When you’re learning SQL DML, the most complicated clause is typically the GROUP BY. It’s a fairly simple grouping based on values from the FROM clause in a SELECT statement. It’s what a mathematician would call an equivalence relation. This means that each grouping, or equivalence class, has the same value for a given characteristic function and the rows are all partitioned into disjoint subsets (groups) that had the same value under that function. The results table can also have columns that give group characteristics; I will get into those in a minute.
In the case of the usual GROUP BY, the function is equality. (More or less. I’ll get to that in a bit, too, but if you know anything about relational programming you might suspect NULL to be involved). Another possible function is modulus arithmetic. Taking MOD (<integer expression>, 2) splits the results into odd and even groups, for example.
Because SQL is an orthogonal language, we can actually do some fancy tricks with the GROUP BY clause. The term orthogonality refers to the property of a computer language which allows you to use any expression that returns a validate result anywhere in the language. Today, you take this property for granted in modern programming languages, but this was not always the case. The original FORTRAN allowed only certain expressions to be used as array indexes (it has been too many decades, but some of the ones allowed were <integer constant>, <integer variable>, and <integer constant>*<integer variable>) this was due to the operations allowed by the hardware registers of the early IBM machines upon which FORTRAN was implemented.
NULL Values and Grouping
NULL values have always been problematic. One of the basic rules in SQL is that a NULL value does not equal anything including another NULL. This implies each row should either be excluded or form its own singleton group when you use equality as your characteristic function.
We discussed this problem in the original ANSI X3H2 Database Standards Committee. There was one member’s company SQL which grouped using strict equality. They ran into a problem with a customer’s database involving traffic tickets. If an automobile did not have a tag, then obviously the correct data model would have been to use a NULL value. Unfortunately, in the real world, this meant every missing tag became its own group. This is not too workable in the state of California. A simple weekly report quickly became insanely long and actually hid information.
When an automobile was missing a tag, the convention had been put in something a human being could read and they picked “none” as the dummy value. Then along came somebody who got a prestige tag that read “NONE” to be cute. The system cheerfully dumped thousands of traffic tickets on to him as soon as his new tag got into the system. Other members had similar stories.
This led us to the equivalence relationship which I will call grouping. It acts just like equality for non-NULL values, but it treats NULL values as if they are all equal (the IS [NOT] IS DISTINCT infixed comparison operator did not exist at the time).
GROUP BY Basics
The skeleton syntax of a simple SELECT statement with a GROUP BY clause is
SELECT <group column expression list> FROM <table expression> [WHERE <row search condition>]0 GROUP BY <column expression list> [HAVING <group search condition>];
Here are the basic characteristics of this construct:
- You get one row returned for each group. Each row has only group characteristics; that means aggregate functions of some kind and columns that were used in the characteristic function.
- The
GROUP BYclause can only be used with a SQLSELECTstatement. - The
GROUP BYclause must be after theWHEREclause. (if the query has one. If theWHEREclause is absent, then the whole table is treated as if it’s one group). - The
GROUP BYclause must be before theORDER BYclause. (if the query has one). - To filter the
GROUP BYresults, you must use theHAVINGclause after theGROUP BY. - The
GROUP BYclause is often used in conjunction with aggregate functions. - All column names listed in the
SELECTclause should also appear in theGROUP BYclause, whether you have an aggregate function or not.
Note that using a GROUP BY clause Is meaningless if there are no duplicates in the columns you are grouping by.
Simple Statistics
The original GROUP BY clause came with a set of simple descriptive statistics; the COUNT, AVG, MIN, MAX, and SUM functions. Technically, they all have the option of a DISTINCT or ALL parameter qualifier. One of the weirdness of SQL is that various constructs can have parentheses for parameters or lists, and these lists can have SQL keywords inside of the parameters. Let’s look at these basic functions one at a time.
COUNT([ALL | DISTINCT | *] <expression>)
Returns an integer between zero whatever the count of the rows in this group is. If the expression returns NULL, it is Ignored in the count. The ALL option is redundant, and I’ve never seen anybody use this in the real world. The DISTINCT option removes redundant duplicates before applying the function. The * (asterisk) as the parameter applies only to the COUNT() function for obvious reasons. It is sort of a wildcard that stands for “generic row”, without regard to the columns that make up that row.
