The series so far:
- Understanding your Azure EA Billing Data and Building a Centralized Data Storage Solution
- Azure EA Financial Reporting and Granular Access to Data Through the Enterprise
Even today, many organizations are struggling to get value from their data in a prompt and coherent way. The topic is complex, and there are many bits and pieces which need to come into place before organizations even get to work with data and act on the learnings from it. There are usually substantial hurdles in the form of legacy systems, ancient ETL flows, non-trustworthy reproductions of data, security concerns, and manual data crunching processes with deeply embedded black-box functionality.
These challenges, however, translate clearly to a requirement/need: how can we have knowledge, ideas, and data openly available at the fingertips of an organization so it can prosper?
First, of course, the organization needs to recognize that openness and sharing are of great value. Second, a common foundation needs to be in a place where people can collaborate in a smart and engaging way. Moreover, the culture of openness needs to be promoted and maintained.
In this article, I will demonstrate the architecture, workflow and some of the challenges of such a collaborative platform. As an example, I will be using the EA Billing solution, which I presented in the previous articles of the series. The solution, in this case, will have two functions – one of them will be an application that someone in the organization is willing to develop, and the second will be an actual part of the cloud foundation platform since an important part is to manage the costs of the cloud foundation platform itself. For the purposes here, the article covers working with the Azure platform, but the abstracted concept is perfectly valid for any cloud platform or even for a private internal cloud setup.
Start with the Curious User
One of the main challenges in many organizations is that curiosity and the ability to explore does not really go beyond the work computer and the knowledge locked on it. There are monolithic production systems, data flows, and integrations, but the knowledge is not easily discoverable, and their building blocks are not modular enough to be dismantled, improved and reused.
The first component needed in place is a curious user, who is ready to discover, build and share.

For example, imagine a curious user who wants to build an app which helps the organization to manage their cloud platform costs better.
The curious user has questions like
- Has anything been done in the area of cloud cost management within the organization?
- Has anyone worked on the dataset?
- How do I get a working integration for this data?
- Is there any previous knowledge about billing data in the organization?
- Is there any competence within the organization which can help me get started?
Getting the answers to all of these questions can easily keep the curious user busy for a while and thus away from actually working on developing the app.
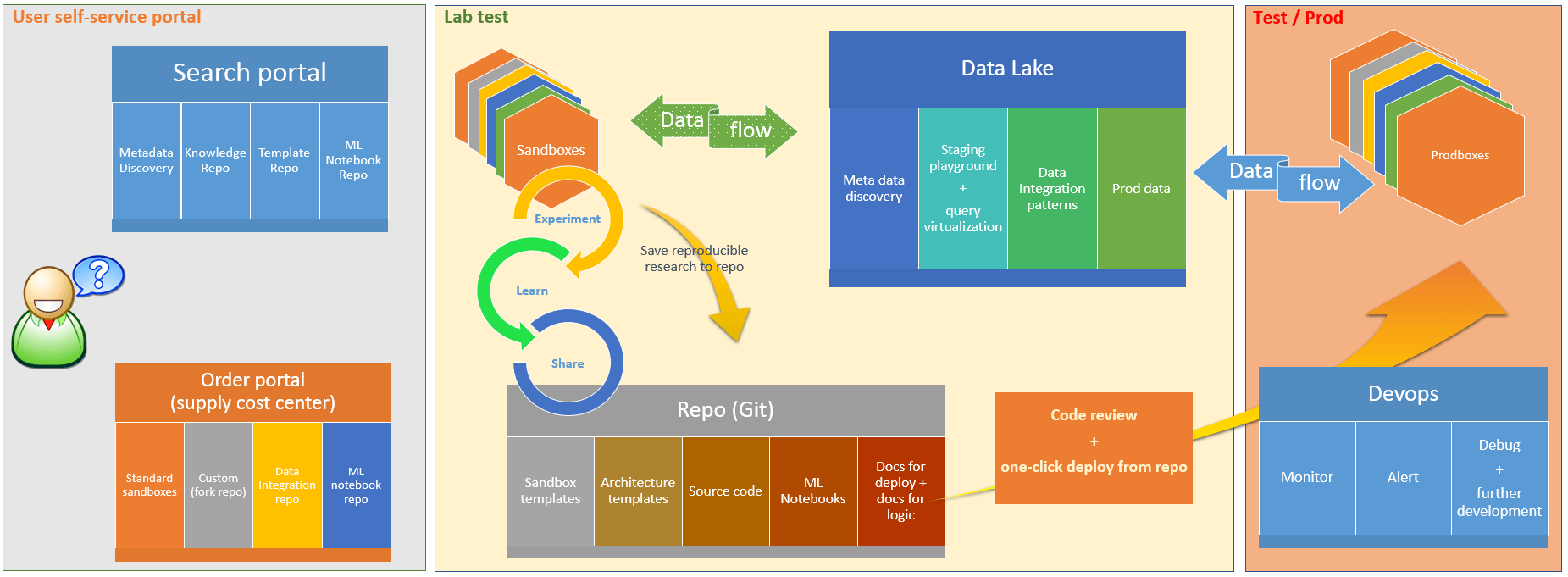
To solve this set of challenges and to make sure the curious user gets to do actual work, they need to be put into a context which helps them answer the questions above. The first thing they need is search functionality.
