Columnstore compression is an impressive array of algorithms that can take large analytic tables and significantly reduce their storage footprint. In doing so, IO is also reduced, and query performance dramatically improved.
This article dives into one aspect of columnstore compression that tends to get buried in all of the hoopla surrounding how awesome columnstore indexes are: Vertipaq optimization. This is a critical component of the columnstore compression process, and understanding how it works can significantly improve the performance of analytic workloads while reducing the computing resources required for the underlying data.
Overview of the columnstore compression process
Columnstore compression can be roughly broken down into three distinct steps:
- Encoding
- Optimization
- Compression
Each of these steps is critical to efficiently storing analytic data, and their order is equally important. Each segment in a columnstore index is compressed separately. This allows different columns of different data types and content to be compressed based on whatever algorithms are best for the values contained within each specific segment.
All compression algorithms discussed in this article are lossless in nature and ultimately rely on exploiting repetition within a data set. The following is a brief review of each compression step and its contribution towards compact OLAP data.
Encoding
The first set of processes used by SQL Server to compress data are transformations known as encoding algorithms. These attempt to restructure data in ways that take up less space. Encoding helps to reduce the footprint of large data types and makes it easier for subsequent compression algorithms to compress effectively. Here are a few examples of common encoding algorithms.
Dictionary encoding
When data values within a segment are a combination of repetitive and wide, dictionary encoding will often be used to “pseudo-normalize” the data prior to further compression. While string data is most often the target of this algorithm, it may also apply to numeric (or other) data types.
In dictionary encoding, each distinct value within a segment is inserted into a dictionary lookup structure and indexed using a numeric key. Each value within the segment is then pointed to the lookup table using its numeric index. For example, consider the following data sample for a column:
|
Value |
Size in Bytes |
| Mario | 5 |
| Sonic the Hedgehog | 18 |
| Mario | 5 |
| Yoshi | 5 |
| Ness | 4 |
| Pikachu | 7 |
| Sonic the Hedgehog | 18 |
| Yoshi | 5 |
| Link | 4 |
The values in this column are string-based and contain some repetition. If dictionary encoding were used, an indexed dictionary would be created that looks like this:
|
ID (Numeric) |
Value (String) |
|
0 |
Link |
|
1 |
Mario |
|
2 |
Ness |
|
3 |
Pikachu |
|
4 |
Sonic the Hedgehog |
|
5 |
Yoshi |
Once a dictionary is created, the rows within the segment are assigned to their corresponding dictionary lookup, and the index IDs used going forward instead of the explicit string values. The result is a transformation from the initial segment data into a dictionary compressed segment, as shown in this diagram:
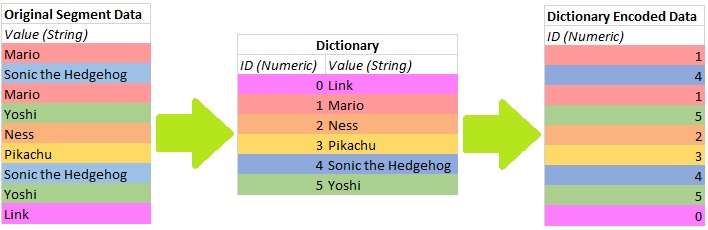
In this example, nine string values were replaced with numeric values. When the dictionary index is created, the data type for the ID is chosen based on the number of distinct values. In this case, 3 bits are enough to store all possible values (zero through five). When complete, the size of the original data sample can be compared with the dictionary encoded results. The string data sample contained nine strings totalling 71 bytes if the data type is VARCHAR or 142 bytes if it is NVARCHAR. The dictionary contains six values totaling 43 bytes. The dictionary encoded table contains nine values, each consuming 3 bits, for a total of 27 bits, or 4 bytes, rounding up.
The savings increases as the number of repeated values increase. If this were a typical data sample for a full columnstore segment containing 1,048,576 repetitive string values, then the savings could be quite immense!
