Concurrency control is an essential aspect of database systems that deals with multiple concurrent transactions. PostgreSQL employs various techniques to ensure concurrent access to the database while maintaining data consistency using atomicity and isolation of ACID (stands for Atomicity, Consistency, Isolation and Durability – https://en.wikipedia.org/wiki/ACID) properties.
Concurrency Techniques
Broadly there are three concurrency techniques available for any database management system, pessimistic, optimistic, and multi-valued concurrency control (MVCC). In this section, I will introduce the techniques.
Pessimistic Locking
This concurrency control technique is used in database systems to handle concurrent access to shared data. It takes a cautious approach by assuming that conflicts between transactions are likely to occur, and it prevents conflicts by acquiring locks on database objects (rows or tables). Pessimistic locking ensures exclusive access to data, but it can lead to increased blocking and reduced concurrency compared to optimistic locking approaches.
An example of pessimistic locking is Strict Two-Phase Locking (2PL) (https://en.wikipedia.org/wiki/Two-phase_locking) and it ensures that concurrent transactions acquire and release locks in a strict and consistent manner, preventing conflicts and maintaining the data integrity. Strict 2PL consists of two distinct phases: the lock growing phase and the lock shrinking phase. In the lock growing phase, a transaction acquires locks on database objects before accessing or modifying them. These locks can be either shared (read) locks or exclusive (write) locks based on the transaction type. In the lock release phase, a transaction releases the locks it holds on database objects. This typically happens at the end of the transaction (a commit or a rollback).
The pros of this technique are, simple to implement and guaranteed consistency and integrity of data. Whereas the cons are, high lock contention such as lock-waits, lock escalations leading to performance bottlenecks.
Optimistic Locking
This concurrency control technique takes an optimistic approach by assuming that conflicts between transactions are rare, and it allows transactions to proceed without acquiring locks on database objects during the execution of the entire transaction. Conflicts are validated, detected and resolved only at the time of committing the transaction.
The pros of this technique are, increased concurrency, reduced lock overhead leading to linear high scalability. Whereas the cons are, high abort rate due to detection of conflict at commit time, and data integrity challenges.
Multi Version Concurrency Control (MVCC)
This concurrency control technique is used in database systems to allow concurrent access to shared database objects while maintaining data consistency and isolation. MVCC provides each transaction with a consistent snapshot of the data as it existed at the start of the transaction, even when other transactions modify the data concurrently.
MVCC works very well within PostgreSQL for read operations. When it comes to updating the data, PostgreSQL would still acquire locks (which is pessimistic locking) at row level to ensure data consistency and prevent conflict between concurrent transactions. PostgreSQL provides various types of locks to manage concurrency and ensure data consistency in multi-user environments. These locks can be classified into several categories based on their scope and purpose. Below are the most common types of locks available (reference: https://ift.tt/voIa8Dx
- Row Level/Tuple Level Locks
- Page Level Locks
- Page Level Locks
- Advisory Locks
PostgreSQL engine handles lock management automatically in the background for most common operations such as update and delete. The database engine acquires and releases locks based on the SQL statements being executed, the transaction isolation level and the volume of data. We will be discussing these in detail in the next article – Deep dive into PostgreSQL locks and deadlocks.
Now that we know about the concurrency control aspects of databases. Let’s dive deep into the building blocks of MVCC specific to PostgreSQL.
Building Blocks of MVCC in PostgreSQL
There are 6 key building blocks of MVCC which are very important to understand how concurrency controls works within PostgreSQL:
- Transaction IDs
- Versioning of Tuple
- Visibility Check Rules
- Read Consistency
- Write Operations
- Garbage Collection
In this section I will introduce each of these topics to help make the basics clear.
Transaction IDs (XIDs):
Each transaction is assigned a unique transaction identifier (ID) called a Transaction ID (XID). It is a 32-bit (4 bytes) value that uniquely identifies a transaction within a PostgreSQL database cluster. It is automatically generated by the transaction manager when a transaction begins, and it remains associated with the transaction until it either commits or rollbacks the transaction.
With 2^ (32 -1), we can have up to 2,147,483,648 transaction IDs in the cluster. Upon reaching this limit, we will experience a wraparound and transaction IDs will be reused.
Note:
Transaction ID 0 (zero) is reserved, 1 is used as bootstrap transaction id during the cluster initialization phase and 2 is used as frozen transaction id.
The built-in function pg_current_xact_id() returns the current transaction ID (XID) of the calling session. This call by itself creates a new transaction when you call it for the first time within the unit of work. For example:

The PostgreSQL transaction manager allocates XID when pg_current_xact_id () is called or an UPDATE, DELETE, INSERT operation is executed. However, a BEGIN transaction or a SELECT operation will not allocate a transaction ID. The built-in function pg_current_xact_id_if_assigned () can be used to return the current transaction ID or NULL if XID is not assigned to the transaction.

