When people start learning a new field, for example T-SQL, it’s tempting to spend very little time trying to understand the fundamentals of the field so that you can quickly get to the advanced parts. You might think that you already understand what certain ideas, concepts and terms mean, so you don’t necessarily see the value in dwelling on them. That’s often the case with newcomers to T-SQL, especially because soon after you start learning the language, you can already write queries that return results, giving you a false impression that it’s a simple or easy language. However, without a good understanding of the foundations and roots of the language, you’re bound to end up writing code that doesn’t mean what you think it means. To be able to write robust and correct T-SQL code, you really want to spend a lot of energy on making sure that you have an in-depth understanding of the fundamentals.
A great example for a fundamental concept in T-SQL that seems simple but actually involves many subtleties is: duplicates. The concept of duplicates is at the heart of relational database design and T-SQL. Understanding what duplicates are is consequential to many of its features. It’s also important to understand the differences between how T-SQL handles duplicates versus how relational theory does.
In this article I focus on duplicates and how to control them. In order to understand duplicates correctly, you need to understand the concepts of distinctness and equality, which I’ll cover as well.
In my examples I will use the sample database TSQLV6. You can download the script file to create and populate this database and its ER diagram in a .ZIP file here. (You can find all of my downloads on my website at the following address: https://itziktsql.com/r-downloads)
What are duplicates in T-SQL?
T-SQL is a dialect of standard SQL So, the obvious place to look for the definition of duplicates is in the standard’s text, assuming you have access to it (you can purchase a copy using the link provided) and the stomach for it. If you do look for the definition of duplicates in the standard’s text, you’ll quickly start wondering how deep the rabbit hole goes.
Here’s the definition of duplicates in the standard:
Duplicates
Two or more members of a multiset that are not distinct
So now you need to figure out what multiset and distinct mean.
Let’s start with multiset. This can get a bit confusing since there’s both a mathematical concept called multiset and a specific feature in the SQL standard called MULTISET (one of two kinds of collection types: ARRAY and MULTISET). T-SQL doesn’t support the standard collection types ARRAY and MULTISET. However, the mathematical concept of a multiset is quite important to understand for T-SQL practitioners.
Here’s the description of a multiset from Wikipedia:
Multiset
In mathematics, a multiset (or bag, or mset) is a modification of the concept of a set that, unlike a set, allows for multiple instances for each of its elements.
In other words, whereas a set is a collection of distinct elements, a multiset allows duplicates. Oops…
I’m not sure why they chose in the standard to define duplicates via multisets. To me, it should be the other way around. I think that it’s sufficient to understand the concept of duplicates via distinctness alone, and later talk about what multisets are.
So, back to the definitions section in the SQL standard, here’s the definition of distinctness:
Distinct (of a pair of comparable values)
Capable of being distinguished within a given context.
Hmm… not very helpful. But wait, there’s more! There’s NOTE 8:
NOTE 8 — Informally, two values are distinct if neither is null and the values are not equal. A null value and a nonnull value are distinct. Two null values are not distinct. See Subclause 4.1.5, “Properties of distinct”, and the General Rules of Subclause 8.15, “<distinct predicate>”.
Let’s start with the meaning of a given context. This has to do with the contexts in SQL where a pair of values can be compared. It could be a query filter, a join predicate, a set operator, the DISTINCT set quantifier in the SELECT list or an aggregate function, grouping, uniqueness, and so on.
Next, let’s talk about the meaning of a pair of comparable values. The concept of distinctness is relevant to a pair of values that can be compared. Later the standard contrasts this with values of a user-defined type that has no comparison type, in which case distinctness is undefined.
I also need to mention here that when the standard uses the term value, it actually includes both non-NULL values and NULLs. To some, myself included, a NULL is a marker for a missing value, and therefore the term NULL value is actually incorrect. But what could be an inclusive term for both NULLs and non-NULL values? I don’t know that there’s a common industry term that is simple, intuitive and accurate. If you know one, let me know! Since our focus is things that can be compared, maybe we’ll just use the term comparands. And by the way, in SQL, the concepts of duplicates and distinctness are of course relevant not just to scalar comparands, but also to row comparands.