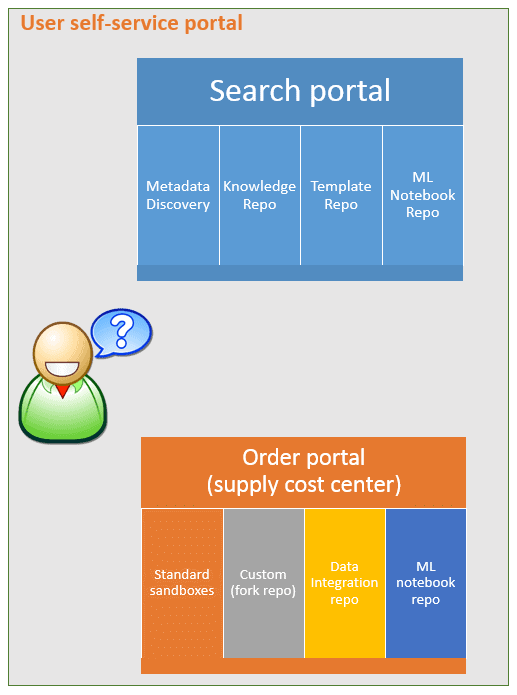
Search Platform
If the curious user has access to a search portal where they can search for metadata, knowledge, previous projects, machine learning notebooks, and resource deployment templates, then the path to doing actual work is shortened significantly.

As you can see in the picture above, there is a search portal where the curious user can discover if anyone in the organization has worked on EA Billing before, if there is any metadata, if anyone has documented anything on the topic.
In this case, suppose that there is nothing available. (I will close the loop at the end of this article with another curious user who is looking for a report on the subset of the EA billing data and finds this project.)
Order Portal
For the user to start working on this application, they will need the following:
- A sandbox — This is where the development work will be done. This might be a Data Science Virtual Machine (DSVM) in Azure, which comes with all tools preinstalled.
- An architecture environment which can be setup from a template — Architecture follows predictable patterns in 90% of the cases, and this means that a library of architecture solutions can be available and deployed from templates. For example, the curious user will know that to start; they will use a common pattern architecture where data will flow from an API and will be recorded in an Azure SQL database.
- Integration patterns – The user will need to do data integration, i.e., the logistics of calling the source, transforming the data and writing the data to the destination.
- ML notebooks – If machine learning or analysis is to be done on the data, then ML notebooks will be used.
All the user needs now is a cost center code, and with that code, they can get the bits and pieces they need from the Order Portal:
- An ARM (Azure Resource Manager) template for deploying the appropriate size of the DSVM — This is a one-click deploy with a bit of configuration work.
- An ARM template for the architecture, from API to Azure SQL database — The curious user can deploy the resources they need with one click; then they can configure, further develop and re-deploy.
- Integration patterns – The user gets templates for Azure Data Factory integration flows which help them get started on getting a sample of data so they can start developing the API App.