A Word About 8-byte Transaction ID (xid8) Enhancement in PostgreSQL
There were enhancements made to the code since PostgreSQL 13 to have a 64-bit (8 bytes) transaction IDs leading up to 9,223,372,036,854,775,808 (9223372 billion transaction IDs compared to 2.2 billion transaction IDs) that does not wrap around during the life of an installation. The following data structures have been modified to make use of 8-byte transaction ID (xid8):
- PostgreSQL system catalog
- Functions and procedures
- Backend worker processes which deal with SQL queries
- PostgreSQL utilities
- Replication slots and
VACUUM
However, the challenge is to convert an existing XMIN and XMAX data structure from xid4 to xid8 on a running database makes it difficult to perform an in-place conversion. Please look out for more details about xid8 in the future article.
Versioning of Tuples
In PostgreSQL, each tuple (row) in a database table contains two transaction ID (XID) fields known as the xmin and xmax. These fields represent the minimum and maximum transaction IDs that are permitted to see or access a specific row. They play a crucial role in the Multi-Version Concurrency Control (MVCC) mechanism for maintaining data visibility and consistency.
Below are the characteristics of xmin and xmax fields:
xmin (Transaction ID of the creating transaction):
- The
xminfield stores the Transaction ID (XID) of the transaction that created the row version. - It indicates the minimum Transaction ID that is allowed to see the row version.
- Any transaction with a Transaction ID lower than
xmincan see and access the row version. xminis set when a new row version is inserted or created.
xmax (Transaction ID of the deleting transaction):
- The
xmaxfield stores the Transaction ID (XID) of the transaction that deleted or marked the row version as deleted. - It indicates the maximum Transaction ID that is allowed to see the row version.
- Only transactions with a Transaction ID lower than
xmaxcan see the row version. - If
xmaxis set to infinity (represented as 0), it means the row version is currently not deleted or marked as deleted by any transaction.
