GDPR regulation came into full force on May 25th, 2018. That date represents the end of a two-year ‘running in’ period. It was, if you like, the end of the beginning.
Naturally, most of the attention has fallen on databases, as the area of highest risk for data at rest, but is this necessarily true? The corporate file servers and the file shares that reside on them can contain an immense amount of data in many non-database formats. In this article, I am going to describe at how you can uncover sensitive and personal data buried in network file shares and assess the level of risk this poses to your organisation, using tools such as Apache Tika, Bash and PowerShell.
What Is the Problem with File Shares?
Consider some of the facilities that an RDBMS gives us that a file share does not:
-
A focal point of where data resides
-
A structure optimized for that data
-
Enforcement of that structure
-
Relative clarity of what that structure represents
-
The means to capture documentation of that structure through tools such as Redgate SQL Doc
-
A simple means of interrogating the contents and structure of the database through the SQL language
The mindset that goes with administration and development of an RDBMS lends itself to data categorisation, and to structures that support such activity.
A file share gives us none of those things. It is akin to having a large garage or attic into which to stuff things that might be useful one day but will probably never be used. How many of us have said to a colleague “I know that I have it in a file somewhere, but I can’t quite find it right now?” This is why I believe that many businesses need someone with skills similar to those of a librarian, whose job it is to build data catalogs that include file shares as a data source.
Quantifying the Risk Posed by File Shares
To quantify the risk, we must find answers to the following questions:
-
What types of file do we have?
-
Where do they reside?
-
Are those files still in use or is there a legal obligation to keep them?
-
Who is currently responsible for those files?
-
Do they contain GDPR sensitive data?
Expect to find a substantial number of old files for which there is no known use and no current owner. There may even be no easy way to open those files, due to their obsolescence. GDPR represents a rare opportunity for digital decluttering.
In some cases, I can answer the risk questions posed above with an acceptable degree of accuracy. In others, I can only give a warning that further, more detailed, investigation needs to take place. For example, if I discover a zip file or a password protected file, then I can acknowledge its existence but further investigation, beyond my scope of operation, would be needed.
Preparation Before Investigation
If I must assess all corporate file shares for sensitive data, then the nature of the task means that both I, and my workstation, present a potential security risk. The approach taken to mitigate such a risk could be:
-
The creation of a specific virtual workstation for the task
-
Minimize software on the virtual workstation. No internet access, no email, etc.
-
The creation of a specific login for me to use to access the workstation and to carry out that work
-
Enhanced auditing of the workstation and my login
-
Strict timeboxing of the work.
The toolkit for my virtual workstation was primarily Bash and Powershell, to identify and locate the files, and Apache Tika to look inside those that may contain sensitive or personal data.
Bash and PowerShell?
I use both shells because each one has unique strengths:
-
PowerShell is useful when interacting with objects
-
Bash is useful when handling text streams
Limiting use to one shell risks a solution that succumbs to the tyranny of “or,” rather than the genius of “and.” However, I did find some difficulties with a PowerShell-only solution. For example, it does not have a suitable Sort command for the contents of a text file. Community modules exist, though I found them somewhat clunky. I also found that some PowerShell commands did not accept data piped through to them, requiring me to adjust the process to write an intermediate file. Given the size of the task, I was reluctant to do this. Therefore, I use Windows subsystem for Linux so I can use the shell that is appropriate to the task at hand.
On my workstation, the Linux subsystem lists drives mapped under Windows within the Linux /mnt folder. The C:\ drive will be /mnt/c. The Linux subsystem can use Windows file shares directly, without the need to map those shares to a Windows drive first, but I like being able to capitalize on the strengths of both Windows and Linux, so the mapped drive technique meets my needs, and the technique for doing this is described in the example below. On my PC, I have a share, called \\DadsPCJune2014\Chapter05, which contains files from one of Ivor Horton’s “Beginning Java” books. Within the Linux subsystem, I create a folder that used to access that share.
sudo mkdir -p /mnt/java_tutorial/chapter05
The Linux mkdir command is very close to the Windows equivalent. The -p option ensures that all folders in the path are created if they do not exist already. The Windows share can now be attached to that directory as follows:
sudo mount -t drvfs '\\DadsPCJune2014\Chapter05' /media/java_tutorial/chapter05/ # Try a directory listing # -l = a line per file # -h = include human readable file size ls /media/java_tutorial/chapter05 -hl
What File Types Do We Have?
