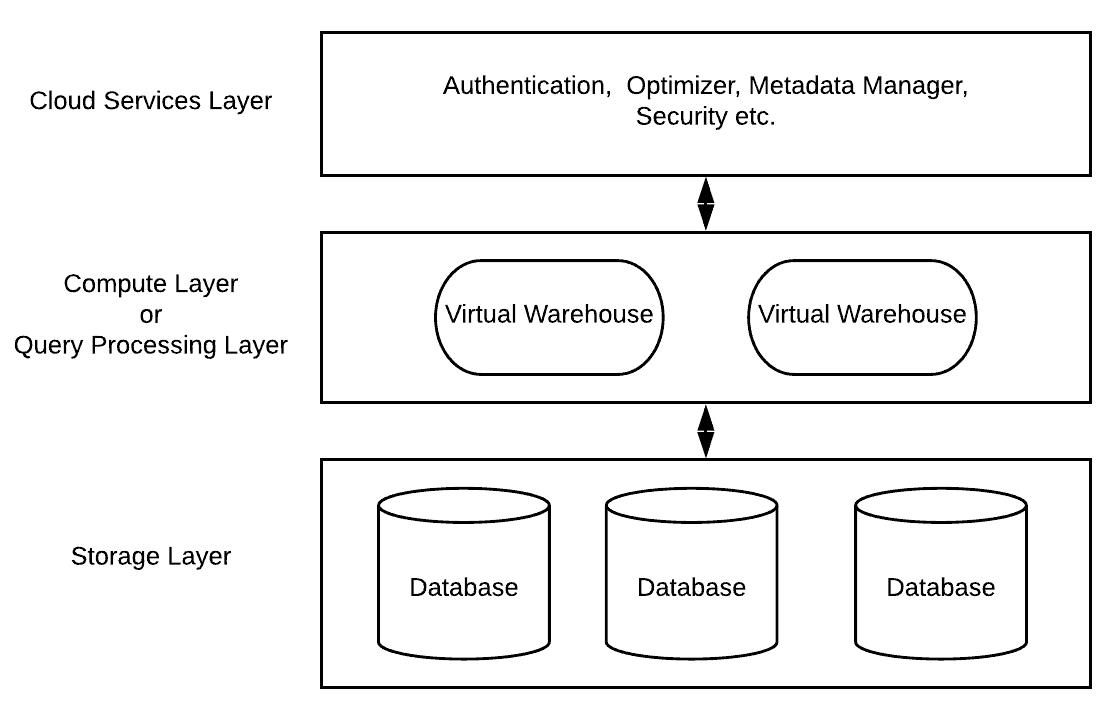
Figure 1 shows a high-level view of the Snowflake architecture.

Figure 1: Architecture of snowflake
As shown in Figure 1, the unique Snowflake architecture consists of three key layers:
Cloud Services
This is the “brain” of Snowflake where activities such as authentication, infrastructure management, metadata management, query parsing and optimization, and access control are all managed. These services tie together all the different components of Snowflake to process user requests, from login to query dispatch.
Query Processing
This layer is also known as Compute layer. Considered the “brawn” of Snowflake, the Query Processing layer performs data manipulations, transformations, and queries (data fetching) requested by users. All this processing is done by Snowflake using virtual warehouses.
Each virtual warehouse is a massively parallel processing (MPP) compute resource cluster. Each virtual warehouse consists of multiple nodes with CPU and memory automatically provisioned in the Cloud by Snowflake.
Here are some benefits of virtual warehouses:
- Comes in different sizes from extra small to 6XL and you can change the size of an existing virtual warehouse based upon your need. When you resize your virtual warehouse, running queries remain unaffected; only new queries submitted will use the new warehouse size.
- You only pay for the resources you utilize. If there are no workloads running, there are no costs associated with virtual warehouse compute. However, it’s important to note that you are charged for data storage regardless of usage. Can be started or stopped at any time. You can also auto-suspend, or auto-resume a Virtual Warehouse based upon a specific period of inactivity.
- Can be set to auto-scale. This means if more queries are launched on a Virtual Warehouse, increasing the load on it, it can automatically launch new clusters to accommodate the increased load and automatically scale down when the load decreases.
Database Storage Layer
Snowflake is a columnar database. When data is loaded into Snowflake, it is internally reorganized into an optimized, compressed, columnar format. Snowflake stores this optimized data in Cloud storage. Snowflake’s database storage layer is tasked with the responsibility of storing and managing data. It utilizes a scalable and elastic storage infrastructure, effectively decoupling compute, and storage operations. The data is organized into numerous micro-partitions, optimizing data access and query performance. Notably, Snowflake’s storage layer exhibits a high level of durability, automatically replicating data across multiple availability zones to ensure reliability. Moreover, it is designed to seamlessly handle extensive data volumes and supports a wide array of data formats, enabling organizations to efficiently store and analyse diverse data types.
The internal representation of data objects is not accessible, nor is it visible, to customers. Snowflake manages all aspects of storage file organization, metadata compression, and data storage statistics. This ensures that users do not need to worry about data distribution across different micro partitions.
