A challenge that reappears periodically in the world of databases (especially database management) is the need to run code on a subset of databases and to do so in a nuanced manner. Some maintenance or metrics collection processes can be simply run against every database on a server with no ill-effect, but others may be app-specific, or need to omit specific sets of databases.
This article dives into how to create and customize your own solution, tackling everything from filtering databases to validating schema elements to error-handling.
What About sp_MSforeachdb?
The sp_MSforeachdb system stored procedure can be used to run T-SQL across many SQL Server databases. While that sounds ideal, it is an undocumented black box that does not always perform the way you may want it to. Undocumented features can be used with extreme caution, but it is inadvisable to make them a key part of important processes as they may change, be deprecated, or be discontinued with little or no notice.
In addition, sp_MSforeachdb has no ability to be customized or expanded upon. What you see is what you get and there is no flexibility if it does not do precisely what you want.
This article covers some of the things done in a procedure named dbo.RunQueryAcrossDatabases that you can download in a .zip file: RunQueryAcrossDatabases_FullScript.
Code Reusability
The common solution to this problem is to create new code that iterates through databases for each application or process whenever it is needed. While this certainly is functional, it poses all of challenges of code maintainability when the same code is copied into many places.
If a new database appears that is an exception the rules, then each and every process would need to be inspected and adjusted as needed to ensure that the exception is accounted for. Even on a small number of database servers, it is likely that one might be omitted and cause unexpected (and perhaps, not quickly noticed) harm. If hundreds of servers are being maintained, then the odds of missed many become quite high.
A single universal stored procedure that is used for this purpose ensures that when changes are needed, they can be made a single time only:
- Update the stored proc in source control.
- Test it in dev/QA.
- Deploy to production.
Because this process follows the typical one used for deploying application-related code, it is familiar and less likely to result in mistakes or omissions. In addition, a solution that is parameterized can ensure that when changes are needed, they can be made to parameter values and not to source code, minimizing the need for more impactful changes.
Building a Code Execution Solution
To build a solution that executes T-SQL for us, there is value in listing the steps needed to accomplish this task:
- Create and apply filters to determine which databases should have code executed against them.
- Create code that will run against that database list.
- Iterate through that database list.
- Run the code against each of those databases.
When written out as a list, it becomes clear that this task is far simpler than it sounds, which means that our job of writing this code can move quickly through the necessities and into customization (which is far more fun!)
Note that a complete/working solution is attached at the end of this article. Feel free to download and customize it to your heart’s content!
Create and Customize a Database List
The key to this process is to create a list of databases that code will be run against. This may be as simple as an explicit list of N databases, but more often than not will involve some more detailed logic. For example, there may be a need to filter out all databases that do not meet a specific naming convention. Alternatively we may want to exclude databases by name.
Ultimately, this entire task comes down to querying sys.databases and filtering based on information in the system view. Yeah, you heard that right: SELECT from a view and add a WHERE clause and DONE! OK, it isn’t quite that simple, but we’ll do our best to not make this complex. In order to create this process, dynamic T-SQL will be used. It is possible to do this via standard SQL by creating/modifying a database list step-by-step, adding and removing databases along the way. While this certainly works, I find the resulting code even more convoluted than dynamic SQL (yes, I said that!).
As a brief reminder, sys.databases is a system catalog view that provides a row per database on the server. Included in that data is a hefty amount of metadata and operational information that tells us how a database is configured and its current state. The following query returns some basic (but useful) information from this view:
SELECT
databases.name,
databases.database_id,
databases.create_date,
databases.compatibility_level,
databases.collation_name,
databases.user_access_desc,
databases.state_desc,
databases.recovery_model_desc
FROM sys.databases;
The results provide a whole lot of actionable info:
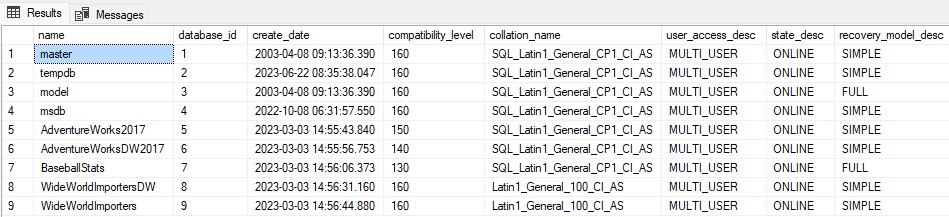
When inspecting databases, knowing the compatibility level, collation, or current state could be critical to making decisions about whether or not to query them and especially apply changes to them. At a higher level, there is value in knowing this information regardless. For example, that BaseballStats database of mine…should that really be set to compatibility level 130 (SQL Server 2016)?! If that were an oversight, then it can be corrected. Similarly, should only two databases be using the FULL recovery model? Another fine question for an administrator/operator to consider.