Let’s take an example and see how versioning is maintained in a table.

In this example, xmin for the first tuple is 609167. It is the XID of the transaction which inserted this tuple. The xmax column value is set to 0, which means the tuple is active (validity is set to infinity) and there was no update or delete performed on this tuple.
The column ctid is a system column that represents the physical location or address of a row within a table. It consists of two parts: block number and tuple index. The block number identifies the disk block where the row is stored, and tuple index identifies the position of the row within the block.
Figure 1 illustrates a PostgreSQL tuple versioning with a simple example. The session #1 read tuples from table account_info, where xmax was set to infinity (zero) – that means no modifications were made to tuples and were active versions. You will also notice, the ctid is set to (0,1) (0,2) that means both the tuples are stored sequentially in block 0 and this table has only 2 tuples. When session #2 updates the account_type for account=1 tuple, xmin is changed from txid 609167 to 609169 to reflect the transaction performing the update. You will also notice the change in ctid from (0,1) (0,2) to (0,2) (0,3) that means we have 3 tuples in the table stored in block 0. Why do we have 3 tuples in the table when we only see 2 tuples? That’s because PostgreSQL has retained the older version of the tuple for 2 reasons, (1) – there is an open transaction which reads the earlier version of the tuple which is valid between txid 609167 and 609169 and (2) – the recent change is not committed yet from session #2.
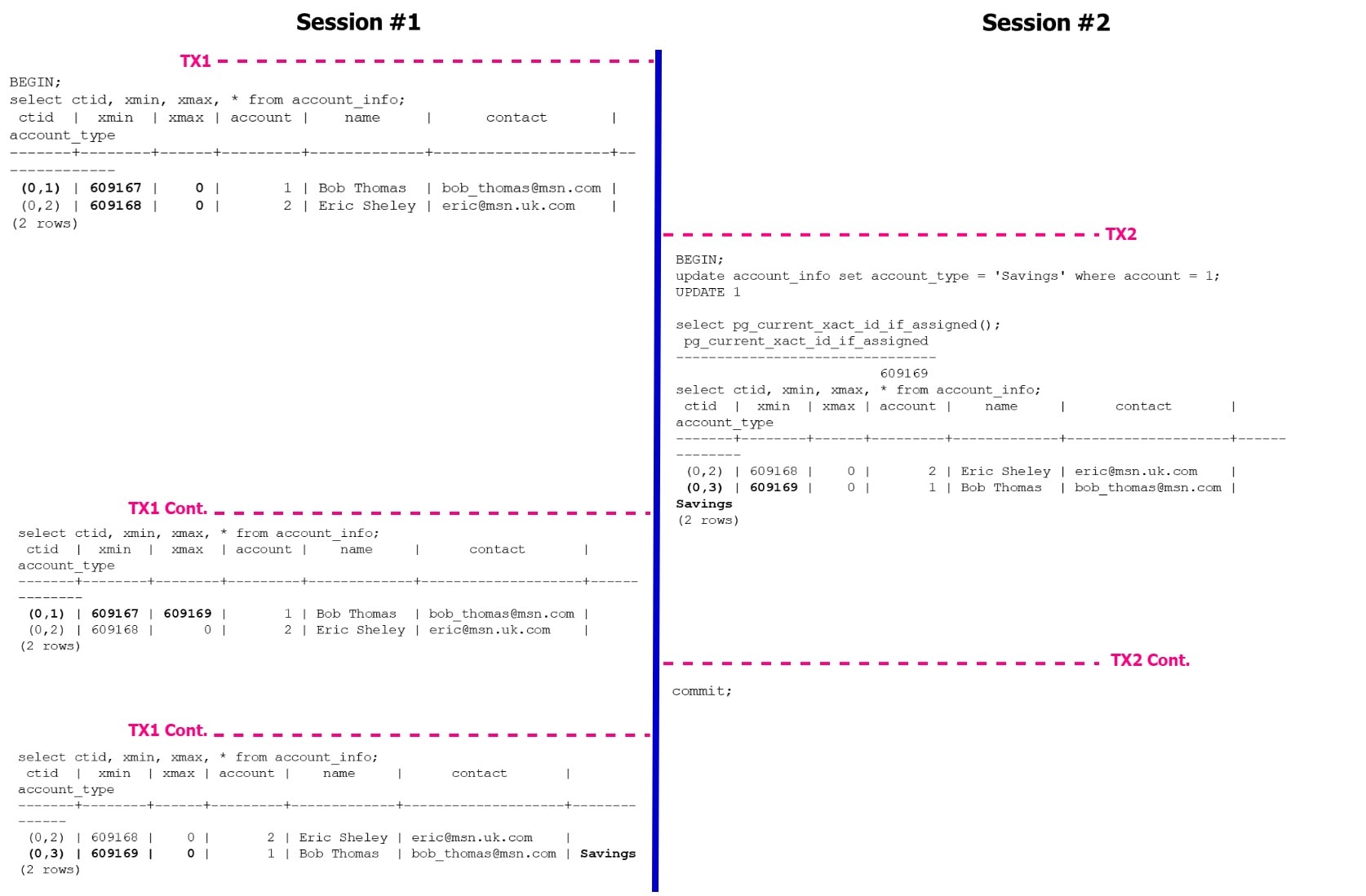
Figure 1: PostgreSQL Versioning Example
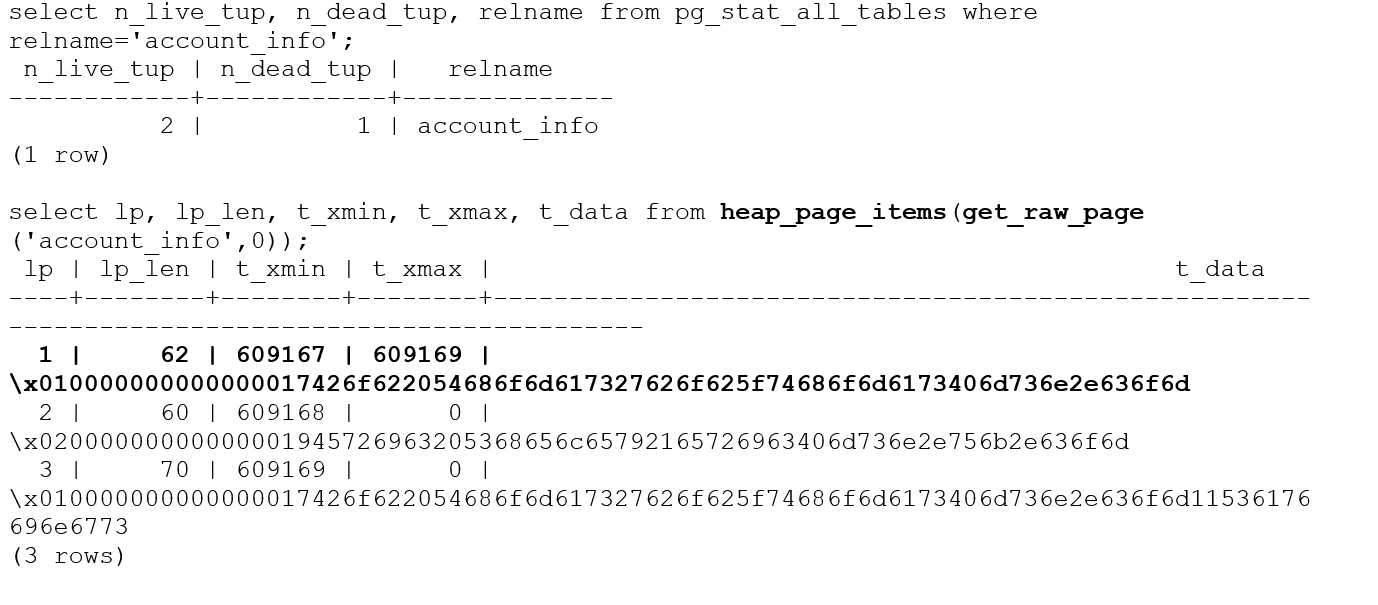
The pageinspect module in PostgreSQL provides a set of functions that allow you to inspect and analyze the contents of database pages at a low level. This module is particularly useful for debugging, troubleshooting, and understanding the internal structure of PostgreSQL database pages. For example, we can inspect the table account_info to extract all 3 tuples details (2 active tuples and 1 dead tuple).