As the storage layer is independent, customers need to pay only for the average monthly storage used. Since Snowflake is provisioned on the Cloud, storage is elastic and is charged as per terabyte (TB) of usage per month. Compute nodes connect with the Database Storage layer to fetch data for query processing. The main benefit of columnar databases store is it stores data in columns rather than rows, they are well-suited for analytical workloads that involve querying large amounts of data. Columnar databases can retrieve data more quickly than row-oriented databases because they only need to read the columns that are required for a particular query. This can result in significant performance improvements, particularly for complex queries that involve multiple joins and aggregations.
Creating a Virtual Warehouse
Now let’s discuss how to create virtual warehouses. By default, when we create a Snowflake account it comes with a default warehouse named COMPUTE_WH. You can create new warehouses at any time using the ACCOUNTADMIN and SYSADMIN security roles in Snowflake.
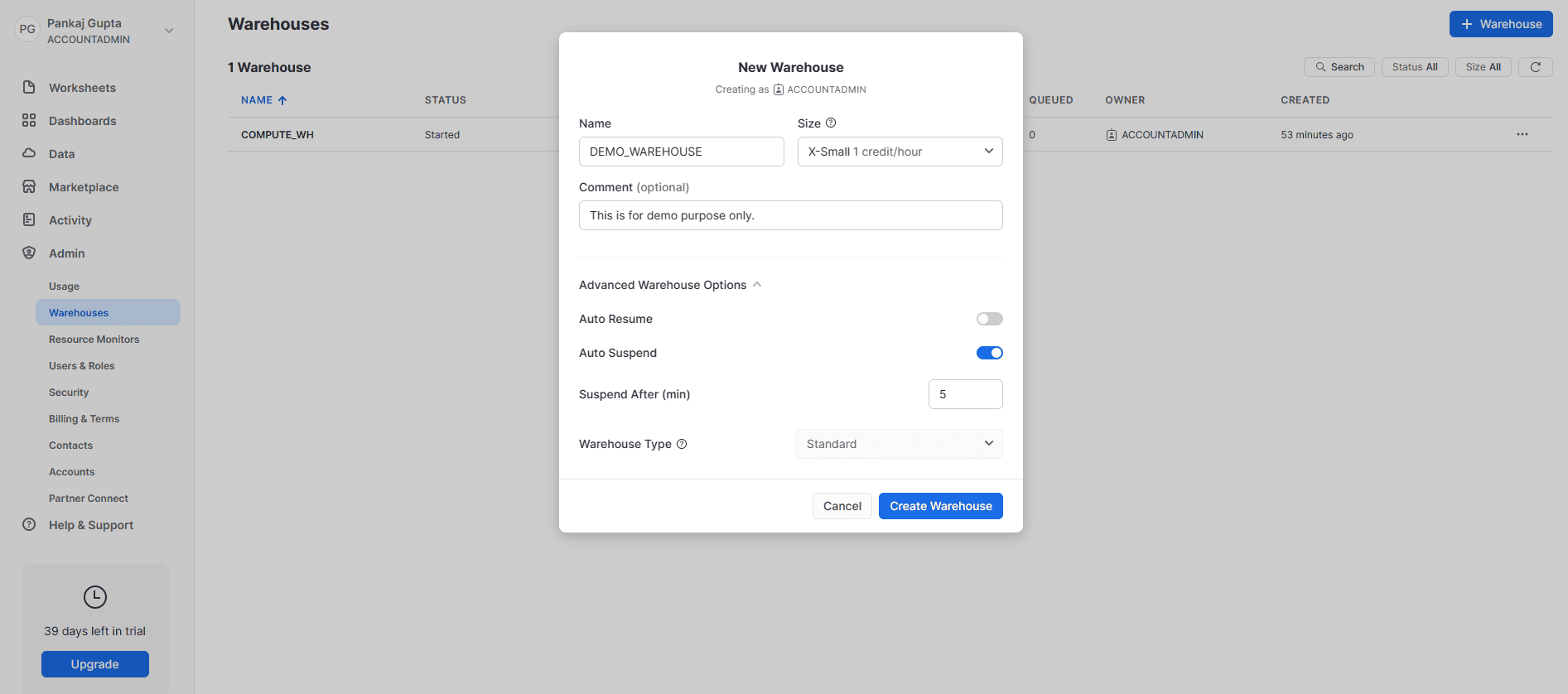
To create a new warehouse, log into the Snowflake web UI, go to the Warehouses tab and click the “+ Warehouse” button. Give your new warehouse a meaningful name. I have named my new warehouse DEMO_WAREHOUSE and kept the size as X-Small. You can also select Advanced Settings like Auto Resume and Auto Suspend from this New Warehouse dialog. Figure 2 shows the New Warehouse dialog.
Figure 2: how to create a virtual warehouse from snowflake UI.