Note that the database list above will be used for the duration of this article. The databases on your test server, as well as related objects and metadata will vary from what is presented here.
To start, let’s limit the database filtering to database name only. Additional customization based on other details is relatively easy to add once a starter-query has been constructed. To do this, a handful of variables will be introduced:
DECLARE @DatabaseNameLike VARCHAR(100) = 'WideWorldImporters'; DECLARE @DatabaseNameNotLike VARCHAR(100); DECLARE @DatabaseNameEquals VARCHAR(100);
These filters can be added one by one as filters to sys.databases. If any filter is NULL, it can be ignored:
SELECT
*
FROM sys.databases
WHERE (@DatabaseNameLike IS NULL
OR name LIKE '%' + @DatabaseNameLike + '%')
AND (@DatabaseNameNotLike IS NULL
OR name NOT LIKE '%' + @DatabaseNameNotLike + '%')
AND (@DatabaseNameEquals IS NULL OR name = @DatabaseNameEquals);
If @DatabaseNameLike is set to 'WideWorldImporters' and the other variables are left NULL, then the results of the above query would return:

There are no limits to filtering like this. It would be relatively easy to add additional filters for names that start with a prefix, end in a suffix, or any other comparison that can be dreamed up.
Another common need is to omit system databases from queries. Running some T-SQL across many databases may include model, master, tempdb, and msdb, but oftentimes will not. This added filter to the query above can be handled by another variable and one more WHERE clause:
DECLARE @DatabaseNameLike VARCHAR(100) = 'WideWorldImporters';
DECLARE @DatabaseNameNotLike VARCHAR(100);
DECLARE @DatabaseNameEquals VARCHAR(100);
DECLARE @SystemDatabases BIT = 0;
SELECT
*
FROM sys.databases
WHERE (@DatabaseNameLike IS NULL
OR name LIKE '%' + @DatabaseNameLike + '%')
AND (@DatabaseNameNotLike IS NULL
OR name NOT LIKE '%' + @DatabaseNameNotLike + '%')
AND (@DatabaseNameEquals IS NULL
OR name = @DatabaseNameEquals)
AND (@SystemDatabases = 1
OR name NOT IN ('master', 'model', 'msdb', 'tempdb'));
If a search is run using @DatabaseNameLike = 'B' and @SystemDatabases = 1, then the results will look like this:

If the same search is performed, but with @SystemDatabases = 0, then the results are reduced to only a single result:

Sys.databases contains quite a few columns that can be filtered as easily as the name, such as compatibility level, collation name, user access (is it in single or multi-user?), state, recovery model, and much more. Adding filters can be accomplished on any column in the same fashion as above. For example, if there is a need to query all databases on a server – but only those that are online and multi-user, the query above could be adjusted as follows:
DECLARE @DatabaseNameLike VARCHAR(100) = 'WideWorldImporters';
DECLARE @DatabaseNameNotLike VARCHAR(100);
DECLARE @DatabaseNameEquals VARCHAR(100);
DECLARE @SystemDatabases BIT = 0;
DECLARE @CheckOnline BIT = 1;
DECLARE @CheckMultiUser BIT = 1;
SELECT
*
FROM sys.databases
WHERE (@DatabaseNameLike IS NULL
OR name LIKE '%' + @DatabaseNameLike + '%')
AND (@DatabaseNameNotLike IS NULL
OR name NOT LIKE '%' + @DatabaseNameNotLike + '%')
AND (@DatabaseNameEquals IS NULL
OR name = @DatabaseNameEquals)
AND (@SystemDatabases = 1
OR name NOT IN ('master', 'model', 'msdb', 'tempdb'))
AND (@CheckOnline = 0
OR state_desc = 'ONLINE')
AND (@CheckMultiUser = 0
OR user_access_desc = 'MULTI_USER');
Run this query, and you will get back WideWorldImportersDW and WideWorldImporters. To test the offline change, let’s set WideWorldImportersDW offline:
ALTER DATABASE WideWorldImportersDW SET OFFLINE;
If you want to make it happen immediately on your local machine, you can add: WITH NO_WAIT ROLLBACK IMMEDIATE; and it will kill existing transactions/connections and apply the ALTER DATABASE command.