Value encoding
Value encoding attempts to shrink the size of data by manipulating how it is stored to use smaller data types. Encoding is accomplished via mathematical transformations to the underlying data and is used exclusively on numeric data types. The easiest way to illustrate this is via an example. The following is a set of integer values:
| Value | Size in Bits |
| 1700 | 11 |
| 289000 | 19 |
| 500 | 9 |
| 10000 | 14 |
| 1000 | 10 |
| 2000000 | 21 |
These values are likely stored in an INT or BIGINT column and therefore consume 4 bytes or 8 bytes each, respectively. The bits are provided as a reference since columnstore compression will use as little space as possible to store values, regardless of data type. Value encoding will attempt to find common divisors for all values in the segment and applying the appropriate exponent to all values to shrink their footprint. For the sample values above, all are divisible by 100, and therefore can be rewritten like this:
|
Value |
Value * 10-2 |
Size (bits) |
|
1700 |
17 |
5 |
|
289000 |
2890 |
12 |
|
500 |
5 |
3 |
|
10000 |
100 |
7 |
|
1000 |
10 |
4 |
|
2000000 |
20000 |
15 |
This transformation divides all values by 100, denoting that the common negative exponent for each value is 10-2. The result of this first transformation is a reduction in storage from 84 bits to 46 bits. Another transformation used in value encoding is to rebase the values using whatever value is closest to zero. This is an additive operation that, in the case of this example, will take the smallest absolute value in the list (five) and subtract it from all values, like this:
|
Value |
Value * 10-2 |
Value * 10-2 – 5 |
Size (bits) |
|
1700 |
17 |
12 |
4 |
|
289000 |
2890 |
2885 |
12 |
|
500 |
5 |
0 |
0 |
|
10000 |
100 |
95 |
7 |
|
1000 |
10 |
5 |
3 |
|
2000000 |
20000 |
19995 |
15 |
This further decreases storage by another 5 bits. This may seem small, but it does represent an 11% reduction from the previous step and 51% overall compression, which is quite impressive! When this data is stored, it will be maintained alongside the exponent and rebasing value so that decompression can occur quickly by reversing these operations.
Compression
The optimization step is being intentionally skipped (for the moment) to introduce compression. This step uses a variety of compression algorithms that comprise the xVelocity algorithm to reduce the size of segment data as much as possible. While the details of this algorithm are not public, it is safe to make some assumptions about how this data is compressed based on the information that is publicly available. There are multiple algorithms commonly used, including bit-array compression and run-length encoding. Columnstore archive compression implements more aggressive compression techniques and is intended for data that is cool/cold, rather than warm/hot.
The simplest and biggest space-saver regarding columnstore compression is run-length encoding, which takes values that repeat consecutively and compresses them into single entries that signify their value and the number of times it repeats. In analytic data, values often repeat, thus allowing this algorithm to provide significant savings when applied. Consider this example data:

Some values repeat consecutively and can be simplified into a value and magnitude:

This simplification reduces the number of values that need to be stored by three (from twelve to nine). They’d likely also be previously dictionary compressed, further reducing the storage footprint. Note that there are still multiple values that repeat in this list and are stored repeatedly. This is a significant hurdle towards the ability for run-length encoding to effectively compress data. This challenge leads into the headlining topic for this article: Vertipaq Optimization.
Optimization
In rowstore tables, row order is critical to the function of clustered indexes and the performance of typical OLTP queries. A table with a clustered index on an ID column will be ordered on that column so that index seeks on that key can quickly return results. That order is essential for the maintenance of binary-tree indexes and makes perfect sense for common OLTP data scenarios.
Columnstore indexes throw all of that out the window. There is no built-in row order. When building a columnstore index, the data order is determined by however the architect had rows ordered prior to its creation. Azure Synapse Analytics and Parallel Data Warehouse provide syntax for the initial ordering of data within a columnstore index, but once created, maintaining data order is up to whatever processes write data to the index.
This means that once compressed, the order of rows within each rowgroup does not matter. This allows for row order optimization to occur. This is a process that determines an optimal row order based on the order that generates the best compression ratio for the underlying data. The highest compression ratios will typically be those that move as many repeated values into adjacent groupings as possible. This greatly benefits run-length encoding and further enhances the impact of encoding steps taken earlier in the compression process.
Note that a row order is determined for an entire rowgroup, which means that the row order for any one segment may be quite optimal, whereas the order for another segment may be suboptimal. Despite that detail, like values tend to group together across segments, and SQL Server is capable of determining a good row order, even when many different columns are present. Reconsidering the run-length encoding example from the previous section, applying row order optimization to the data would reduce storage further, as shown by this diagram:

Rearranging row order allowed for each of the three pairs of repeated values to be combined further, reducing the row count from nine to six. Note that the count of values for each distinct entry has not changed. Reordering rows, though, allowed for additional values to be combined via run-length encoding.
Vertipaq Optimization is the proprietary process used by Microsoft in compressing analytic data on many of their platforms, including SSAS, PowerPivot, Power BI, and in columnstore indexes. Whenever a rowgroup is created or modified, this optimization will be automatically used whenever possible.
