Nearly a decade ago, I wrote a post called “Bad habits : Counting rows the hard way.” In that post, I talked about how we can use SQL Server’s metadata to instantly retrieve the row count for a table. Typically, people do the following, which has to read the entire table or index:
DECLARE @c int = (SELECT COUNT(*) FROM dbo.TableName);
To largely avoid size-of-data constraints, we can instead use sys.partitions.
OBJECT_ID() instead of a join, but that function doesn’t observe isolation semantics, so can cause blocking – or be a victim. A potential compromise is to create standardized metadata views, but I’ll leave that as an exercise for the reader.DECLARE @object int = (SELECT o.object_id
FROM sys.objects AS o
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE o.name = N'TableName'
AND s.name = N'dbo');
DECLARE @c int = (SELECT SUM([rows])
FROM sys.partitions
WHERE index_id IN (0,1)
AND object_id = @object);
That’s great when you want to count the whole table without size-of-entire-table reads. It gets more complicated if you need to retrieve the count of rows that meet – or don’t meet – some criteria. Sometimes an index can help, but not always, depending on how complex the criteria might be.
An example
One example is the soft delete, where we have a bit column like IsActive that defaults to 1, and only gets updated to 0 when a row gets “soft deleted.” Consider a table like this:
CREATE TABLE dbo.Users ( UserID int NOT NULL, Filler char(2000) NOT NULL DEFAULT '', IsActive bit NOT NULL DEFAULT 1, CONSTRAINT PK_Users PRIMARY KEY (UserID) ); -- insert 100 rows: INSERT dbo.Users(UserID) SELECT TOP (100) ROW_NUMBER() OVER (ORDER BY object_id) FROM sys.all_columns ORDER BY object_id; -- soft delete 3 rows: UPDATE dbo.Users SET IsActive = 0 WHERE UserID IN (66, 99, 4);
The metadata alone can’t tell us how many active users we have; only the total. But sometimes we want to know how many are active and how many are inactive. I have seen users implement such a query like this:
SELECT [status] = 'Active', [count] = COUNT(*) FROM dbo.Users WHERE IsActive = 1 UNION ALL SELECT [status] = 'Inactive', [count] = COUNT(*) FROM dbo.Users WHERE IsActive = 0;
Results:
status count -----------|-------| Active | 97 | Inactive | 3 |
Without any other indexes, this is achieved with two full scans:
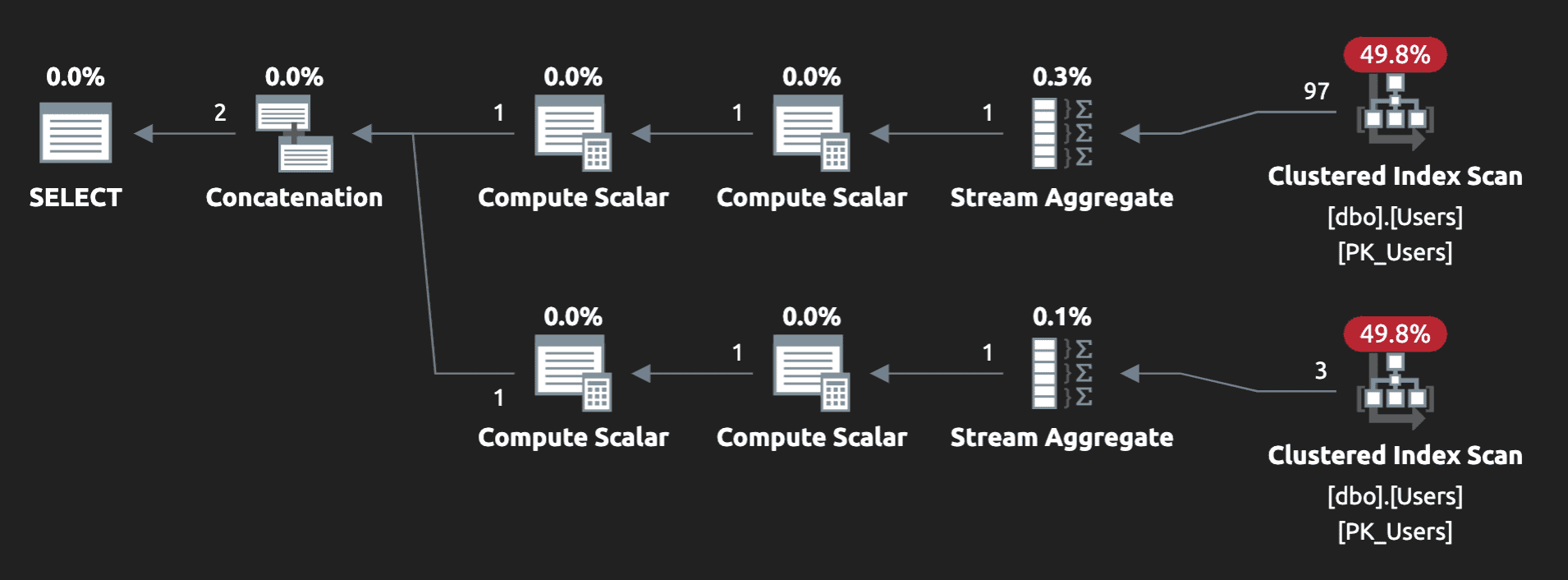
A union produces two full scans
A slightly more efficient query, that only scans the entire table once, is a conditional aggregation:
SELECT Active = COUNT(CASE IsActive WHEN 1 THEN 1 END),
InActive = COUNT(CASE IsActive WHEN 0 THEN 1 END)
FROM dbo.Users;
Results:
Active Inactive
--------|-----------|
97 | 3 |
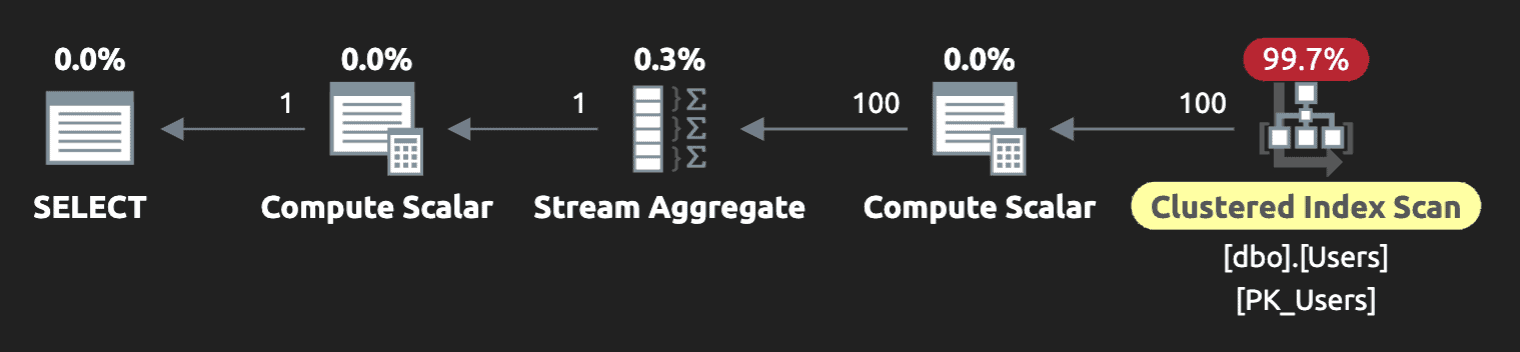
Conditional aggregation: just one scan
Why not create an index?
