Views are used to encapsulate common queries for reuse by SQL Server database objects or applications. They also allow for customized permissions to be applied while avoiding granting access to the underlying objects.
While this can be hugely beneficial, views are additional database objects that incur a maintainability cost in addition to the typical cost of upkeep for new code.
When a view’s underlying objects change, the view itself will not change. This can result in a view where the data types of columns, as well as nullability, precision, and scale can be reported inaccurately. When this happens, it is possible for queries against these columns to return errors, truncate data, perform poorly, or otherwise behave in unexpected ways.
This article will delve into views, how they are defined, and how T-SQL can be used to programmatically test the validity of views and ensure they never become stale.
How Can Views Become Stale?
To demonstrate how a view can fall out-of-sync with the tables it references, we will introduce a view and step through the process of altering data types underneath it.
Consider the view HumanResources.vEmployeeDepartment, which can be found in the AdventureWorks sample database:
CREATE VIEW [HumanResources].[vEmployeeDepartment]
AS
SELECT
e.[BusinessEntityID]
,p.[Title]
,p.[FirstName]
,p.[MiddleName]
,p.[LastName]
,p.[Suffix]
,e.[JobTitle]
,d.[Name] AS [Department]
,d.[GroupName]
,edh.[StartDate]
FROM [HumanResources].[Employee] e
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = e.[BusinessEntityID]
INNER JOIN [HumanResources].[EmployeeDepartmentHistory] edh
ON e.[BusinessEntityID] = edh.[BusinessEntityID]
INNER JOIN [HumanResources].[Department] d
ON edh.[DepartmentID] = d.[DepartmentID]
WHERE edh.EndDate IS NULL
The view contains ten columns that are selected from four tables. The data types for each of these columns are defined based on the underlying source columns. For example, the Suffix column in Person.Person is NVARCHAR(10); therefore, the Suffix column in vEmplloyeeDepartment will also be NVARCHAR(10). The data types of view columns can be quickly checked via SQL Server Management Studio by expanding Views within the database:
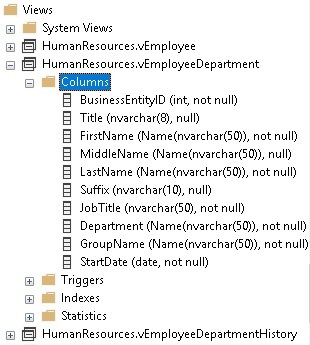
Let’s consider an upcoming software release that lengthens the Suffix column from 10 to 15 characters to accommodate new entries from within an application. Lengthening columns is a common change that helps an app adjust to changing business requirements as its data needs evolve over time. The change can be made with the following T-SQL:
ALTER TABLE Person.Person ALTER COLUMN Suffix NVARCHAR(15) NULL;
This change can be confirmed via the table definition:
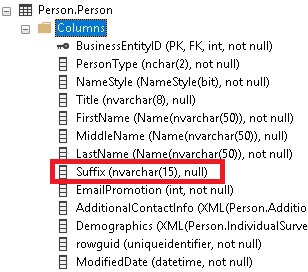
If we return to the view definition, though, we’ll note that the column definition there has not changed:
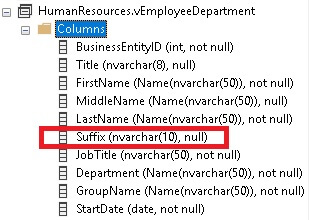
The discrepancy is not a UI glitch. No amount of refreshing the table or reopening the database server will change the length of the column. This functionality is intentional, and views are designed not to update when referenced objects change. The security, performance, and data ramifications of cascading data type changes would be far more consequential than the current state of affairs in which no updates occur.
Anyone that looks at the view definition will observe a length of 10, whereas the Person table reports a length of 15. This discrepancy can result in a variety of problems that are not likely to manifest themselves immediately, such as:
- Confusion and disruption to application development as the data type definitions documented by these two sources conflict with each other.
- ORMs or data analytics tools may report the wrong column length and throw errors or behave erratically.
- Unexpected behavior by SQL Server when processing misreported columns.
Note that the actual observed behavior will vary depending on the details of a view’s definition, the table’s definition, and how they are queried. Arguably, uncertainty is worse in code than a known and well-documented bug, and, therefore, we should not rely on unexpected behavior to diagnose view-related inconsistencies.
