The series so far:
- DBA in training: So, you want to be a DBA...
- DBA in training: Preparing for interviews
- DBA in training: Know your environment(s)
- DBA in training: Security
- DBA in training: Backups, SLAs, and restore strategies
- DBA in training: DBA in training: Know your server’s limits
You are now more familiar with your environment, how to secure it, and how to keep it from breaking. It’s time to begin delving into the weeds and learn more about SQL Server under the hood. (Well, sort of. You can spend a lifetime learning internals). This article will deal with basic internals, indexing, tuning, and sins against SQL Server, which should be avoided.
SQL Server – the house that Microsoft built
To get an idea of how SQL Server works, let’s start at the bottom and work our way up. Here is a 10,000-mile view to help us get started:
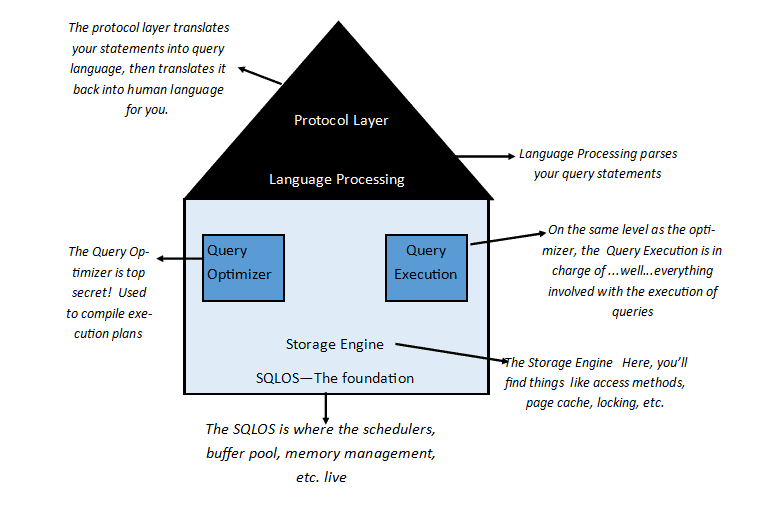
The basic anatomy of a SQL Server instance
The more rows of data that can fit on a page, the better performance will be for everything up the tree. This is the reason that you need to look at what kind of data types are making up your tables – even a small difference might not end up scaling. We’ll go more into that point when we start talking about tables.
So, a query walks into the parser….
….and SQL Server will see if it parses or not. If it does parse, it is sent off to the Query Optimizer. The Query Optimizer sees if it already has a plan that will work for the query. If it does, it uses it. If not, it will look through the options until it finds a good enough plan (not necessarily the best one!). To do that, it looks through table structures and indexes; it combs through statistics to figure out what (if any) indexes can be used, and if they can, will it be a quick seek or a row-by-agonizing-row proposition. It coordinates with the Query Execution layer. Meanwhile, waaaaay down the stack, the Engine is reading pages into memory (if they aren’t already there), locking tables or rows of data (if needed), and generally carrying out the nuts and bolts that make the query happen. The protocol layer takes the results and translates them back into a language that the end-user can understand.
This, of course, is the 10,000 mile-high view of it, but you get the idea.
The DMVs and system objects
There are many built-in ways to find out what’s going on under-the-hood: DMVs (dynamic management views) and other system objects.
Dynamic Management Objects
The Dynamic Management Objects are a set of views and functions supplied by Microsoft to help you look inside SQL Server. They need a bit of manipulation to present the data in an immediately useable way. Glenn Berry has done the work for you. Unless you just love a challenge, don’t reinvent the wheel. You can find his diagnostic queries here, or if you like PowerShell, DBATools will run his queries and even export them to Excel for you. They are the source of invaluable information on your servers, and I have used them countless times when trying to troubleshoot issues or to baseline metrics.
INFORMATION_SCHEMA views
Microsoft also gives you something called the INFORMATION_SCHEMA views. These are a fast and easy way to get the answer when you have questions such as what table has what column, or how to find occurrences of a string anywhere on a server instance. It can also give you information on column-level permissions, constraint column usage, and more.