Visibility Check Rules
In PostgreSQL’s Multi-Version Concurrency Control (MVCC) mechanism, visibility check rules are used to determine which data versions are visible to a transaction’s snapshot. These rules ensure that each transaction sees a consistent snapshot of the database as of its start time.
The Visibility Check Rules in PostgreSQL are as follows:
1. Transaction ID (XID) Comparison: Each data version in PostgreSQL has an associated Transaction ID (XID) indicating the transaction that created or modified it. To determine if a data version is visible to a transaction’s snapshot, the following rule is applied:
xmin <= pg_current_xact_id ()
AND (xmax = 0 OR pg_current_xact_id () < xmax)
- If the
xminof the data version is lower than the transaction’s XID, it is considered committed before the transaction’s start time and visible to the transaction. - If the
xminof the data version is greater than or equal to the transaction’sXID, it is considered not yet committed or modified after the transaction’s start time and not visible to the transaction. However, a tuple will be visible even when xmin > pg_current_xact_id ()with READ COMMITTED isolation level. For example:



In this example, txid 609176 is still able to view committed data from txid 609177 which is a future transaction id. In PostgreSQL, when a transaction in READ COMMITTED isolation level starts a new query, it takes a new snapshot of the database state. This snapshot represents the committed state of the database at the point in time the query starts. This is the reason for allowing tuples to be visible with xmin > pg_current_xact_id ().
2. Snapshot Transaction ID Range: A transaction’s snapshot includes a transaction ID range that determines the XIDs of the data versions visible to the transaction. For example, you can use pg_current_snapshot () snapshot information function to list the snapshots transaction ID range.
mvcc=# begin;
BEGIN
mvcc=*# update account_info
set account_type = 'Checking'
where account = 2;
UPDATE 1
mvcc=*# select pg_current_snapshot();
pg_current_snapshot
---------------------
609172:609172:
(1 row)
mvcc=*# select pg_last_committed_xact ();
pg_last_committed_xact
--------------------------------------------
(609169,"2023-07-09 01:12:03.883742+00",0)
(1 row)
The snapshot includes the transaction’s own XID and may include a range of other XID values based on the chosen isolation level.
- Read Committed: A transaction’s snapshot includes its own
XIDonly, allowing it to see only committed data versions that existed before its start time. - Repeatable Read: A transaction’s snapshot includes its own
XIDand allXIDvalues that were already committed at its start time, allowing it to see a consistent snapshot of the data throughout the transaction’s duration. - Serializable: A transaction’s snapshot includes a range of XID values up to the transaction’s
XID, allowing it to see a consistent snapshot and preventing conflicts with concurrent transactions modifying the same data.
3. Visibility Information: Each data version in PostgreSQL has visibility information associated with it, including the minimum XID (xmin) and the maximum XID (xmax) that are allowed to see the version. These values are used to determine visibility based on the transaction’s snapshot.
- If the transaction’s
XIDis greater thanxmin, the data version is visible to the transaction. - If the transaction’s
XIDis greater than or equal toxmax, the data version is not visible to the transaction. - If
xminis less than the transaction’sXIDandxmaxis greater than the transaction’sXID, additional checks may be performed to handle special cases, such as in-progress transactions or locks have been held at tuple level.
By applying these visibility check rules, PostgreSQL ensures that each transaction sees a consistent snapshot of the data based on its start time and isolation level. This allows for concurrent access to the database while maintaining read consistency and transaction isolation.
Read Consistency
The read consistency refers to the guarantee that a transaction sees a consistent snapshot of the database as of the transaction’s start time, regardless of concurrent changes made by other transactions. Read consistency ensures that the data accessed by a transaction remains stable and consistent throughout its execution.
Let’s take a closer look at read phenomena, also known as anomalies, are undesirable behaviours that can occur in concurrent database transactions when multiple transactions are reading and modifying the same data concurrently. These phenomena can result in inconsistent or unexpected results if proper isolation and concurrency control measures are not in place.
Dirty Read – This phenomenon can occur during concurrent database transactions. It happens when one transaction reads data that has been modified by another transaction that has not yet been committed. In other words, a transaction reads uncommitted or dirty data. This is completely prevented in PostgreSQL (however this is still possible in other relational database systems such as SQL Server and Db2) and we cannot read uncommitted data.