Since a software release does not always immediately precede corresponding data changes, it is possible that weeks or months could pass before a user enters data greater than 10 characters into this column. Our ability to keep track of views and update them diligently is therefore important while a release is fresh in our minds.
Updating View Metadata
The solution to stale views is the built-in stored procedure sp_refreshview. When called, this stored procedure will regenerate the metadata for a given view based on all of its underlying objects. The syntax is straightforward and consists of one parameter: the name of the view.
Using this view, we can update the metadata for vEmployeeDepartment:
EXEC sp_refreshview @viewname = 'Humanresources.vEmployeeDepartment';
After executing, let’s return to the view definition, refresh it, and check the data type for the Suffix column:
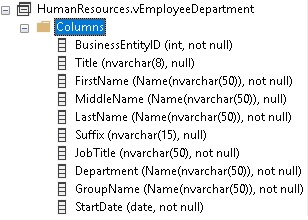
After executing sp_refreshview, the view now reports the Suffix column as NVARCHAR(15), rather than its previous length of 10. Success!
What About Schema binding?
There is another option that allows views to stay in sync with their underlying objects: schema binding. When a view is created with schema binding, its definition is bound to the underlying objects. This prevents all changes to referenced objects while the schema bound view exists.
Schema binding protects a view from unintended changes to any objects it references. To illustrate this, let’s create a new view in AdventureWorks:
CREATE VIEW v_employee_test
WITH SCHEMABINDING
AS
SELECT
Employee.BusinessEntityID,
Employee.NationalIDNumber,
Person.FirstName,
Person.MiddleName,
Person.LastName,
Person.Suffix
FROM HumanResources.Employee
INNER JOIN Person.Person
ON Person.BusinessEntityID = Employee.BusinessEntityID
WHERE Person.Suffix IS NOT NULL;
This view selects a handful of columns from two tables. Note the use of the WITH SCHEMABINDING clause on the CREATE VIEW statement.
Consider a scenario where a developer was to attempt to adjust the length of the Suffix column back to 10:
ALTER TABLE Person.Person ALTER COLUMN Suffix NVARCHAR(20) NULL;
Unlike earlier when the ALTER TABLE command was allowed, this attempt to change the column length will be met with an error message:

Schema binding enforces the underlying database objects and will prevent changes to any of them. This is intentional and forces developers to address the view itself before making changes. The two most common solutions to manage changes to underlying objects are:
- Drop the view, change the tables it depends upon, recreate the view with schema binding.
- Alter the view to remove schema binding, change the tables it depends upon, and alter the view again to add schema binding to it.
The first option is problematic as dropping the view will remove its ability to serve an application. If an app needs the view, then dropping it will result in an outage. The second option has more steps but allows for the view to remain in place while objects are altered. The following script illustrates applying this method to our previous column change:
ALTER VIEW v_employee_test
AS
SELECT
Employee.BusinessEntityID,
Employee.NationalIDNumber,
Person.FirstName,
Person.MiddleName,
Person.LastName,
Person.Suffix
FROM HumanResources.Employee
INNER JOIN Person.Person
ON Person.BusinessEntityID = Employee.BusinessEntityID
WHERE Person.Suffix IS NOT NULL;
GO
ALTER TABLE Person.Person ALTER COLUMN Suffix NVARCHAR(20) NULL;
GO
ALTER VIEW v_employee_test
WITH SCHEMABINDING
AS
SELECT
Employee.BusinessEntityID,
Employee.NationalIDNumber,
Person.FirstName,
Person.MiddleName,
Person.LastName,
Person.Suffix
FROM HumanResources.Employee
INNER JOIN Person.Person
ON Person.BusinessEntityID = Employee.BusinessEntityID
WHERE Person.Suffix IS NOT NULL;
GO
This script succeeds in altering the column to a length of 20 by removing schema binding, altering the column length, and then adding schema binding back to the view. The view remains present for the entire operation, ensuring that anything that relies on it will continue to function.
Schema binding is heavy-handed, but an effective solution for managing the tables that views rely on and ensuring that changes cannot slip through the cracks unnoticed. It forces developers to consider dependencies anywhere they exist, prior to changes being made.