Now, run the query and the offline database is removed from the results:

We’ve dove into filtering the database list by metadata in sys.databases. Next up is how to filter based on the existence (or non-existence) of objects.
Validating the Presence of Objects
Another common challenge when executing a query across any number of databases is to only run the query if a specific table or object exists. Some examples of this include:
- Select data from a table, but only if it exists (or if a specific column in that table exists).
- Execute a stored procedure, but only if it exists. This prevents throwing “Object Not Found” errors.
- Validate if an object exists and log details about it, depending on its status.
- Check if a release completed successfully.
At its core, this is not a challenging task. There are many views available in SQL Server that allow us to check and see if an object exists or not. For example, the following code will check if the table Sales.Customers exists in the WideWorldImporters database:
SELECT
COUNT(*) AS DoesItExist
FROM WideWorldImporters.sys.tables
INNER JOIN WideWorldImporters.sys.schemas
ON tables.schema_id = schemas.schema_id
WHERE tables.name = 'Customers'
AND schemas.name = 'Sales';
The result is straightforward, since there is one table name Sales.Customers in the WideWorldImporters database:
What I want is for the logic behind this to be encapsulated into the process we are building. Having to rewrite this code every single time an object needs to be checked for is cumbersome, and someone will eventually make a mistake.
To get us started, two new parameters will be declared:
DECLARE @SchemaMustContainThisObject VARCHAR(100); DECLARE @SchemaCannotContainThisObject VARCHAR(100);
When @SchemaMustContainThisObject contains a value, then its presence will be validated and only databases that contain it will have the query executed against them. When @SchemaCannotContainThisObject contains a value, then databases that contain that object will be excluded.
The following is a simple implementation of this logic, looking for the number of schemas that have a Customers table in the WideWorldImporters database:
DECLARE @SchemaMustContainThisObject VARCHAR(100) = 'Customers';
DECLARE @SchemaCannotContainThisObject VARCHAR(100);
DECLARE @DatabaseName sysname = 'WideWorldImporters'
DECLARE @SQL NVARCHAR(MAX);
DECLARE @ObjectValidationCount INT;
DECLARE @ObjectExceptionCount INT;
DECLARE @ParameterList NVARCHAR(MAX);
IF @SchemaMustContainThisObject IS NOT NULL
BEGIN
SELECT @SQL = 'SELECT @ObjectValidationCount = COUNT(*) FROM ' +
QUOTENAME(@DatabaseName) + --in case database name has
--spaces/special characters
'.sys.objects WHERE objects.name = ''' +
@SchemaMustContainThisObject + ''';';
SELECT @ParameterList = '@ObjectValidationCount INT OUTPUT';
EXEC sp_executesql @SQL,
@ParameterList,
@ObjectValidationCount OUTPUT;
END;
IF @SchemaCannotContainThisObject IS NOT NULL
BEGIN
SELECT @SQL = 'SELECT @ObjectExceptionCount = COUNT(*) FROM ' +
QUOTENAME(@DatabaseName) +
'.sys.objects WHERE objects.name = ''' +
@SchemaCannotContainThisObject + ''';';
SELECT @ParameterList = '@ObjectExceptionCount INT OUTPUT';
EXEC sp_executesql @SQL,
@ParameterList,
@ObjectExceptionCount OUTPUT;
END;
SELECT @ObjectValidationCount AS FoundObjectCount,
@ObjectExceptionCount AS NotFoundObjectCount;
Executing this code, you will see that there are two schemas in the WideWorldImporters have a Customers object (the one we have been working with, and another a view object in the Website schema).
