Why do you have to go to the live database to see what objects are in it? It is all in the source code, even if it isn’t always easy to find. It is likely to be nicely commented too. This goes particularly for tables and their columns, constraints and indexes. You may not even have a live database of the version you’re interested in checking out; you’ve just got the source code. What do you do then?
Even if you have access to the live server, information about tables isn’t that intuitive to get. Unlike routines, such as procedures and functions, the actual source of a SQL Server table, with its comments and descriptions, isn’t stored in SQL Server. I can’t think of a good reason for this, beyond that fact that a table represents a complex assemblage of objects and properties rather than a single object.
I’ll be describing a way of getting this information. Although one can do much more, the code in this article can be used merely for the useful task of cataloguing the source code. A PowerShell one-liner, specifying the source code of a file or directory, can produce reports like this using sample database source code as input.

Why Get the Documentation into the Database?
You might argue that all you need is the name of the columns and their datatypes, and these are nicely displayed in SSMS. Nope. One of the handiest ways of understanding a routine is to look at its source in the metadata, especially if it has comments and documentation in it. Just a few well-chosen words can save plenty of time for the developers and DBAs maintaining a system.
It is a great advantage to have this documentation in the live database. It is irritating to have to go to and fro between the source code and the live database just to see what a column or constraint is for, or to understand why a table was designed the way it is. It is much easier to have the information with the actual table in a way that can be queried in SQL. With a large database, it is so much easier to find a particular column if you can search not only by name or by datatype but by comment!
If you are so inclined, you can, using the techniques I describe here, store every table script as an extended property attached to the table, but I’ll be describing how you can, using PowerShell, even tease out all the end-of-line comments and block comments from the source and store them as extended properties with their associated column, table, constraint or index.
With all this information in extended properties, you can get lists of tables or columns complete with explanations. I occasionally use code that reverse-engineers a build script complete with the reconstituted comments. Having the information in place makes security checks easier too, such as ‘Are all tables containing personal data encrypted?’.
Documentation in the Wrong Place
It has always been a problem that documentation in the source, where it should be, is not then passed into the live database when the build script is executed. In a table, you have columns, constraints and indexes that you are likely to document using line-ending comments and block comments. You probably have a big block comment at the start, explaining the table. This information should be available in the live database. Microsoft don’t have a good answer and vaguely go on about adding comments in extended properties. Well, that’s fine but it hasn’t happened, unsurprisingly: Have you ever tried to do it? It is an almost impossible task, even with SQL Doc.
My solution is to execute my finely-documented build script as usual to create the latest version of the database, and then process the same script in PowerShell to add all the comments and documentation as extended properties in the right place in the live database.
I use a Microsoft SQL Server parser for .NET to get the documentation, and the script then checks the live database. If the documentation for the table, column, constraint or index isn’t in the database then it puts it there. Any build script generated from the live database will have the script for the documentation included there as extended properties.
Using a PowerShell Parse-TableDDLScript Function
Here in this article I’ll introduce a PowerShell function that does the hard work. Before we get too far into the details, here it is parsing a table. A string containing a table (it could be a database of tables) is passed to the function. It produces an object that describes the table. We convert it to JSON merely to make it easy to display.
$object=Parse-TableDDLScript @"
CREATE TABLE dbo.PurchaseOrderDetail /* this provides the details of the PurchaseOrder */
(
PurchaseOrderID int NOT NULL--the purchase order ID--Primary key.
REFERENCES Purchasing.PurchaseOrderHeader(PurchaseOrderID),-- Foreign key to PurchaseOrderHeader.PurchaseOrderID.
LineNumber smallint NOT NULL,--the line number
ProductID int NULL --Product identification number. Foreign key to Product.ProductID.
REFERENCES Production.Product(ProductID), --another foreign key
UnitPrice money NULL, --Vendor's selling price of a single product.
OrderQty smallint NULL,--Quantity ordered
ReceivedQty float NULL,--Quantity actually received from the vendor.
RejectedQty float NULL, -- Quantity rejected during inspection.
DueDate datetime NULL, --Date the product is expected to be received.
rowguid uniqueidentifier ROWGUIDCOL NOT NULL --the rowguid
CONSTRAINT DF_PurchaseOrderDetail_rowguid DEFAULT (NEWID()),--the named constraibt
ModifiedDate datetime NOT NULL --Date and time the record was last updated.
CONSTRAINT DF_PurchaseOrderDetail_ModifiedDate DEFAULT (GETDATE()),--Default constraint value of GETDATE()
LineTotal AS ((UnitPrice*OrderQty)), --Per product subtotal. Computed as OrderQty * UnitPrice.