Many organizations will not use schema binding for this exact reason, in any case. If a database has many views in it, then schema binding will force developers to alter views frequently throughout the scripting process. This can bloat release scripts and by increasing the volume of release code also increase the risk of things going wrong.
The remainder of this article deals with databases where schema binding is not used for all views.
Solving the Problem Permanently
For most databases, schema binding will not be universally used. As a result, it will be possible to change objects without being forced to also address the views as part of those changes.
Tackling this challenge requires building a solution that can check view metadata before and after a release and determine if underlying objects have changed in ways that could invalidate their dependent views.
Setup
Running this test requires a development environment where we can make changes freely without worries about breaking an app. To do this, we would need a database backup or, if data is large, a copy of a database’s schema (with empty tables) to work against. Data is not needed for this validation, so feel free to leave it behind.
Validation Steps
The goal is to take a snapshot of all views in the database and compare that against what those views would look like after they are all refreshed. To do this, let’s create a pair of temporary tables that will store these snapshots:
CREATE TABLE #view_metadata_before
( view_metadata_before_id INT NOT NULL
IDENTITY(1,1) PRIMARY KEY clustered,
view_object_id INT NOT NULL,
view_schema_name SYSNAME NOT NULL,
view_name SYSNAME NOT NULL,
column_name SYSNAME NOT NULL,
column_id INT NOT NULL,
user_type_id INT NOT NULL,
user_type_name SYSNAME NOT NULL,
column_max_length SMALLINT NOT NULL,
column_precision TINYINT NOT NULL,
column_scale TINYINT NOT NULL,
is_column_nullable BIT NOT NULL,
is_schemabound_view BIT NOT NULL);
CREATE TABLE #view_metadata_after
( view_metadata_after_id INT NOT NULL
IDENTITY(1,1) PRIMARY KEY CLUSTERED,
view_object_id INT NOT NULL,
view_schema_name SYSNAME NOT NULL,
view_name SYSNAME NOT NULL,
column_name SYSNAME NOT NULL,
column_id INT NOT NULL,
user_type_id INT NOT NULL,
user_type_name SYSNAME NOT NULL,
column_max_length SMALLINT NOT NULL,
column_precision TINYINT NOT NULL,
column_scale TINYINT NOT NULL,
is_column_nullable BIT NOT NULL,
is_schemabound_view BIT NOT NULL);
With some holding places defined, we can populate #view_metadata_before with the current state of affairs in the database:
INSERT INTO #view_metadata_before
(view_object_id, view_schema_name, view_name, column_name,
column_id, user_type_id, user_type_name, column_max_length,
column_precision, column_scale, is_column_nullable,
is_schemabound_view)
SELECT
views.object_id AS view_object_id,
schemas.name AS view_schema_name,
views.name AS view_name,
columns.name AS column_name,
columns.column_id,
types.user_type_id,
types.name AS user_type_name,
CASE WHEN types.name IN ('nchar', 'nvarchar') THEN
columns.max_length / 2 ELSE columns.max_length END
AS column_max_length,
columns.precision AS column_precision,
columns.scale AS column_scale,
columns.is_nullable,
OBJECTPROPERTY(views.object_id, 'IsSchemaBound')
AS is_schemabound_view
FROM sys.views
INNER JOIN sys.columns
ON columns.object_id = views.object_id
INNER JOIN sys.types
ON types.user_type_id = columns.user_type_id
INNER JOIN sys.schemas
ON schemas.schema_id = views.schema_id
ORDER BY views.object_id, columns.column_id;
The result of this is a row per column within each view and some metadata describing the nature of each column:

Note the CASE statement that checks the data type and halves the column length when a double-byte data type is present. This is not necessary, but helps the results match up better with what a user might see in SQL Server Management Studio.
The results are not an exhaustive list of column attributes. There are other pieces of metadata stored in sys.columns that could potentially affect how that column operates. These views contain the most commonly used attributes that will actually impact views. If a database environment has unique circumstances, then adjusting these tables to add more metadata is relatively straightforward.