System functions
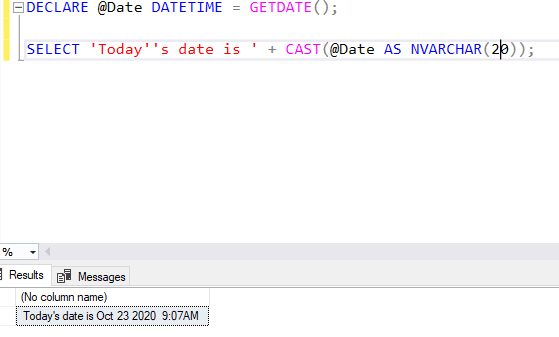
SQL Server comes equipped with a set of useful functions that are good to know. Some examples include the invaluable GETDATE(), which returns the current date as a datetime:
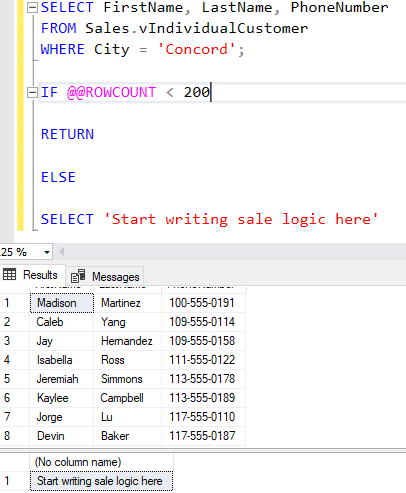
They may also include @@ROWCOUNT, which does what you would expect: it returns the number of rows affected by your last code statement. In an admittedly contrived example, say you work for AdventureWorks and want to liquidate some inventory. You’re considering the possibility of having a sale in a particular area, but it won’t make sense to do so for a population under 200 people. You could use @@ROWCOUNT in your decision logic:
If you think your statement will return a huge number of rows (over two billion), ROWCOUNT_BIG() will be the function to use instead. I have used all of these system function examples more often than I can count. You likely will as well, or you will find others more useful to you.
Note: You may have noticed the system functions are not consistently written: some of them are prefaced with “@@”, and some are appended with “()”, so be careful to check which is which when you are using them.
System stored procedures
Like the system functions, the system stored procedures are Microsoft’s internal stored procedures. There are a metric ton of them – so many that Microsoft lists them by category rather than listing them separately. In SSMS, you can find them by going to the Programmability tab, then expanding the Stored Procedures tab, then expanding the System Stored Procedures tab. Most are for internal processes and shouldn’t be used unless you know what you are doing. Some examples that you can use include sp_helpdb, which will give you basic information about all your databases:
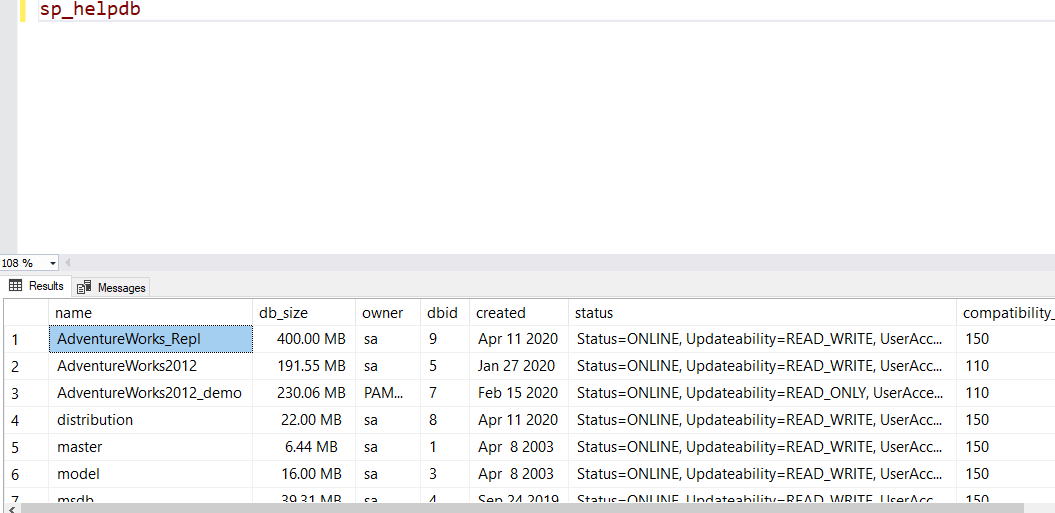
Or, just more detailed information on one database in particular:
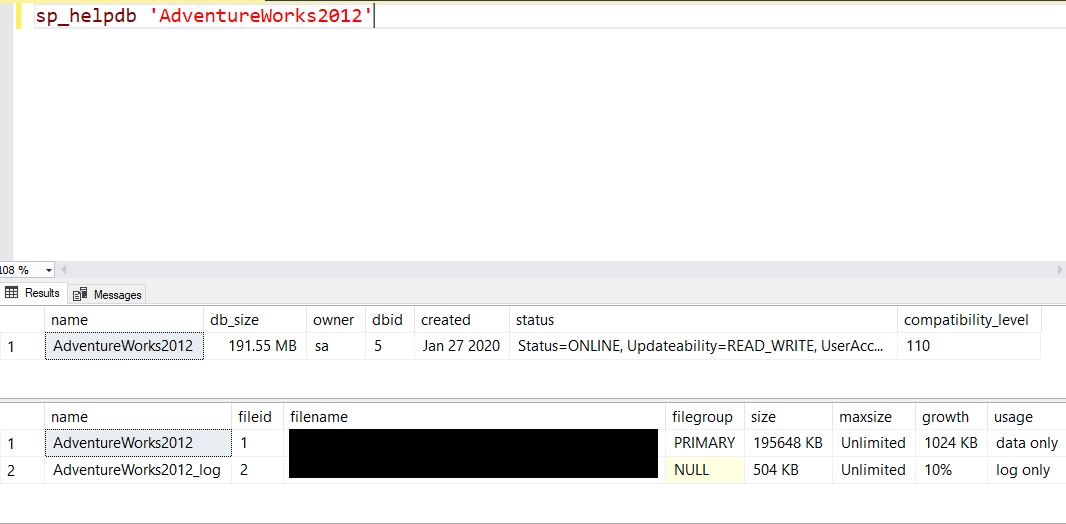
Another example would be sp_helpserver, which will give you info on your server or linked servers on your instance. If you are a new DBA, stick to the sp_help procedures for now.
Databases in SQL Server
So, we’ve taken the server-level, 10,000 mile-high view of SQL Server. Let’s begin talking about databases.
