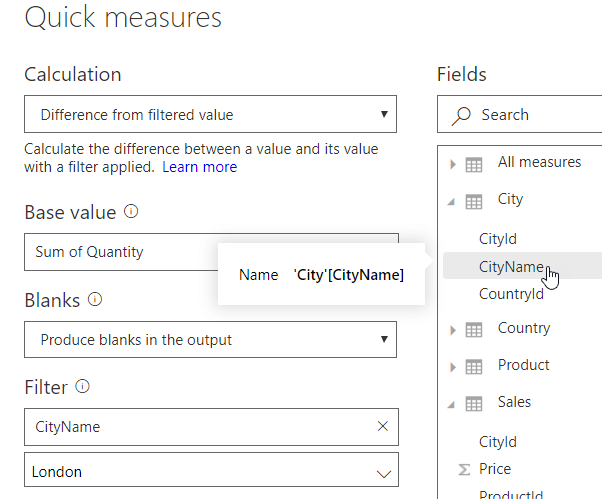
Security can be one of the most complex issues to contend with when managing a SQL Server instance, yet it’s also one of the most important, especially when sensitive and personal data are on the line. In fact, for many organizations, security is their number one priority, which should come as no surprise, given what’s at stake.
Fortunately, SQL Server includes a variety of tools for protecting data from theft, destruction, and other types of malicious behavior. In this article, the first in a series about SQL Server security, I introduce you to many of these tools, with the goal of providing you with an overview of the options available for safeguarding your data. In subsequent articles, I’ll dig deeper into the different technologies, providing a more in-depth look at how they work and what it takes to protect a SQL Server instance.
SQL Server Authentication and Authorization
Protecting data starts with the ability to authenticate users and authorize their access to specific data. To this end, SQL Server includes an authentication mechanism for verifying the identities of users trying to connect to a SQL Server instance, as well as an authorization mechanism that determines which data resources that authorized users can access and what actions they can take.
Authentication and authorization are achieved in SQL Server through a combination of security principals, securables, and permissions. Before I get into these, however, it’s important to note that SQL Server supports two authentication modes: Windows Authentication, sometimes referred to as integrated security, and SQL Server and Windows Authentication, sometimes referred to as mixed mode.
Windows authentication is integrated with Windows user and group accounts, making it possible to use a local or domain Windows account to log into SQL Server. When a Windows user connects to a SQL Server instance, the database engine validates the login credentials against the Windows principal token, eliminating the need for separate SQL Server credentials. Microsoft recommends that you use Windows Authentication whenever possible.
In some cases, however, you might require SQL Server Authentication. For example, users might connect from non-trusted domains, or the server on which SQL Server is hosted is not part of a domain, in which case, you can use the login mechanisms built into SQL Server, without linking to Windows accounts. Under this scenario, the user supplies a username and password to connect to the SQL Server instance, bypassing Windows Authentication altogether
You can specify the authentication mode when setting up a SQL Server instance or change it after implementation through the server’s properties, as shown in Figure 1.
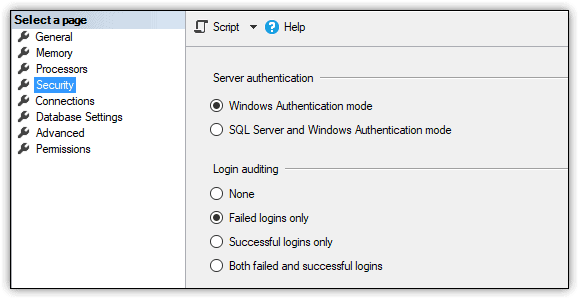
Figure 1. Selecting an authentication mode for a SQL Server 2017 instance
At the heart of the authentication and authorization mechanisms are the principals, securables, and permissions that must be configured to enable users to access the data they need, while preventing unauthorized users from accessing data they shouldn’t.