Non-Repeatable Read – This phenomenon can occur when a transaction reads the same row or tuple multiple times during its execution, but the data values change or vanishes (is deleted) between the reads due to concurrent modifications by other transactions.
Phantom Read – This occurs when a transaction retrieves a set of rows based on a condition, and between consecutive reads, another transaction inserts that satisfy the same condition. As a result, the second read includes additional rows or misses previously retrieved rows, leading to an inconsistent result set.
Serialization Anomaly: This occurs when the outcome of executing a group of transactions concurrently is inconsistent with the outcome of executing the same transactions sequentially in all possible orderings. In other words, the final result of a set of concurrent transactions is not equivalent to any possible serial execution of those transactions.
In PostgreSQL, various transaction isolation levels are available to control the level of concurrency and consistency in database transactions. Each isolation level defines the visibility and locking behavior for concurrent transactions and PostgreSQL supports the following isolation levels:
1. Read Committed (default):
- Provides read consistency by ensuring that a transaction only sees data that has been committed at the time the query begins.
- Prevents dirty reads by requiring data to be committed before it becomes visible to other transactions.
- Allows non-repeatable reads and phantom reads, as concurrent transactions may modify the data between reads.
- Offers a good balance between consistency and concurrency and is suitable for many applications.
2. Repeatable Read:
- Provides a higher level of read consistency than
Read Committed. - Ensures that a transaction sees a consistent snapshot of the database as of the transaction’s start time.
- Prevents dirty reads and non-repeatable reads by acquiring read locks on accessed data, preventing concurrent modifications.
- Allows phantom reads, as concurrent transactions may insert new rows that match the query criteria.
- Provides a stronger guarantee of data consistency but can result in increased concurrency issues due to acquired locks.
3. Serializable:
- Provides the highest level of isolation and guarantees serializability of transactions.
