In older versions of SQL Server (prior to SQL Server 2019, aka 15.x), SQL Server memory grant feedback supported was added, but only for batch mode queries. Queries that use batch mode performing scanning and calculations on up to 900 rows at a time, versus row mode that only processes one row at a time. With the introduction of version 15.x, memory grant feedback has been expanded to support row mode queries as well.
What is memory grant feedback? At a high level, memory grant feedback is the process of tuning the memory grant requirements of a given query based on how much memory was used the last time the query ran. Meaning if a cached query used too much memory the last time it executed, then SQL Server uses the memory grant feedback information to reduce the memory for the next execution of the same query. Or if SQL Server detected a query spilled to disk because not enough memory was allocated the last time, then it increases the amount of memory for the next execution to hopefully eliminate the costly spill to disk operation. The goal of memory grant feedback is to adjust the memory requirements of a cached query each time a query is executed until the query uses the appropriate amount of memory based on the number of rows being processed.
The Memory Grant Feedback features (batch and row mode) are part of the into the Intelligent Query Processing (IQP) feature set. See Figure 1 for a diagram that shows all the IQP features introduced in Azure SQL Database and SQL Server 2019, as well as features that were originally part of the Adaptive Query Processing feature included in the older generation of Azure SQL Database and SQL Server 2017.
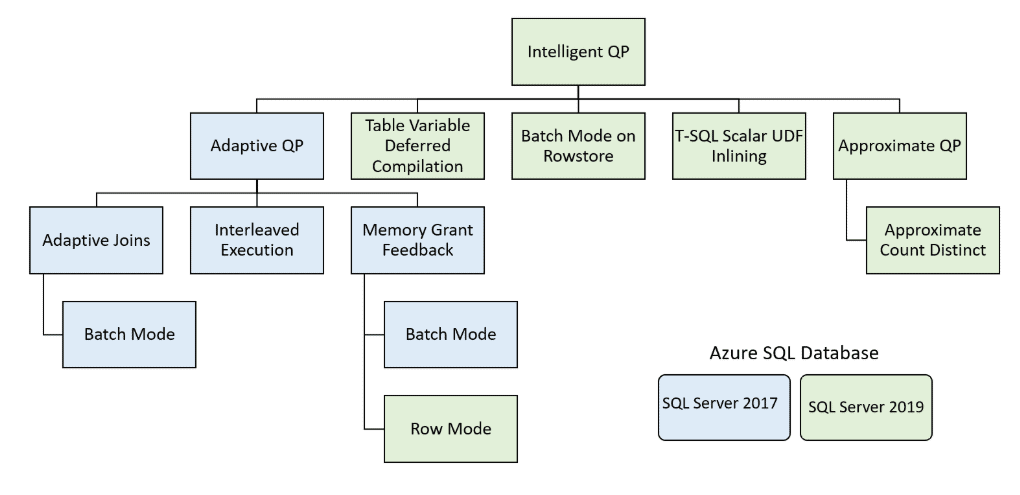
Figure 1: Intelligent Query Processing
To better understand how memory grant feedback works, let me explore the memory grants required for a specific query as it is executed the first time and then is adjusted over time for each subsequent execution.
Exploring How Memory Grants Change Over Time
In order to explore how memory grants change over time, I will execute a given query over and over again. Each time it runs, I will show you how much memory was allocated and used by the query, as well as the additional feedback provided to help the databases engine adjust the memory requirement each time the query runs. To explore how the new version of SQL Server, version 15.x, adjusts memory requirements over time, I will run a query that executes against the WideWorldImporters database which can be downloaded here. The specific query to test the row mode memory grant feedback feature can be found in Listing 1.
Listing 1: Test Query
USE WideWorldImporters; GO SELECT * FROM Sales.Orders ORDER By OrderDate;
Before testing this query, let me review why the memory grant information is incorrect and perform a few setup steps to prepare for testing the new row mode memory grant feedback feature.
Why is the Memory Grant Information Incorrect in the First Place?
There are many factors that make up how much memory a given query requires. The query optimizer needs to consider the memory requirements of each operation of an execution plan when calculating the total amount of memory to grant. Here is a list of some of those things the optimizer considers when calculating the amount of memory to grant to a query:
- Cardinality numbers of tables involved in query
- Column being selected
- Estimated size of each row.