With a baseline defined, we now need to refresh all views. If a view’s underlying objects have changed, then its metadata will also update accordingly. Updating all views requires a distinct list of views, which we can quickly collect from the list we generated above:
CREATE TABLE #distinct_view_list
(distinct_view_list_id INT NOT NULL
IDENTITY(1,1) PRIMARY KEY CLUSTERED,
view_schema_name SYSNAME NOT NULL,
view_name SYSNAME NOT NULL);
INSERT INTO #distinct_view_list
(view_schema_name, view_name)
SELECT DISTINCT
view_metadata_before.view_schema_name,
view_metadata_before.view_name
FROM #view_metadata_before view_metadata_before
WHERE view_metadata_before.is_schemabound_view = 0;
This script takes the columns list and distills it into a list of views. Schemabound views are filtered out as they will not impact our testing. Since they cannot have their components altered without explicit view changes, there won’t be any surprises to find from them.
Refreshing all views will require some dynamic SQL to generate sp_refreshview statements for each view identified above:
CREATE TABLE #view_ddl_exception_list
(view_name SYSNAME NOT NULL PRIMARY KEY CLUSTERED);
DECLARE @sql_command NVARCHAR(MAX);
SELECT @sql_command = '';
SELECT
@sql_command = @sql_command + '
BEGIN TRY
EXEC sp_refreshview N''' +
CAST(distinct_view_list.view_schema_name
AS VARCHAR(MAX)) + '.' +
CAST(distinct_view_list.view_name
AS VARCHAR(MAX)) + ''';
END TRY
BEGIN CATCH
PRINT ''The following view is broken via DDL errors
during sp_refreshview: ' +
CAST(distinct_view_list.view_schema_name
AS VARCHAR(MAX)) + '.' +
CAST(distinct_view_list.view_name
AS VARCHAR(MAX)) + ''';
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK;
END
INSERT INTO #view_ddl_exception_list
(view_name)
SELECT
''' + CAST(distinct_view_list.view_name
AS VARCHAR(MAX)) + ''';
END CATCH;'
FROM #distinct_view_list distinct_view_list;
EXEC sp_executesql @sql_command;
Note that there is some added complexity here in the form of try…catch blocks. A view can be broken by changes to its underlying tables, and we’d like to catch these errors gracefully, rather than have our code break mid-execution. The resulting command that gets executed will look like this:
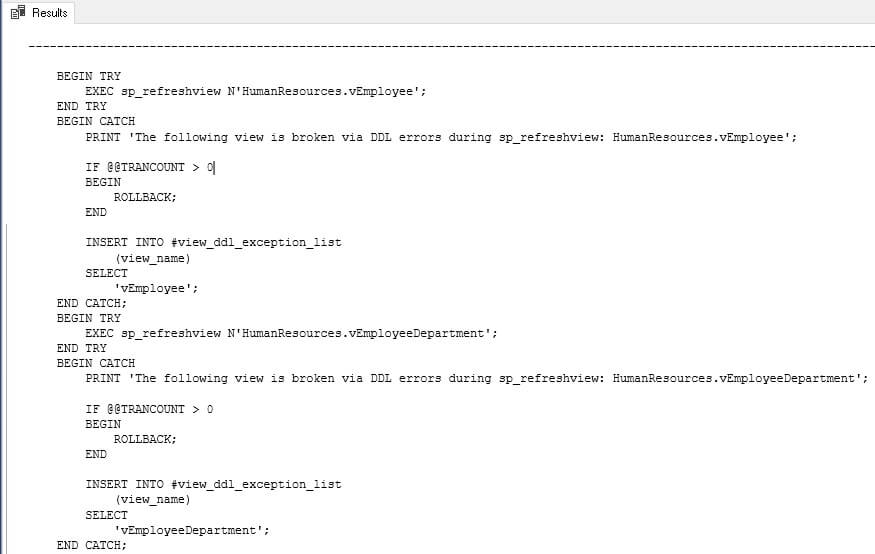
This sample shows the T-SQL needed to refresh two views. The full script will contain a TRY and CATCH block for each view. Note that the temp table #view_ddl_exception_list will be populated with a broken view name, which will allow you to research further when this script is complete. We can capture more metrics, such as error codes and messages, but I wanted to stop short of making this script too complex. Feel free to add more debugging if it proves helpful in error-trapping.