Conventional wisdom has told us to not create indexes involving bit columns, because they’re not very selective. If you’re using such a column to highlight the minority (e.g. only a tiny fraction of users ever get soft deleted), then an index on just the IsActive column wouldn’t be extremely useful:
CREATE INDEX ix_IsActive ON dbo.Users(IsActive);
The above queries would still have to look at all the rows (the conditional aggregate would still perform a full scan, and the UNION would seek twice, at this low row count, but that could get worse at scale). Both plans:
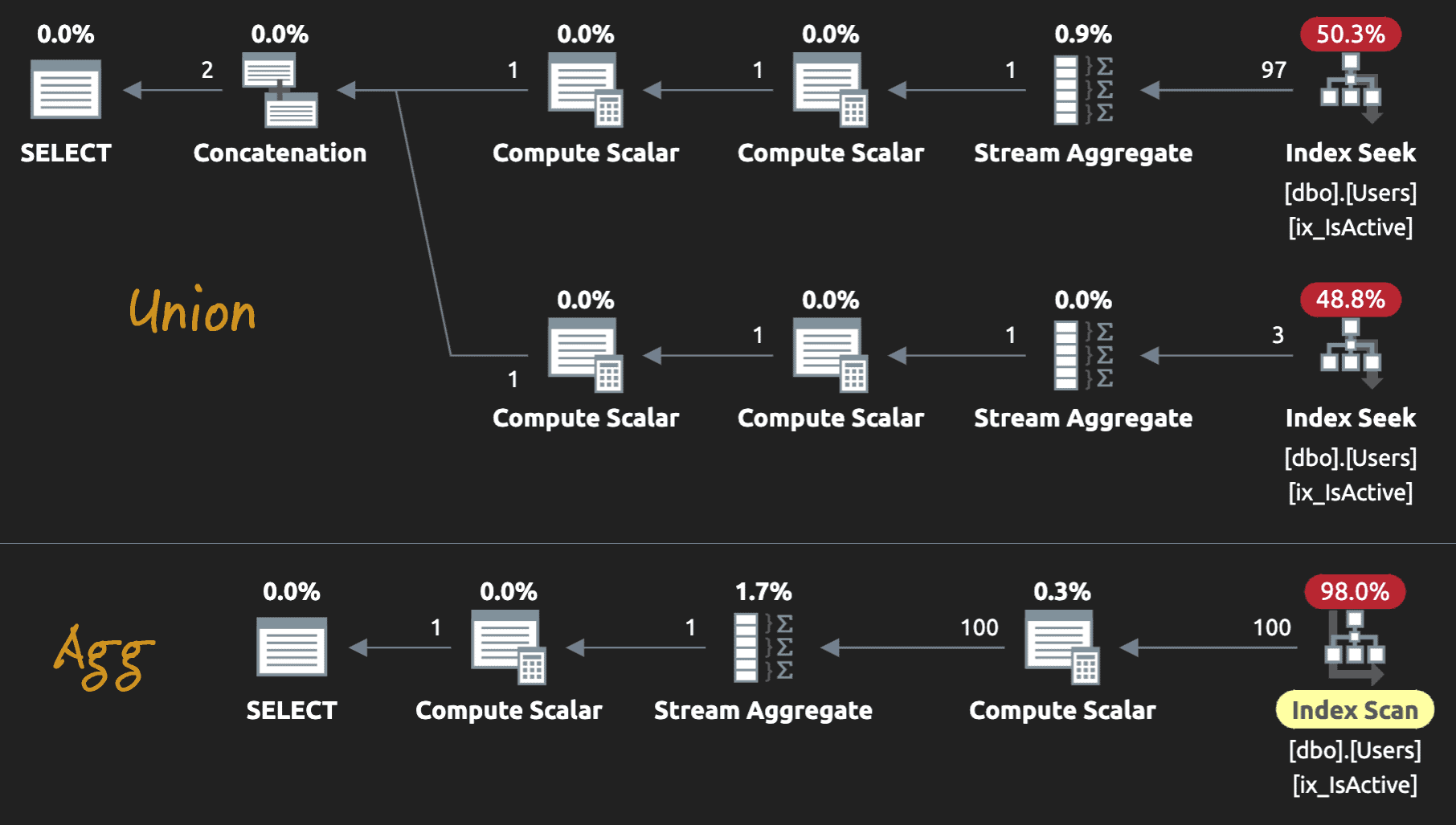
An index might not be overly helpful
But what if we had a filtered index on just the minority case (where IsActive = 0)?