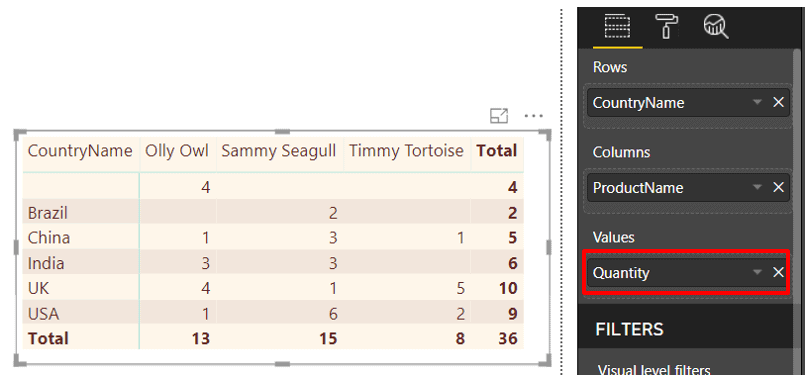
You can view and work with principals, securables, and permissions through SQL Server Management Studio (SSMS), using either the built-in GUI tools or the available T-SQL statements. Figure 2 shows Object Explorer in SSMS with the expanded Security folder for the WideWorldImporters database and, below that, the expanded Security folder for the SQL Server instance.
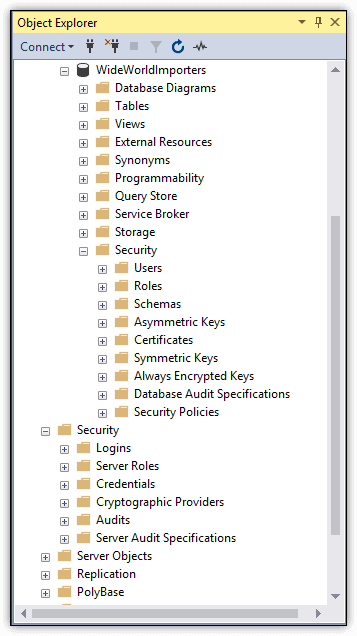
Figure 2. Working with security features in Object Explorer
Principals are individuals, groups, or processes that are granted access to the SQL Server instance, either at the server level or database level. Server-level principals include logins and server roles, which are listed in the Logins and Server Roles subfolders in the Security folder:
- A login is an individual user account for logging into the SQL Server instance. A login can be a local or domain Windows account or a SQL Server account. You can assign server-level permissions to a login, such as granting a user the ability to create databases or logins.
- A server role is a group of users that share a common set of server-level permissions. SQL Server supports fixed server roles and user-defined server roles. You can assign logins to a fixed server role, but you cannot change its permissions. You can do both with a user-defined server role.
Database-level principals include users and database roles, which are listed in the Users and Roles subfolders in the database’s Security folder:
- A database user is an individual user account for logging into a specific database. The database user commonly maps to a corresponding server login in order to provide access to the SQL Server instance as well as the data itself. However, you can create database users that are independent of any logins, which can be useful for developing and testing data-driven applications, as well as for implementing contained databases.
- A database role is a group of users that share a common set of database-level permissions. As with server roles, SQL Server supports both fixed and user-defined database roles.
For each security principal, you can grant rights that allow that principal to access or modify a set of securables. Securables are the objects that make up the database and server environment. They can include anything from functions to database users to endpoints. SQL Server scopes the objects hierarchically at the server, database and schema levels:
- Server-level securables include databases as well as objects such as logins, server roles, and availability groups.
- Database-level securables include schemas as well as objects such as database users, database roles, and full-text catalogs.
- Schema-level securables include objects such as tables, views, functions, and stored procedures.
Permissions define the level of access permitted to principals on specific securables. You can grant or deny permissions to securables at the server, database, or schema level. The permissions you grant at a higher level of the hierarchy can also apply to the children objects, unless you specifically override the permissions at the lower level.
For example, if you grant the SELECT permission to the user1 principal on the Sales schema in the WideWorldImporters database, the user will be able to query all table data in that schema. However, if you then deny the SELECT permission on the Sales.Customers table, the user will not be able to query that table, but will still be able to access the other tables in that schema.
You can use SSMS or T-SQL to view the permissions that have been explicitly granted to a user on a securable. For example, Figure 3 shows the permissions granted to the user2 principal on the Sales.Customers table. In this case, the user has been granted the DELETE, INSERT, SELECT and UPDATE permissions, with no permissions explicitly denied.
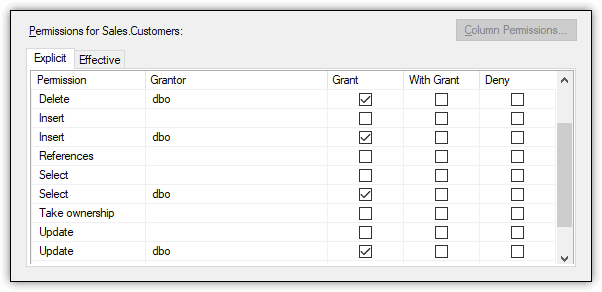
Figure 3. Viewing a user’s permissions granted on a schema object
Configuring permissions for multiple principles on multiple securables can be a complex and sometimes frustrating process. If you don’t get it right, you could end up denying permissions to users who should have access to specific data or, worse still, granting access to users who should not. The safest bet is to follow the principles of least privilege, working at the most granular level practical for a given situation.