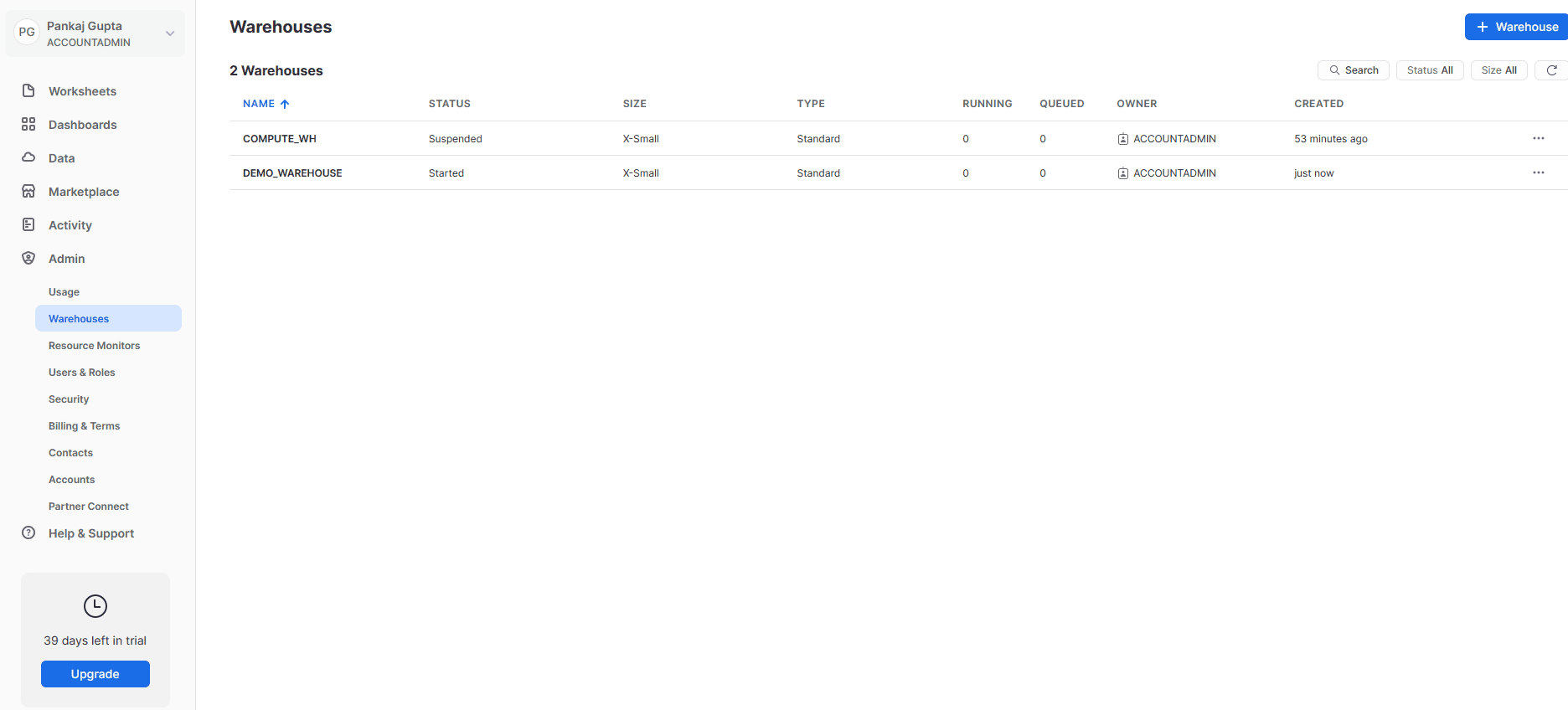
A warehouse is created within a few seconds, giving us a glimpse of the power of Cloud computing and Snowflake. We did not purchase any hardware, performed no installation, and yet we now have a data warehouse up and running within minutes. The main advantage is we can change the compute power on the fly, have multiple warehouses—like one for each department—and only pay for the resources we use. Figure 3 shows the Warehouses summary screen after we create our warehouse.
Figure 3: Virtual warehouse window after creation.
You can also create warehouse using the Snowflake SQL CREATE WAREHOUSE statement, shown in Figure 4.
CREATE OR REPLACE WAREHOUSE DEMO_WAREHOUSE
WITH WAREHOUSE_SIZE = XSMALL
COMMENT = 'This is for demo purpose only.'
AUTO_SUSPEND = 300
WAREHOUSE_TYPE = STANDARD;
Execute this code and you should see:
Figure 4: SQL’s and parameters for creating virtual warehouse.