What’s left to understand is what capable of being distinguished means. Note 8 goes into details trying to explain distinctness via equality, with exceptions when NULLs are involved. And as usual, it sends you elsewhere to read about properties of distinct, and the distinct predicate.
What’s crucial to understand here is that there’s an important difference between equality-based comparison (or inequality) and distinctness-based comparison in SQL. You understand the difference using predicate logic. Given comparands c1 and c2, here are the truth values for the inequality-based predicate c1 <> c2 versus the distinctness-based counterpart c1 is distinct from c2:
|
c1 |
c2 |
c1 <> c2 |
c1 is distinct from c2 |
|
non-NULL X |
non-NULL X |
false |
false |
|
non-NULL X |
non-NULL Y |
true |
true |
|
any non-NULL |
NULL |
unknown |
true |
|
NULL |
any non-NULL |
unknown |
true |
|
NULL |
NULL |
unknown |
false |
As you can see, with inequality, when both comparands are non-NULL, if they are the same the comparison evaluates to false and if they are different it evaluates to true. If any of the comparands is NULL, including both, the comparison evaluates to the truth value unknown.
With distinctness, when both comparands are non-NULL, the behavior is the same as with inequality. When you have NULLs involved, they are basically treated just like non-NULL values. Meaning that when both comparands are NULL, IS DISTINCT FROM evaluates to false, otherwise to true.
Similarly, given comparands c1 and c2, here are the truth values for the equality-based predicate c1 = c2 versus the distinctness-based counterpart c1 is not distinct from c2:
|
c1 |
c2 |
c1 = c2 |
c1 is not distinct from c2 |
|
non-NULL X |
non-NULL X |
true |
true |
|
non-NULL X |
non-NULL Y |
false |
false |
|
any non-NULL |
NULL |
unknown |
false |
|
NULL |
any non-NULL |
unknown |
false |
|
NULL |
NULL |
unknown |
true |
As you can see, with equality, when both comparands are non-NULL, if they are the same the comparison evaluates to true and if they are different it evaluates to false. If any of the comparands is NULL, including both, the comparison evaluates to the truth value unknown.
With non-distinctness, when both comparands are non-NULL, the behavior is the same as with equality. When you have NULLs involved, they are basically treated just like non-NULL values. Meaning that when both comparands are NULL, IS NOT DISTINCT FROM evaluates to true, otherwise to false.
In case you’re not already aware of this, starting with SQL Server 2022, T-SQL supports the explicit form of the standard distinct predicate, using the syntax <comparand 1> IS [NOT] DISTINCT FROM <comparand 2>. You can find the details here.
As you can gather, trying to understand things from the standard can be quite an adventure.
So let’s try to simplify our understanding of duplicates.
First, you need to understand the concept of distinctness. This is done using predicate logic by understanding the difference between equality-based comparison and distinctness-based comparison, and familiarity with the distinct predicate and its rules.
These concepts are not trivial to digest for the uninitiated, but they are critical for a correct understanding of the concept of duplicates.
Assuming you have the concept of distinctness figured out, you can then understand duplicates.
Duplicates
Comparands c1 and c2 are duplicates if c1 is not distinct from c2. That is, if the predicate c1 IS NOT DISTINCT FROM c2 evaluates to true.
The comparands c1 and c2 can be scalar comparands, in contexts like filter and join predicates, or row comparands, in contexts like the DISTINCT quantifier in the SELECT list and set operators.
T-SQL/SQL Versus Relational Theory
Even though standard SQL and the T-SQL dialect, which is based on it, are founded in relational theory, they deviate from it in a number of ways, one of which is the handling of duplicates. The main structure in relational theory is a relation. Relational expressions operate on relations as inputs and emit a relation as output.
The counterpart to a relation is a table in SQL. Similar to relational expressions, table expressions, such as ones defined by queries, operate on tables as inputs and emit a table as output.