DROP INDEX ix_IsActive ON dbo.Users; CREATE INDEX ix_IsInactive ON dbo.Users(IsActive) WHERE IsActive = 0;
This doesn’t help our existing queries much at all. The UNION can scan this smaller index to get the inactive count, but still has to scan the entire table for the active count. And the conditional aggregate still has to perform a full scan:
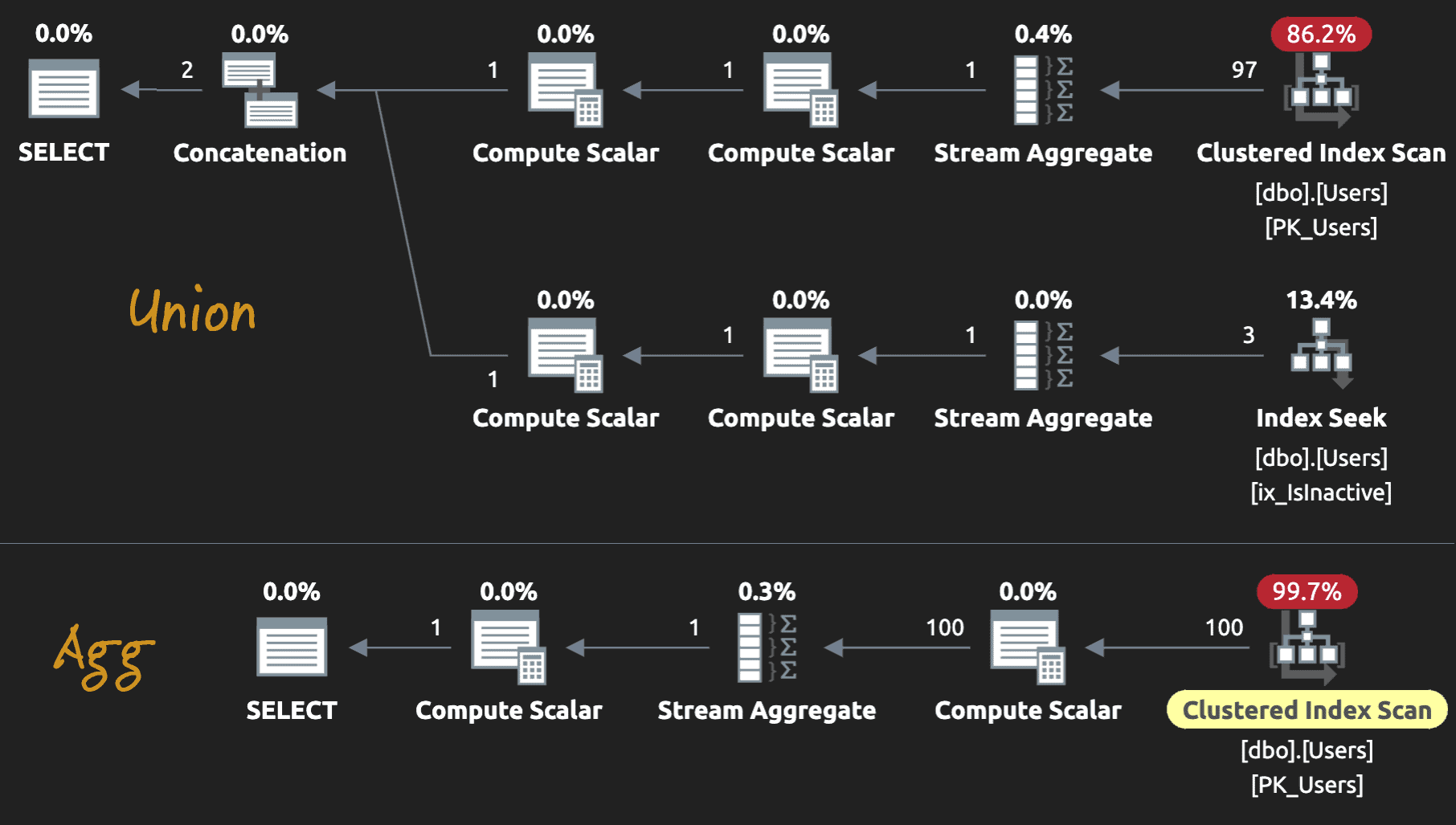
Even a filtered index might not be overly helpful
The filtered index brings the two queries closer, but both still have performance tied to the size of the table.
