This article is part of Aisha Bukar's 6 part series on MySQL Replication. The entries include:
- Part 1: Introduction to MySQL Replication
- Part 2: Configuring Source and Replicas
- Part 3: Multi-Source Replication
- Part 4: Using GTID Based Replication
This technology is built on top of the MySQL InnoDB storage engine and employs a multi-source replication approach which we discussed in part 3 of the replication series. In this article, we’d be looking at an overview of the group replication technique, configuring and managing group replication, and also best practices for group replication. So, let’s get started!
Overview of group replication
MySQL’s group replication was designed to give a high availability, fault tolerant database cluster. It operates using a multi-master replication approach, allowing multiple MySQL server instances to collaborate as a group, ensuring data consistency and availability. This feature ensures high availability by allowing multiple servers to work together, and if one server fails, another server in the group takes over, minimizing downtime and ensuring continuous access to the data.
Group replication can operate in single-primary mode (default), where only one server (which is the primary server) can accept write operations at a time, or multi-primary mode, where multiple servers can accept write operations simultaneously.
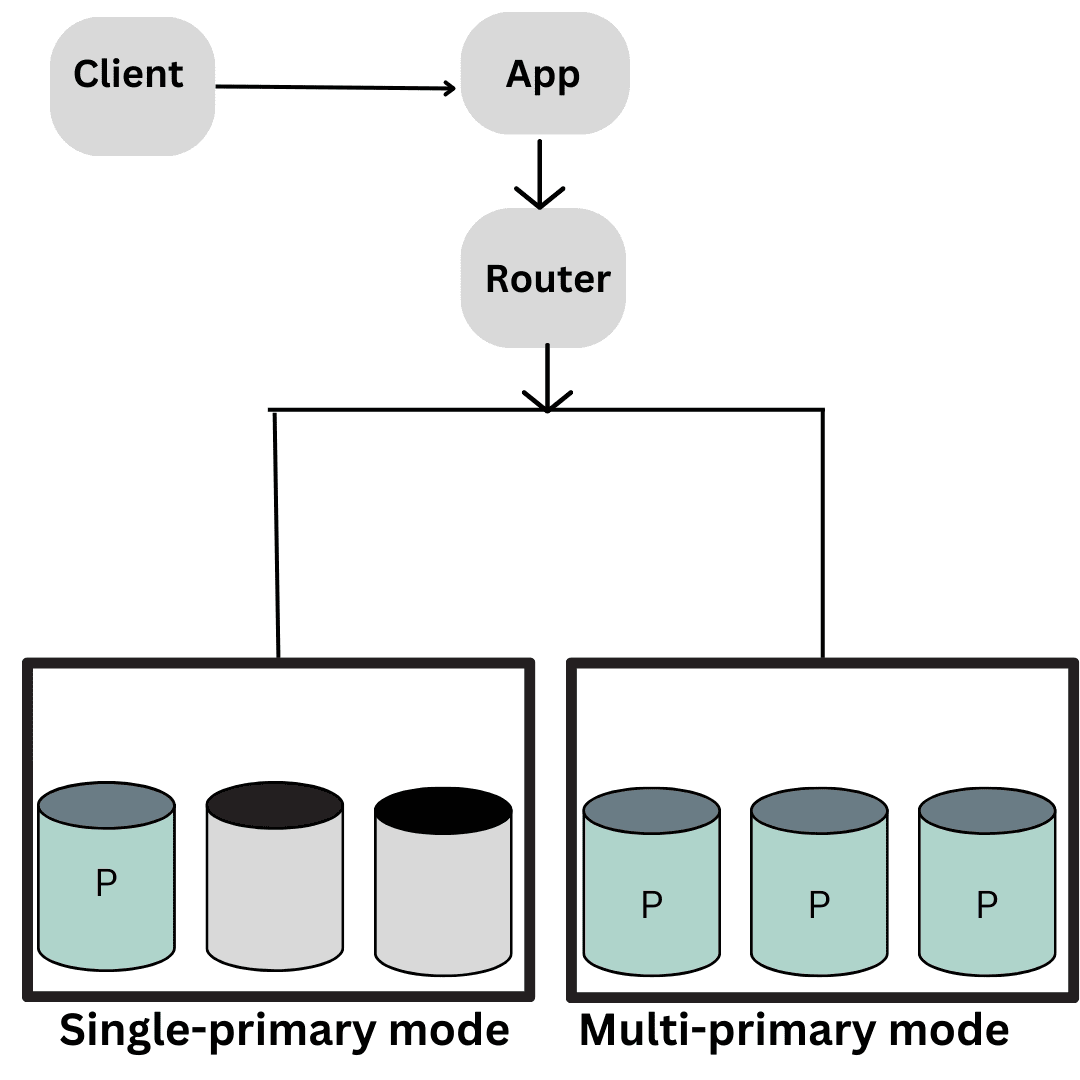
Group replication uses a certification-based replication protocol to ensure that data remains consistent across all servers in the group. In the event of a primary server failure, group replication automatically elects a new primary server to handle write operations, ensuring uninterrupted service by employing middleware devices such as network load balancers or routers. Additionally, it supports both synchronous and asynchronous replication modes, providing flexibility based on your application’s requirements.