SUM ([ALL | DISTINCT | <expression>)
This is a summation of a numeric value after the NULL values have been removed from the set. Obviously, this applies only to numeric data. If you look at SQL, you’ve probably knows it has a lot of different kinds of numeric data. I strongly suggest taking a little time to see how your particular SQL product returns the result. The scale and precision may vary from product to product.
AVG()
This function is a version of the simple arithmetic mean. Obviously, this function would only apply to columns with numeric values. It sums all the non-NULL values in a set, then divides that number by the number of non-NULL values in that set to return the average value. It’s also wise to be careful about NULL values; consider a situation where you have a table that models employee compensation. This compensation includes a base salary and bonuses. But only certain employees are eligible for bonuses. Unqualified employees have rows that show the bonus_amt column value as NULL. This lets us maintain the difference between an employee who is not qualified and somebody who just didn’t get any bonus ($0.00) in this paycheck. The query should look like this skeleton:
SELECT emp_id, SUM(salary_amount + COALESCE (bonus_amount, 0.00)) AS total_compensation_amount FROM Paychecks GROUP BY emp_id;
MIN() and MAX()
These functions are called extrema functions in mathematics. Since numeric, string and temporal functions have ordering to them, they can be used by these two functions. Technically, you can put in the ALL and DISTINCT in the parameter list; which is somewhat absurd.
The reason for picking the small set of descriptive statistics was the ease of implementation. They are still quite powerful and there’s a lot of cute tricks you can try with them. For example, if (MAX(x) = MIN(x)) then we know the (x) column has one and only one value in it. Likewise, (COUNT(*) = COUNT(x)) tells us that column x does not have any NULL vales. But another reason for this selection of aggregate functions is that some of these things are already being collected by cost-based optimizers. We essentially got them for free.
More Descriptive Stats
The SQL:2006 Standard added some more descriptive aggregate functions to the language. I’ve actually never seen anybody use them, but they’re officially there. Various SQL products have ended other functions in top of these, but let’s go ahead and make a short list of some of what’s officially there.
VAR_POP
This is also written as simply VAR() or VARP(). It’s a statistic called the variance, which is defined as the sum of squares of the difference of <value expression> and the <independent variable expression>, divided by the number of rows.
It is a statistical measurement of the spread between numbers in a data set. More specifically, variance measures how far each number in the set is from the mean, and thus from every other number in the set. We write it as σ2, , in mathematics. Variance tells you the degree of spread in your data set. The more spread the data, the larger the variance is in relation to the mean. You can see why this might be useful for an optimizer. We also added VAR_SAMP() To compute the sample variance.
STDEV_POP
This is the population standard deviation. The standard deviation (or σ) is a measure of how dispersed the data is in relation to the mean. You can think of it as another way of getting the same information as the variance, but it can go negative.
A standard deviation close to zero indicates that data points are close to the mean, whereas a high or low standard deviation indicates data points are respectively above or below the mean.
We also have another function defined for a sample population, STDEV_SAMP. There are no surprises here so you can see the “_SAMP” postfix is consistent.
There are other functions that were added standard deal with regression, and correlation. They are even more obscure and are never actually in the real world.
Interestingly enough, standards did not build in the mode (most frequently occurring value in a set), and the median (middle value of a set). The mode has a problem. There can be several of them. If population has an equal number of several different values, you get a multi-modal distribution; SQL functions do not like to return non-scalar values. The median has a similar sort of problem. If the set of values has an odd number of elements in it, then the median is pretty well defined as the value which sits dead center when you order the values. However, if you have an even number of values, then it gets a little harder. You have to take the average of values in the middle of the ordering. Let’s say you have a column with values {1, 2, 2, 3, 3, 3}. The values in the middle of this list are {2, 3} which averages out to 2.5. But if I use an average computed with duplicate values, I get 13/5 = 2.6 instead. This second weighted average is actually more accurate because it shows the slight skew toward 3.