- Will the data read need to be sorted and/or joined
- Does the query go parallel
SQL Server needs to consider all the different aspects of where memory will be needed to successfully process a given query, in order to calculate the amount of memory to grant. If too much memory is granted then SQL Server is wasting memory that could be used for other processes. Or if to little memory is granted then a query will spill to disk, which is an costly operation.
SQL Server doesn’t always do a good job of calculating the amount of memory to grant the first time around. Out of date or inaccurate statistics are the most common reasons why SQL Server calculates the wrong amount of memory to grant. But even when the statistics are correct SQL Server might over or underestimate the amount of memory to grant for some other reason. One of those other reasons is when SQL Server calculates incorrectly calculates the Estimated Row Size for columns being returned. My code used for testing this new memory grant feedback feature will show how an over estimation on row size causes my test query to get an excessive grant warning, due to the three NVARCHAR(MAX) columns I included that are always NULL.
At least now when SQL Server incorrectly calculate the amount of memory to grant, the memory grant feedback feature can be used to improve memory allocation for subsequent runs. Each time a query is executed, the memory usage feedback information from the prior execution is used to determine if the memory allocation needs to be adjusted for the current query. If the memory allocation used the last time around was less than ideal, then the database engine adjusts the memory allocation appropriately for the query.
Setup for Initial Execution of Test Query
To show you how memory allocation is adjusted over time for the test query, I will need to do a few things first. The first requirement is to set the compatibility level of the WideWorldImporters database to 150. I have to do this because the Memory Grant Feedback – Row Mode is only available if the database is running in compatibility level 150. The code in Listing 2 sets the database to compatibility level 150.
Listing 2: Setting Compatibility Level to 150
ALTER DATABASE WideWorldImporters SET COMPATIBILITY_LEVEL = 150; GO
The next thing to do is clear out the procedure cache with the code in Listing 3. I do this so when I run the test query, the engine will create a new cached plan for the test.
Listing 3: Clear the procedure Cache
USE WideWorldImporters; GO ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO
With the environment all set up, I’m ready to perform the initial execution of the test query in Listing 1.
Initial Execution of Test Query
To show the amount of memory that is used by the test query and the feedback that the database engine provides, I will review information from the actual execution plan from each execution of the test query.
When I run the code in Listing 1 the first time, I get the execution plan displayed in Figure 2.
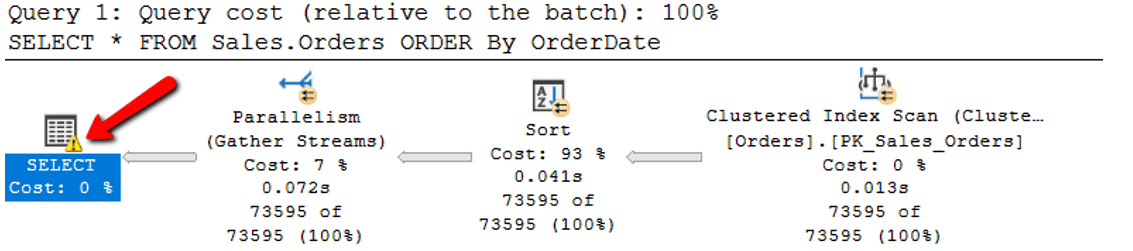
Figure 2: Execution plan for initial execution of Listing 1
As you can see, the SELECT icon shows a warning sign, as pointed to by the red arrow in Figure 2. Hovering over the SELECT icon shows the information in Figure 3.
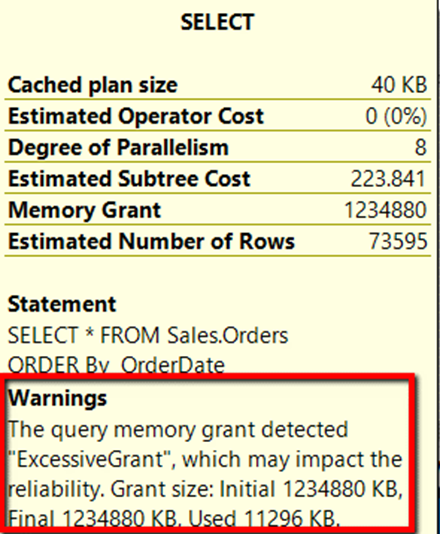
Figure 3: Select properties of first execution.