There are two types of databases in SQL Server: system databases and user databases.
There are five system databases that you will typically see in a SQL Server instance:
- master – this is where you’ll find all the basic information of your SQL Server instance, including the logins, databases, settings – everything. SQL Server doesn’t start without this database, so it is paramount that this (as well as all of the other system databases except resource and tempdb) are regularly backed up.
- model – this is, yes, the “model” for what all your other databases will look like. Whatever you do here happens to any new database made afterward.
- msdb – this is where all the SQL Agent job information is located. It’s also the home of database mail and service broker and the backup history. Jeremiah Peschka suggests limiting the amount of backup history you keep, but be very careful with this. Know what the business expectations are for backup history retention, and never assume that is your decision to make – it isn’t.
- tempdb – this is SQL Server’s scratchpad, where temp tables are made and discarded, where versioning is used for some of the isolation levels, and where query processing goes to do its work (and to spill data from badly performing queries). It is remade every time SQL Server reboots. You want to give tempdb plenty of room to work, and of course, it is the only database (along with the Resource database) you do not back up.
- Resource – this database will be invisible to you unless you know some special queries to look at it. This is where the system objects are kept. It is best to let it do its job and leave it alone.
- Distribution – you will see this special system database on the distribution server instance if you use replication.
User databases are just what they sound like – databases that were created by SQL Server users.
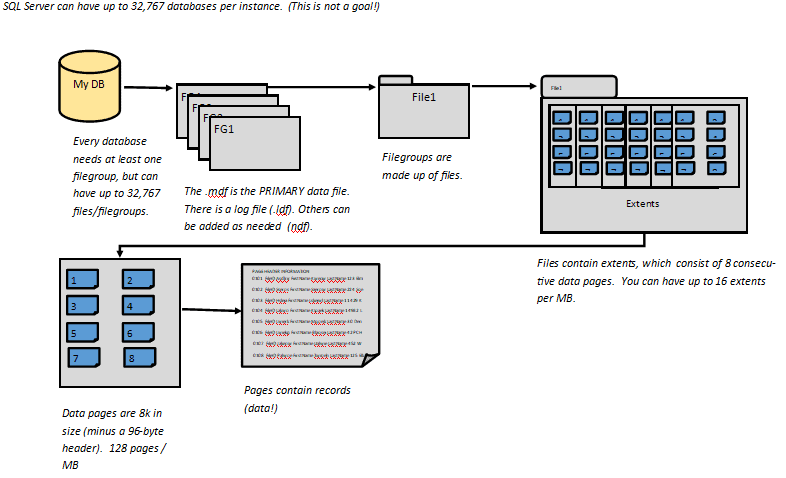
Filegroups
Data files are grouped into filegroups on databases. This allows for better organization and efficiency. There is always one filegroup – PRIMARY – that houses the main data file, or .mdf. But you can have as many as are needed. Jess Borland does a great job of discussing filegroups here.