OLAP Extensions ROLLUP, CUBE and GROUPING SETS
OLAP, or “Online Analytical Processing”, became a fad in the mid-2010’s. Several products devoted to this sort of statistical works hit the market and SQL decided to add extensions that would allow it to be used in place of a dedicated package. This added more descriptive statistics to SQL.
Note: I would be very careful about using SQL as a statistical reporting language. We never intended it for this purpose, so it’s hard to guarantee if the corrections for floating-point rounding errors and other things that need to go into a good statistical package are going to be found in your SQL product.
GROUPING SETS
The grouping sets construct Is the basis for CUBE and ROLLUP. You can think of it as shorthand for a series of UNION queries that are common in reports. But since a SELECT statement must return a table, we have to do some padding with generated NULL values to keep the same number of columns in each row. For example:
SELECT dept_name, job_title, COUNT(*) FROM Personnel GROUP BY GROUPING SET (dept_name, job_title);
This will give us a count for departments as a whole and for the job titles within the departments. You can think of it as a shorthand for
BEGIN SELECT dept_name, CAST(job_title AS NULL), COUNT(*) FROM Personnel GROUP BY dept_name UNION ALL SELECT CAST(dept_name AS NULL), job_title, COUNT(*) FROM Personnel GROUP BY job_title; END;
If you think about it for a minute, you’ll see there’s a little problem here. I don’t know if the NULL values that I’ve created with my CAST () Function calls were in the original data or not. That’s why we have a GROUPING (<grouping column name>) Function to test for it. It returns zero if the NULL was in the original data and one If it was generated, and therefore belongs to a sub group.
For example,
SELECT
GROUPING
CASE (dept_name)
WHEN 1 THEN ‘Department Total’.
ELSE dept_name END AS dept_name,
GROUPING
CASE (job title)
WHEN 1 THEN ‘Job Total’
.ELSE job_title END AS job_title
FROM Personnel
GROUP BY GROUPING SET (dept_name, job_title);
I’m a little ashamed of this example because it shows me using SQL display formatting on a result. This violates the principle of a tiered architecture.
ROLLUP
The ROLLUP subclause can be defined with the GROUPING SET construct, which is why I introduced GROUPING SET first. In reality, the ROLLUP is our good old hierarchical report in a new suit. We used to call these breakpoint, or control and break reports in the old days of sequential file processing. The report program set up a bunch of registers to keep running aggregates (usually totals). Every time you pass a control point in the input sequence of records, you dump the registers, reset them with their calculations and begin again. Because of sequential processing, lowest level in his hierarchy would print out first and then the next level of aggregation would appear and so on until you got the grand totals.
Consider GROUP BY ROLLUP (state_code, county_name, emp_id) as shorthand for
GROUP BY GROUPING SETS (state_code, county_name, emp_id), (state_code, county_name), (state_code), () -- Entire table
Please notice that the order of those columns in the ROLLUP clause is important. This will give you an aggregate for every employee within each county of each state, an aggregate for every county within each state, that same aggregate for each state and finally a grand aggregate for the entire data set (that is what the empty parentheses mean).
CUBE
The cube supergroup is another SQL 99 extension which is really an old friend with a new name. We used to call it “cross tabs” which is short for cross tabulation. In short, it creates unique groups for all possible combinations of the columns you specify. For example, if you use GROUP BY CUBE on (column1, column2) of your table, SQL returns groups for all unique values (column1, column2), (NULL, column2), (column1, NULL) and (NULL, NULL).
Conclusion
This is just a skim over the options available in the GROUP BY clause. Anytime you have a query that works on the data with an equivalence relation, is a pretty good chance you will be able to do it using a GROUP BY.
As a quick programming exercise, I recently saw a post on one of the SQL forums by a less-experienced programmer. He wanted to UPDATE a flag column (Yes, flags are a bad idea in SQL) from 0 to 1, if any row in the group had a one. The code got fairly elaborate because he had to destroy data as he overwrote existing rows.
Can you write a simple piece of SQL that will give us this information, using a GROUP BY? It definitely is possible.
The GROUP BY Clause
When you’re learning SQL DML, the most complicated clause is typically the GROUP BY. It’s a fairly simple grouping based on values from the FROM clause in a SELECT statement. It’s what a mathematician would call an equivalence relation. This means that each grouping, or equivalence class, has the same value for a given characteristic function and the rows are all partitioned into disjoint subsets (groups) that had the same value under that function. The results table can also have columns that give group characteristics; I will get into those in a minute.