Assuming no errors, the dynamic SQL above will execute quietly, and execution will move on to the next section of code with no fanfare. The next step is to capture view metadata a second time, using the same syntax that was used earlier:
INSERT INTO #view_metadata_after
(view_object_id, view_schema_name, view_name, column_name,
column_id, user_type_id, user_type_name, column_max_length,
column_precision, column_scale, is_column_nullable,
is_schemabound_view)
SELECT
views.object_id AS view_object_id,
schemas.name AS view_schema_name,
views.name AS view_name,
columns.name AS column_name,
columns.column_id,
types.user_type_id,
types.name AS user_type_name,
CASE WHEN types.name IN ('nchar', 'nvarchar') THEN
columns.max_length / 2 ELSE columns.max_length END
AS column_max_length,
columns.precision AS column_precision,
columns.scale AS column_scale,
columns.is_nullable,
OBJECTPROPERTY(views.object_id, 'IsSchemaBound')
AS is_schemabound_view
FROM sys.views
INNER JOIN sys.columns
ON columns.object_id = views.object_id
INNER JOIN sys.types
ON types.user_type_id = columns.user_type_id
INNER JOIN sys.schemas
ON schemas.schema_id = views.schema_id
WHERE views.name NOT LIKE 'x[_]%'
ORDER BY views.object_id, columns.column_id;
With a before and after snapshot available, we can compare the two and determine if any differences exist. To do this meaningfully, we should perform left joins between the before-snapshot and the after-snapshot. To be thorough, we should execute this query starting with the before metadata and then also starting with the after metadata. This ensures that we capture any changes, including dropped or added columns. The resulting query is a bit lengthy, but will provide exactly what is needed to evaluate changes in views:
WITH CTE_before_except AS (
SELECT
view_object_id,
view_schema_name,
view_name,
column_name,
column_id,
user_type_id,
user_type_name,
column_max_length,
column_precision,
column_scale,
is_column_nullable,
is_schemabound_view
FROM #view_metadata_before
EXCEPT
SELECT
view_object_id,
view_schema_name,
view_name,
column_name,
column_id,
user_type_id,
user_type_name,
column_max_length,
column_precision,
column_scale,
is_column_nullable,
is_schemabound_view
FROM #view_metadata_after),
CTE_after_except AS (
SELECT
view_object_id,
view_schema_name,
view_name,
column_name,
column_id,
user_type_id,
user_type_name,
column_max_length,
column_precision,
column_scale,
is_column_nullable,
is_schemabound_view
FROM #view_metadata_after
EXCEPT
SELECT
view_object_id,
view_schema_name,
view_name,
column_name,
column_id,
user_type_id,
user_type_name,
column_max_length,
column_precision,
column_scale,
is_column_nullable,
is_schemabound_view
FROM #view_metadata_before)
SELECT
CTE_before_except.view_object_id,
CTE_before_except.column_id,
CTE_before_except.view_schema_name AS view_schema_name_before,
view_metadata_after.view_schema_name AS view_schema_name_after,
CTE_before_except.view_name AS view_name_before,
view_metadata_after.view_name AS view_name_after,
CTE_before_except.column_name AS column_name_before,
view_metadata_after.column_name AS column_name_after,
CTE_before_except.user_type_id AS user_type_id_before,
view_metadata_after.user_type_id AS user_type_id_after,
CTE_before_except.user_type_name AS user_type_name_before,
view_metadata_after.user_type_name AS user_type_name_after,
CTE_before_except.column_max_length AS column_max_length_before,
view_metadata_after.column_max_length AS column_max_length_after,
CTE_before_except.column_precision AS column_precision_before,
view_metadata_after.column_precision AS column_precision_after,
CTE_before_except.column_scale AS column_scale_before,
view_metadata_after.column_scale AS column_scale_after,
CTE_before_except.is_column_nullable AS is_column_nullable_before,
view_metadata_after.is_column_nullable
AS is_column_nullable_after,
CTE_before_except.is_schemabound_view
INTO #sp_refreshview_results
FROM CTE_before_except
LEFT JOIN #view_metadata_after view_metadata_after
ON view_metadata_after.view_object_id = CTE_before_except.view_object_id
AND view_metadata_after.column_id = CTE_before_except.column_id
UNION
SELECT
view_metadata_before.view_object_id,
view_metadata_before.column_id,
view_metadata_before.view_schema_name AS view_schema_name_before,
CTE_after_except.view_schema_name AS view_schema_name_after,
view_metadata_before.view_name AS view_name_before,
CTE_after_except.view_name AS view_name_after,
view_metadata_before.column_name AS column_name_before,
CTE_after_except.column_name AS column_name_after,