The details as to whether or not a rowgroup has been optimized can be viewed in SQL Server via the system view dm_db_column_store_row_group_physical_stats as a bit. The following query returns this information for each rowgroup within a specific columnstore index:
SELECT
schemas.name AS schema_name,
objects.name AS table_name,
dm_db_column_store_row_group_physical_stats.partition_number,
dm_db_column_store_row_group_physical_stats.row_group_id,
dm_db_column_store_row_group_physical_stats.has_vertipaq_optimization
FROM sys.dm_db_column_store_row_group_physical_stats
INNER JOIN sys.objects
ON objects.object_id =
dm_db_column_store_row_group_physical_stats.object_id
INNER JOIN sys.schemas
ON schemas.schema_id = objects.schema_id
INNER JOIN sys.indexes
ON indexes.index_id =
dm_db_column_store_row_group_physical_stats.index_id
AND indexes.object_id =
dm_db_column_store_row_group_physical_stats.object_id
WHERE objects.name = 'Sale'
ORDER BY dm_db_column_store_row_group_physical_stats.row_group_id,
dm_db_column_store_row_group_physical_stats.partition_number;
The results provide a row per rowgroup and whether Vertipaq Optimization has been used when segments were compressed within each rowgroup:
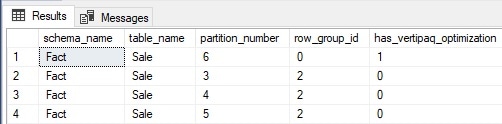
For the columnstore index on Fact.Sale, one rowgroup in partition 6 has Vertipaq Optimization, whereas the other three rowgroups in partitions 3, 4, and 5 do not. While this sample columnstore index in WideWorldImportersDW is not very large, it can be used to demonstrate the impact on compression when Vertipaq Optimization is not used. Row count and size can be added to the previous query, like this:
SELECT
schemas.name AS schema_name,
objects.name AS table_name,
dm_db_column_store_row_group_physical_stats.partition_number,
dm_db_column_store_row_group_physical_stats.row_group_id,
dm_db_column_store_row_group_physical_stats.has_vertipaq_optimization,
dm_db_column_store_row_group_physical_stats.total_rows,
dm_db_column_store_row_group_physical_stats.deleted_rows,
dm_db_column_store_row_group_physical_stats.size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats
INNER JOIN sys.objects
ON objects.object_id =
dm_db_column_store_row_group_physical_stats.object_id
INNER JOIN sys.schemas
ON schemas.schema_id = objects.schema_id
INNER JOIN sys.indexes
ON indexes.index_id =
dm_db_column_store_row_group_physical_stats.index_id
AND indexes.object_id =
dm_db_column_store_row_group_physical_stats.object_id
WHERE objects.name = 'Sale'
ORDER BY dm_db_column_store_row_group_physical_stats.row_group_id,
dm_db_column_store_row_group_physical_stats.partition_number;
The results show how many rows there are in each rowgroup and their size:

What happened!? Why do three rowgroups lack Vertipaq Optimization? For a large columnstore index, this could be quite costly! More importantly, what can we do about it!?
When does optimization not occur?
Vertipaq optimization is a resource-intensive step that needs to occur quickly whenever a rowgroup is written to. This not only includes columnstore index creation, but also data loads that INSERT, UPDATE, or DELETE data within rowgroups. Because of this, there are two common scenarios where optimization will not occur:
- Memory-optimized columnstore indexes
- Clustered columnstore indexes with non-clustered rowstore indexes when delta store rowgroups are merged into compressed rowgroups.
The primary reason that these index configurations will forgo Vertipaq Optimization is due to the cost associated with rearranging rows in each scenario. Memory-optimized tables are structured as row-based solutions to solve contentious OLTP workloads. Regardless of how a memory-optimized table is indexed (columnstore or rowstore), the underlying data is stored in a row-by-row configuration. This differs from disk-based columnstore indexes, which are physically stored by column rather than row.
This is not to say that memory-optimized columnstore indexes are not valuable, but they will not benefit from Vertipaq Optimization when used. If real-time operational analytics are required from a memory-optimized table, consider the fact that compression ratios may not be as impressive for a memory-optimized columnstore index as they would be for its disk-based counterpart and budget memory appropriately based on that knowledge.
When a clustered columnstore index has non-clustered rowstore indexes added to it, a row mapping must be maintained between the non-clustered and clustered indexes. This is analogous to how nodes in a non-clustered rowstore index contain a copy of the clustered primary key that allow for fast writes or key lookups between the indexes, when needed. For Vertipaq Optimization to work in this scenario would require the row mapping between each non-clustered rowstore index and the clustered columnstore index to be updated whenever the optimization process was applied. This would be quite expensive (aka: SLOW!), and as such, the process is skipped in these scenarios.