StockedQty AS ((ReceivedQty-RejectedQty)), --Quantity accepted into inventory. Computed as ReceivedQty - RejectedQty.
CONSTRAINT PK_PurchaseOrderDetail_PurchaseOrderID_LineNumber --the primary key
PRIMARY KEY CLUSTERED (PurchaseOrderID, LineNumber) --combining PurchaseOrderID and LineNumber
WITH (IGNORE_DUP_KEY = OFF) --with options
)
ON [PRIMARY];
go
"@
$object|ConvertTo-Json -Depth 5
If we look at the jSON, we can see what it makes of the Create script
{
"TableName": "dbo.PurchaseOrderDetail",
"Documentation": " this provides the details of the Individual products and is used together\r\nwith General purchase order information associated with dbo.PurchaseOrderHeaderthat provides specific purchase order. ",
"Columns": [
{
"Name": "PurchaseOrderID",
"Type": "int NOT NULL",
"Documentation": "the purchase order ID--Primary key."
},
{
"Name": "LineNumber",
"Type": "smallint NOT NULL",
"Documentation": "the line number"
},
{
"Name": "ProductID",
"Type": "int NULL",
"Documentation": "Product identification number. Foreign key to Product.ProductID."
},
{
"Name": "UnitPrice",
"Type": "money NULL",
"Documentation": "Vendor's selling price of a single product."
},
{
"Name": "OrderQty",
"Type": "smallint NULL",
"Documentation": "Quantity ordered"
},
{
"Name": "ReceivedQty",
"Type": "float NULL",
"Documentation": "Quantity actually received from the vendor."
},
{
"Name": "RejectedQty",
"Type": "float NULL",
"Documentation": " Quantity rejected during inspection."
},
{
"Name": "DueDate",
"Type": "datetime NULL",
"Documentation": "Date the product is expected to be received."
},
{
"Name": "rowguid",
"Type": "uniqueidentifierRowguidCol NOT NULL",
"Documentation": "the rowguid"
},
{
"Name": "ModifiedDate",
"Type": "datetime NOT NULL",
"Documentation": "Date and time the record was last updated."
},
{
"Name": "LineTotal",
"Type": " computed",
"Documentation": "Per product subtotal. Computed as OrderQty * UnitPrice."
},
{
"Name": "StockedQty",
"Type": " computed",
"Documentation": "Quantity accepted into inventory. Computed as ReceivedQty - RejectedQty."
}
],
"Constraints": [
{
"Name": "*FK1",
"Type": "Foreign key (anonymous) for PurchaseOrderID",
"Documentation": " Foreign key to PurchaseOrderHeader.PurchaseOrderID."
},
{
"Name": "*FK2",
"Type": "Foreign key (anonymous) for ProductID",
"Documentation": "another foreign key"
},
{
"Name": "*D3",
"Type": "Default (anonymous) for DueDateDefault ",
"Documentation": "default duedate to today's date"
},
{
"Name": "DF_PurchaseOrderDetail_rowguid",
"Type": "Default ",
"Documentation": "the named constraibt"
},
{
"Name": "DF_PurchaseOrderDetail_ModifiedDate",
"Type": "Default ",
"Documentation": "Default constraint value of GETDATE()"
}
],
"Indexes": []
}
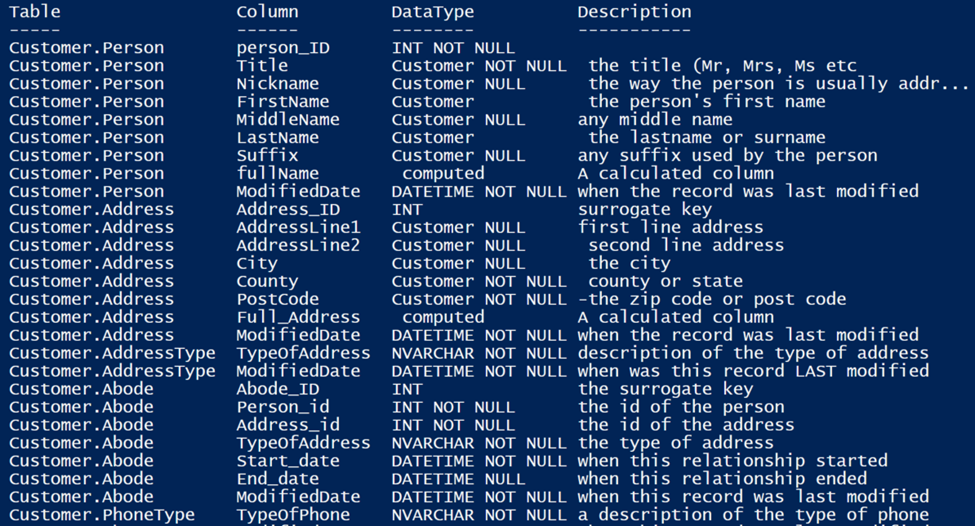
But you’d want to process an entire table build script to find out what’s in it. Here is the script I used to get the list of tables I displayed earlier (you need to put the correct path in the filespec), and you can get the file I used from GitHub.