In the case of the usual GROUP BY, the function is equality. (More or less. I’ll get to that in a bit, too). Another possible function is modulus arithmetic. Taking MOD (<integer expression>, 2) splits the results into odd and even groups, for example.
Because SQL is an orthogonal language, we can actually do some fancy tricks with the GROUP BY clause. The term orthogonality refers to the property of a computer language which allows you to use any expression that returns a validate result anywhere in the language. Today, you take this property for granted in modern programming languages, but this was not always the case. The original FORTRAN allowed only certain expressions to be used as array indexes (it has been too many decades, but some of the ones allowed were <integer constant>, <integer variable>, and <integer constant>*<integer variable>) this was due to the operations allowed by the hardware registers of the early IBM machines upon which FORTRAN was implemented.
NULL Values and Grouping
NULL values have always been problematic. One of the basic rules in SQL is that a NULL value does not equal anything including another NULL. This implies each row should either be excluded or form its own singleton group when you use equality as your characteristic function.
We discussed this problem in the original ANSI X3H2 Database Standards Committee. There was one member’s company SQL which grouped using strict equality. They ran into a problem with a customer’s database involving traffic tickets. If an automobile did not have a tag, then obviously the correct data model would have been to use a NULL value. Unfortunately, in the real world, this meant every missing tag became its own group. This is not too workable in the state of California. A simple weekly report quickly became insanely long and actually hid information.
When an automobile was missing a tag, the convention had been put in something a human being could read and they picked “none” as the dummy value. Then along came somebody who got a prestige tag that read “NONE” to be cute. The system cheerfully dumped thousands of traffic tickets on to him as soon as his new tag got into the system. Other members had similar stories.
This led us to the equivalence relationship which I will call grouping. It acts just like equality for non-NULL values, but it treats NULL values as if they are all equal (the IS [NOT] IS DISTINCT infixed comparison operator did not exist at the time).
GROUP BY Basics
The skeleton syntax of a simple SELECT statement with a GROUP BY clause is
SELECT <group column expression list> FROM <table expression> [WHERE <row search condition>]0 GROUP BY <column expression list> [HAVING <group search condition>];
Here are the basic characteristics of this construct:
- You get one row returned for each group. Each row has only group characteristics; that means aggregate functions of some kind and columns that were used in the characteristic function.
- The
GROUP BYclause can only be used with a SQLSELECTstatement. - The
GROUP BYclause must be after theWHEREclause. (if the query has one. If theWHEREclause is absent, then the whole table is treated as if it’s one group). - The
GROUP BYclause must be before theORDER BYclause. (if the query has one). - To filter the
GROUP BYresults, you must use theHAVINGclause after theGROUP BY. - The
GROUP BYclause is often used in conjunction with aggregate functions. - All column names listed in the
SELECTclause should also appear in theGROUP BYclause, whether you have an aggregate function or not.
Note that using a GROUP BY clause Is meaningless if there are no duplicates in the columns you are grouping by.
Simple Statistics
The original GROUP BY clause came with a set of simple descriptive statistics; the COUNT, AVG, MIN, MAX, and SUM functions. Technically, they all have the option of a DISTINCT or ALL parameter qualifier. One of the weirdness of SQL is that various constructs can have parentheses for parameters or lists, and these lists can have SQL keywords inside of the parameters. Let’s look at these basic functions one at a time.
COUNT([ALL | DISTINCT | *] <expression>)
Returns an integer between zero whatever the count of the rows in this group is. If the expression returns NULL, it is Ignored in the count. The ALL option is redundant, and I’ve never seen anybody use this in the real world. The DISTINCT option removes redundant duplicates before applying the function. The * (asterisk) as the parameter applies only to the COUNT() function for obvious reasons. It is sort of a wildcard that stands for “generic row”, without regard to the columns that make up that row.