The SELECT statement information shows an excessive grant warning. The query was granted 1,234,880 KB of memory, but it only used 11,296 KB. This means the query allocated much more memory than what the query needed.
With version 15.x of SQL Server, two new attributes were added to the MemoryGrantInfo section of the SELECT properties of the execution plan. These two new attributes are IsMemoryGrantFeedbackAdjusted and LastRequestedMemory. These two attributes provide the feedback required to adjust memory for the next execution of the query. You can find these two new attributes by viewing the MemoryGrantInfo in the graphical execution plan. To display this information, first hover over the SELECT icon in the execution plan, right-click and then select the Properties option from the menu displayed. These new properties for the query display in the expanded view of the MemoryGrantInfo item, as shown in Figure 4.
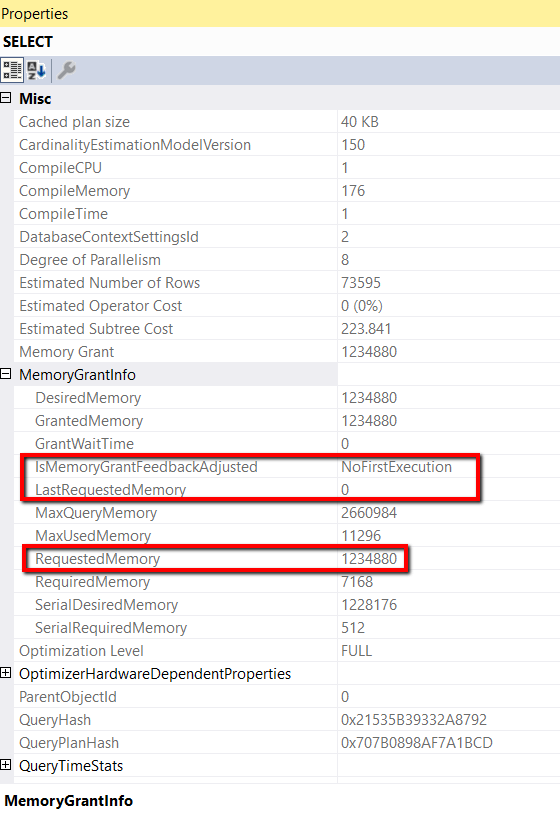
Figure 4: Memory Grant Information
In the initial run of the test query, the IsMemoryGrantFeedbackAdjusted property is set to NoFirstExecution and the LastRequestedMemory property value is set to 0. The RequestedMemory setting has a value of 1234880. This is the amount of memory that was requested when I ran the query the first time. To better understand the new feedback properties, let me explore the values these properties could have.
Understanding the new MemoryGrantInfo Feedback Properties
These two new feedback properties are set each time a query runs. The values set for these feedback properties are based on what the database engine learned during the execution of the query. The feedback information is stored in the cached plan for the next execution of the particular query from the cache. When the next execution is starting, it uses this feedback to determine if the memory should be adjusted.
The IsMemoryGrantFeedbackAdjusted property has 5 different values, which can be found in Table 1.
Table 1: Description of possible IsMemoryGrantFeedbackAdjusted values
|
IsMemoryGrantFeedbackAdjusted Value |
Description |
|
No: FirstExecution |
Memory grant feedback does not adjust memory for the first compile and associated execution. |
|
No: Accurate Grant |
If there is no spill to disk and the statement uses at least 50% of the granted memory, then memory grant feedback is not triggered. |
|
No: Feedback disabled |
If memory grant feedback is continually triggered and fluctuates between memory-increase and memory-decrease operations, we will disable memory grant feedback for the statement. |
|
Yes: Adjusting |
Memory grant feedback has been applied and may be further adjusted for the next execution. |
|
Yes: Stable |
Memory grant feedback has been applied and granted memory is now stable, meaning that what was last granted for the previous execution is what was granted for the current execution. |
By using Table 1, I can verify that when I ran the test query above it was the first time the query had been run from the procedure cache because the value displayed in Figure 4 was NoFirstExeuction.