Additional Access Control Features
SQL Server also provides several other features for controlling access to data. For example, you can implement row-level security on a specific table by creating a security policy that calls one or more predicates. A security policy defines the structure necessary to apply row-level security to a table. A predicate is a table-value function that provides the logic necessary to determine which rows the security policy applies to.
A security policy supports two types of predicates: filter and block. A filter predicate filters the rows available to read operations, and a block predicate blocks write operations that violate the predicate. You can include both filter and block predicates within a security policy, and you can call the same or different predicate functions within that policy.
For example, the WideWorldImporters database includes the FilterCustomersBySalesTerritoryRole security policy, which defines both a filter predicate and block predicate. Figure 4 shows the security policy as it is listed in Object Explorer, along with the policy definition. In this case, both the filter predicate and block predicate call the DetermineCustomerAccess function, which determines which rows the current user can access.
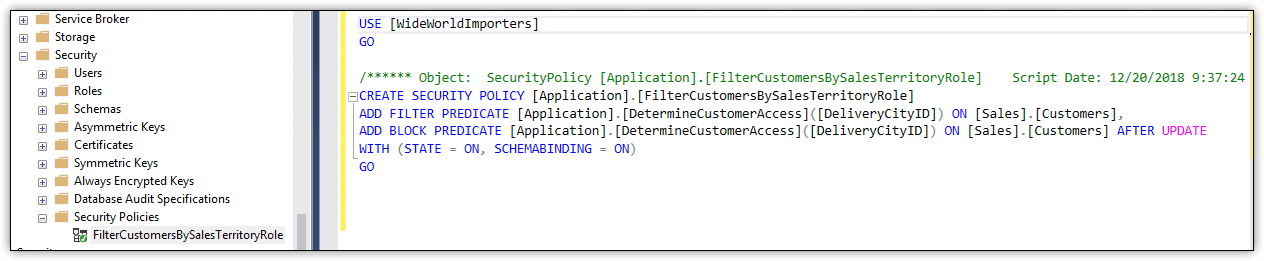
Figure 4. Viewing a security policy definition in SSMS
Another SQL Server security feature is the application role, which is similar to the database role, except that it is used specifically to assign permissions to an application. However, unlike database roles, application roles do not contain members. In addition, they’re invoked only when an application connects to SQL Server and calls the sp_setapprole system stored procedure, passing in the name of the application role and password. SQL Server enforces the permissions granted to the application role for the duration of the connection.
Another access mechanism that SQL Server provides is the credential, a server-level object (record) that contains authentication information such as a username and password. The credential makes it possible for a SQL Server user to connect to a resource outside of the SQL Server environment. For example, you can use a credential to run an external assembly or to access domain resources if you’ve logged in using SQL Server Authentication.
SQL Server Data Encryption
Also important to SQL Server security are the encryption capabilities built into the database engine. Encryption provides a way to encode—or obfuscate—data so that only authorized users can view the data in an unencrypted state. To everyone else, the encrypted data looks like gibberish.
Encryption is not an access-control mechanism, that is, it does not prevent unauthorized users from accessing data. However, encryption can limit the exposure of sensitive data should unauthorized users manage to break through SQL Server’s access-control defenses. For example, if cybercriminals acquire encrypted credit card information from a database, they will not be able to make sense of that data unless they’ve also figured out a way to decrypt it.
SQL Server supports several approaches to encryption to accommodate different types of data and workloads. For example, you can encrypt data at the column level by taking advantage of SQL Server’s built-in encryption hierarchy and key management infrastructure. Under this model, each layer encrypts the layer below it, using a layered architecture made up of a public key certificate and several symmetric keys. In this way, the column data is always protected until it is specifically decrypted.
Another tool available to SQL Server is Transparent Data Encryption (TDE), which encrypts and decrypts both data and log files in real-time, working at the page level to ensure that data at-rest is protected. The database engine encrypts the pages before writing them to disk and decrypts them when reading the pages into memory. Unlike column-level encryption, an application does not have to take specific steps to decrypt the data. The entire process occurs behind the scenes.