- Ensures that concurrent transactions appear as if they were executed serially, without any concurrency anomalies.
- Prevents dirty reads, non-repeatable reads, and phantom reads.
- May result in increased locking and potential serialization conflicts, leading to more blocking and reduced concurrency.
Table 1 shows the phenomenon which can occur in a specific isolation level. Even though PostgreSQL allows setting the isolation level to uncommitted, it behaves exactly like read committed.
|
Isolation Level/Phenomenon |
Dirty Read |
Non-Repeatable Read |
Phantom Read |
Serialization Anomaly |
|
READ COMMITTED |
Not Possible |
Possible |
Possible |
Possible |
|
REPEATABLE READ |
Not Possible |
Not Possible |
Not Possible |
Possible |
|
SERIALIZABLE |
Not Possible |
Not Possible |
Not Possible |
Not Possible |
Table 1: Transaction Isolation Levels and Read Phenomenon
Let’s look at the Read Committed isolation level and its behavior. Figure 2 illustrates how the dirty read behavior would work. PostgreSQL always reads a committed version of the tuple and dirty reads are not possible. As a side note, you can set the transaction isolation at transactional level or at the database level.
Note: The default isolation level set at the database level is read committed. You can use ALTER DATABASE command to make the change as shown below:
ALTER DATABASE ${dbname}
SET DEFAULT_TRANSACTION_ISOLATION TO 'repeatable read';
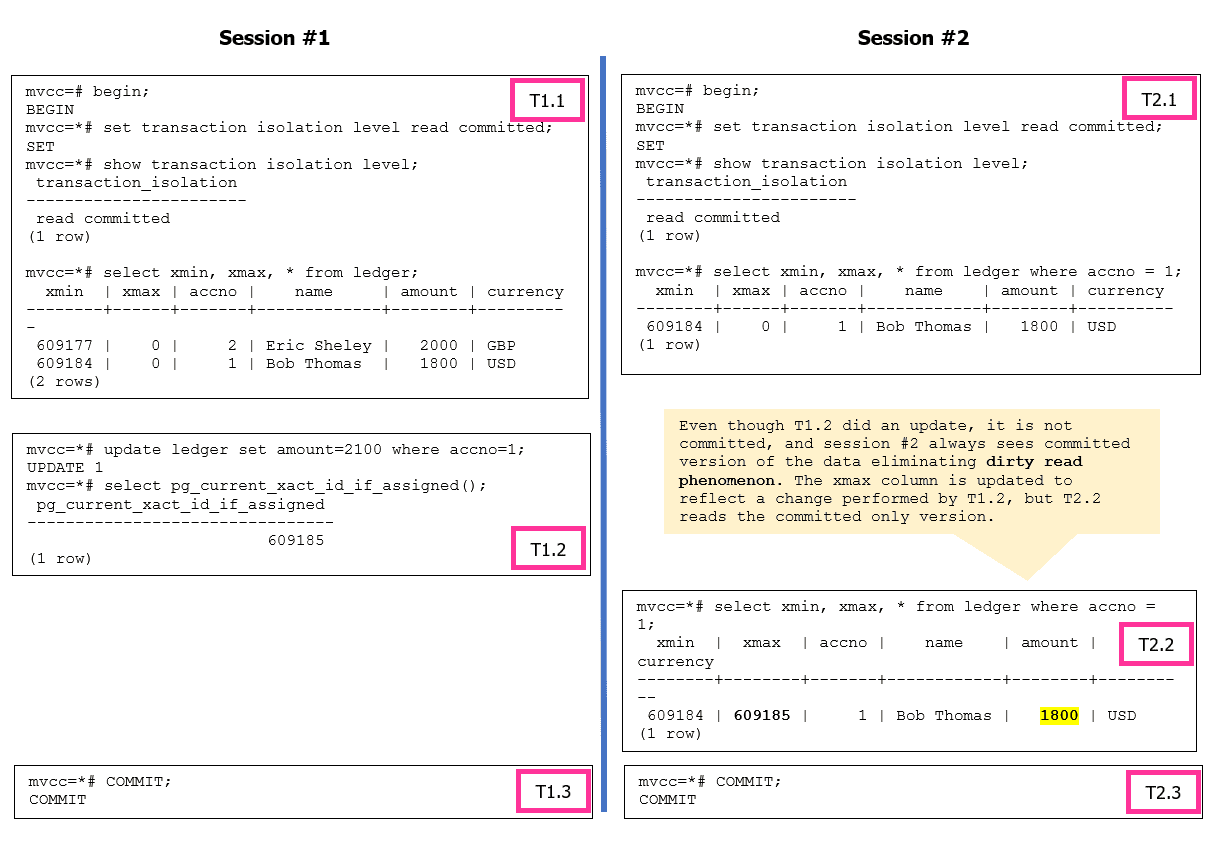
Figure 2: Dirty Read phenomenon is not a possibility in PostgreSQL
Figure 3 illustrates the possibility of having non-repeatable read and phantom phenomenon when the isolation level set to READ COMMITTED.


Figure 3: Non-Repeatable read and Phantom read phenomenon are possible in PostgreSQL
Let’s look at the Repeatable Read isolation level and its behavior. Figure 4 showcases how PostgreSQL resolves the non-repeatable read and phantom read anomalies. The serialization anomaly can still occur based on how the application is designed.


Figure 4: Repeatable Read Isolation Level Operations
What happens if an update is attempted to the same tuple from session #2? Let’s try.
mvcc=*# update ledger set amount = 2200 where accno = 1; ERROR: could not serialize access due to concurrent update mvcc=!# select pg_current_snapshot (); ERROR: current transaction is aborted, commands ignored until end of transaction block mvcc=!# rollback; ROLLBACK