SUM ([ALL | DISTINCT | <expression>)
This is a summation of a numeric value after the NULL values have been removed from the set. Obviously, this applies only to numeric data. If you look at SQL, you’ve probably knows it has a lot of different kinds of numeric data. I strongly suggest taking a little time to see how your particular SQL product returns the result. The scale and precision may vary from product to product.
AVG()
This function is a version of the simple arithmetic mean. Obviously, this function would only apply to columns with numeric values. It sums all the non-NULL values in a set, then divides that number by the number of non-NULL values in that set to return the average value. It’s also wise to be careful about NULL values; consider a situation where you have a table that models employee compensation. This compensation includes a base salary and bonuses. But only certain employees are eligible for bonuses. Unqualified employees have rows that show the bonus_amt column value as NULL. This lets us maintain the difference between an employee who is not qualified and somebody who just didn’t get any bonus ($0.00) in this paycheck. The query should look like this skeleton:
SELECT emp_id, SUM(salary_amount + COALESCE (bonus_amount, 0.00)) AS total_compensation_amount FROM Paychecks GROUP BY emp_id;
MIN() and MAX()
These functions are called extrema functions in mathematics. Since numeric, string and temporal functions have ordering to them, they can be used by these two functions. Technically, you can put in the ALL and DISTINCT in the parameter list; which is somewhat absurd.
The reason for picking the small set of descriptive statistics was the ease of implementation. They are still quite powerful and there’s a lot of cute tricks you can try with them. For example, if (MAX(x) = MIN(x)) then we know the (x) column has one and only one value in it. Likewise, (COUNT(*) = COUNT(x)) tells us that column x does not have any NULL vales. But another reason for this selection of aggregate functions is that some of these things are already being collected by cost-based optimizers. We essentially got them for free.
More Descriptive Stats
The SQL:2006 Standard added some more descriptive aggregate functions to the language. I’ve actually never seen anybody use them, but they’re officially there. Various SQL products have ended other functions in top of these, but let’s go ahead and make a short list of some of what’s officially there.
VAR_POP
This is also written as simply VAR() or VARP(). It’s a statistic called the variance, which is defined as the sum of squares of the difference of <value expression> and the <independent variable expression>, divided by the number of rows.
It is a statistical measurement of the spread between numbers in a data set. More specifically, variance measures how far each number in the set is from the mean, and thus from every other number in the set. We write it as 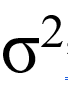 σ2, , in mathematics. Variance tells you the degree of spread in your data set. The more spread the data, the larger the variance is in relation to the mean. You can see why this might be useful for an optimizer. We also added
σ2, , in mathematics. Variance tells you the degree of spread in your data set. The more spread the data, the larger the variance is in relation to the mean. You can see why this might be useful for an optimizer. We also added VAR_SAMP() To compute the sample variance.
STDEV_POP
This is the population standard deviation. The standard deviation (or ![]() σ) is a measure of how dispersed the data is in relation to the mean. You can think of it as another way of getting the same information as the variance, but it can go negative.
σ) is a measure of how dispersed the data is in relation to the mean. You can think of it as another way of getting the same information as the variance, but it can go negative.
A standard deviation close to zero indicates that data points are close to the mean, whereas a high or low standard deviation indicates data points are respectively above or below the mean.
We also have another function defined for a sample population, STDEV_SAMP. There are no surprises here so you can see the “_SAMP” postfix is consistent.
There are other functions that were added standard deal with regression, and correlation. They are even more obscure and are never actually in the real world.
Interestingly enough, standards did not build in the mode (most frequently occurring value in a set), and the median (middle value of a set). The mode has a problem. There can be several of them. If population has an equal number of several different values, you get a multi-modal distribution; SQL functions do not like to return non-scalar values. The median has a similar sort of problem. If the set of values has an odd number of elements in it, then the median is pretty well defined as the value which sits dead center when you order the values. However, if you have an even number of values, then it gets a little harder. You have to take the average of values in the middle of the ordering. Let’s say you have a column with values {1, 2, 2, 3, 3, 3}. The values in the middle of this list are {2, 3} which averages out to 2.5. But if I use an average computed with duplicate values, I get 13/5 = 2.6 instead. This second weighted average is actually more accurate because it shows the slight skew toward 3.