view_metadata_before.user_type_id AS user_type_id_before,
CTE_after_except.user_type_id AS user_type_id_after,
view_metadata_before.user_type_name AS user_type_name_before,
CTE_after_except.user_type_name AS user_type_name_after,
view_metadata_before.column_max_length AS column_max_length_before,
CTE_after_except.column_max_length AS column_max_length_after,
view_metadata_before.column_precision AS column_precision_before,
CTE_after_except.column_precision AS column_precision_after,
view_metadata_before.column_scale AS column_scale_before,
CTE_after_except.column_scale AS column_scale_after,
view_metadata_before.is_column_nullable
AS is_column_nullable_before,
CTE_after_except.is_column_nullable AS is_column_nullable_after,
CTE_after_except.is_schemabound_view
FROM CTE_after_except
LEFT JOIN #view_metadata_before view_metadata_before
ON view_metadata_before.view_object_id = CTE_after_except.view_object_id
AND view_metadata_before.column_id = CTE_after_except.column_id;
IF EXISTS (SELECT * FROM #sp_refreshview_results)
BEGIN
SELECT
*
FROM #sp_refreshview_results;
END
The results of the above T-SQL provide a clean data set showing what views have changed, but have not been refreshed:

Seven views rely on the Suffix column that we altered earlier. The details above show the view name, the column, and how it changed. Before and after metadata are included, allowing for a full understanding of changes without any guesswork. Using this information, we can review our application changes and ensure that views remain accurate as changes occur to tables and columns.
One hugely important note: Always run this process in a development environment! In order to do a before & after schema comparison, it is necessary to refresh views and determine if any changes have occurred. Perform this test in development and then refresh specific views in production to bring them in sync with the underlying schema.
Bonus: Validating Views
We can also test views for errors that may have arisen due to changes in underlying objects. For example, if a table that a view references is dropped, the view will throw an error when queried. Data type mismatches or truncation could also occur if data types change without related views getting altered or refreshed.
This process is simpler than verifying schema changes and can be conducted by a nice combination of brute force and dynamic SQL. If a view no longer functions correctly, it can be tested by selecting a row and catching errors when they occur. Dynamic SQL provides an easy means to accomplish this task:
DECLARE @sql_command NVARCHAR(MAX);
IF EXISTS (SELECT * FROM tempdb.sys.tables
WHERE tables.name LIKE '#distinct_view_list%')
BEGIN
DROP TABLE #distinct_view_list;
END
CREATE TABLE #distinct_view_list
(distinct_view_list_id INT NOT NULL
IDENTITY(1,1) PRIMARY KEY CLUSTERED,
view_schema_name SYSNAME NOT NULL,
view_name SYSNAME NOT NULL);
INSERT INTO #distinct_view_list
(view_schema_name, view_name)
SELECT
schemas.name AS view_schema_name,
views.name AS view_name
FROM sys.views
INNER JOIN sys.schemas
ON schemas.schema_id = views.schema_id;
IF EXISTS (SELECT * FROM tempdb.sys.tables WHERE tables.name
LIKE '#view_ddl_exception_list%')
BEGIN
DROP TABLE #view_ddl_exception_list;
END
CREATE TABLE #view_ddl_exception_list
(view_name SYSNAME NOT NULL PRIMARY KEY CLUSTERED);
SELECT @sql_command = '';
SELECT
@sql_command = @sql_command + '
BEGIN TRY
SELECT TOP 1 *
INTO temp_results_' +
CAST(distinct_view_list.distinct_view_list_id
AS VARCHAR(MAX)) + '
FROM [' + CAST(distinct_view_list.view_schema_name
AS VARCHAR(MAX)) + '].[' +
CAST(distinct_view_list.view_name AS VARCHAR(MAX))
+ '];
DROP TABLE temp_results_' +
CAST(distinct_view_list.distinct_view_list_id
AS VARCHAR(MAX)) + ';
END TRY
BEGIN CATCH
PRINT ''The following view is broken via DML errors
from a SELECT * FROM query: ' +
CAST(distinct_view_list.view_schema_name
AS VARCHAR(MAX)) + '.' +
CAST(distinct_view_list.view_name AS VARCHAR(MAX)) + '
Error Message: '' + ERROR_MESSAGE();
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK;
END
END CATCH;'
FROM #distinct_view_list distinct_view_list
WHERE distinct_view_list.view_name NOT IN
(SELECT view_ddl_exception_list.view_name
FROM #view_ddl_exception_list view_ddl_exception_list);
EXEC sp_executesql @sql_command;
The first part of the script collects a list of views and is a simplified version of what we worked with earlier. Since all that is needed are view names, we can forgo collecting column and data type metadata.