The error message indicates a serialization failure during concurrent transactions. It occurs when two or more transactions attempt to modify the same data simultaneously, resulting in conflicts that violate the strict serializability guarantee.
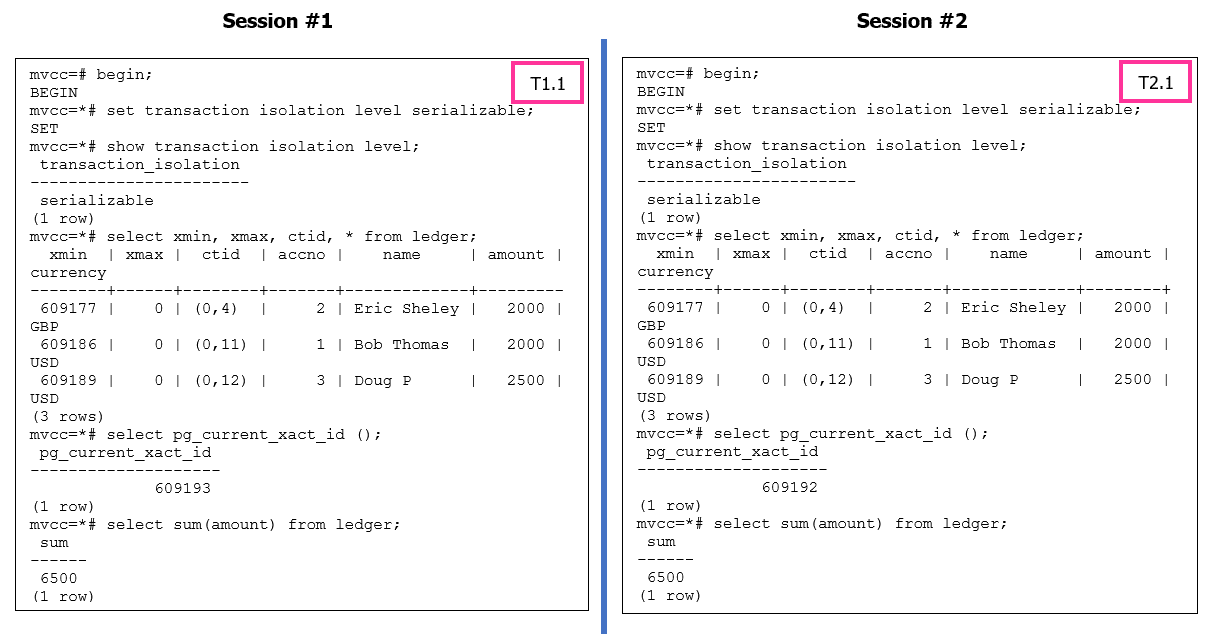
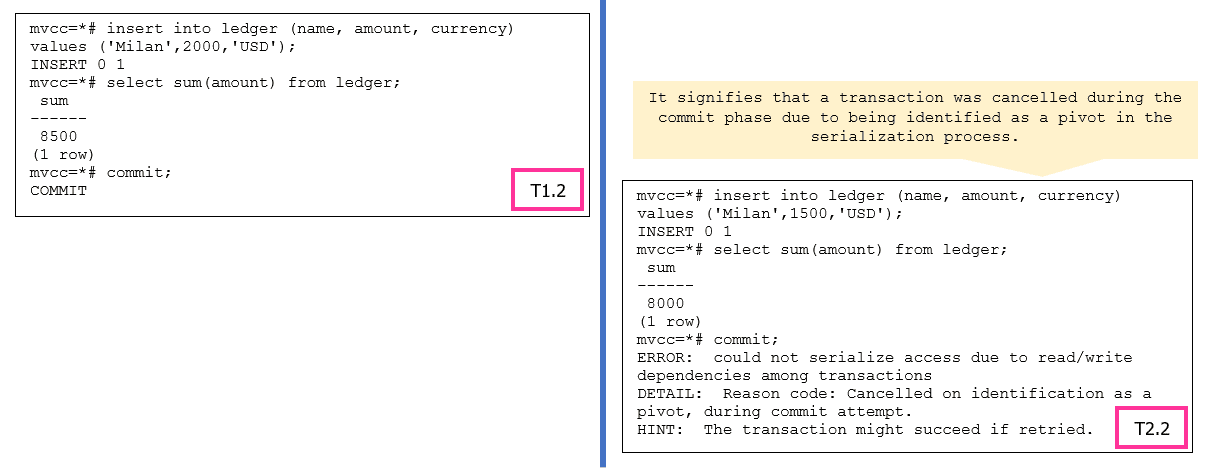
Figure 5: Serializable Isolation Level Operations
In PostgreSQL’s SERIALIZABLE isolation level, transactions are executed as if they were running in a serial order, which ensures data consistency. To maintain this strict serializability, PostgreSQL may identify a transaction as a “pivot” when conflicts occur with other concurrent transactions.
A “pivot” transaction is one that serves as a reference point for the serialization process. When conflicts arise, PostgreSQL may choose one transaction as the pivot and abort the other conflicting transactions to preserve consistency. The error message indicates that the transaction being canceled was identified as the pivot during the commit attempt.
For more information, please refer to https://wiki.postgresql.org/wiki/Serializable.
Write Operations
In PostgreSQL databases, an INSERT is simple and no different than other databases. The background writer and WAL writer processes handle the data write operation from shared buffers to the transaction log file and the data pages.
The interest is more in UPDATE and DELETE operations. Let’s take a look at UPDATE operation. When an UPDATE operation in PostgreSQL modifies a row, it follows a multi-version concurrency control (MVCC) mechanism. PostgreSQL will perform a delete and insert internally instead of modifying the existing row in place. This is done to ensure data consistency and handle concurrency control effectively by writers not blocking readers and readers not blocking the writers.
Every UPDATE operation performs pseudo delete, i.e., the original row is marked for deletion, creating a new version of the row with a delete flag. And an insert, a new row is inserted with the updated values, creating a new version of the row.
For simplicity, let’s take an UPDATE example with the READ COMMITTED (default) isolation level. In the example below, either of sessions can start the execution first or can execute both the sessions concurrently.