$content = [System.IO.File]::ReadAllText('<path to>\Customers Database Documented.sql')
(Parse-TableDDLScript $content).GetEnumerator()|
Select @{label="Table";expression={$_.TableName}},
@{label="Description";expression={$_.Documentation}}|
Format-Table
And, of course I ought to include the one that listed the columns. The content variable is re-used from the previous snippet.
(Parse-TableDDLScript $content).GetEnumerator()|
Select @{label="column";expression={$_.columns}},
@{label="Table";expression={$_.TableName}} -PipelineVariable table|
Foreach{$_.column} |# foreach {$table}|convertTo-json
Select @{label="Table";expression={$table.Table}},
@{label="Column";expression={$_.Name}},
@{label="DataType";expression={$_.Type}},
@{label="Description";expression={$_.Documentation}}|Format-Table
The Parse-TableDDLScript
Here is the PowerShell script. It uses a State Machine, because the script is working on the streamed output from a parser. The meaning of any token extracted from the code in sequence depends on what preceded it. Occasionally, it has more than one possible meaning dependent on what follows it. All this can be managed naturally in a state machine, even though the code looks unsettlingly different. Never mind, because you just execute it rather than look at it. (If you have trouble importing the sqlserver module, check here for more information.)
import-module sqlserver -Global
function Parse-TableDDLScript
{
param
(
$Sql # the string containing one or more SQL Server tables
)
<#
This uses the Microsoft parser to iterate through the tokens and construct enough details of
the table to get the various components such as columns, constraints and inline indexes, along
with the comments and documentation
#>
$msms = 'Microsoft.SqlServer.Management.SqlParser'
$Assembly = [System.Reflection.Assembly]::LoadWithPartialName("$msms")
$psr = "$msms.Parser"
$ParseOptions = New-Object "$psr.ParseOptions"
$ParseOptions.BatchSeparator = 'GO'
$anonymous=1 #the number of anonymous constraints
$FirstScript = [Microsoft.SqlServer.Management.SqlParser.Parser.Parser]::Parse(
$SQL, $ParseOptions)
$State = 'StartOfExpression' #this is the current state
$TableDetails = @{ TableName = $null; Documentation = $null;
Columns = @(); Constraints = @(); Indexes = @() }
$AllTablesDetails = @() #the returned list of tableDetails found in the script
$ListItemType = 'unknown' # we start y not knowing what sort of object is in the create staement
$LineCommentRegex = [regex] '(?im)--(.*)\r' # to clean up an end-of-line comment
$MultiLineCommentRegex = [regex] '(?ism)/\*(.*)\*/' # to clean up a block comment
$ListItemDetails = @{ } #the details of the current column found if any
$ExpressionLevel = 0 #used to work out whether you are in an expression
$FirstScript.script.tokens | select Text, Id, Type | foreach {
# if this works out, we've found the first create statement
if ($_.Type -eq ';') { $State = 'StartOfExpression' }
Write-Verbose "State:'$state', Type:'$($_.Type)', Expressionlevel:'$ExpressionLevel' ListItemType:'$ListItemType'"
if ($_.Type -eq 'TOKEN_CREATE')
{
#If the state is 'initialBlock, it is expecting a create statement
if ($state -eq 'initialBlock')
{ $blockComment = $TableDetails.Documentation }; #because it is cleared out
$state = 'CreateStatement' # change state
}
# now we need to keep tabs of the expression level based on the nesting of the brackets
if ($_.Type -eq '(') { $ExpressionLevel++ } #to deal with bracketed expressions- start of expression
if ($_.Type -eq ')')
{
$ExpressionLevel--;
if ($ExpressionLevel -eq 0)
{
# end of the table script so save anything and initialise.
# deal with the problem of having several CREATE statements in a batch
if (($state -ne 'CreateStatement') -or ($_.Type -eq 'LEX_BATCH_SEPERATOR'))
{ $State = 'StartOfExpression'; }
# here we reset the state, expression level and ListItem type
$ExpressionLevel = 0;
$ListItemType = 'unknown';
if ($TableDetails.TableName -ne $null) #then there is something there
{
Write-Verbose "storing table $($TableDetails.TableName)";
$AllTablesDetails += $TableDetails;
}
write-verbose "$state zapping table details"
$TableDetails = @{ TableName = $null; Documentation = $null;
Columns = @(); Indexes = @(); Constraints = @() }
$blockcomment = $null;
} #save any existing table
} #to deal with bracketed expressions- end of expression
#is it the start of a list?