Why would you have more than one filegroup? Aside from the obvious organizational benefits, if you have multiple filegroups, you can leverage piecemeal or partial restores in an emergency. Paul Randal goes into this in his “Advanced Corruption Recovery Techniques” course on Pluralsight. It’s highly recommended that you listen to his course “SQL Server: Detecting and Correcting Database Corruption” first.
Tables, data types, and referential integrity
Just like there are system and user databases, there are system and user tables.
- System tables – here’s an article from Tom LaRock explaining them.
- User tables – just what they sound like! These are tables created by users.
When you query the content of a table in SSMS, the output looks a great deal like an Excel spreadsheet. One of the many advantages that SQL Server has over Excel lies in its ability to allow its tables to “talk” to each other. Millions of rows and huge numbers of columns can be joined together from tables to give the end-user the data they need (although again, this is not a goal!).
Why is this not a goal? Because as a DBA, one of your goals is to get the right data to the right user at the right time, as quickly as possible. To accomplish the “as quickly as possible” piece, it’s important to use the right architecture from the beginning.
Kimberly Tripp of SQL Skills illustrates the point of using the smallest data type that can reasonably be used to accomplish the objective here. A small difference in bytes saved can equal GB saved at scale. Moreover, there can be huge savings in IO, CPU, and other metrics. I highly recommend this course, which can save a great deal of pain and suffering later.
So now that you realize how important they are, a review of data types is in order. When new tables come through development, it’s an opportunity for you to help ensure efficiency from the start, by looking at the data types and offering suggestions for more efficient ones that should accomplish the same business purpose.
With very few exceptions, your tables should have a primary key – one or more fields that guarantees a record (row) is unique. Any field that you choose for the primary key must have data in it (in other words, it cannot be NULL). You are only allowed one primary key per table. Whatever primary key or clustering key you choose, it should be unique, narrow, static, and ever-increasing. This ensures that new rows have the best chance of being inserted at the end of the data page, rather than at different points in it. This is important (and we’ll discuss why soon).
When you create the primary key, you create a primary key constraint by default. A constraint is nothing more than a rule in SQL Server. This constraint ensures that every row is unique – preventing duplicate data. The primary key in one table can be used to link to another table. When that happens, it’s called a foreign key.
SQL Server will try to ensure that the data in related tables is correct (with your help). For instance, let’s say you have a database to track bicycle orders (if this sounds suspiciously like AdventureWorks, well, it’s not paranoid if it’s true). In that database, you have tables for your CustomerID, CustomerName, CustomerAddress, and OrderIDs. If you have an order for a bicycle, you can make the relationship between the customer number, name and shipping information, and order number. So now, for every order number, there must be a customer number, a name, and shipping information. That relationship is called referential integrity. It is usually enforced by constraints but can also use things like triggers or defaults (although constraints are preferred). Triggers can have performance overhead and can be tricky to maintain. For those reasons (among others), I don’t recommend using them as a first course of action.
Indexing
So far, we’ve taken SQL Server down to the bare bones and started building back up again. We have tables with the right data types to fit the most data possible on to our 8k data pages. The right relationships between the tables are established. That ensures that when the tables are queried, we have fewer pages to spin up into memory for processing, and performance will be great, right?
Not yet. For one thing, we haven’t indexed our tables.
What are indexes in SQL Server?
Indexes are just what you think they would be – sort of. SQL Server has two basic types of indexes: the clustered index and nonclustered indexes.
The clustered index is the data: it’s the order the data is physically sorted in. It is roughly analogous to the table of contents in a book. It is not, however, necessarily the same thing as the primary key. When you create a primary key in SQL Server, you create a unique clustered index by default. However, you could opt to create a unique nonclustered index to enforce the primary key constraint (not that I would recommend it in most cases).
So, what is a nonclustered index, and how is it different? A nonclustered index is a copy of some of the table columns (with the clustering key tacked on under the covers). It doesn’t have to be unique – and often is not. Why would you want that? Because frequently, when you query SQL Server, you don’t want to look through every row of every column of the table in the clustered index – or even most of them – if you could find it faster by looking through a few rows in a few columns.
Because nonclustered indexes are, in effect, copies of the tables, they need to be maintained, and they’ll grow as the tables grow. So, you don’t want too many of these per table. It’s important to create the nonclustered indexes that you know will be used by most of your queries (which is the art, versus the science, of indexing).