You can find the full syntax and additional options related to virtual warehouse creation at the following link: https://docs.snowflake.com/en/sql-reference/sql/create-warehouse.html
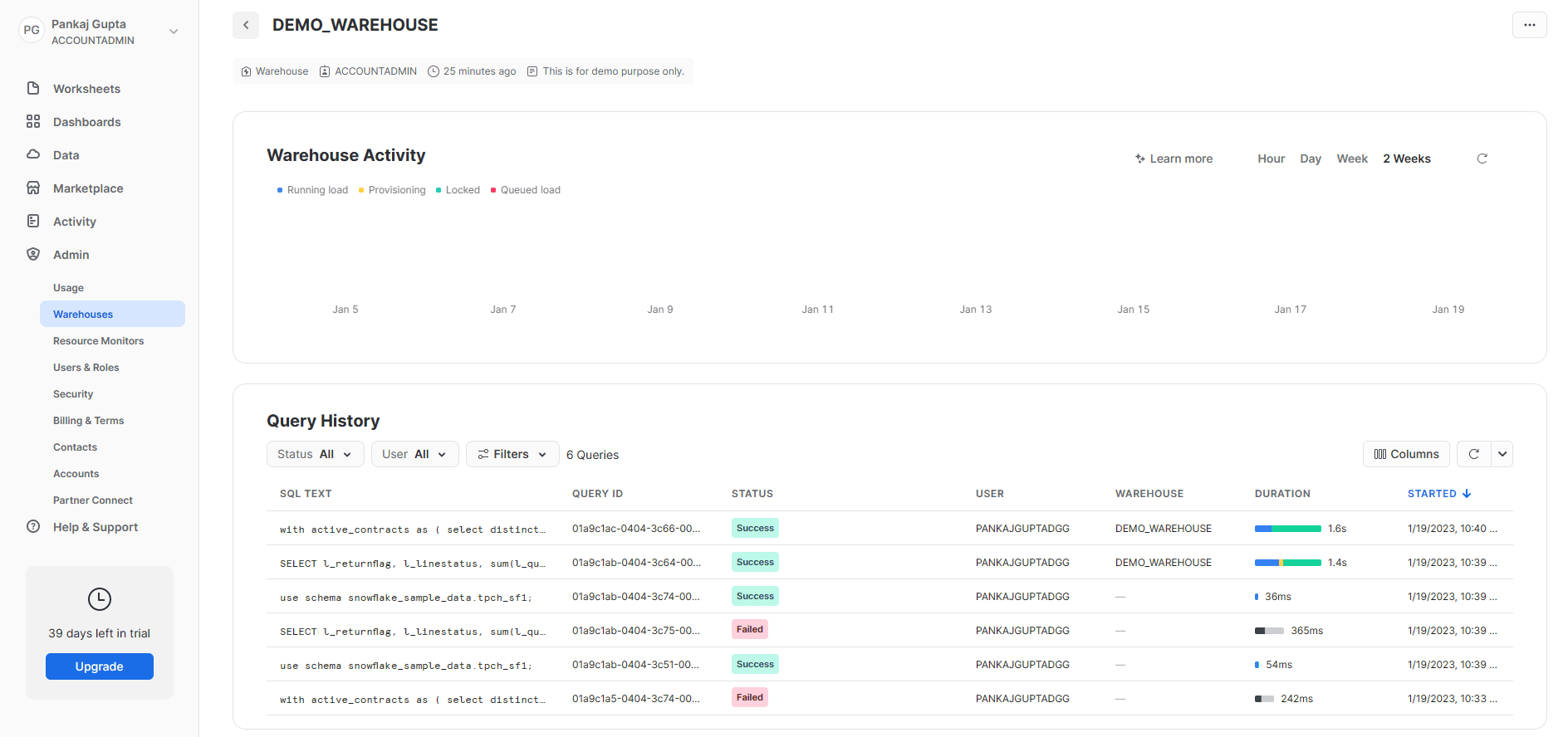
The Web UI provides access to additional features like transferring ownership, roles, and many other warehouse management functions. In the Warehouse Activity tab, you can see individual query execution metrics like executed query text, query executor, and duration, etc. Figure 5 shows the Warehouse Activity screen.
Figure 5: Web UI demo for available information.
Time travel and fail safe in Snowflake:
Time travel in Snowflake enables users to retrieve historical versions of data that were previously stored in the system. This feature allows users to query the data as it appeared at a specific moment in time, regardless of any subsequent changes or deletions that may have occurred.
For more details on Snowflake time travel, see the following documentation:
https://docs.snowflake.com/en/user-guide/data-time-travel
Within the context of Snowflake, the term “fail-safe” pertains to the system’s capability to prevent data loss, corruption, or compromise in the event of a system failure or outage. The fail-safe mechanisms implemented in Snowflake are intended to uphold data integrity and to reduce the possibility of any downtimes or data loss.
For more details on Snowflake fail-safe, see the following documentation:
https://docs.snowflake.com/en/user-guide/data-failsafe
Snowflake Tables
In this section, I will cover some of characteristics of Snowflake tables to help you understand the basic architecture of how tables are built and utilized.
Table Types
Snowflake provides 3 different types of tables: Temporary, Transient, and Permanent.
Temporary Tables
Temporary tables are like permanent tables with a caveat that they only exist for the current session. A temporary table is only visible to the user who created it and cannot be accessed by anyone else. When the session ends, the data in the temporary table gets purged.
The common use case for temporary tables is storing data, which is non-permanent and can be recreated, like aggregates, etc. Temporary tables serve as a staging area for data prior to undergoing transformations or being loaded into permanent tables. They are handy for storing intermediate results during complex data processing tasks and can improve query performance by materializing intermediate results.
Figure 6 shows the creation of a temporary table.
CREATE OR REPLACE TEMPORARY TABLE DEMO_TEMP
(
NAME VARCHAR(100),
EMPLOYER VARCHAR(100),
ID NUMBER
);
Figure 6: Code for creating a temporary table.
You can find the full syntax and additional options related to create table creation at the following link: https://docs.snowflake.com/en/sql-reference/sql/create-table.
Transient Tables
Transient tables operate like permanent tables except for the fact that they do not have a fail-safe period associated with them. The maximum time travel retention period for transient tables is one day, while permanent tables in the Enterprise Edition or higher can retain data for up to 90 days. Data in the transient table is persisted until the table is explicitly dropped, so unlike a temporary table the transient table will remain even after the session it was created in ends.
There is no fail-safe cost associated with it, but it does contribute to overall storage expenses for accounts.
Figure 7 shows how to create a transient table.