OLAP Extensions ROLLUP, CUBE and GROUPING SETS
OLAP, or “Online Analytical Processing”, became a fad in the mid-2010’s. Several products devoted to this sort of statistical works hit the market and SQL decided to add extensions that would allow it to be used in place of a dedicated package. This added more descriptive statistics to SQL.
Note: I would be very careful about using SQL as a statistical reporting language. We never intended it for this purpose, so it’s hard to guarantee if the corrections for floating-point rounding errors and other things that need to go into a good statistical package are going to be found in your SQL product.
GROUPING SETS
The grouping sets construct Is the basis for CUBE and ROLLUP. You can think of it as shorthand for a series of UNION queries that are common in reports. But since a SELECT statement must return a table, we have to do some padding with generated NULL values to keep the same number of columns in each row. For example:
SELECT dept_name, job_title, COUNT(*) FROM Personnel GROUP BY GROUPING SET (dept_name, job_title);
This will give us a count for departments as a whole and for the job titles within the departments. You can think of it as a shorthand for
BEGIN SELECT dept_name, CAST(job_title AS NULL), COUNT(*) FROM Personnel GROUP BY dept_name UNION ALL SELECT CAST(dept_name AS NULL), job_title, COUNT(*) FROM Personnel GROUP BY job_title; END;
If you think about it for a minute, you’ll see there’s a little problem here. I don’t know if the NULL values that I’ve created with my CAST () Function calls were in the original data or not. That’s why we have a GROUPING (<grouping column name>) Function to test for it. It returns zero if the NULL was in the original data and one If it was generated, and therefore belongs to a sub group.
For example,
SELECT
GROUPING
CASE (dept_name)
WHEN 1 THEN ‘Department Total’.
ELSE dept_name END AS dept_name,
GROUPING
CASE (job title)
WHEN 1 THEN ‘Job Total’
.ELSE job_title END AS job_title
FROM Personnel
GROUP BY GROUPING SET (dept_name, job_title);
I’m a little ashamed of this example because it shows me using SQL display formatting on a result. This violates the principle of a tiered architecture.
ROLLUP
The ROLLUP subclause can be defined with the GROUPING SET construct, which is why I introduced GROUPING SET first. In reality, the ROLLUP is our good old hierarchical report in a new suit. We used to call these breakpoint, or control and break reports in the old days of sequential file processing. The report program set up a bunch of registers to keep running aggregates (usually totals). Every time you pass a control point in the input sequence of records, you dump the registers, reset them with their calculations and begin again. Because of sequential processing, lowest level in his hierarchy would print out first and then the next level of aggregation would appear and so on until you got the grand totals.
Consider GROUP BY ROLLUP (state_code, county_name, emp_id) as shorthand for
GROUP BY GROUPING SETS (state_code, county_name, emp_id), (state_code, county_name), (state_code), () -- Entire table
Please notice that the order of those columns in the ROLLUP clause is important. This will give you an aggregate for every employee within each county of each state, an aggregate for every county within each state, that same aggregate for each state and finally a grand aggregate for the entire data set (that is what the empty parentheses mean).
CUBE
The cube supergroup is another SQL 99 extension which is really an old friend with a new name. We used to call it “cross tabs” which is short for cross tabulation. In short, it creates unique groups for all possible combinations of the columns you specify. For example, if you use GROUP BY CUBE on (column1, column2) of your table, SQL returns groups for all unique values (column1, column2), (NULL, column2), (column1, NULL) and (NULL, NULL).
Conclusion
This is just a skim over the options available in the GROUP BY clause. Anytime you have a query that works on the data with an equivalence relation, is a pretty good chance you will be able to do it using a GROUP BY.
As a quick programming exercise, I recently saw a post on one of the SQL forums by a less-experienced programmer. He wanted to UPDATE a flag column (Yes, flags are a bad idea in SQL) from 0 to 1, if any row in the group had a one. The code got fairly elaborate because he had to destroy data as he overwrote existing rows.
Can you write a simple piece of SQL that will give us this information, using a GROUP BY? It definitely is possible.
The post The GROUP BY Clause appeared first on Simple Talk.
from Simple Talk https://ift.tt/lVceunX
via
No comments:
Post a Comment