I worked by mapping the network shares to an explicit drive letter on my secure virtual workstation. Using PowerShell, I can count the files by their extension, most frequent first:
# Powershell
Get-Childitem c:\ -Recurse | where { -not $_.PSIsContainer } | group Extension -NoElement | sort count -desc > c:\users\gdpr_dave\count_by_extension.txt
I can perform a similar task using Bash, retrieving the extensions in alphabetic order:
find . -type f|awk -F "/" '{print tolower($NF)}'|grep -F .|sed -n 's/..*\.//p'|sort|uniq -c > $HOME/extension_count.txt
Bash is a little harder, so here’s a brief description of what the above command does:
-
Find all files below the current location
-
Use
awkto split the file name and path by the / folder separator and output the last part (the file) in lower case -
Filter out anything that does not contain a “.” as this indicates the presence of an extension
-
Replace anything before the “.”
-
Sort the results
-
Provide a unique count
The intention is to exclude any files without an extension, such as the multiple small files generated by git.
We can import the resulting files into Excel and cross-reference the entries to https://en.wikipedia.org/wiki/List_of_filename_extensions. By combining the two information sources, we can add a column to indicate whether a particular file type could contain GDPR sensitive data.
How Old Are My Files?
The Windows operating system presents us with three file dates, but these present some challenges when assessing the age of the file.
|
Date |
Description |
|
Created |
The date that the file was created at its current location. If I copy a file to a target folder today, then the date and time I performed the copy will be the creation date |
|
Modified |
The date that the file was created, or last modified. If I copy the file to another location, then the modified date is retained giving the appearance that a file was modified before it was created. |
|
Last Accessed |
By default, this is the same as the Modified date and not the true date and time the file was last accessed. We can switch on the last access tracking, but it is next to useless if the Windows GUI is used as the act of examining the property results in the property being set to the current date/time. |
In short, the file dates available through the Windows operating system are flawed, so we have to consider both the created and modified dates, separately.
For the purpose of evaluating file shares, I mapped a share to a drive letter and used two PowerShell modules to find the oldest and youngest file, in each folder within the share.
Get-OldestYoungestItemInfolder.ps1
The module shown below produces tab-delimited output which we can pipe into a file for import into SQL Server using bcp, BULK INSERT or appropriate ETL tool.
The code evaluates the file creation date. If we wanted to use the file modified date, then we would change CreationTime to LastWriteTime.
[cmdletbinding()]
param([string]$Foldername='.',[string]$DesiredDate='CreationTime')
$file_eariest_date = [DateTime]::MaxValue
$file_latest_date = [DateTime]::MinValue
$earliest_file_name=""
$latest_file_name=""
$number_of_files = Get-ChildItem -Path $Foldername -File -Force|Measure-Object|%{$_.Count}
$items = Get-ChildItem -Path $Foldername -File -Force|sort $DesiredDate|Select -First 1 -Last 1
$file_eariest_date = $items[0].$DesiredDate
$file_latest_date = $items[$items.Count -1].$DesiredDate
$earliest_file_name = $items[0].Name
$latest_file_name = $items[$items.Count -1].Name
Write-Output "$FolderName't$($number_of_files)'t$('{0:yyyy-MM-dd}' -f $file_eariest_date)'t$('{0:yyyy-MM-dd}' -f $file_latest_date)'t$($earliest_file_name)'t$($latest_file_name)"
Get-OldestYoungestItemRecursive.ps1
Our second module recurses down through the folder structure, calling our first module for each folder.
[cmdletbinding()]
param([string]$Foldername='.',[string]$DesiredDate='CreationTime')
Get-ChildItem -Path $Foldername -Directory -Recurse|Where-Object{$_.GetFiles().Count -gt 0}|ForEach-Object{Get-OldestYoungestItemInFolder.ps1 $($_.FullName)}
Let us suppose that we mapped a file share to the M:\ drive then we might pipe output to a file as follows:
Get-OldestYoungestItemRecursive.ps1 M:\ CreationTime >C:\Users\gdpr_auditor\Share_CreationTime.txt Get-OldestYoungestItemRecursive.ps1 M:\ LastWriteTime >C:\Users\gdpr_dave\Share_LastWriteTime.txt
Even these simple lists of folders and dates can reveal opportunities to remove obsolete information.