SQL Server also supports the Always Encrypted feature, which makes it possible for a client application to handle the actual encryption operations, without the encryption keys being revealed to the database engine. However, to implement Always Encrypted, you must first generate the column encryption keys necessary to support Always Encrypted. To do so, you can use the Always Encrypted wizard in SSMS, as shown in Figure 5.
Figure 5. Running the Always Encrypted wizard
Once the columns have been encrypted, the data is ready for client access. However, for a client application to connect to encrypted data, it must incorporate a driver that is enabled for Always Encrypted and can handle the encryption and decryption operations.
Another useful SQL Server security feature is Dynamic Data Masking (DDM), a tool for masking all or part of data values. Although DDM doesn’t actually encrypt the data, it does limit the amount of exposed data to non-authorized users. For example, you can use DDM to mask all but the last four digits of a credit card number or national identifier such as a social security number.
SQL Server Tools
SQL Server includes a number of other tools to help protect data and limit risks. For example, you can use SQL Server Configuration Manager to configure startup or connection options, or use the sp_configure stored procedure to configure global SQL Server settings. SQL Server also provides the Surface Area Configuration facets for enabling or disabling features at the instance level, as shown in Figure 6.
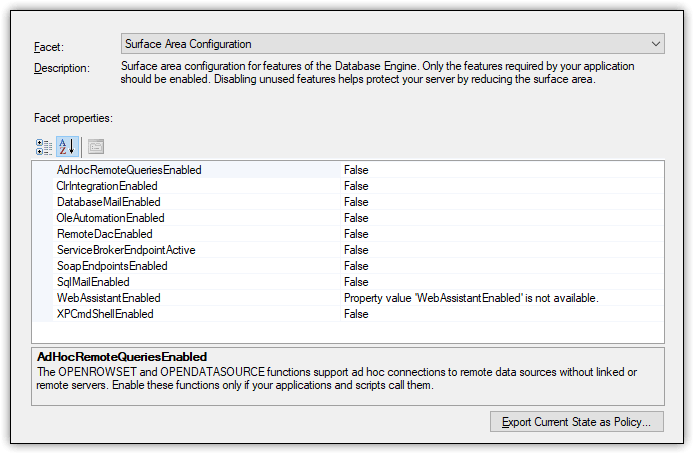
Figure 6. Accessing the Surface Area Configuration facets for a SQL Server 2017 instance
You can use these tools to ensure that only those features essential to supporting your users and applications are enabled at any given time, helping to reduce the exposed surface area and consequently the level of risk.
SQL Server also provides tools for identifying potential database issues. For instance, SQL Server provides the TRUSTWORTHY property as one of its database properties. The property shows whether the current SQL Server instance can trust the database and its contents.
In addition, SSMS provides the Data Discovery & Classification feature for classifying, labeling, and reporting on potentially sensitive data in a database, as well as the SQL Vulnerability Assessment (SVA) tool for discovering, tracking, and addressing potential database vulnerabilities. Figure 7 shows the results of running an SVA assessment against the WideWorldImporters database in SQL Server 2017.
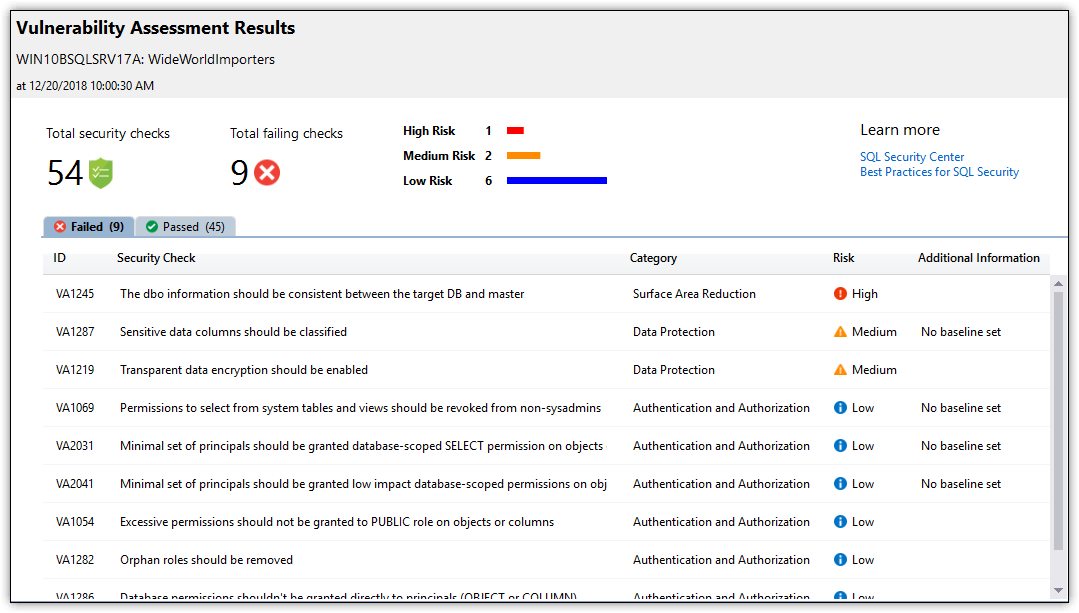
Figure 7. Viewing a SQL Vulnerability Assessment report
One of the most valuable SQL Server security tools is SQL Server Audit, which provides a structure for tracking and logging events that occur within the database engine. With SQL Server Audit, you can monitor events at the server level, database level, or both.