A relation has a heading and a body. The heading of a relation is a set of attributes. Similarly, the heading of a Table is a set of columns. There are interesting differences between the two, but that’s not the focus of this article.
The body of a relation is a set of tuples. Recall that a set has no duplicates. This means that by definition, a relation must have at least one candidate key.
Unlike the body of a relation, the body of a table is a multiset of rows. Recall, a multiset is similar to a set, only it does allow duplicates. Indeed, you don’t have to define a key in a table (no primary key or unique constraint), and if you don’t, the table can have duplicate rows.
Furthermore, even if you do have a key defined in a table; unlike a relational expression, a table expression that is based on a base table with a key, does not by default eliminate duplicates from the result table that it emits.
Suppose that you need to project the countries where you have employees. In relational theory you formulate a relational expression doing so, and you don’t need to be explicit about the fact that you don’t want duplicate countries in the result. This is implied from the fact that the outcome of a relational expression is a relation. Suppose you try achieving the same in T-SQL using the following table expression:
SELECT country FROM HR.Employees
As an aside, you might be wondering now why I didn’t terminate this expression, despite the fact that I keep telling people how important it is to terminate all statements in T-SQL as a best practice. Well, you terminate statements in T-SQL. Statements do something. My focus now is the table expression returning a table with the cities where you have employees. The expression is the query part without the terminator, and is the part that can be nested in more elaborate table expressions.
Back to our discussion about duplicates. Despite the fact that the underlying Employees table has a key and hence no duplicates, this table expression which is based on Employees, does have duplicates in its table result:
Run the following code:
USE TSQLV6; SELECT country FROM HR.Employees;
You get the following output:
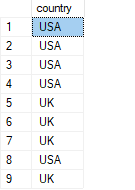
Of course, T-SQL does give you tools to eliminate duplicates in a table expression if you want to, it’s just that in some cases it doesn’t do so by default. In the above example, as you know well, you can use the DISTINCT set quantifier for this purpose. People often learn a dialect of SQL like T-SQL without learning the theory behind it. Many are so used to the fact that returning duplicates is the default behavior, that they don’t realize that that’s not really normal in the underlying theory.
Controlling duplicates in T-SQL/SQL
If I tried covering all aspects of controlling duplicates in T-SQL, I’d probably easily end up with dozens of pages. To make this article more approachable, I’ll focus on features that involve using quantifiers to allow or restrict duplicates.
SELECT List
T-SQL allows you to apply a set quantifier ALL | DISTINCT to the SELECT list of a query. The default is ALL if you don’t specify a quantifier.
The earlier query returning the countries where you have employees, without removal of duplicates, is equivalent to the following:
SELECT ALL country FROM HR.Employees;
As you know, you need to explicitly use the DISTINCT quantifier to remove duplicates, like so:
SELECT DISTINCT country FROM HR.Employees;
This code returns the following output:

Aggregate Functions
Similar to the SELECT list’s quantifier, you can apply a set quantifier ALL | DISTINCT to the input of an aggregate function. Also here the ALL quantifier is the default if you don’t specify one explicitly. With the ALL quantifier—whether explicit or implied—redundant duplicates are retained. The following two queries are logically equivalent:
SELECT COUNT(country) AS cnt FROM HR.Employees; SELECT COUNT(ALL country) AS cnt FROM HR.Employees;
Both queries return a count of 9 since there are nine rows where country is not NULL.
Again, you can use the DISTINCT quantifier if you want to remove redundant duplicates, like so:
SELECT COUNT(DISTINCT country) AS cnt FROM HR.Employees;
This query returns 2 since there are two distinct countries where you have employees.
Note that at the time of writing, T-SQL supports the DISTINCT quantifier with grouped aggregate functions, but not with windowed aggregate functions. There are workarounds, but they are far from being trivial.
Set operators
Set operators allow you to combine data from two input table expressions. The SQL standard supports three set operators UNION, INTERSECT and EXCEPT, each with two possible quantifiers ALL | DISTINCT. With set operators the DISTINCT quantifier is the default if you don’t specify one explicitly.