Where Are My Files?
We know what files we have, and the oldest and youngest file, in any folder. For file types that are likely to hold sensitive data, we must identify where they are held.
For any folder, we want to traverse down through all its subfolders listing those that contain a file with the desired extension. The Get-FileTypeLocation.ps1 PowerShell module below achieves this:
[cmdletbinding()]
param([string]$Foldername='.',[string]$FileExtensionPattern='xls')
Get-ChildItem $Foldername -Recurse -Include *.$FileExtensionPattern|Sort-Object DirectoryName|%{Write-Output $_.DirectoryName}|Get-Unique -AsString
Given the wide usage of Microsoft Excel across the enterprise, I chose .xls as the default file extension value for which to search. If I pass xl* then I gain a list of directories for XLS, XLM, XLSX, XLSM files, as well.
Using the ‘file share mapped to a drive’ example from earlier in this article, I can pipe the results of my PowerShell module to files:
Get-fileTypeLocation m:\ xl* >C:\Users\gdpr_dave\Share_ExcelLocation.txt Get-fileTypeLocation m:\ acc* >C:\Users\gdpr_dave\Share_AccessLocation.txt Get-fileTypeLocation m:\ mdb >C:\Users\gdpr_dave\Share_OldAccessLocation.txt Get-fileTypeLocation m:\ mde >C:\Users\gdpr_dave\Share_OldAccess2Location.txt
By importing each of these files into SQL Server as separate tables and joining on the folder name, we can get a reasonable approximation of when a folder was last active for file creation or modification, and what types of files are present in those folders.
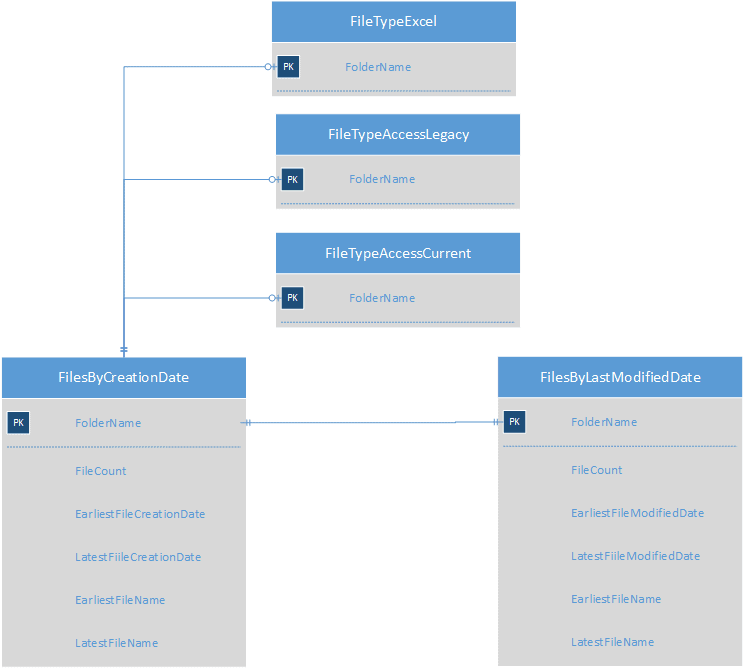
Which Files Pose a GDPR Risk?
I need to know if my files contain personal names, email addresses, and other sensitive information. Apache Tika provides the mechanism by which we can look inside files, without needing to have the original application used to create those files.
Apache Tika’s origins are as part of Apache Nutch and Apache Lucene, which are a web crawler and index. For such programs to be most effective, they need to be able to look at the contents of the files and extract the relevant material. In other words, they need:
-
Visible content
-
Metadata – such as the XIFF metadata in JPEG images.
Apache Tika supports over 1,400 file formats, which include the Microsoft Office suite and many more that are likely to contain the sort of data we need to find.
Running Apache Tika
Apache Tika is a Java application. Version 1.18 requires Java 8 or higher. It can behave as a command line application or as an interactive GUI.