- ML notebooks – The curious user gets a set of sample notebooks which show some very common patterns for time series analysis. After all, billing data is expected to be a time series data set.
Sandbox Labs
As mentioned, it is imperative to be able to provide the curious users across your organization with the ability to quickly access a lab environment where they can incubate and iterate ideas.
The DSVM in Azure, which is available from the portal, is already loaded with almost everything a curious user may need – there is an R environment, Python, Visual Studio Code, and so on. Also, keep in mind that the ARM templates for the sandboxes are kept in the GIT repository, which is a part of the Cloud Foundation platform. A user may have access to choose from a list of ARM templates for sandboxes, but they can’t change the code of the ARM template. And in the ARM template there is a functionality which limits the allowed values like this: “allowedValues”: [ “<array-of-allowed-values>” ]. This means that the curious user will not overspend and will not use a sandbox for production purposes.

The user gets also a Visual Studio project which contains three solutions which are empty in this case. The empty solutions also come from the GIT repository, and they are configured according to the chosen architecture: API App + Web job + Azure SQL Database.
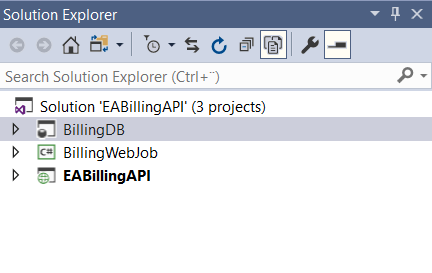
Another important part of the work is the data that the curious user needs for the project. To start the work, they get a small dataset from the EA Billing data so they can develop the SQL Database. They get this as a template from GIT which contains a template on how to call an API and save the data in the Data Lake.
Data Lake with Metadata Discovery
The Data Lake consists of two parts:
- Staging playground – sample data for PoCs which consists of subsets from prod or other large datasets
- Prod data – This part of the data lake contains full datasets which are used for production systems.
One important quality of the Data Lake is that it supports data virtualization, metadata catalog which is searchable, and it has a data integration repo which is maintained to follow the most common principles of data integrations.
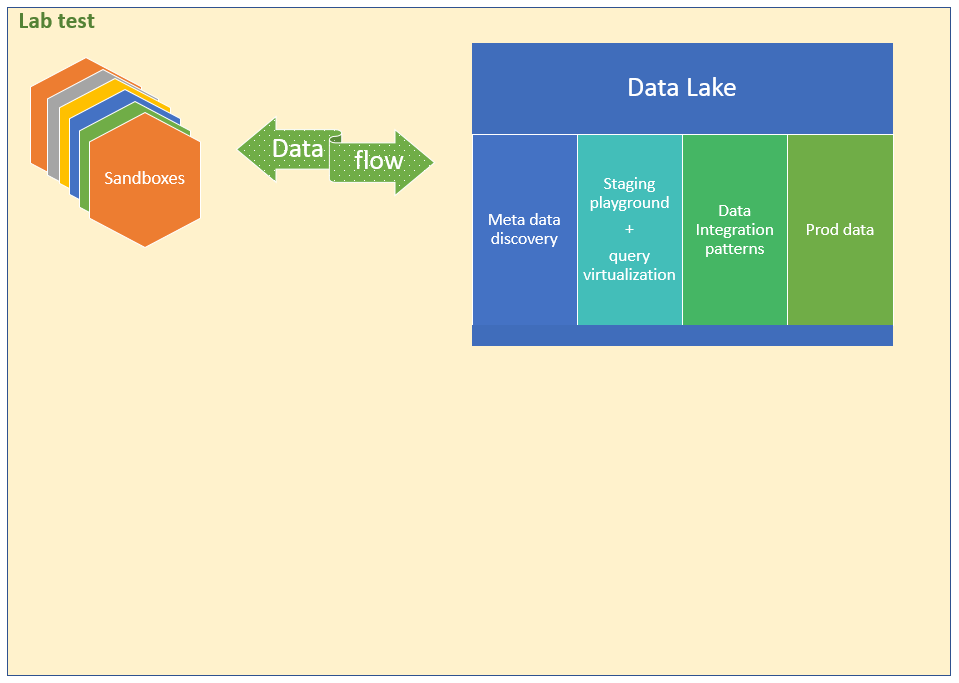
In this case, the curious user gets a small corner of the data lake where they store a bit of EA billing data. They also have the Azure SQL Database which is empty for now.