SQL Server Audit comprises three primary component types. The first is the audit object, which provides a structure for carrying out the auditing process. The audit object defines a target for the audited events. The target can be log files, the Application log, or the Security log. The audit object also includes configuration settings such as the number and size of the log files.
In addition to the audit object, an audit usually includes a server audit specification, a database audit specification for each applicable database, or a combination of any of these. The specifications determine which events should be audited at the server level or database level. For example, Figure 8 shows a database audit specification that audits UPDATE and DELETE events on the Sales.Customers table.
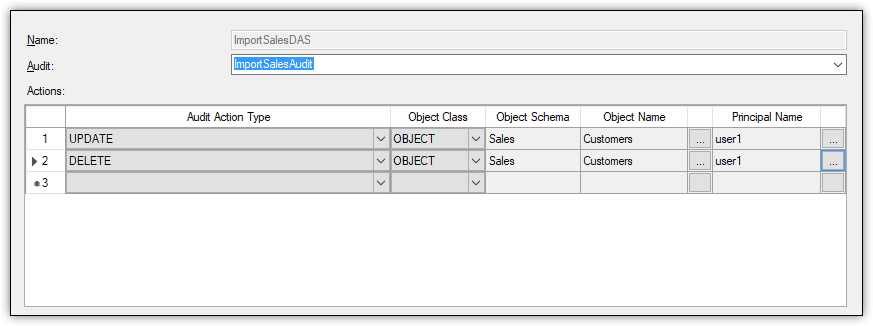
Figure 8. Viewing the audited actions defined in a database audit specification
In this case, both events are specific to the user1 database user. If the user tries to update or delete data in the Customers table, SQL Server Audit will log the event to the target repository.
Along with all these tools, SQL Server also provides a number of catalog views and dynamic management views for accessing security-related data. For example, you can retrieve details about the permissions granted and denied to a specific database user.
Protecting a SQL Server instance
In addition to taking steps within SQL Server to protect data, DBAs should also be certain to implement protections related to the SQL Server instance as a whole, such as disabling unused SQL Server components, applying security patches and service packs in a timely manner, and ensuring that database and backup files are fully protected and secure at all times.
But a protection strategy should not be limited only to SQL Server. The host operating system should also be kept up-to-date and properly patched, with just as much attention paid to surface area reduction.
In addition, DBAs and IT administrators must ensure that the host server is physically protected and that network safeguards such as firewalls and intrusion detection are in place. A SQL Server instance must be both physically and logically protected to achieve the maximum security.
Development teams must also ensure that the applications connecting to a SQL Server instance are properly vetted for security issues. A data-driven application is at risk for a number of attacks, including connection string injections, elevation of privileges, and SQL injections. The teams should factor in data security from the start, when first designing the application, not after it’s been implemented.
Securing SQL Server
SQL Server security is a huge topic, and what I’ve covered here barely skims that surface. You should view this article as only a starting point, meant to alert you to the many security considerations to take into account and the different SQL Server tools available for protecting data.
As this series progresses, I’ll dig deeper into the various security components, fleshing out what I’ve covered here and introducing you to concepts I’ve yet to explore. In the meantime, I recommend you learn as much about SQL Server security as possible, beginning with Microsoft’s own documentation.
The post Introduction to SQL Server Security — Part 1 appeared first on Simple Talk.
from Simple Talk http://bit.ly/2AmO9Fm
via