The LastRequestedMemory property shows the amount of memory requested, in Kilobytes (KB), the last time the query was run. Since I was running the test query for the first time, the value was set to 0.
Let me run the test query a second time to see how the database engine uses these feedback properties to improve the memory allocation for the second execution.
Second Execution of Test Query
After running the test query a second time, the yellow warning sign shown in the first execution has now gone away, as shown in Figure 5.
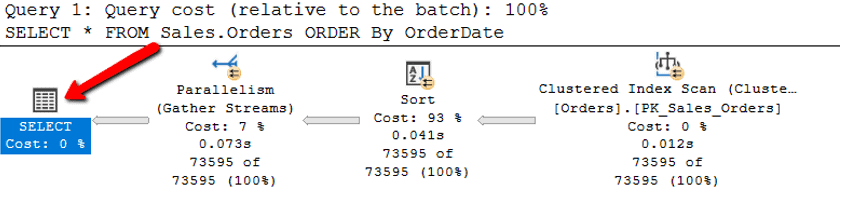
Figure 5: Execution Plan for Second Execution of the test query
The MemoryGrantInfo properties of the SELECT icon for the second execution of the test query shows that some of the feedback property values have changed as well as the amount of RequestedMemory. The MemoryGrantInfo properties from this second execution can be found in Figure 6.
in 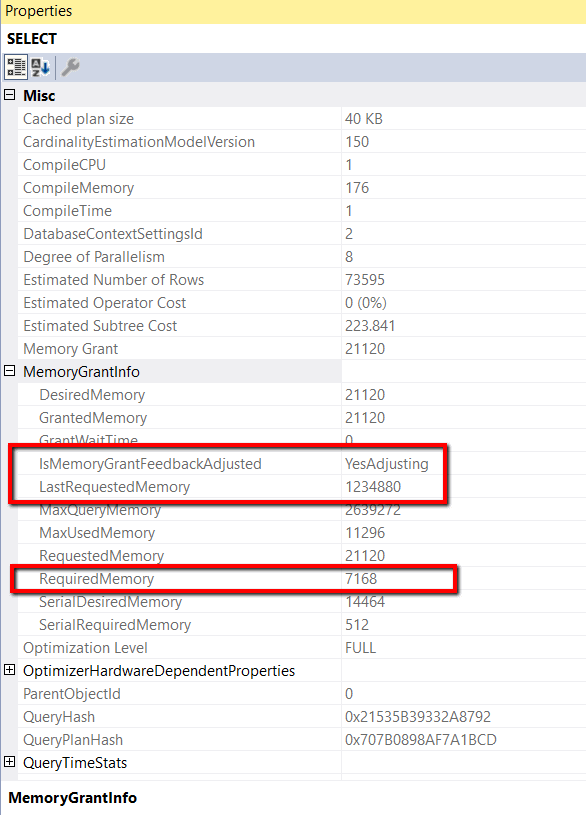
Figure 6: MemoryGrantInfo properties for the second execution
The IsMemoryGrantFeedbackAdjusted property in Figure 6 shows that this property is now set to YesAdjusting. This status means that memory feedback was applied to the second execution of the query. Additionally, the LastRequestedMemory is now set to 1234990, which is the amount of RequestedMemory from the first execution of this query. The RequestedMemory property shows that the second execution of the query requested only 2304 KB of memory. This value is considerably less than the amount of memory requested for the first execution.
Before rerunning the query, I should probably note something I ran into when testing memory grant feedback properties between different runs of the test query. What I found was, that if I waited too long between subsequent query execution, that the execution plan might be evicted from the procedure cache between executions. When this happens, the IsMeoryGrantFeedbackAdjusted property value will be set to NoFirstExecution, which indicates that the subsequent runs were really the first execution since being placed in the procedure cache. Therefore, to see the progression of memory grant feedback working between executions, I had to execute each of subsequent execution fairly quickly after the prior execution to avoid the cached plan eviction problem. By doing this, the test query stays in the procedure cache.
Third Execution of Test Query
After executing the query a third time, the MemoryGrantInfo properties can be found in Figure 7.