At the time of writing, T-SQL supports only a subset of the standard set operators. It supports UNION (implied DISTINCT), UNION ALL, INTERSECT (implied DISTINCT) and EXCEPT (implied DISTINCT). It doesn’t allow you to be explicit with the DISTINCT quantifier, although that’s the behavior that you get by default, and it supports the ALL option only with the UNION ALL operator. It currently does not support the INTERSECT ALL and EXPECT ALL operators. I’ll explain all standard variants, and for the missing ones in T-SQL, I’ll provide workarounds.
You apply a set operator to two input table expressions, which I’ll refer to as TE1 and TE2:
TE1 <set operator> TE2
The above represents a table expression.
A statement based on a table expression with a set operator can have an optional ORDER BY clause applied to the result, using the following syntax:
TE1 <set operator> TE2 [ORDER BY <order by list>];
You’re probably familiar with the set operators that T-SQL supports. Still, let me briefly explain what each operator does:
UNION: Returns distinct rows that appear inTE1,TE2or both. That is, if rowRappears inTE1,TE2or both, irrespective of number of occurrences, it appears exactly once in the result.UNION ALL: Returns all rows that appear inTE1,TE2or both. That is, if row R appears m times inTE1and n times inTE2, it appearsm + ntimes in the result.INTERSECT: Returns distinct rows that are common to bothTE1andTE2. That is, if rowRappears at least once inTE1, and at least once inTE2, it appears exactly once in the result.INTERSECT ALL: Returns all rows that are common to bothTE1andTE2. That is, if row R appears m times inTE1and n times inTE2, it appearsminimum(m, n)times in the result. For example, ifRappears 5 times inTE1and 3 times inTE2, it appears 3 times in the result.EXCEPT: Returns distinct rows that appear inTE1but not inTE2. That is, if a rowRappears inTE1, irrespective of the number of occurrences, and does not appear inTE2, it appears exactly once in the output.EXCEPT ALL: Returns all rows that appear inTE1but don’t have an occurrence match inTE2. That is, if a rowRappears m times inTE1, and n times inTE2, it appearsmaximum((m - n), 0)times in the result. For example, ifRappears 5 times inTE1and 3 times inTE2, it appears 2 times in the result. IfRappears 3 times inTE1and 5 times inTE2, it doesn’t appear in the result.
An interesting question is why would you use a set operator to handle a given task as opposed to alternative tools to combine data from multiple tables, such as joins and subqueries? To me, one of the main benefits is the fact that when set operators compare rows, they implicitly use distinctness-based comparison and not equality-based comparison. Recall that distinctness-based comparison handles NULLs and non-NULL values the same way, essentially using two-valued logic instead of three-valued logic. That’s often the desired behavior, and with set operators it simplifies the code a great deal. For example, the following code identifies distinct locations that are both customer locations and employee locations:
SELECT country, region, city FROM Sales.Customers INTERSECT SELECT country, region, city FROM HR.Employees;
This code generates the following output:
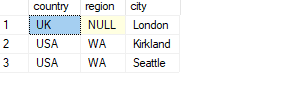
Since set operators implicitly use the distinct predicate to compare rows (not to confuse with the fact that without an explicit quantifier they use the DISTINCT quantifier by default), you didn’t need to do anything special to get a match when comparing two NULLs and a nonmatch when comparing a NULL with a non-NULL value. The location UK, NULL, London is part of the result since it appears in both inputs.
Also, with no explicit quantifier specified, a set operator uses an implicit DISTINCT quantifier by default. Remember that with INTERSECT, as long as at least one occurrence of a row appears in both sides, INTERSECT returns one occurrence of the row in the result.
As an exercise, I urge you to write a logically equivalent solution to the above code, using either joins or subqueries. Of course it’s doable, but not this concisely.