if (($_.Type -eq '(') -and ($ExpressionLevel -eq 1)) { $ListItemType = 'unknown' }
# if we definitely have a CREATE TABLE so...
if ($state -notin ('CreateStatement', 'StartOfExpression'))
{
# Do we need to save any current object and then reinitialise?
# to keep this operation in one place we have some complicated condition tests here
if (($_.Type -eq ',' -and $ExpressionLevel -eq 1 #if it is the start of a new list item
) -or ($_.Type -in @('LEX_BATCH_SEPERATOR',
'TOKEN_INDEX',
'TOKEN_CONSTRAINT') #change in object being defined
) -or ($_.Type -eq ')' -and $expressionLevel -eq 0
# or it is one of the anonymous constraints such as a default constraint or a foreign key constraint
) -or (($ListItemType -ne 'Constraint') -and
($_.Type -in @('TOKEN_FOREIGN','TOKEN_DEFAULT','TOKEN_REFERENCES'))))
{ #we've found a new component of the table
# we have to make sure that we've got the current line saved
$State = 'startOfLine'; #OK. This is the start of a list item of the create statement
#we save the details of the previous list item
if ($ListItemDetails.Name -ne $null) # if it exists, save it
{
if ($ListItemType -eq 'column')
{
# if we are needing to save the column whose details we collected ...
$TableDetails.columns += $ListItemDetails;
Write-Verbose "column found $($ListItemDetails.Name) $($ListItemDetails.Documentation)";
}
if ($ListItemType -eq 'constraint')
{
# if we are needing to save the constraint whose details we assembled ...
$TableDetails.constraints += $ListItemDetails;
Write-Verbose "constraint found and added to $($TableDetails.constraints | convertto-json)";
}
if ($ListItemType -eq 'index')
{
# if we are needing to save the index whose details we gathered ...
$TableDetails.Indexes += $ListItemDetails;
Write-Verbose "Index found $($ListItemDetails.Name) $($ListItemDetails.Documentation)";
} # so now we try to work out what sort if list item we have
if ($_.Type -in @('TOKEN_CONSTRAINT', 'TOKEN_FOREIGN'))
{ $ListItemType = 'constraint' }
elseif ($_.Type -eq 'TOKEN_INDEX') { $ListItemType = 'index' }
elseif ($_.Type -eq 'TOKEN_REFERENCES')
{
$ListItemType = 'constraint'
$State = 'Identifier';
$ListItemDetails =
@{ Name = '*FK'+($anonymous++);
Documentation = $null ;
Type = 'Foreign key (anonymous) for '+$ListItemdetails.Name };
}
elseif ($_.Type -eq 'TOKEN_DEFAULT')
{
$ListItemType = 'constraint'
$State = 'Identifier';
$ListItemDetails =
@{ Name = '*D'+($anonymous++);
Documentation = $null;
Type = 'Default (anonymous) for '+$ListItemdetails.Name };
} else { $ListItemType = 'unknown' }
}
}
} #end of list item (column or table constraint or index)
if ($State -eq 'CreateStatement')
#we are looking for the first token which will be a table name.
#If no table name, the expression must be ignored.