While this may seem like a cautionary tale as to why non-clustered rowstore indexes should not be used in conjunction with clustered columnstore indexes, there are ways to mitigate this problem and minimize the impact of it at little cost to the SQL Server that hosts this data.
Steps to resolve unoptimized rowgroups
The primary reason that Vertipaq Optimization is not applied to rowgroups is because non-clustered rowstore indexes were present on the columnstore index when data was written to it. A clustered columnstore index may be built with non-clustered rowstore indexes present, and existing data will be optimized, but additional data that is written later may not be. Despite that situation, optimization can still occur. The following are some strategies for tackling this problem, both pre-emptively and after the fact.
Partitioning
Tables with columnstore indexes can be partitioned just like any other table in SQL Server. Rowgroups do not span partitions, and each partition will have its own unique set of rowgroups. If the partition scheme organizes data based on active versus inactive data (a time-based dimension), then indexing strategies and maintenance can vary from partition to partition. This means that:
- Older partitions might not need as many (or any) non-clustered rowstore indexes.
- Older data may never change. If so, it can be subject to a one-time rebuild/cleanup process, after which it will remain optimal indefinitely.
- If a columnstore index is memory-optimized, then maybe older data that is rarely subject to busy OLTP querying can be separated into disk-based tables/partitions/indexes and not maintained in-memory.
For a large columnstore index, consider partitioning it. The benefits are huge and the drawbacks minimal. Ensure that each partition has enough rows to comprise many rowgroups so that rowgroups are not inadvertently undersized.
Initial build considerations
When creating a columnstore index for the first time and populating it with data, forgo the non-clustered indexes until after the initial build is complete. This will not only allow optimization to occur, but it will speed up the data load as SQL Server does not need to write to both clustered and non-clustered indexes while loading data.
Non-clustered indexes can be created after all data has been inserted, preserving its optimal compression along the way.
Columnstore index rebuilds
While SQL Server will not automatically apply Vertipaq Optimization to newly inserted data in clustered columnstore indexes that have non-clustered rowstore indexes present, re-creating the index will resolve the problem. Note that when performing an index rebuild on the columnstore index, optimization will not necessarily be applied, but it also will not be removed.
This is a helpful key in understanding what the has_vertipaq_optimization bit means as it applies to data that is inserted in the future. Since columnstore indexes have no built-in data order, existing data may or may not be optimized. Future index rebuilds will not take optimized data and “de-optimize” it. Therefore, once data is pristine, it will remain so unless a more disruptive process changes it (such as the use of a clustered rowstore index).
This can be demonstrated with Fact.Sale, for which three of four rowgroups do not have Vertipaq Optimization applied to their compression. The following T-SQL executes a rebuild against the columnstore index:
ALTER INDEX CCX_Fact_Sale ON Fact.Sale REBUILD WITH (ONLINE = ON);
Once complete, checking metadata reveals that no rowgroups have Vertipaq Optimization enabled:

The has_vertipaq_optimization bit is now set to zero, and nothing else has changed. Rebuilding the index did not provide any benefit regarding optimization. With the non-clustered indexes present, getting Vertipaq Optimization applied will require dropping and recreating the columnstore index the old-fashioned way:
DROP INDEX CCX_Fact_Sale ON Fact.Sale; CREATE CLUSTERED COLUMNSTORE INDEX CCX_Fact_Sale ON Fact.Sale WITH (MAXDOP = 1);
I get 
Note that not only is Vertipaq Optimization enabled, but the space consumed by each rowgroup has decreased. The rowgroup that was already optimized has not changed, but the other three have been shrunk from a total of 5,035,816 bytes to 3,346,304. This is about a 34% savings, which underscores the significance of Vertipaq Optimization and how it can greatly improve columnstore compression ratios.
There is an important cautionary lesson here: Limit non-clustered rowstore indexes on clustered columnstore indexes. It is very unlikely that a real-world table needs this many foreign key indexes and including them wastes space and resources. Test queries without supporting indexes first and verify if they are needed or not. If the table is truly analytic in nature, then a well-ordered columnstore index should be able to service most (or all) of the OLAP queries issued against it. If the table serves a mixed workload, consider which is predominant, the OLTP queries or the OLAP queries. If transactional queries dominate, then consider using a clustered rowstore index with a non-clustered columnstore index on the appropriate columns.
Once the rowgroups are optimized, keep in mind that inserting or merging new data into them will result in has_vertipaq_optmization to be set to 0. This can be simulated locally with a REBUILD operation. Note that when data is optimized and has_vertipaq_optimization is later set to zero for a rowgroup, the existing data remains optimized.