CREATE OR REPLACE TRANSIENT TABLE DEMO_TEMP
(
NAME VARCHAR,
EMPLOYER VARCHAR,
ID NUMBER
);
Figure 7: Code to create a transient table.
Permanent Tables
Permanent tables have a fail-safe period and provide an additional level of data recovery and protection. A permanent table is created when data must be stored for a longer period. Permanent tables persist until explicitly dropped. Figure 8 shows the creation of a permanent table.
CREATE OR REPLACE TABLE DEMO_PERM
(
NAME VARCHAR(100),
EMPLOYER VARCHAR(100),
ID NUMBER
);
Figure 8: Web UI creating a permanent table.
Inserting data into DEMO_PERM table:
INSERT INTO DEMO_PERM
VALUES ('Pankaj Gupta','Test Employer','1');
INSERT INTO DEMO_PERM
VALUES ('Ravi Jain','DataDog','2');
This will insert the following data as shown in Figure 9:
Figure 9: Web UI showing inserted data.
Table 1 summarizes the differences between Snowflake table types and their impact on time travel and fail-safe functionality.
|
Table Type
|
Persistence
|
Time Travel Retention Period (Days)
|
Fail-safe Period (Days)
|
|
Temporary
|
Remainder of session
|
0 or 1 (default is 1)
|
0
|
|
Transient
|
Until explicitly dropped
|
0 or 1 (default is 1)
|
0
|
|
Permanent (Standard Edition)
|
Until explicitly dropped
|
0 or 1 (default is 1)
|
7
|
|
Permanent (Enterprise Edition and higher)
|
Until explicitly dropped
|
0 to 90 (default is configurable)
|
7
|
Table 1. Differences Between Snowflake Table Types.
Clustering Keys and Query Performance
In this section we will consider clustering keys in Snowflake and their effect on query performance for large tables.
The clustering key in Snowflake is a designated column or set of columns that dictates the physical storage order of data within a table. It plays a crucial role in determining how data is structured and grouped together on disk, leading to notable effects on query performance and the efficiency of data retrieval. By carefully selecting the clustering key, you can optimize the organization of data on disk, resulting in improved query performance and faster access to relevant information.
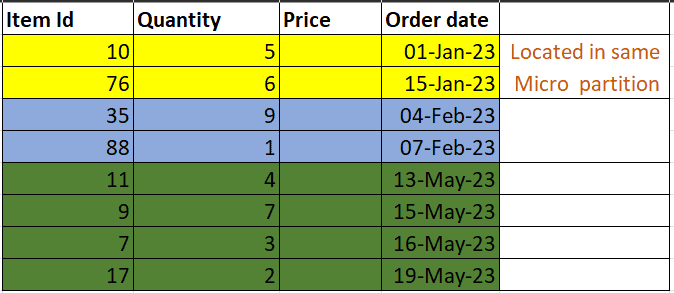
Fig. 14 shows a cluster table where data with same month in kept in same micro partitions.
Within Snowflake’s architecture, micro-partitions refer to individual units of data storage that comprise a section of a table’s data. These micro-partitions are designed to contain a relatively small amount of data, usually ranging between 50 MB to 500 MB. Moreover, data stored within each micro-partition is compressed, columnar-organized, and saved in a specialized format, which is fine-tuned to optimize query processing performance.
Clustering in snowflake relates to arrangement of rows co-located with similar rows in the same micro-partitions. The effect of clustering can be seen for very large tables (larger than 1+ TB) when ordering of data when initially loaded data was not ordered or an excessive number of Data Manipulation Language (DML) operations have been performed against the table (like INSERT, UPDATE, etc.), causing the table’s natural clustering to degrade over a period.
When a clustering key is defined on a table, the automatic clustering service will co-locate rows with similar values in their cluster key columns to the same micro-partitions.
The Benefits of Defining Clustering Keys:
- Better scan efficiency, making your queries execute more efficiently.
- Less table maintenance is required if auto-clustering is enabled, and data is not being inserted in order.
- Better column compression.
A clustering key can be defined on a table at the time of creation or by using the ALTER TABLE statement if the table already exists.
To demonstrate, we will create a table without any clustering key and insert data in it, using the following code. The results of this query are shown in Figure 15.
CREATE OR REPLACE TABLE DEMO_NO_CLUSTERING (
EMP_ID NUMBER(10,0),
DEPT_ID NUMBER(4,0),
EMP_NAME VARCHAR(4),
HOME_ADDR VARCHAR(1000)
);
INSERT OVERWRITE INTO DEMO_NO_CLUSTERING
SELECT
seq4() AS EMP_ID,
uniform(1, 1000, random()) AS DEPT_ID,
randstr(4, random()) AS EMP_NAME,
randstr(1000, random()) AS HOME_ADDR
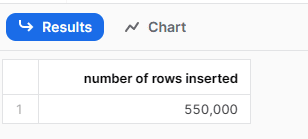
FROM table(generator(rowcount => 550000));
This will return:
Figure 15: Snowflake web UI showing SQL run of query.
We can then select a record from our sample table using a SELECT query with a WHERE clause filter, as shown in the following code:
SELECT *
FROM DEMO_NO_CLUSTERING
WHERE DEPT_ID = 1;
The output is shown in Figure 16.
Figure 16. SELECT from sample non-clustered table.