{
if ($_.Type -eq 'TOKEN_TABLE')
{ $state = 'WhatNameIsTable'; $ListItemType = 'table' }
#the table can be in several different consecutive tokens following this
};
if ($State -eq 'identifier') # it could be adding the NOT NULL constraint
{if ($_.Type -eq 'TOKEN_NOT') {$ListItemDetails.Type+=' NOT'}
if ($_.Type -eq 'TOKEN_NULL') {$ListItemDetails.Type+=' NULL'}
}
# we may want to remember the actual data type of a column. This token follows a column name
if (($State -eq 'GetDataType') -and ($_.Type -eq 'TOKEN_ID') -and $ExpressionLevel -eq 1)
{ $ListItemDetails.Type = $_.Text; $State = 'identifier' }
#we need to react according to the type of list item/line being written
if (($State -eq 'startOfLine'))
{
if (($_.Type -eq 'TOKEN_WITH') -and ($ExpressionLevel -eq 0)) #
{ $State = 'with' } # a TableOption expression is coming
if (($_.Type -eq 'TOKEN_ON') -and ($ExpressionLevel -eq 0)) #
{ $State = 'on' } # a TableOption expression is coming
if ($_.Type -eq 'TOKEN_ID')
{
if ($ListItemType -eq 'unknown') { $ListItemType = 'column' };
$ListItemDetails = @{ Name = $_.Text; Documentation = $null; Type = '' };
$State = 'GetDataType';
};
};
#now save the tokens that tell us about the type of the object
if ($_.Type -eq 'TOKEN_CLUSTERED') { $ListItemDetails.type += 'Clustered ' }
if ($_.Type -eq 'TOKEN_NONCLUSTERED') { $ListItemDetails.type += 'NonClustered ' }
if ($_.Type -eq 'TOKEN_UNIQUE') { $ListItemDetails.type += 'Unique ' } # Token_on
if ($_.Type -eq 'TOKEN_PRIMARY') { $ListItemDetails.type += 'Primary ' } # Token_on
if ($_.Type -eq 'TOKEN_ROWGUIDCOL') { $ListItemDetails.type += 'RowguidCol ' }
if ($_.Type -eq 'TOKEN_DEFAULT') { $ListItemDetails.type += 'Default ' }
if ($_.Type -eq 'TOKEN_AS') { $ListItemDetails.type += ' computed' }
if ($_.Type -eq 'TOKEN_s_CTW_DATA_COMPRESSION') { $tableDetails.type += 'Data-compression ' }
# if we his a batch separator (eg Go) then we save the current table if there is one
if ($_.Type -in @('LEX_BATCH_SEPERATOR'))
{
#gone to expressionLevel
$State = 'StartOfExpression'
};
# store any comments with the current object
if ($State -in @('startOfLine', 'Identifier', 'GetDataType'))
{
if ($_.Type -eq 'LEX_END_OF_LINE_COMMENT')
{
# one has to strip out the delimiters in both cases
$ListItemDetails.Documentation += $LineCommentRegex.Replace($_.Text, '${1}');
}
if ($_.Type -eq 'LEX_MULTILINE_COMMENT')
{
$ListItemDetails.Documentation += $MultiLineCommentRegex.Replace($_.Text, '${1}');
}
}
if ($State -eq 'WhatNameIsTable') # we are trying to find out the name of the table
{
if ($_.Type -in @('TOKEN_ID', '.'))
{
$TableDetails.TableName += $_.Text;
Write-Verbose "Table name found $($TableDetails.TableName)";
}
if ($_.Type -eq '(' -and $ExpressionLevel -eq 1) { $State = 'startOfLine' };
};
if ($_.Type -eq 'LEX_MULTILINE_COMMENT')
# deal with multiline comments that can be associated with a table
{
$blockComment = $MultiLineCommentRegex.Replace($_.Text, '${1}')
if (($ListItemType -in ('table')) -or
($state -in @('StartOfExpression', 'initialBlock')))
{ $TableDetails.Documentation += $blockComment; $blockComment = $null }
Write-Verbose "Found block comment $($_.Text) "
if ($state -eq 'StartOfExpression') { $state = 'InitialBlock' }
}
}
# now we add the table to the list of tables
if ($TableDetails.TableName -ne $null)
{
$AllTablesDetails += $TableDetails;
$TableDetails = @{ TableName = $null; Documentation = $null;
Columns = @(); indexes = @(); constraints = @() }
}
Write-Verbose "found $($AllTablesDetails.count) tables"
$AllTablesDetails
}
The current version of this code is contained in the GitHub project here
A state machine will read a series of inputs. When it reads an input that belongs to a particular set of values associated with that state, it will switch to a different state. Each state specifies which state to switch to, for a given input. This means that you have a script where complexity can be limited to a single place and the script is very easy to amend. It is curious that, as you better-understand and develop the algorithm, one can pull code out, and the code shrinks.
The parsing routine ends up with an object that represents a set of tables. Basically, you just want the name and type of the property or object so you can use the information. I suspect there are other uses for it, but I couldn’t resist getting datatypes for columns.
If the code finds something that isn’t a table script, it skids through it naturally, because it never finds that ‘table’ token. Hopefully, it recovers to the correct state to proceed on to the next statement to see if it is a Table script. (Hopefully because I haven’t yet tested it with every possible CREATE statement).
The output of the function is a list of table objects, or maybe just one. Each object consists of its name, the type, and any comment blocks or end-of-line comments.
Each object has three lists. The columns, the constraints and the inline indexes. These all contain the name, the type and the comment. It is a PowerShell object but you can easily convert this to JSON, YAML or XML for export. With a bit of tweaking you can convert it to CSV, save it to disk and put it in Excel or whatever you wish.