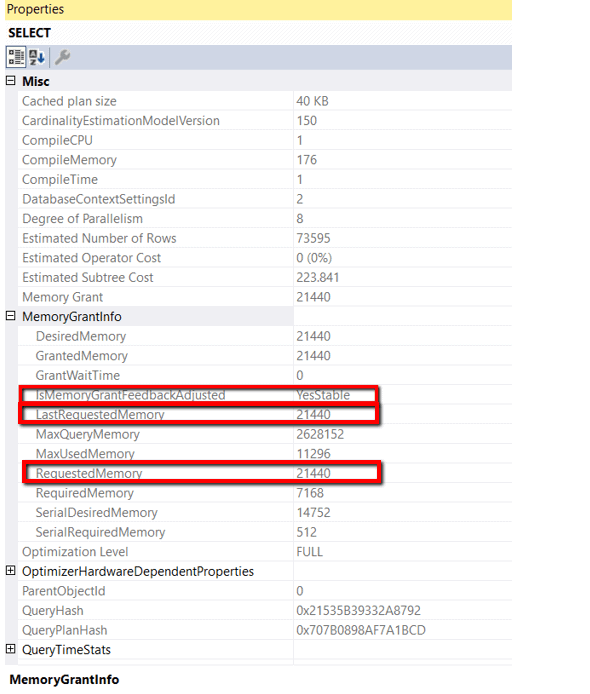
Figure 7: SELECT properties for the third execution of Listing 1
The IsMemoryGrantFeedbackAdjusted now says YesStable. This means the third execution had the same memory allocation as the second execution. I verified this by comparing the LastRequestedMemory and the RequestedMemory values to make sure they are the same. For the test query, the memory grant feedback feature allowed the query to request the appropriate amount of memory after three executions.
When Memory is Not Stable
There are some queries where the memory allocation amounts might never be consistent between executions of the same cached plan. When this occurs, SQL Server gives up trying to adjust memory and disables memory grant feedback for the query. One situation where this occurs is when you have a stored procedure that might have different parameters values passed for each execution.
To show a situation when SQL Server disables memory grant feedback, I will execute a test stored procedure multiple times. For each execution, I will vary a parameter for the stored procedure. By doing this, the query within the procedure will require different amounts of memory for each execution, due to different numbers of records being processed for each of the different parameter values. The code for the test stored procedure can be found in Listing 4.
Listing 4: Test Stored Procedure
USE WideWorldImporters; GO CREATE OR ALTER PROC TestProc (@KeyValue int) AS SELECT * FROM Sales.Orders WHERE OrderID > 1 and OrderID < @KeyValue ORDER By OrderDate
The stored procedure in Listing 4 accepts a parameter named @KeyValue. The code to test the stored procedure can be found in Listing 5.
Listing 5: Code to call Test Stored Procedure
DECLARE @I INT = 1;
DECLARE @TestKeyValue INT;
WHILE @I < 35
BEGIN
IF @I % 2 = 0
EXEC TestProc @KeyValue = 20000;
ELSE
EXEC TestProc @KeyValue = 100;
SET @I = @I + 1;
END
By looking at the code in Listing 5, you can see I will be executing the stored procedure 35 times. For each execution of the test stored procedure, this code alternates the @KeyValue parameter value between the 20000 and 100. When the parameter is set to 20000, the query returns 19,998 rows, but when then parameter value is 100, it returns only 98 rows. As you can guess, each execution requires different amounts of memory, because the number of rows processed is so drastically different for each parameter value.
To test the code in Listing 5, I will execute it from an SSMS query window and will display the actual execution plan. After I executed the code, I reviewed each of the execution plans to determine how the memory grant feedback feature affected the execution plan attributes for each execution. What I found was, from the 2nd execution of the test stored procedure through the 32nd, the IsMemoryGrantFeedbackAdjust property of the SELECT statement had a value of YesAdjusting. Eventually, on the 33rd execution, SQL Server gave up trying to adjust the memory for the test stored procedure and disables memory grant feedback. In Figure 8, you can see the MemoryGrantInfo proprieties for the 33rd execution of the stored procedure.