Semi-Structured Data in Snowflake
Here we will look at the power of Snowflake’s semi-structured data handling capability. We will create a table with the VARIANT data type and use it to load semi-structured JSON data. Figure 10 shows the creation of a table with a VARIANT data type column and loading JSON data into it.
For example:
CREATE OR REPLACE TABLE DEMO_TEMP_VARIANT
(
LOCATION VARIANT
);
Insert below test data for loading into table.
INSERT INTO DEMO_TEMP_VARIANT
SELECT parse_json(column1)
from values
('{
"id": "1234",
"name": {
"first": "Pankaj",
"last": "Gupta"
},
"company": "demo_company",
"email": "pankaj.gupta@demo_company.info",
"phone": "+1 (123) 456-7890",
"address":
"268 Havens Place, Dunbar, Rhode Island, 7725"
}')
, ('{
"id": "5678",
"name": {
"first": "Arpan",
"last": "Rai"
},
"company": "DIGIGEN",
"email": "Arpan.Rai@DIGIGEN.net",
"phone": "+1 (111) 222-3021",
"address":
"441 Dover Street, Ada, New Mexico, 5922"
}');
Figure 10: Running SQL and INSERT query in Snowflake web UI.
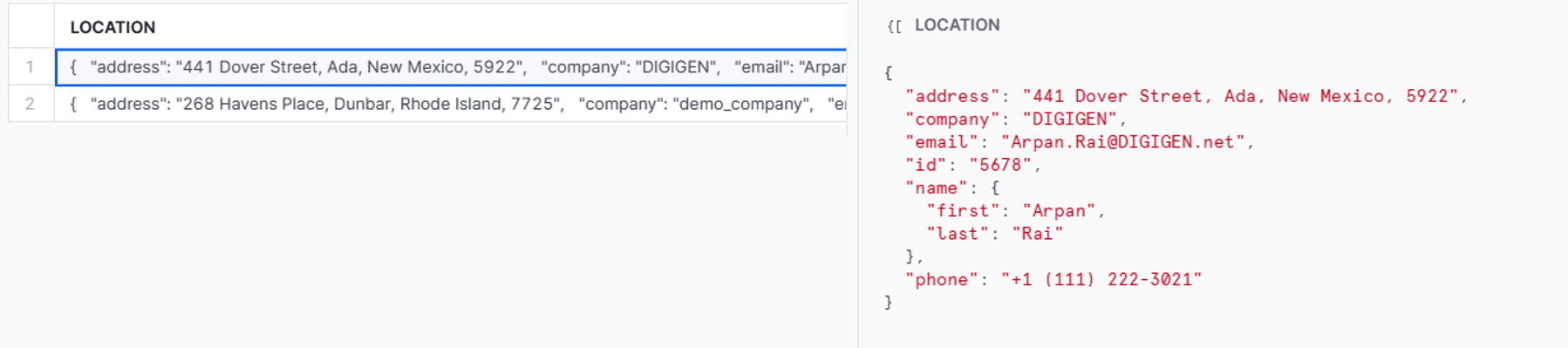
Once our JSON data has been inserted into the Snowflake table, we can view it with a SELECT query, as shown in Figure 11.
SELECT *
FROM DEMO_TEMP_VARIANT;
Executing this code will return:
Figure 11: Showing data in Snowflake web UI.
Now we’ll consider the technique for parsing the JSON data in this table. One thing to keep in mind is that VARIANT values are not strings; VARIANT values contain strings. The operators “:” and subsequent “.” and “[]” always return VARIANT values containing strings.
Below are some pre-defined functions which can be used with variant data.
PARSE_JSON – pre-defined function in Snowflake that facilitates the extraction of data from strings that are formatted in JSON. This function takes a solitary parameter, which is a string that contains the data formatted as JSON, and subsequently returns a variant data type that can be used in SQL queries.CHECK_JSON built-in function in Snowflake that validates whether a string contains valid JSON data. This function can be used to check if a given string is formatted correctly as JSON and returns a Boolean value of TRUE or FALSE
Sample query
SELECT CHECK_JSON(
'
{
"id": "1234",
"name": {
"first": "Pankaj",
"last": "Gupta"
}
}')
as is_valid;
Using Snowflake’s semi-structured data extraction operators, our JSON data can simply be fetched in a flat table format using a simple query like the one shown in Figure 12.
SELECT
(LOCATION:id) as id,
(LOCATION:name:first) as first_name,
(LOCATION:name:last) as last_name,
(LOCATION:company) as company,
(LOCATION:email) as email,
(LOCATION:phone) as phone,
(LOCATION:address) as address
FROM
DEMO_TEMP_VARIANT;
Figure 12:SQL for parsing JSON in Snowflake web UI.
Figure 13 shows the results of our JSON extraction query.
Figure 13: Flattened semi structured JSON data.
Query History and Profiling
To look as the query plan of queries that have been executed. You
can go to query profiling page through activity tab 🡪 Query History:
Figure 17: query history tab
Select the query for which you want to see profile.