I downloaded tika-app-1.18.jar into c:\code\ApacheTika\ on my workstation, and ran the following command, to use Tika as an interactive application.
java -jar c:\code\ApacheTika\tika-app-1.18.jar
This produces a dialogue as shown below.

The file menu allows a file to be selected and the view menu provides different views of that file. Apache Tika can also be run as a command line application.
java -jar c:\code\ApacheTika\tika-app-1.18.jar -t m:\documents\Blessed_Anthem.docx
The -t switch asked for the output in plain text and resulted in the content shown below:
Mae hen wlad fy nhadau yn annwyl i mi Gwlad beirdd a chantorion enwogion o fri Ei gwrol ryfelwr, gwlad garwyr tra mad Tros ryddid collasant eu gwaed. Gwlad Gwlad, Pleidiol wyf i'm gwlad, Tra môr yn fur i'r bur hoff bau O bydded i'r hen iaith barhau
When running as a command line application, Apache Tika offers more facilities than are present in the interactive GUI. For example, the -l switch attempts to identify the language in the file.
java -jar c:\code\ApacheTika\tika-app-1.18.jar -l m:\documents\Blessed_Anthem.docx
This produces cy which is the ISO639-2 language code for Welsh.
Using Apache Tika to Extract Data from Spreadsheets
Let’s suppose that, prior to GDPR, the marketing manager at AdventureWorks had decided to run an email campaign involving all AdventureWorks customers. He or she had exported two tables from AdventureWorks2014 to an Excel spreadsheet, as shown below.
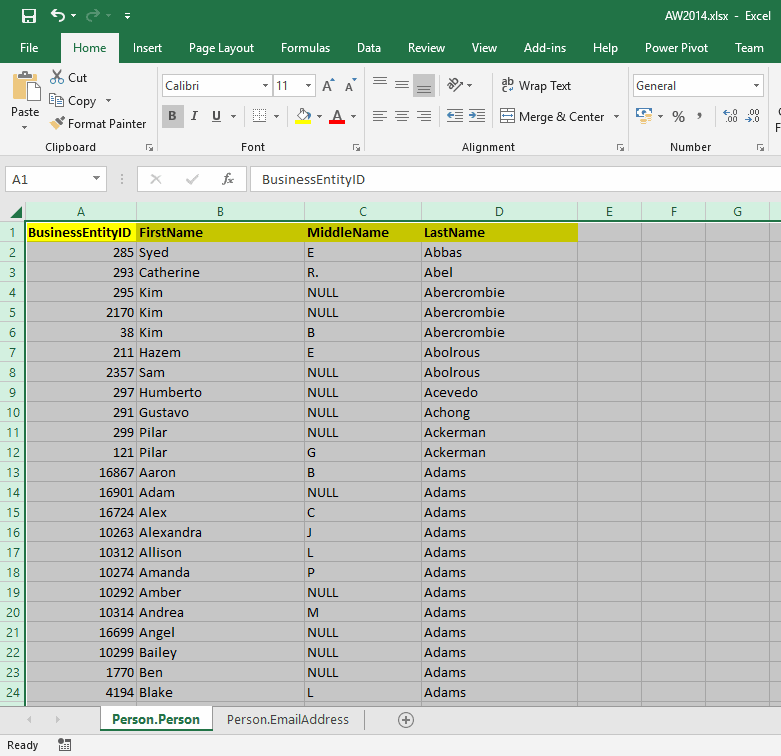
The command below would extract the content of the sample spreadsheet to a file called output.txt.
java -jar tika-app-1.18.jar -t C:\Users\david.poole\Documents\SQLServerCentral\Red-Gate\GDPR\Tika\Email_Campaign2014.xlsx>output.txt
If we were to open that file in Notepad++, we would see something similar to the following:
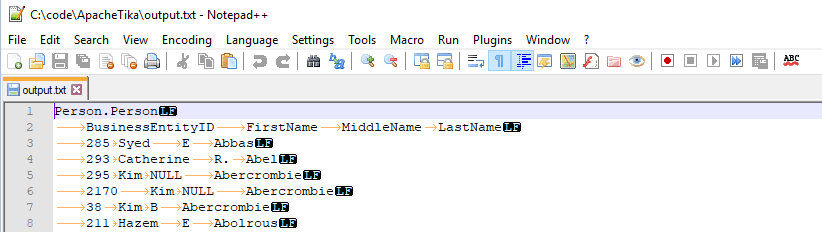
-
The spreadsheet tab names are against the left-hand margin
-
The spreadsheet rows are indented by one TAB
-
The spreadsheet columns are TAB-delimited
-
The spreadsheet rows are terminated by a line-feed, which is the Unix standard
-
Each sheet terminates with two empty rows.