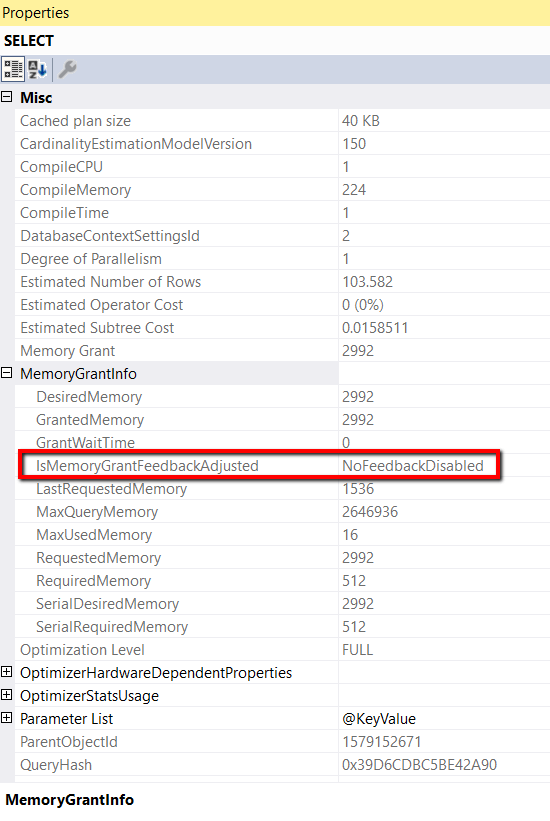
Figure 8: Memory Grant Feedback Disabled on 33rd Execution
As you can see that the IsMemoryGrantFeedbackAdjusted setting is set to NoFeedbackDisabled. This means that the database engine was not able to use the feedback to get a stable memory allocation for the stored procedure, so it decided to disable memory grant feedback for the query. All the subsequent executions of the test stored procedure after the 33rd execution all have memory grant feedback disabled.
Not All Queries Need to use Memory Grant Feedback
Sometimes SQL Server guesses the amount of memory correctly the first time around, so memory grant feedback is not used in subsequent queries. Let me demonstrate this by running the code in Listing 6.
Listing 6: Test Code for Correct Memory Allocation
USE WideWorldImporters; GO SELECT * FROM Sales.Orders WHERE OrderID < 3 ORDER BY OrderDate;
When I run the code in Listing 6, I get the execution plan in Figure 9.
Figure 9: Execution plan when running code in Listing 6
The MemoryGrantInfo properties of the execution plan when running the code in Listing 6 shows that this is the first execution by looking at the IsMemoryGrantFeedback adjusted. Also, the query requested 1024 KB of memory shown by looking at the Requested Memory property. These values can be seen by reviewing Figure 10.
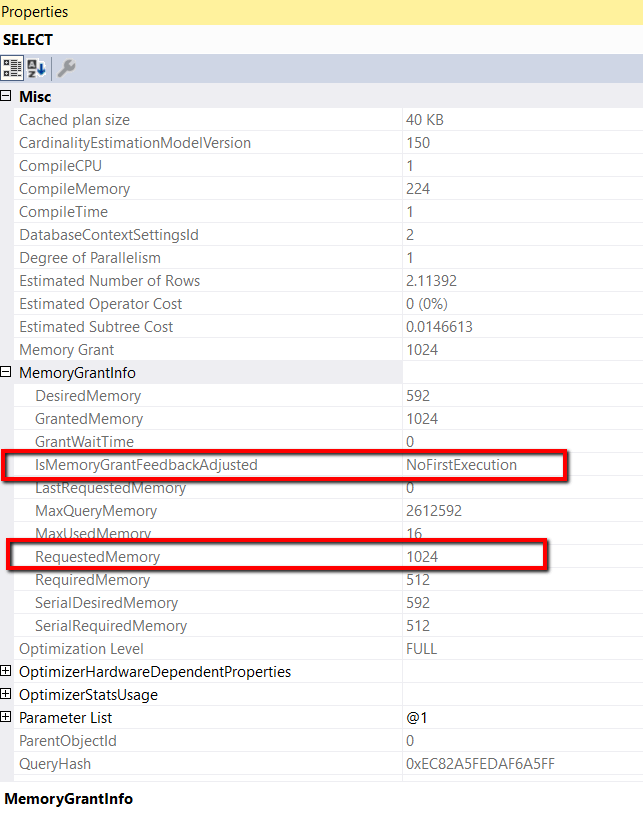
Figure 10: MemoryGrantInfo for the first execution of the query
The memory grant information for the second execution can be seen in Figure 11.