Underneath clustered and nonclustered indexes there are other possibilities that you will probably see as your career progresses:
- Unique clustered index (the default clustered index)
- Non-unique clustered index
- Unique nonclustered index
- Non-unique nonclustered index (the default nonclustered index)
- Unique filtered indexes
- Non-unique filtered indexes
Finally, there is a thing called a HEAP. Heaps are tables without clustered indexes. When you are inserting records into a heap, it will be blazing fast. This is because SQL Server won’t try to put the records in any sort of order. First come, first served! That seems great until you try querying a table sitting on a heap. Then, prepare to sit and watch the grass grow while SQL Server frantically tries to retrieve the records you asked for. Unless you’re doing ETL work, you want your table to have a clustered index.
Index maintenance
Since you’re a good DBA and your tables are well-indexed, do you know how SQL Server figures out which indexes to use? That is where statistics come in! Statistics are just units of measure that keep track of things such as data distribution in tables and how often indexes are accessed. In this way, SQL Server can look at a table named dbo.Employee and know things such as there are 11 rows of data for employees whose last name falls between Ba-Bl, and that there is a nonclustered index on that table that is used 15% of the time, but there is another index that could be there that would constitute a 93% improvement. SQL Server uses these numbers to determine its execution plans, to make indexing recommendations, etc. These recommendations are not perfect, but they can be a starting place to point you in the right direction.
On tables where data is being inserted, updated, or deleted, your indexes and statistics are going to go through some wear and tear. Index wear and tear is called fragmentation, and there are two types:
- Logical fragmentation – the physical data page no longer matches the index key order, due to the data page splits that happen during INSERT or UPDATE queries.
- Physical fragmentation – there is more free space on the data page than there should be, due to page splits (usually through DELETE queries, but also during INSERT or UPDATE operations).
As your indexes grow (or shrink) and change, statistics can get out of date as well. All of these things can cause performance problems unless you have a process to keep it all current. There are several options out there to help, but the best way to keep your indexes and statistics tuned is to use Ola Hallengren’s Maintenance Solution. His scripts will set up all the SQL Server Agent Jobs you need to maintain your indexes, statistics (and will even manage your backups and database integrity checks, if you like). They are free, well-vetted, and safe to use in production.
Database Objects
We have discussed a couple of types of database object already – tables and indexes. But there is much more to SQL Server than just those two things. Let’s touch on some of the database objects you can expect to see and work with as a DBA.
Views
Say that you want to see two columns from Table A, three columns from Table B, a column from Table C, and four columns from Table D joined together, but you don’t want to retype the code to make that happen every single time you need it. You don’t need to! You can make a view. There are system views and user-made views.
A view is just that – a virtualized table. They can be materialized, though, in special circumstances. Those kinds of views are called indexed views. Indexed views do have some limitations, but are a valuable tool to have in your toolbelt. They are particularly useful for aggregations.
Synonyms
A synonym is nothing more than a nickname. Rather than saying, SELECT TOP 10 * FROM SERVERINSTANCE.DatabaseName.dbo.ObjectName over and over in your code, you could just use a synonym: SELECT TOP 10 * FROM ObjectName. When you create the code for the synonym, you “point” it, like this:
CREATE SYNONYM dbo.ObjectName FOR SERVERINSTANCE.DatabaseName.dbo.ObjectName
Aside from saving you the tedium of typing a fully qualified name over and over, synonyms offer a significant advantage: if the location of the object ever changes, just repoint the synonym, and all the code still works. If you don’t use synonyms, and a referring object location ever changes, better hope you found every occurrence in every piece of code ever, or something will break, and it will probably be a long time before you find it.
Stored procedures
A stored procedure (also commonly called a “sproc”) is a script that is stored on SQL Server. As with the other database objects we have discussed, there are system stored procedures and user-made sprocs. Aside from saving you the time and labor of retyping code every time, stored procedures have other upsides:
- They are usually flexible because they use parameters and variables.
- They are compiled in SQL Server, so the execution plans can be reused (this should be a good thing, but sometimes is not).
- They have been tested, and it is generally recommended that end-users use a stored procedure over ad-hoc code for this reason as well as performance reasons (precompiled code, prevention of cache bloat, etc.).
Functions
Functions are routines that will take a parameter, perform some sort of action on it (usually a calculation), and return the result of that action. Other code will see the output, but not the code of the function itself, making it somewhat like a miniature program in and of itself. Like stored procedures, they are compiled at runtime, and SQL Server can remember that the execution plan is there (if you query the cached_plans DMV, you’ll see an object type of “Proc”, though, which can be a little misleading).