As mentioned, the standard also supports an ALL version of INTERSECT. For example, the following standard query returns all occurrences of locations that are both customer locations and employee locations (don’t run it against SQL Server since it’s not supported in T-SQL):
SELECT country, region, city FROM Sales.Customers INTERSECT ALL SELECT country, region, city FROM HR.Employees;
If you want to use a solution that is supported in T-SQL, the trick is to compute row numbers in each input table expression to number the duplicates, and then apply the operation to the inputs including the row numbers. You can then exclude the row numbers from the result by using a named table expression like a CTE. Here’s the complete code:
WITH C AS
(
SELECT country, region, city,
ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY (SELECT NULL)) AS rownum
FROM Sales.Customers
INTERSECT
SELECT country, region, city,
ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY (SELECT NULL)) AS rownum
FROM HR.Employees
)
SELECT country, region, city
FROM C;
This code generates the following output:
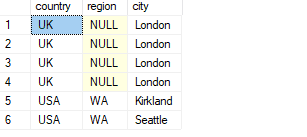
The location UK, NULL, London appears 6 times in the first input table expression and 4 times in the second, therefore 4 occurrences intersect.
You can handle an except need very similarly. If you’re interested in an except distinct operation, you use the EXCEPT (implied DISTINCT) in T-SQL. For example, the following code returns distinct employee locations that are not customer locations:
SELECT country, region, city FROM HR.Employees EXCEPT SELECT country, region, city FROM Sales.Customers;
This code generates the following output:

If you wanted all employee locations that per occurrence don’t have a matching customer location, the standard code for this looks like so:
SELECT country, region, city FROM HR.Employees EXCEPT ALL SELECT country, region, city FROM Sales.Customers;
However, T-SQL doesn’t support the ALL quantifier with the EXCEPT operator. You can use a similar trick to the one you used to achieve the equivalent of INTERSECT ALL. You can achieve the equivalent of EXCEPT ALL by applying EXCEPT (implied DISTINCT) to inputs that include row numbers that number duplicate, like so:
WITH C AS
(
SELECT country, region, city,
ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY (SELECT NULL)) AS rownum
FROM HR.Employees
EXCEPT
SELECT country, region, city,
ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY (SELECT NULL)) AS rownum
FROM Sales.Customers
)
SELECT country, region, city
FROM C;
This code generates the following output:
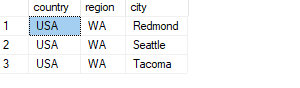
Curiously, Seattle appears once in this result of except all but didn’t appear at all in the result of the except distinct version. You might initially think that there’s a bug in the code. But think carefully what could explain this? There are two employees from Seattle and one customer from Seattle. The except distinct operation isn’t supposed to return any occurrences in the result, yet the except all operation is indeed supposed to return one occurrence.
Conclusion
Without proper understanding of the foundations of T-SQL—primarily relational theory and its own roots—it’s hard to truly understand what you’re dealing with. In this article I focused on duplicates. A concept that to most seems trivial and intuitive. However, as it turns out, a true understanding of duplicates in T-SQL is far from being trivial.
You need to understand the differences between how relational theory treats duplicates versus SQL/T-SQL. A relation’s body doesn’t have duplicates whereas a table’s body can have those.
It’s very important to understand the difference between distinctness-based comparison, such as when using the distinct predicate explicitly or implicitly, versus equality-based comparison. Then you realize that in T-SQL, two comparands are duplicates when one is not distinct from the other.
You also need to understand the nuances of how T-SQL handles duplicates, the cases where it retains redundant ones versus cases where it removes those. You also need to understand the tools that you have to change the default behavior using quantifiers such as DISTINCT and ALL.
I discussed controlling duplicates in a query’s SELECT list, aggregate functions and set operators. But there are other language elements where you might need to control them such as handling ties with the TOP filter, window functions, and others.
What I hope that you take away from this article is the significance of investing time and energy in learning the fundamentals. And if you haven’t had enough of T-SQL Fundamentals, and I’m allowed a shameless plug, check out my new book T-SQL Fundamentals 4th Edition.
May the 4th be with you!
The post T-SQL Fundamentals: Controlling Duplicates appeared first on Simple Talk.
from Simple Talk https://ift.tt/zn5NIH8
via
No comments:
Post a Comment