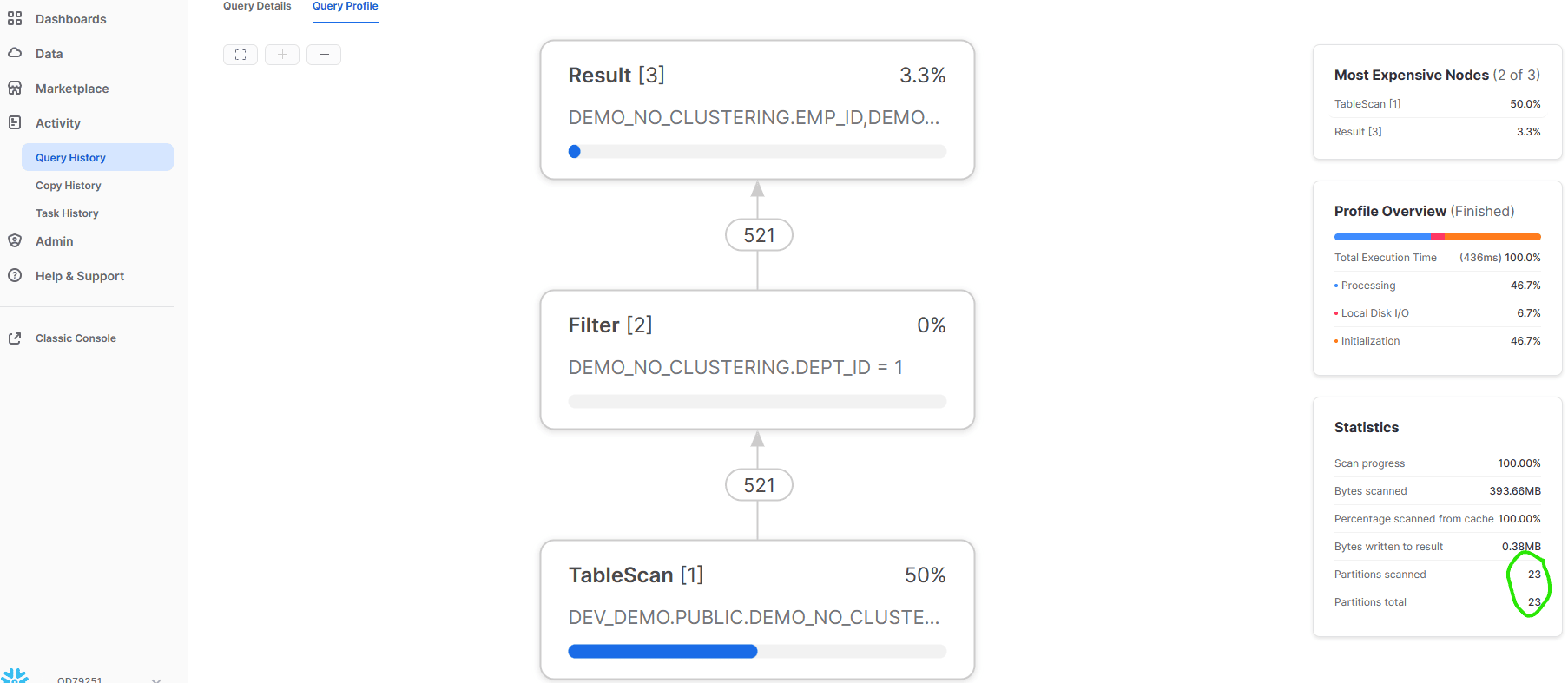
Now when we look at the query profile, we notice this table had 23 micro-partitions, and all 23 were scanned while searching for records where DEPT_ID = 1. This result is shown in Figure 18.
Figure 18: Snowflake web UI showing query profile result for table with no clustering key.
Now let’s create an equivalent table with a clustering key and assess how same select query works. The query in Figure 19 creates our new table with a clustering key.
CREATE OR REPLACE TABLE DEMO_CLUSTERING
cluster by (DEPT_ID) (
EMP_ID NUMBER(10,0),
DEPT_ID NUMBER(4,0),
EMP_NAME VARCHAR(4),
HOME_ADDR VARCHAR(1000)
);
INSERT OVERWRITE INTO DEMO_CLUSTERING
SELECT
seq4() AS EMP_ID,
uniform(1, 1000, random()) AS DEPT_ID,
randstr(4, random()) AS EMP_NAME,
randstr(1000, random()) AS HOME_ADDR
FROM table(generator(rowcount => 550000))
ORDER BY DEPT_ID;
Figure 19: DDL and SQL for execution in snowflake web UI
Now run the equivalent SELECT query from our previous example against the new table, as shown.