Apache Tika has successfully extracted the contents from the spreadsheet, so our next task is to determine the steps necessary to identify the fact that it contains the names of people.
Acquiring a Dictionary of First Names
As the security and compliance manager for AdventureWorks, the quickest way to determine if a file contains customer names is to match against a dictionary of first names.
The easiest way to acquire that list of first names is by querying the company customer database. For this I create a view:
CREATE VIEW Person.ForeNameExtraction
AS
SELECT UPPER(REPLACE(FirstName, '.', '')) AS ForeName
FROM AdventureWorks2014.Person.Person
WHERE FirstName NOT LIKE '% %'
AND LEN(REPLACE(FirstName, '.', '')) > 3
UNION
SELECT UPPER(REPLACE(MiddleName, '.', '')) AS ForeName
FROM AdventureWorks2014.Person.Person
WHERE MiddleName NOT LIKE '% %'
AND MiddleName IS NOT NULL
AND LEN(REPLACE(MiddleName, '.', '')) > 3;
GO
This produces a distinct list of first names that are at least three characters long and do not contain spaces. Without the size qualification, the risk would be that matching against such a list would produce a huge number of false positives.
I would use the query with the SQL Server bcp utility to produce a file of the results.
bcp "SELECT ForeName FROM Person.ForeNameExtraction ORDER BY ForeName" queryout "c:\code\FirstName.txt" -c -T -r0x0A -SMyDbServer
Note that -r0x0A gives an LF character as the row terminator to match the output used by Apache Tika.
Reformatting Apache Tika Output
To aid the matching process, the output from Apache Tika must be reformatted. Either Bash or PowerShell is adequate for the tasks required, as the output from each stage can be piped into the next.
As Windows 10 now supports Linux, and I work in a multi-platform environment, I prefer Bash.
|
Stage |
Bash |
|---|---|
|
Change all white space to LF |
sed ‘s/\s/\n/g’ |
|
Change output to upper case |
tr ‘[a-z]’ ‘[A-Z]’ |
|
Remove empty lines |
sed ‘/^$/d |
|
Sort output in case-insensitive mode |
sort -f |
When put together, the command line would appear as shown below.
cat output.txt |sed 's/\s/\n/g'|tr '[a-z]' '[A-Z]'|sed '/^$/d'|sort -f >sorted_output.txt
Matching Apache Tika Output to the Dictionary of First Names
Both the Apache Tika sorted_output.txt and our FirstName.txt file share the following characteristics.
-
Output is in upper case
-
Output is sorted in alphabetic sequence
-
Record terminators are an LF character
This allows me to use the bash join command, and then wc to count the number of matches.
join -1 1 -2 1 <(cat FirstName.txt) <(cat sorted_output.txt )|wc -l
However, this did produce an error as well as a count:
join: /dev/fd/63:405: is not sorted: J PHILLIP 23826
The error is due to differences between the character sets, and the way that the database sorts its records. This can be fixed by piping the output for both through the sort utility:
join -1 1 -2 1 <(cat FirstName.txt|sort -f) <(cat sorted_output.txt|sort -f )|wc -l
This produces a count of 23,850, which clearly indicates that a lot of first names have been found.
We can compare this to the of the original number of lines output by Apache Tika, which is 39,952.
cat output.txt |wc -l
I could also count the number of unique name matches against my dictionary:
join -1 1 -2 1 <(cat FirstName.txt|sort -f) <(cat sorted_output.txt|sort -f)|uniq|wc -l
Matching Apache Tika Output to a RegEx Pattern
We can also use the egrep utility to search for text patterns that could be email addresses.
cat sorted_output.txt |egrep "^[A-Za-z0-9]+@[A-Za-z0-9-]+\."|wc -l
If we wanted to search for a pattern matching a UK postal code, then at the point where we converted all white space to new-lines characters, we would have to be explicit in converting just tab characters. This would be to avoid splitting the first and second half of the postal code.