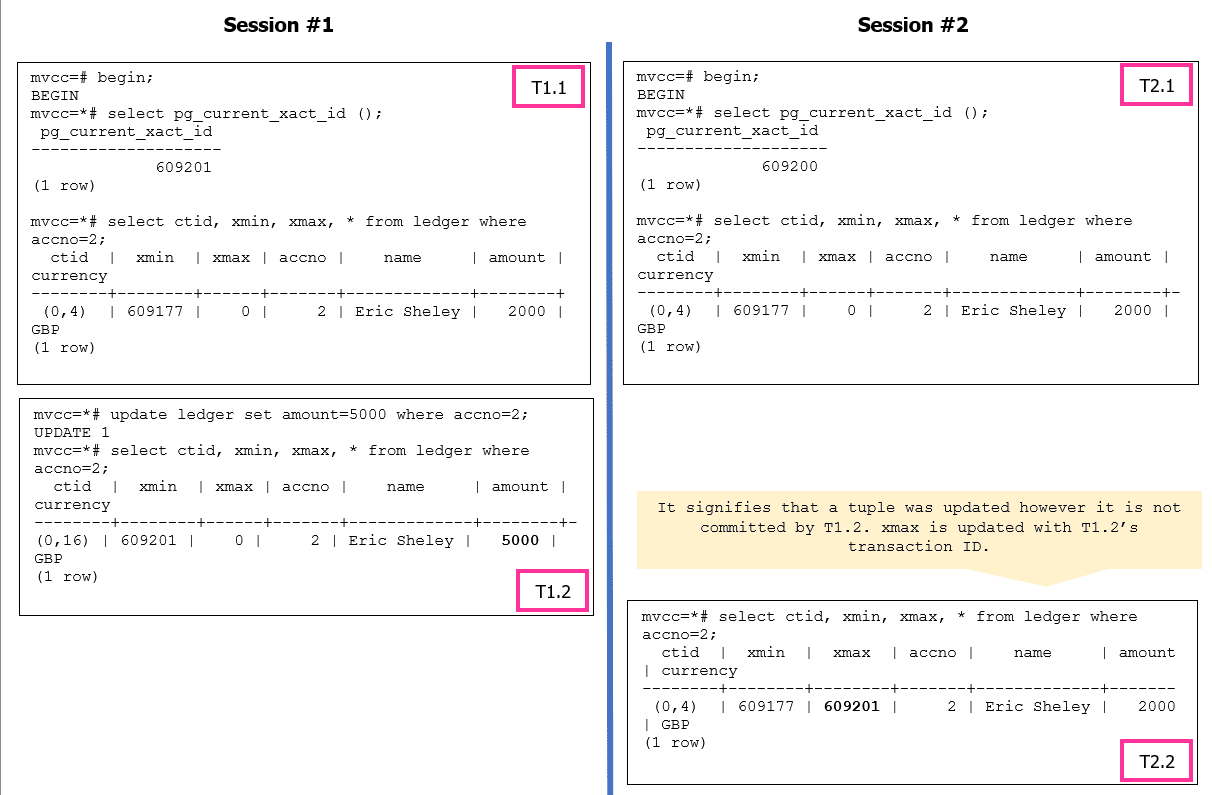

The pageinspect module functions can be used to analyze data at page level for both table and indexes. In the case of a DELETE operation, the xmax will be updated with the transaction id which executes the DELETE and marks the tuple as dead.
Garbage Collection
In PostgreSQL, garbage collection refers to the process of reclaiming disk space occupied by deleted or obsolete data. When data is deleted or updated in PostgreSQL, it is not immediately removed from the disk. Instead, it is marked as eligible for garbage collection, and the actual disk space is reclaimed later by the autovacuum process.
Based on our example, we have 4 live tuples and 12 dead tuples, these dead tuples can be cleaned using VACUUM. The VACUUM command is used to perform a table vacuum (data reorganization). It reclaims disk space by physically reorganizing the table and its associated indexes, and it can be more resource-intensive compared to regular VACUUM operations.
mvcc=# VACUUM VERBOSE ledger; INFO: vacuuming "mvcc.public.ledger" INFO: finished vacuuming "mvcc.public.ledger": index scans: 1 pages: 0 removed, 1 remain, 1 scanned (100.00% of total) tuples: 12 removed, 4 remain, 0 are dead but not yet removable removable cutoff: 609251, which was 0 XIDs old when operation ended index scan needed: 1 pages from table (100.00% of total) had 12 dead item identifiers removed index "ledger_pkey": pages: 2 in total, 0 newly deleted, 0 currently deleted, 0 reusable avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s buffer usage: 11 hits, 0 misses, 0 dirtied WAL usage: 4 records, 1 full page images, 8480 bytes system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s VACUUM
However, the dead tuple count is still showing as 12 in the catalog. This is just the system catalog information and we will have to execute the ANALYZE command to update table statistics, including information about the distribution of data, column histograms, and correlation between columns. These statistics are used by the query optimizer to generate efficient execution plans

Summary:
MVCC (Multi-Version Concurrency Control) is a concurrency control mechanism used in PostgreSQL to handle concurrent access to data. It allows multiple transactions to read and write data concurrently while maintaining transaction isolation and ensuring consistency. In this article we learnt MVCC specifics and the building blocks of MVCC in detail. We will dive deep into each section such as VACUUM internals, storage internals, index B tree internal and locking internals in the future articles.
The post Database Concurrency in PostgreSQL appeared first on Simple Talk.
from Simple Talk https://ift.tt/4jq15EB
via
No comments:
Post a Comment