Merging the Documentation to a Database.
It is very easy to pass an object like the one produced by this PowerShell Script to a procedure. This procedure can be used to update the extended properties of the table, column, constraint or index. I use temporary procedures because I don’t like adding utility procedures in databases. We start with the code for the procedure. Sadly, it uses JSON so it will only work with versions of SQL Server that have this implemented.
CREATE OR alter PROCEDURE #AddDocumentation
@JSON NVARCHAR(MAX), @changed INT output
/**
Summary: >
This procedure takes a JSON document created by
the PowerShell SQL Table Parser and either updates
or creates the documentation in Extended properties
in the database.
It checks that all the columns and constraints
are there as specified in the JSON file to ensure
that you are sending documentation to the right
version of the database
Author: Phil Factor
Date: 03/04/2020
Examples:
- DECLARE @numberChanged int
EXECUTE #AddDocumentation @json, @numberChanged OUTPUT
SELECT @NumberChanged
Returns: >
The number of updates or insertions of documention done
**/
AS
BEGIN
/* this table contains the parameters required for the Extended properties
stored procedures, and some columns used merely for expanding the JSON */
CREATE TABLE #EPParentObjects
(
TheOneToDo INT IDENTITY(1, 1),
level0_type VARCHAR(128) NULL,
level0_Name sysname NULL,
level1_type VARCHAR(128) NULL,
level1_Name sysname NULL,
level2_type VARCHAR(128) NULL,
level2_Name sysname NULL,
[Description] NVARCHAR(3750) NULL,
[columns] NVARCHAR(MAX) NULL,
[indexes] NVARCHAR(MAX) NULL,
constraints NVARCHAR(MAX) NULL
);
-- insert the tables into the #EPParentObjects table with their details
--the details are saved as JSON documents, lists of columns, indexes or constraints.
INSERT INTO #EPParentObjects
(level0_type, level0_Name, level1_type, level1_Name, level2_type,
level2_Name, [Description], [columns], [indexes], constraints)
SELECT 'schema' AS level0_type, Coalesce(ParseName(Name, 2),'DBO') AS level0_Name,
'Table' AS level1_type , ParseName(Name, 1) AS level1_Name,
NULL AS Level2_type,NULL AS Level2_name,
[Description],[columns],[indexes],constraints
FROM OpenJson(@JSON)
WITH
(
Name SYSNAME '$.TableName',
Description NVARCHAR(3876) '$.Documentation',
[columns] NVARCHAR(MAX) '$.Columns' AS JSON,
[indexes] NVARCHAR(MAX) '$.Indexes' AS JSON,
[constraints] NVARCHAR(MAX) '$.Constraints' AS JSON
) AS BaseObjects;
-- Now we simply cross-apply the contents of the table with the OpenJSON function
-- for every list (columns,indexes and constraints). By using a UNION, we can do
-- it all in one statement
INSERT INTO #EPParentObjects
(level0_type, level0_Name, level1_type, level1_Name, level2_type,
level2_Name, Description)
SELECT level0_type, level0_Name, level1_type, level1_Name,
'Column' AS level2_type, name AS level2_Name, documentation
FROM #EPParentObjects
CROSS APPLY OpenJson([Columns])
WITH
(
Name SYSNAME '$.Name',
documentation NVARCHAR(3876) '$.Documentation'
) WHERE documentation IS NOT null
UNION ALL
SELECT level0_type, level0_Name, level1_type, level1_Name,
'Constraint' AS level2_type, name AS level2_Name, documentation
FROM #EPParentObjects
CROSS APPLY OpenJson([Constraints])
WITH
(
Name SYSNAME '$.Name',
documentation NVARCHAR(3876) '$.Documentation'
) WHERE (documentation IS NOT NULL) AND (level2_name NOT LIKE '*#')
UNION ALL
SELECT level0_type, level0_Name, level1_type, level1_Name,
'Index' AS level2_type, name AS level2_Name, documentation
FROM #EPParentObjects
CROSS APPLY OpenJson([Indexes])
WITH
(
Name SYSNAME '$.Name',
documentation NVARCHAR(3876) '$.Documentation'
) WHERE documentation IS NOT null
/* the next thing to do is to check that all the objects have corresponding objects in
the database. If not, then I raise an error as something is wrong. You could, of course
do something milder such as removing failed lines from the result but I wouldn't advise
it unless you were excpoecting it! */
--first we check the tables
IF EXISTS (SELECT * FROM #EPParentObjects e
LEFT OUTER JOIN sys.tables
ON e.level1_Name=tables.name
AND e.level0_Name=Object_Schema_Name(tables.object_id)
WHERE tables.object_id IS NULL)
RAISERROR('Sorry, but there are one or more tables that aren''t in the DATABASE',16,1)
--now we check the constrints
IF EXISTS (SELECT * FROM #EPParentObjects e
LEFT OUTER JOIN sys.objects o
ON e.level0_Name=Object_Schema_Name(o.parent_object_id)
AND e.level1_Name=Object_Name(o.parent_object_id)
AND e.level2_Name=o.name AND level2_type ='constraint'
WHERE level2_type ='constraint' AND e.level2_Name NOT LIKE '*%' -- not an anonymous constraint
AND o.object_id IS null
) RAISERROR('Sorry, but there are one or more constraints that aren''t in the DATABASE',16,1)
--finally we check the columns.