That said…
The filtered index buys us something else
Here’s a secret: with the filtered index, we can now satisfy both counts without ever touching the table at all. Assuming IsActive can’t be NULL, then active user count is simply the total subtract the inactive user count. So this query gets the same results without size-of-entire-index reads:
WITH idx AS
(
SELECT i.[object_id], i.index_id
FROM sys.indexes AS i
INNER JOIN sys.objects AS o
ON i.[object_id] = o.[object_id]
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE o.name = N'Users'
AND s.name = N'dbo'
AND
(
i.index_id IN (0,1)
OR i.filter_definition = N'([IsActive]=(0))'
)
), agg AS
(
SELECT Total = SUM(CASE WHEN p.index_id IN (0,1) THEN p.[rows] END),
Inactive = SUM(CASE WHEN p.index_id > 1 THEN p.[Rows] END)
FROM sys.partitions AS p
INNER JOIN idx
ON p.[object_id] = idx.[object_id]
AND p.index_id = idx.index_id
)
SELECT Active = Total - Inactive,
Inactive
FROM agg;
Now, the query is a lot more complicated than it absolutely has to be, and produces a plan that is far more elaborate than you might expect (so elaborate I’m not going to show it). But you can simplify. If you know the index_id for the filtered index (in my case, 3), for example, and are confident in OBJECT_ID:
DECLARE @filter tinyint = 3;
WITH agg AS
(
SELECT Total = SUM(CASE WHEN index_id <> @filter THEN [rows] END),
Inactive = SUM(CASE WHEN index_id = @filter THEN [Rows] END)
FROM sys.partitions
WHERE [object_id] = OBJECT_ID(N'dbo.Users')
AND index_id IN (0, 1, @filter)
)
SELECT Active = Total - Inactive,
Inactive
FROM agg;
You might not want to memorize the index_id, or hard-code that in production, since indexes can be dropped and re-created in any order. But if you can trust the index name to be stable, and for the filter definition to be accurate, you could replace the first line with the following:
DECLARE @filter tinyint;
SELECT @filter = index_id
FROM sys.indexes
WHERE name = N'ix_IsInactive'
AND has_filter = 1
AND [object_id] = OBJECT_ID(N'dbo.Users');
In either case, you may want error handling to indicate if the index wasn’t found.
Other examples
I used bit columns here to dovetail off an earlier post entitled “Strategies for queries against bit columns.” But this technique isn’t limited to one of two values with significant skew; it can be applied in many more scenarios.
For example, I’ve had dashboards that pull subsets of tables to give counts of things such as some related set of error status codes, and then a filtered index like WHERE error_code IN (1, 12, 18456). Now the dashboard can go right to the metadata and pull a single count directly.
You can do similar things with date ranges, e.g. have a filtered index re-created at the beginning of each month (or any other period), with a hard-coded start range, to simulate partitioning (at least for the current “partition”) without all the work. The metadata for that index will always show the total count of rows for the current month.
And you could combine these as well; for example, a filtered index against some set of error codes this month. Or a filtered index for each error code this month, if they’re important independently, too.
Conclusion
In spite of ugly-looking underlying execution plans against system objects, this technique should be much faster than querying the table – particularly at scale. The only exception might be when the table is small or otherwise always in memory, and sys.partitions is massive (e.g. you have a ridiculous number of tables, partitions, and indexes). Going after the metadata is a technique you may want to consider if you’re performing a lot of queries for counts, filtered or not.
The post Counting more efficiently appeared first on Simple Talk.
from Simple Talk https://ift.tt/xfRtcpS
via
No comments:
Post a Comment