Running the Tika Program
All the steps described so far can be assembled into a simple bash script, CheckFileWithTika.sh, with minor error checking.
#!/bin/bash
export LC_ALL='C' # Forces all programs to output using the default language and use the same bytewise sort
FileToCheck=$1 # It is easier to read code with named arguments
SortedOutputFileName=sorted_output_$(uuidgen).txt # Make a filename unique to this run
if [ $# -eq 0 ]; then
echo -e "\033[31mERROR: NO ARGUMENT SUPPLIED: \033[93mExpected a fully qualified filename\033[0m"
exit
fi
if [ ! -f $FileToCheck ]; then
echo -e "\033[31mERROR File \033[93m$FileToCheck \033[31mdoes not exist\033[0m"
exit
fi
java -jar tika-app-1.18.jar -t $FileToCheck|sed 's/\s/\n/g'|tr '[a-z]' '[A-Z]'|sed '/^$/d'|sort -f >$SortedOutputFileName
fore_name_score=$(join -1 1 -2 1 <(cat FirstName.txt) <(cat $SortedOutputFileName )|wc -l)
email_score=$(cat $SortedOutputFileName |egrep "^[A-Za-z0-9]+@[A-Za-z0-9-]+\."|wc -l)
echo -e "\033[31mFile $FileToCheck matches $fore_name_score fore names and $email_score email addresses\033[0m"
# Clean up after the run.
rm $SortedOutputFileName
The strange syntax in the echo statements controls the colour of the text echoed to the screen. The echo -e ensures that escape sequences in the output text are honoured. Otherwise, they are treated as literals. The \033[31m sets the output text to red. This notation is more widely supported than the \e[31m that is also supported in Ubuntu.
Parallelising the Script Execution
The reason I use the uuidgen utility to give a unique filename for each run of the script is that Linux has one last gift to offer us. If we wanted to run our CheckFileWithTika.sh script for every spreadsheet in a directory, in parallel, then we could use a command similar to the one below.
ls *.xls* | xargs -n1 -P4 -I{} CheckFileWithTika.sh {}
In the example above, the output from the ls command (the Linux equivalent of dir) is piped into xargs:
-
–
n1tellsxargsto use only the first item from each ls output as the argument -
-P4tellsxargswe want to run four sub-processes in parallel -
-I{}tellsxargsthat we want to use{}as a place marker to inject our argument
Challenges with the Apache Tika Approach
The approach described in this article should be regarded as a suitable smoke test, to see if a file might contain GDPR sensitive data. The table below summarizes some of the challenges with this approach:
|
Challenge |
Description |
Mitigation |
|---|---|---|
|
Network bandwidth and IO |
A legacy file share has thousands of folders, millions of files and data volumes measured in terabytes if not exabytes. Scanning such content is extremely expensive in terms of CPU, network and disk utilization |
Limit the scanning of files in a directory to a specific threshold. Once potential GDPR sensitive data has been found up to that threshold note the directory as suspect and move to the next. Consider using dedicated hardware. The Apache Tika process does not need to e ultra-resilient, multi-user or even have particularly high performance. A commodity PC with large local storage may be sufficient. Such a machine will be significantly cheaper than a €20million fine. |
|
Security permissions |
Corporate files shares may have extremely sensitive information on them. Consider HR and Finance department concerns. |
To limit the exposure and escalation of privileges necessary to allow a scan to take place a dedicated machine in a secure location with limited access may be necessary. |
|
Security credentials |
Some files may be protected by passwords |
Apache Tika does have the facility to inject a password in order to read a file. However, this would require a means of matching files to passwords and being able to inject them as part of the process. |
|
ZIP files |
ZIP files contain many files |
The ZIP files can be extracted provided they are not password protected. |
|
Limitations of Apache Tika |
Apache Tika can freeze when processing very large files and in particular those that contain embedded images. |
Both Bash and PowerShell are able to filter files by type and size. The process could be run in an iterative manner for specific types and sizes of files. |
|
Match accuracy |
The match is only as good as the dictionary or pattern we supply |
Consider the approach indicative rather than definitive. |
The post Exhuming the GDPR Bodies appeared first on Simple Talk.
from Simple Talk https://ift.tt/2MjxfdT
via
No comments:
Post a Comment