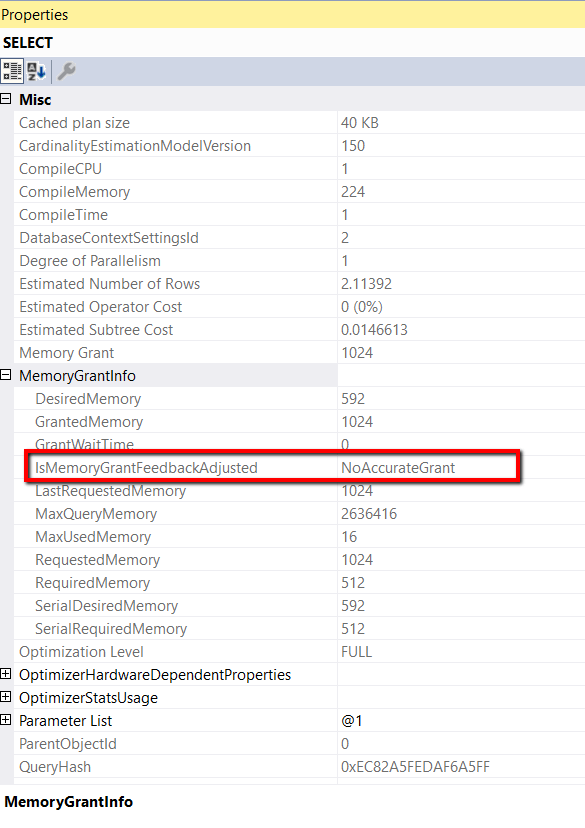
Figure 11: MemoryGrantInfo for the second execution
For the second execution, the IsMemoryGrantFeedbackAdusted is now set to NoAccurateGrant. This status means the second execution didn’t need any more memory, so memory grant feedback was not triggered. This can be verified by noting that the RequestedMemory is the same in Figure 10 and 11.
Turning off Memory Grant Feedback
If for some reason, you would like to turn off memory grant feedback for row mode, there are a couple of ways to do this. The first one is to set the database to a compatibility level of less than 150. The only problem with this is that it also turns off all the other features that come with version 15.x. Alternatively, if you only wanted to turn off memory grant feedback for the WideWorldImporters database, you could set the ROW_MODE_MEMORY_GRANT_FEEDBACK database scoped configuration option to off, by using the script in Listing 7.
Listing 7: Turning off Memory Grant Feedback for a database
USE WideWorldImporters; GO ALTER DATABASE SCOPED CONFIGURATION SET ROW_MODE_MEMORY_GRANT_FEEDBACK = OFF; GO
Listing 7 changes the database configuration to turn off the memory grant feedback feature at the database level. By doing this, no queries will use row mode memory grant feedback when running against the WideWorldImporters database. This is not the only way to disable row mode memory grant feedback. You can also disable memory grant feedback for row mode on a single query by using a query hint, as shown in Listing 8.
Listing 8: Using a Query Hint to Disable Memory Grant Feedback
USE WideWorldImporters;
GO
SELECT * FROM Sales.Orders
ORDER By OrderDate
OPTION
(USE HINT ('DISABLE_ROW_MODE_MEMORY_GRANT_FEEDBACK'));
In Listing 8, the DISABLE_ROW_MODE_MEMORY_GRANT_FEEDBACK query hint disables Memory Grant Feedback for a single query.
Right-Sizing Row Mode Query Memory Requirements
Memory grant feedback for batch mode has been around for a while. But it wasn’t until the rollout of version 15.x that memory grant feedback was available for row mode queries. To enable memory grant feedback for row mode queries, all that is needed is to set a database to run under compatibility level to 150, which of course only works if you are running on the current version of Azure SQL database, or SQL Server 2019. When Row Mode Memory Grant Feedback is enabled, SQL Server uses the memory allocation feedback information for the last execution of a cached query to adjust the memory allocations for the current execution. By adjusting memory, for each execution of a query, using the memory grant feedback feature, a given row mode queries will automatically have their memory allocation right-sized over time.
The post Right-Sizing Row Mode Query Memory Requirements appeared first on Simple Talk.
from Simple Talk https://ift.tt/3cYCnSj
via