Configuring group replication
In order to use MySQL Group Replication, you need to install and configure the plugin on each server in the group. This plugin is designed specifically for the MySQL server and enables you to replicate data across multiple servers, ensuring that your data is always secure and consistent.
By following the installation and configuration instructions carefully, you can ensure that your MySQL group replication setup is both efficient and effective. Here’s a step by step guide to help you demonstrate the process of configuring the group replication:
Ensure that the group replication plugin is installed and activated on each server instance
The MySQL Server 8.0 comes bundled with the Group Replication plugin, so there is no need for extra software. However, it is essential to install the plugin on the active MySQL server to enable its functionality. To install the Group Replication plugin on the active MySQL servers, follow these steps:
i. Check Plugin Availability: First, ensure that the group replication plugin is available in your MySQL installation. Starting from MySQL 8.0, the plugin is included by default, but it’s a good practice to verify its presence. You can do this using the following command:
SHOW PLUGINS;
ii. Connect to MySQL: Use the MySQL client or MySQL Shell to connect to the MySQL server where you want to install the plugin. You need appropriate administrative privileges (e.g., the root user) to perform the installation.
iii. Install the Plugin: Run the following SQL command to install the Group Replication plugin:
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
If you are using Windows, use ‘group_replication.dll’ instead of ‘group_replication.so’.
iv. Verify Installation: To confirm that the installation was successful, you can check the installed plugins by running:
SHOW PLUGINS;
Make sure that ‘group_replication’ appears in the list of installed plugins.
v. Repeat for Other Servers: Repeat the above steps for each of the active MySQL servers that you want to be part of the Group Replication cluster.
It’s important to note that when setting up a Group Replication cluster, all servers should have the same version of MySQL and identical configurations. Also, ensure that you have a backup of your data before making any significant changes to your MySQL installation.
Monitoring group replication
Monitoring group replication using the performance schema in MySQL involves utilizing a powerful feature that provides the metrics for analyzing the performance of various database activities, including replication. The performance schema allows you to gather detailed insights into how your group replication setup is performing, identify bottlenecks, and diagnose issues. Here’s how you can monitor group replication using the performance schema:
1.Enable Performance Schema: Ensure that the performance schema is enabled in your MySQL server. You can do this by editing the MySQL configuration file (my.cnf or my.ini) and setting the appropriate configuration option, usually “performance_schema=ON”.
2. Relevant Performance Schema Tables: The performance schema provides a range of tables that store information about different aspects of MySQL’s performance, including replication. The key tables related to group replication monitoring include:
i. replication_group_members: This table provides information about the members of your replication group, their status, roles, and more.
ii. replication_connection_status: This table offers details about the connection status between replication group members.
iii. replication_applier_status_by_worker: This table provides information about the status of applier workers on each member, including replication lag and progress.
iv. replication_group_member_stats: This table contains various statistics related to replication for each group member, including transaction counts and sizes.
Running Queries and Analyzing Data
You can run SQL queries against these performance schema tables to retrieve insights into your group replication setup. For example:
To monitor the overall health and state of the replication group, the following query is issued:
SELECT * FROM performance_schema.replication_group_members;
To monitor a group replication members performance, the following query is used:
SELECT * FROM performance_schema.replication_group_member_stats\G
You can also monitor group replication with GTIDs. This is a crucial task which helps to maintain the dependability and consistency of your database. GTIDs (Global Transaction Identifiers) are unique identifiers that are allocated to each transaction in a MySQL database. This makes it simpler to track changes across multiple servers. For more information on GTID, check out part 4 of this series.
To effectively monitor group replication with GTIDs, powerful tools such as MySQL Enterprise Monitor or Percona Monitoring and Management are utilized. These tools allow you to keep an eye on your replication group’s status, assess transaction performance and latency, and diagnose any issues that may arise. It is highly recommended to regularly monitor your replication group to guarantee that it is functioning correctly and to detect potential issues early on.
Best practices for group replication
To achieve a successful MySQL group replication, it’s crucial to ensure that:
1. All members in the group are using the same version of MySQL
2. All members have identical configuration settings
3. All members are connected through a reliable network
It’s also essential to monitor the group’s status regularly and perform backups to maintain data safety in case of failures. Limiting the number of members in the group can reduce the likelihood of conflicts and ensure efficient replication. Consistency and communication are the main factors in maintaining the group’s success.
Conclusion
MySQL group replication is an important topic in replication. It helps multiple server instances to collaborate as a group. This article is beginner friendly and only highlights the important aspects of using the group replication technique. For more in-depth information, please visit the official MySQL blog and documentation.
The post A Beginners Guide to MySQL Replication Part 5: Group Replication appeared first on Simple Talk.
from Simple Talk https://ift.tt/xOe8CDt
via