The curious user is working in the Sandbox environment. They are coding the API App, the Web Job, and the SQL Database. They are iterating through exploring, learning and sharing their work. The sharing is done in a GIT repository, where the user can check in their changes directly from Visual Studio.
Repository
As mentioned earlier, the repo is an essential part of the Cloud Foundation system because it contains the following
- Templates for sandboxes
- Templates for architecture (big part of the architecture follows predictable patterns)
- Source code for work and research that has been done (successful and not so successful, in production or not)
- ML notebooks templates including ML notebooks that are customized for different projects
- Documentation – deployment procedures and app documentation used for reproducible experiments in sandbox environments and for deployment to production
The important part is that the GIT repo is searchable, and the search is available to any curious user to discover items, templates, and ideas; and more importantly, it will eventually prevent them from starting research from “Square one” if this has been worked on before.
Another critical part is the reproducibility and the disaster recovery aspects.
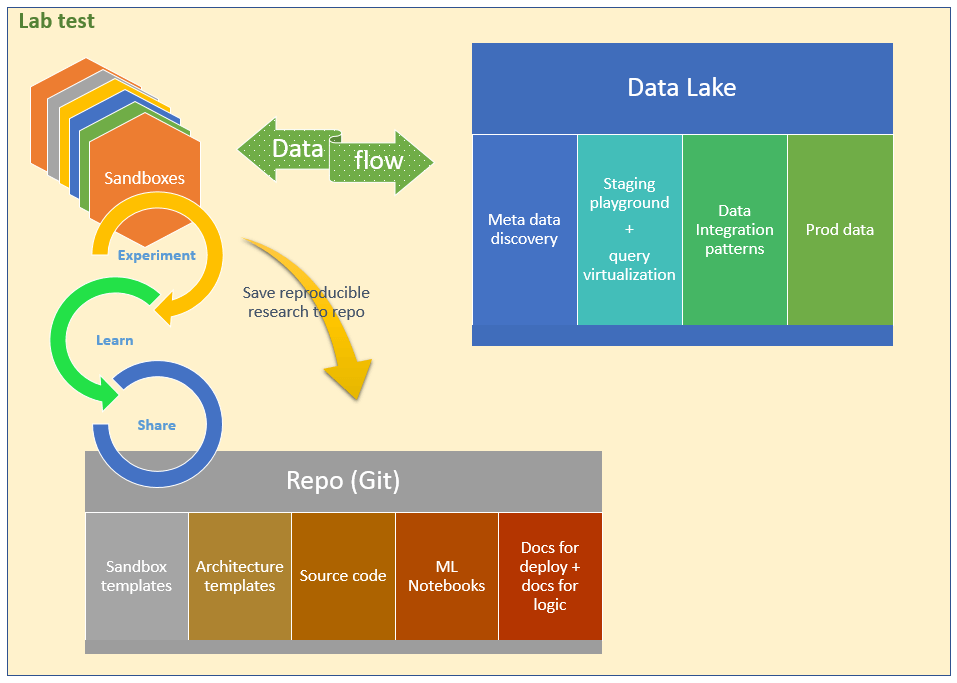
Of course, it is great to Experiment, Learn and Share, but to get real value out of it, the ideas which are turned into code have to be documented and reviewed.
The curious user checks in their solution which contains the Web App, the Web Job and the SQL Database code to GIT, and with it they submit the documentation for the solution and how to deploy it.
Code Review and Test / Prod Deploy from Repo
The Cloud Foundation structure supports a function which enforces peer reviews on the team or organizational unit levels. Also, there are guidelines which enforce certain best-practice rules.
For example, there are several architectures which would support the EA Billing solution, for example, it can use HDInsight clusters, Event Hubs or even a Cosmos DB database. All of the above approaches would solve the business demand, however, there is a big difference in complexity and price tag. The first tier of protection would be the peer review. The second tier would be the best-practice guidelines of the Cloud Foundation platform.