For example, consider the similar rowgroup metadata below:

While has_vertipaq_optimization is now shown as zero for all rebuilt partitions, it has had no impact on the size of those rowgroups and will only impact data written in the future. Therefore, there is value in only issuing index maintenance against active partitions that need it. Older data that has already had Vertipaq Optimization applied will not benefit from further rebuild processes unless the data is modified somehow before that maintenance.
Index maintenance strategy
The impact of non-clustered indexes on a clustered columnstore index leads to the need to target index maintenance to the data that requires it most. In most typical data warehouse scenarios, data is written once (or multiple times over a short span of time) and then not altered again. In this situation, it is possible to save the expensive index drop/add or index rebuilds to when the data is no longer hot. This will minimize disruption while ensuring that data at rest is as compact as possible. It will also ensure that infrequent (but resource-hungry) long-term analytics can run as quickly and efficiently as possible. Similarly, read-only data needs only to be targeted by index maintenance one time so long as it is not written again.
Validating Vertipaq optimization
Using simplified versions of queries already introduced in this article, it becomes easy to check for any columnstore index rowgroups that do not have Vertipaq Optimization. The following query returns filtered details about any columnstore rowgroups that are not optimized:
SELECT
schemas.name AS schema_name,
objects.name AS table_name,
indexes.name AS index_name,
dm_db_column_store_row_group_physical_stats.partition_number,
dm_db_column_store_row_group_physical_stats.row_group_id,
dm_db_column_store_row_group_physical_stats.total_rows,
dm_db_column_store_row_group_physical_stats.deleted_rows,
dm_db_column_store_row_group_physical_stats.size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats
INNER JOIN sys.objects
ON objects.object_id =
dm_db_column_store_row_group_physical_stats.object_id
INNER JOIN sys.schemas
ON schemas.schema_id = objects.schema_id
INNER JOIN sys.indexes
ON indexes.index_id =
dm_db_column_store_row_group_physical_stats.index_id
AND indexes.object_id =
dm_db_column_store_row_group_physical_stats.object_id
WHERE dm_db_column_store_row_group_physical_stats.has_vertipaq_optimization = 0
ORDER BY schemas.name, objects.name, indexes.name,
dm_db_column_store_row_group_physical_stats.row_group_id,
dm_db_column_store_row_group_physical_stats.partition_number;
The results show again the four rowgroups from Fact.Sale that were discussed above:

Using this information, an architect or operator can decide how (or if) to take any further actions with index maintenance. Some thoughts on how to proceed given this data:
If rowgroups contain data that is no longer hot, then indexes can easily be dropped and recreated. If the data is heavily used, then an online rebuild could be used to help improve index structure, with a drop/recreate saved for a time when maintenance operations are allowed. Keep in mind that the need to fix unoptimized data should be rare and will often be a one-time operation for analytic data as it is rarely the subject of disruptive update operations. Once a rowgroup is full and optimized, then it will remain optimal indefinitely, even if the has_vertipaq_optimization bit is flipped to zero. Only a significant change to the table’s structure would change that.
If a rowgroup is relatively small and lacks optimization, then dropping an index on a large table to fix that small rowgroup is likely not a good use of resources. Employ index maintenance tactically and only when there is a meaningful benefit to be gained. Generally speaking, optimization will improve compression ratios by at least 25%, though I have personally seen it go as high as 60%. The more repetitive the data, the better the improvement.
Because analytic data is written on more structured schedules by well-defined processes, the need to validate optimization is unlikely to be daily, or even weekly. Consider this as an infrequent check to ensure that storage and IO are not being wasted in large amounts. The accumulated bloat of poorly compressed data will not be seen in a few days but will be realized either when a table is first populated or over time as more data is added.
Conclusion
Optimization is an important step in the columnstore compression algorithm that can greatly reduce storage footprint and improve IO. SQL Server will utilize Vertipaq Optimization whenever possible, but under some circumstances will not. When unable to be used, it is up to us to identify when and why it was skipped and determine the simplest way to proceed.
For a large columnstore index, Vertipaq Optimization can provide significant savings at little cost to an organization. It’s free and easy to use, and all that is needed is knowledge of its existence and how to take advantage of it. Enjoy!
If you liked this article, you might also like Hands-On with Columnstore Indexes: Part 1 Architecture.
The post Vertipaq optimization and its impact on columnstore compression appeared first on Simple Talk.
from Simple Talk https://ift.tt/3GMVUo0
via
No comments:
Post a Comment