Additional variables are declared to support parameterized dynamic SQL, as well as to store the output of the test queries. The counts can then be checked later to validate if an object exists or not. Note that sys.objects is used here for convenience without any added object type checks. If additional criteria or object types need to be checked, adding checks on the type_desc column in sys.objects can be used to further filter object details and return exactly what you are looking for. If only tables are checked, then sys.tables could be used instead. Similarly, if there is a need to check multiple types at once, additional variables/parameters could be declared for different object types.
Providing an Explicit Database List
A simple, but common implementation of this is to have an added parameter that provides an explicit database list to run a query against. If it is known exactly which databases need to be executed against and the list will not change without this code being altered, then it is possible to pass in a detailed list. This can be accomplished with a string or table-valued parameter, depending on your preference. Since the number of databases (and the length of this list) is bound by how many databases you have in a single place, it’s not likely that the length of this list would become prohibitively long for either solution. Therefore, the database list may be stored as a comma-separated-values string, like this:
DECLARE @DatabaseList VARCHAR(MAX);
SELECT @DatabaseList =
'AdventureWorks2017, BaseballStats, WideWorldImporters';
It may also be stored using a table-valued parameter:
CREATE TYPE dbo.DatabaseListType AS TABLE
(DatabaseName SYSNAME);
GO
DECLARE @DatabaseList dbo.DatabaseListType;
Similarly, the table variable may be memory-optimized, if your SQL Server version supports it and you are so inclined:
CREATE TYPE dbo.DatabaseListType AS TABLE
(DatabaseName SYSNAME PRIMARY KEY NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON);
GO
DECLARE @DatabaseList dbo.DatabaseListType;
If you choose that option, it is also worth considering using natively compiled stored procedures for consuming memory-optimized table variable. This is not an article about memory-optimized-awesomeness, and therefore a discussion of that will be skipped here. In either case, database names can be inserted into the user-defined table type like this:
INSERT INTO @DatabaseList
(DatabaseName)
VALUES
('AdventureWorks2017'),
('BaseballStats'),
('WideWorldImporters');
The final step is to prepare the T-SQL to execute and run it against the selected database list. A loop will be used to iterate through each database to run against. Assuming the query to execute is stored in the variable/parameter @SQLCommand, and the name of the current database to execute against is stored in @DatabaseName, then the resulting execution code would look like this:
CREATE TABLE #DatabaseList
(DatabaseName SYSNAME,
IsProcessed BIT);
INSERT INTO #DatabaseList
(DatabaseName, IsProcessed)
--<<<[Database List Determined Above and 0 for IsProcessed]>>>
DECLARE @CurrentDatabaseName SYSNAME,
@SQLCommand nvarchar(max);
WHILE EXISTS (SELECT * FROM #DatabaseList WHERE IsProcessed = 0)
BEGIN
SELECT TOP 1
@CurrentDatabaseName = DatabaseName
FROM #DatabaseList
WHERE IsProcessed = 0;
-- Replace "?" with the database name
SELECT @SQLCommand = REPLACE(@SQLCommand,
'?', @CurrentDatabaseName);
EXEC sp_executesql @SQLCommand;
UPDATE #DatabaseList
SET IsProcessed = 1
WHERE DatabaseName = @CurrentDatabaseName;
END;
SELECT *
FROM #DatabaseList;
Executing this code using the table variable created earlier in the section, you will see that the databases you passed in will be processed (in this snippet of code, it will actually work whether the database exists or not)
There are many ways to write this code, so if your own implementation varies from this and works, then roll with it 😊 The only added feature in there is to replace question marks with the database name. Note that if your query naturally contains question marks, then this may be problematic. This was added to mimic the behavior of sp_msforeachdb and make it easy to insert/use the local database name for each database that is executed against in the loop. If your environment makes common use of question marks in code, then feel free to adjust it to a character or string that is more obscure/deliberate.
Conclusion
Building reusable tools is fun and can provide a great deal of utility in the future if more needs arise that require code like this. A script containing all elements in this article is attached. Feel free to use it, customize it, and provide feedback if you think of new or interesting ways to tweak it.
There is value in avoiding use of undocumented SQL Server features in production environments. Fortunately for this tool, replacing it is not very complicated, and the new version can be given significantly more utility!
The post Running Queries Across Many SQL Server Databases appeared first on Simple Talk.
from Simple Talk https://ift.tt/JMPCYqi
via