In other words, if a curious user comes with a cost center and wants to play around with a very expensive Cosmos DB database, they can do that. However, a solution like this will be reviewed before taking it to production, and some strategic questions need to be answered before clearing the path to the production environment.
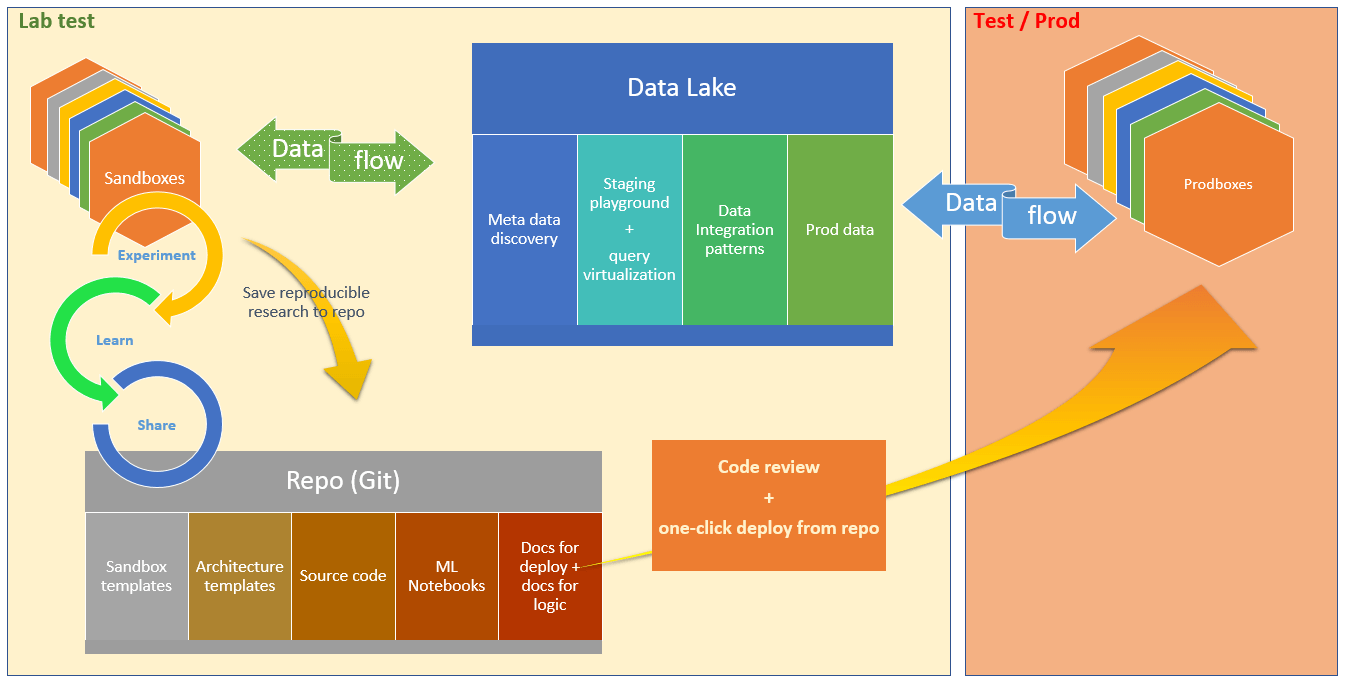
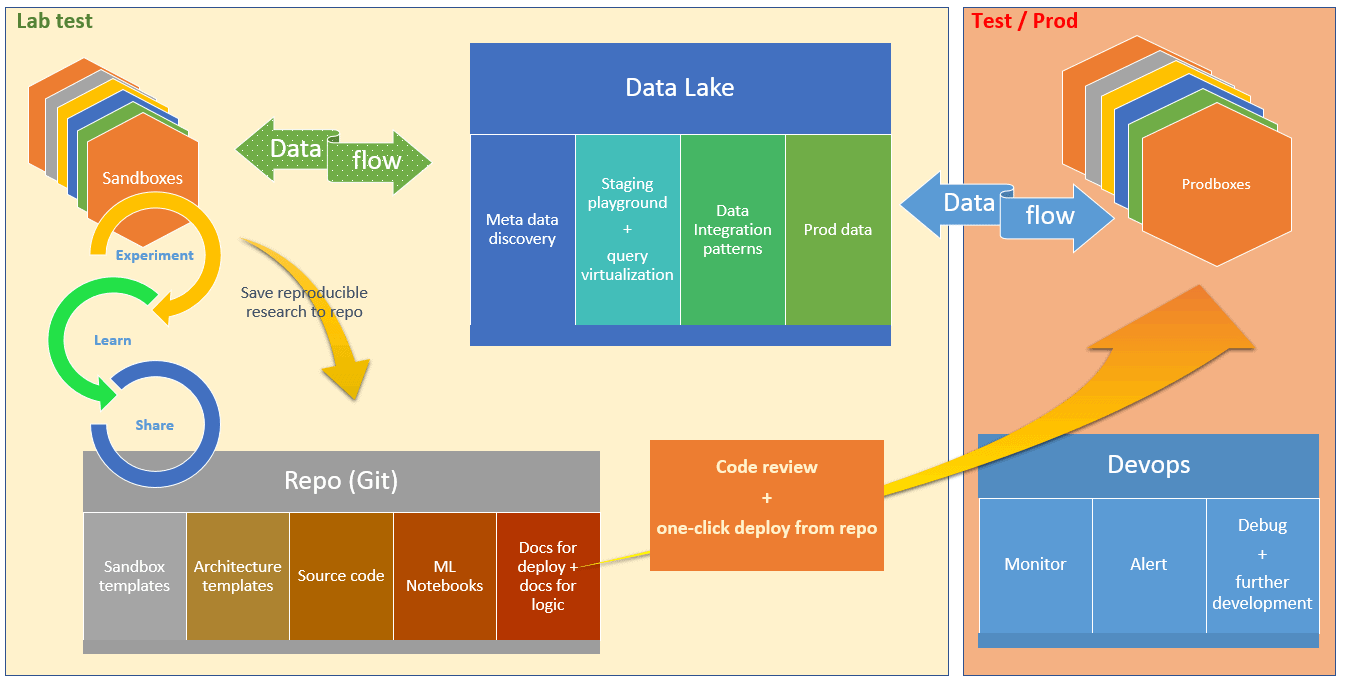
As you can see, the deployment to production is quite easy, since all templates and code are checked in to the GIT repository. Also, the deployment documentation is checked in together with the configuration details.
Then the DevOps team takes the deployment to the test environment from there.
DevOps – Take Over the Monitoring and Alerting
Finally, when the DevOps team has deployed to Test and Production environments, it is time to monitor the solution and to alert the responsible team in case of failure. There are also questions about debugging and further development of the solution, however, these can be answered for each app and for each organization based on their needs and processes.
Closing the Loop
I am closing the loop with another curious user who is looking for a report on the subset of the EA billing data and finds this project.
Another curious user comes with a question about what resources are created in which Cloud regions. The user searches via the Cloud Foundation portal, and they find the metadata which contains information about resources and regions. They also find the EA Billing project, its documentation and the people who have worked on it. This way, instead of developing the entire app from scratch, the user contacts the developer, they exchange some knowledge and it turns out that the solution is simply to create a new Power BI report dashboard which visualizes the count and type of resources per region.
Finally, the whole picture of how curiosity is enabled to prosper and to deliver results within an organization is in place. And all of this is done in a collaborative manner, via experimentation, learning and sharing.
Conclusion
In this article, I explored the need and the benefits of a collaborative analytical platform. Such a platform is fundamental for speeding up the data analysis and the conversion of data into knowledge. More importantly, anyone in an organization should be able to find previous research, improve it and share it. A lot of time is saved this way by not “reinventing the wheel” and by speeding up the path from curiosity to production.
The post Building a Collaborative Platform to Speed up Data Analysis appeared first on Simple Talk.
from Simple Talk https://ift.tt/2Pkk8dW
via
No comments:
Post a Comment