IF EXISTS (SELECT * FROM #EPParentObjects e
LEFT OUTER JOIN sys.columns c
ON e.level0_Name=Object_Schema_Name(c.object_id)
AND e.level1_Name=Object_Name(c.object_id)
AND e.level2_Name=c.name
where e.level2_name IS NOT NULL AND level2_type ='Column'
and c.column_id IS null
) RAISERROR('Sorry, but there are one or more columns that aren''t in the DATABASE',16,1)
--indexes should be checked in the same way, probably, but these are less frequent.
--we now iterate through all the lines of the table. Notice that I don't delete
--documentation if the corresponding JSON record has a null. I just think that
--it is a bad way of deleting documentation. It is easy to add.
DECLARE @iiMax int= (SELECT Max(TheOneToDo) FROM #EPParentObjects)
DECLARE @level0_type VARCHAR(128), @level0_Name sysname,
@level1_type VARCHAR(128),@level1_Name sysname,
@level2_type VARCHAR(128),@level2_Name sysname,@Description nvarchar (3750),
@NeedsChanging BIT,@DidntExist BIT
DECLARE @ii INT =1
SELECT @Changed =0
WHILE @ii<=@iiMax
BEGIN
SELECT @level0_type =level0_type, @level0_Name=level0_Name,
@level1_type =level1_type,@level1_Name =level1_Name,
@level2_type=level2_type,@level2_Name =level2_Name,@Description=[description]
FROM #EPParentObjects WHERE TheOneToDo=@ii
SELECT @NeedsChanging=CASE WHEN value=@description THEN 0 ELSE 1 end --so what is there existing?
FROM fn_listextendedproperty ('ms_description',
@level0_type,@level0_Name,@level1_type,
@level1_Name,@level2_type,@level2_Name)
IF @@RowCount=0 SELECT @DidntExist=1, @NeedsChanging=CASE WHEN @description IS NULL THEN 0 ELSE 1 END
IF @NeedsChanging =1
BEGIN
SELECT @Changed=@Changed+1
IF @DidntExist=1
EXEC sys.sp_addextendedproperty 'ms_description',@description,
@level0_type,@level0_Name,@level1_type,
@level1_Name,@level2_type,@level2_Name
ELSE
EXEC sys.sp_Updateextendedproperty 'ms_description',@description,
@level0_type,@level0_Name,@level1_type,
@level1_Name,@level2_type,@level2_Name
end
SELECT @ii=@ii+1
END
END
The latest version of this code is included in the Github project here
Putting It All Together
We now have all the components we need to add the documentation from the source code into the live database. As you’ll see in the comments, you need to first install the SqlServer module (it is in the PowerShell Gallery) and make sure you have the Microsoft.SqlServer.Management.SqlParser (it is part of SMO and the sqlserver module). You will, of course, need to provide the path to both the build script and the source for the stored procedure and the connection string properties.
<# we start with the build script, the SqlServer module, the Powershell function, the
Microsoft.SqlServer.Management.SqlParser parser from Microsoft and the source code for
the import temporary #AddDocumentation procedure #>
<#
We need to use the System.Data.SqlClient library because we want to create a
connection where we can first install our temporary stored procedure and then run it.