The remainder of the script uses dynamic SQL to attempt a SELECT of the top one row from each view. If it succeeds, then nothing happens. If an error is thrown, then the CATCH block will print the error message and view name for our review when the process completes.
Note that permanent tables are used in the dynamic SQL, which guards against errors if there happens to be XML schema collections defined within the database. While uncommon, I chose here to include rather than omit them. Feel free to adjust these to temporary tables if this will not be an issue within your own database environment.
We can test this code by intentionally building a view and then breaking it:
ALTER TABLE Person.Person ADD
favorite_ice_cream_flavor VARCHAR(50) NULL;
GO
UPDATE Person.Person
SET favorite_ice_cream_flavor = 'Mint Chocolate Chip';
GO
CREATE VIEW v_employee_ice_cream
AS
SELECT
Person.BusinessEntityID,
Person.FirstName,
Person.LastName,
CAST(Person.favorite_ice_cream_flavor
AS VARCHAR(25)) AS favorite_ice_cream_flavor
FROM Person.Person;
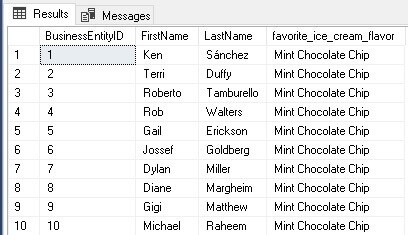
GO
SELECT TOP 10
favorite_ice_cream_flavor
FROM dbo.v_employee_ice_cream;
This T-SQL creates a new column in Person.Person to store a favorite ice cream flavor. A view is then created that returns a person’s ID, name, and favorite flavor:
Since the view was not created with schema binding, we can alter the Person table with no immediate feedback:
ALTER TABLE Person.Person DROP COLUMN favorite_ice_cream_flavor;
ALTER TABLE Person.Person ADD favorite_ice_cream_flavor XML NULL;
UPDATE Person.Person
SET favorite_ice_cream_flavor =
'<ice_cream>Mint Chocolate Chip</ice_cream>';
By dropping and recreating the column as XML, we are creating a situation where casting the data on the fly is going to fail. Now let’s run the code we created earlier and test all views in our database for DML errors. To make testing this easier, you can find a stored procedure version here. When we do so, the following information is printed for our review:

Our code caught the error shown above and returned it as a friendly message instead. It also provided some details as to which view broke, allowing us to quickly test and verify for ourselves that it is indeed broken:
SELECT TOP 10
favorite_ice_cream_flavor
FROM dbo.v_employee_ice_cream;
Here is the message that is returned by SQL Server:

This code will catch any DML error that can be thrown by the view, allowing us to identify obscure or unexpected errors that may not be found otherwise. The benefit of this is that we can reduce bugs up-front, long before app changes are deployed!
Conclusion
Views are useful constructs that can save time and improve application maintainability when used effectively. When not schema bound, though, views can become stale and become the source of bugs. The code discussed in this article has allowed us to identify three distinct types of problems:
- Views that are not refreshed and are reporting incorrect data types.
- Views that contain DDL errors and cannot be refreshed or used.
- Views that can be refreshed, but contain DML errors related to data types or data content.
Adding a script that performs these tasks on a regular basis as part of a QA process can allow for views to be tested and validated before they ever see a production environment. Over time, this will reduce bugs and improve code quality as mistakes are caught immediately, rather than days or weeks later.
The post Tracking Underlying Object Changes in Views appeared first on Simple Talk.
from Simple Talk https://ift.tt/33YptR0
via
No comments:
Post a Comment