SELECT *
FROM DEMO_CLUSTERING
WHERE DEPT_ID = 1;
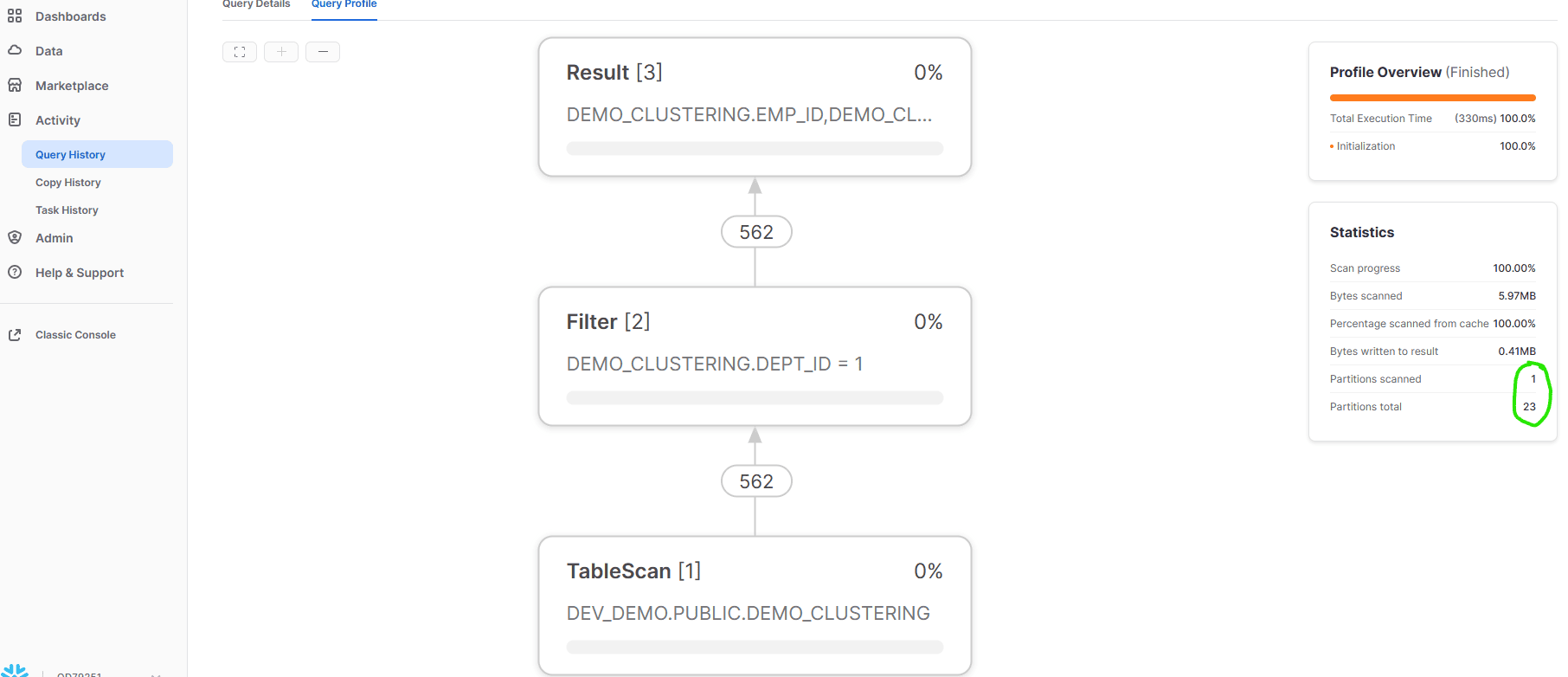
When we look at the query profile, we can clearly see that with a clustering key enabled on the DEPT_ID column, this query scans only 1 partition of the 23 available. If there are thousands of partitions, then clustering key can increase CPU resource efficiency and result in more efficient execution. The key thing here is that data should be inserted for the clustering key in the sorted order in our table. This is why we apply the ORDER BY clause to the SELECT query that feeds our INSERT statement. If you do not load data in sorted order for DEPT_ID, it will not organize micro-partitions properly and will still scan all the micro-partitions. Figure 20 shows our query profile after applying a clustering key and inserting our data into the table in clustering key order.
Figure 20: Snowflake web UI showing query profile result for table with clustering key.
Within most traditional database management systems (DBMSs), utilization of the ORDER BY clause within a SELECT query that feeds a DML statement, such as UPDATE or DELETE, does not inevitably guarantee ordering of the resulting data. Consequently, rows retrieved by such a query might not consistently maintain the same order every time the query is executed, even if the ORDER BY clause is used.
Nevertheless, this characteristic distinguishes Snowflake from most other DBMSs. When using Snowflake, the ORDER BY clause in a SELECT query that feeds a DML statement does guarantee ordering of the resulting data. Hence, rows returned by the query will persistently maintain the same order, regardless of how many times the query is executed.
This guarantee of ordering can be attributed to Snowflake’s unique architecture. Its micro-partitioning technique and query optimization methods permit highly efficient and parallelized query execution, resulting in ordered outputs even when using the ORDER BY clause in a DML statement.
Summary
In this article we considered the basic differences between an on-premises infrastructure and a Cloud-based infrastructure. We then discussed the Snowflake architecture and created a new virtual warehouse. We discussed the different types of tables Snowflake supports and created each type of table. We also covered how to load semi-structured data in Snowflake in a VARIANT data type column, and how to extract JSON data in a tabular format. Finally, we discussed clustering keys and performed a practical demonstration that showed the difference between tables created with and without a clustering key.
References
Snowflake Documentation: https://docs.snowflake.com/en/
Here are a few popular Cloud providers you can visit to get additional information. There are many more, and this article does not endorse any specific one. The links are for informational purposes only.
Amazon Web Services: https://aws.amazon.com/
Microsoft Azure: Cloud Computing Services | Microsoft Azure
Google Cloud Platform: Cloud Computing Services | Google Cloud
The post Snowflake: A Cloud Warehouse Solution for Analytics appeared first on Simple Talk.
from Simple Talk https://ift.tt/0vnfIeK
via