We need Invoke-Sqlcmd from the SqlServer module for the build script because it has
GO batch terminators. #>
#get the build script
$content = [System.IO.File]::ReadAllText('<myPathToBuildScript>\Customers Database Documented.sql')
# parse it to get the json model of the contents
$JsonResult=(Parse-TableDDLScript $content)|ConvertTo-Json -Depth 5
# now make a connection string (we use a more elaborate approach
# we never put it in a string in a script!
$ConnectionString= "Data Source=MyServer;Initial Catalog=Customers;user id=PhilipJFactor;Password=NotMyRealPassword"
# we execute the build script (you'll need the SQLServer library for this)
Invoke-Sqlcmd -Query $content -ConnectionString $connectionString
#now we use a sqlclient connection
$sqlconn = New-Object System.Data.SqlClient.SqlConnection
$sqlconn.ConnectionString = $ConnectionString
# we now read in the code for the temporary stored procedure
$Procedure = [System.IO.File]::ReadAllText('<myPathToProcedureScript> \AddDocumentation.sql')
#now we make a connection and install the temporary procedure
$cmd = New-Object System.Data.SqlClient.SqlCommand
$cmd.Connection = $sqlconn
$cmd.CommandTimeout = 0
$cmd.CommandText=$Procedure
# Now we execute the build for the temp stored procedure
try
{
$sqlconn.Open()
$cmd.ExecuteNonQuery() | Out-Null
}
catch [Exception]
{
Write-error $_.Exception.Message
}
# now we execute the procedure, passing the JSON as a parameter
$HowManyUpdates=0; #initialise the output variable
$cmd.Parameters.Clear(); # just in case you rerun it absent-mindedly
# add in the JSON as the first input parameter
$sqlParam1 = New-Object System.Data.SqlClient.SqlParameter("@JSON",$JsonResult)
# add in the integer output parameter as the second parameter
$sqlParam2 = New-Object System.Data.SqlClient.SqlParameter("@changed",$HowManyUpdates)
$sqlParam2.Direction = [System.Data.ParameterDirection]'Output';
$cmd.CommandText = "EXEC #AddDocumentation @JSON,@changed"
#Add the parameters
$Null=$cmd.Parameters.Add($sqlParam1)
$Null=$cmd.Parameters.Add($sqlParam2)
try
{
$Updates=$cmd.ExecuteNonQuery()
}
catch [Exception]
{
Write-error $_.Exception.Message
}
finally
{ # the temporary procedure is cleaned out at this point
$sqlconn.Dispose()
$cmd.Dispose()
}
"We updated or created $Updates Extended properties."
(this code is included in the GitHub project together with a sample table script)
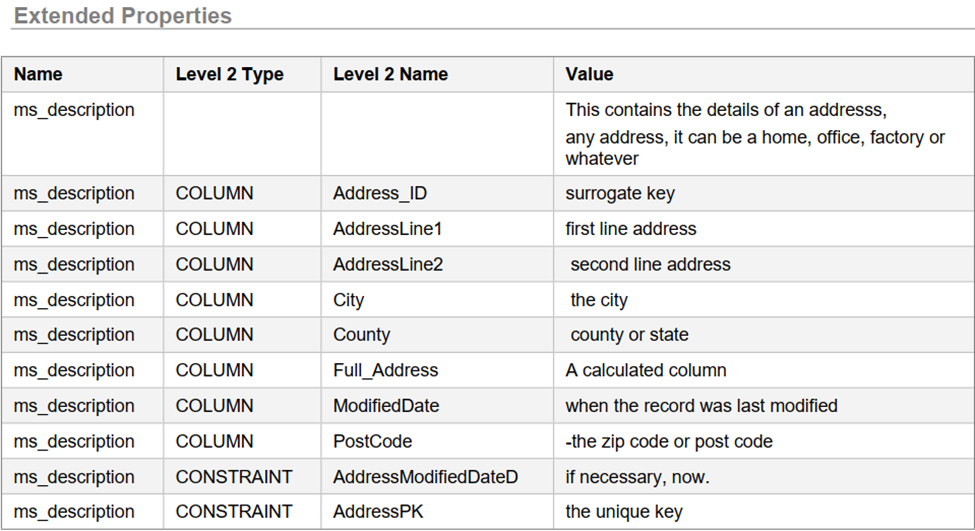
We run this on our test database stable script and lo, the documentation has been added (just an extract from a sample table). This is a screenshot from Redgate’s SQLDoc.
Summary
I’m hoping that, if you’ve got this far in the article, I’ve convinced you that not only should source build scripts be documented but this documentation should be included in the actual built database. Database Documentation needs the light. I’ve provided several ways of using this documentation from extended properties using SQL.
There are, however, many other ways of using the information gleaned by the PowerShell function. You can, for example, create reports and PDF documentation. There are plenty of ways of using this general technique. I use a similar technique to take structured headers for tables or functions and parse them into YAML documents for various team documentation resources. By combining what you can glean from the source, with information you can get from the live database, such as dependencies, you have some very useful information.
The post How to Document SQL Server Tables appeared first on Simple Talk.
from Simple Talk https://ift.tt/2yqt2Uf
via
No comments:
Post a Comment