Aside from the system functions and aggregate functions, you’ll be primarily dealing with two types: table-valued functions and scalar-valued functions. A table-valued function returns a result set in the form of a table. It is executed once per session (usually making it more performant than a scalar-valued function). A scalar-valued function will execute once per row of data returned, making it costly to use. We will go into this in more detail in the Query Tuning Basics section.
Triggers
Triggers are stored procedures that automatically fire when an event “triggers” them. They are attached to tables and are not visible unless you go looking for them in SSMS. When triggers break or act in unanticipated ways, their very nature (the fact that they go off automatically when triggered and are largely invisible) makes them somewhat difficult to troubleshoot. They are typically used for auditing or to keep corresponding tables current, but they should be used sparingly and with caution.
Assemblies
Assemblies are objects that are compiled together and then deployed as a single unit in the form of a .dll file. They can be made of up stored procedures, functions, triggers, types, and/or aggregates. They are created in .NET instead of using T-SQL. They can present a security risk, so it’s important to know how the business feels about them before using them and how to do it safely.
Types
Types in SQL Server can be system data types, or user-defined. Sometimes, users need to define custom data types or table types, and here is where SQL Server allows that to happen.
Rules
Rules are just what you’d think they are. They are a type of constraint that forces data to comply with its conditions. They are a deprecated feature as of 2012.
Sequences
A sequence is a schema-bound object that creates a list of numbers, beginning with a specified value, then increments and returns them, according to user specifications.
Agent Jobs: Getting the right data to the right people at the right time
Database jobs take multiple actions that SQL Server performs automatically for you at a specific time that you schedule. They are run by the SQL Server Agent. Job steps can be run as T-SQL, from the command prompt, using SSIS, PowerShell, or many other options. I will cover some examples of jobs and practice creating some as well in a future article.
Query tuning basics: Getting the right data to the right user at the right time, as quickly as possible
By this point, you have a basic understanding of SQL Server and how it works (I know you are thinking, basic!!?? The good news is that you’ve chosen a field that will ensure that you are a lifelong learner. At least you will never be bored!) We’ve learned how to build tables with the right data types, and how to use primary and foreign keys to effectively define, link, index, and protect our data. We have a basic idea of the types of indexes and why they are used, and how SQL Server uses statistics to keep track of the data and optimize query plans. We understand database objects and how they are used.
You would think we’d be all ready to go. But we’ve only laid the foundation.
Because now, we’re letting people into our database to query it. And people write evil, awful queries sometimes.
It’s usually not their fault. SQL works on a different paradigm than many other programming and scripting languages. SQL works best when it is used for set-based operations – getting batches of data at once. That means that some of the basics developers learn like cursors, which go through every row of a table – or even a group of tables- to return data can bring a SQL Server pain and suffering. As a DBA, you are a resource to help developers get the right data to the right people as quickly as possible.
It’s not uncommon for a horribly performing query to come to your attention that is bringing the server to its knees. The developer swears that it ran fine in test. There could be many reasons this is happening, but we’ll focus on six of the most common ones. These are known as antipatterns. Future articles will address more specific query tuning techniques.
The query is bringing it ALL back
The first example that comes to mind is the dreaded SELECT * FROM…. query, but it can be any query that is bringing back more columns than it needs. SELECT * in particular is discouraged because it can be a performance hit. This query can also bring back unexpected results if the underlying table structure has changed as well.
The problem with a query that “brings it all back” is that it causes unnecessarily increased IO and memory. I worked on a case some time ago where a query was timing out. SQL Server on that instance had been restarted a couple of times due to the stress on the server, with no help in sight. When my colleague and I first went to work on the issue, the problem query was generating over 217 million logical reads per execution. Refining the query to bring back only the columns needed resulted in 344,277 reads. CPU went from 129,031 to 1.470. If the vendor had allowed us to index the table needed, we could have gotten the reads down to 71.
Moral of the story: Make sure the query brings back only what it needs.
Nested Views
This is the case where you find views calling views calling whatever else until – finally -the tables are called. SQL Server will try to help figure out what you need, but there is a performance hit just on that effort, and the execution plan will be needlessly complex. It can (and probably will) also cause prolonged execution times, returning more data than you needed in the first place. Finally, they are a nightmare to troubleshoot, and when one of the underlying views break, they can return unexpected results.
Some time ago, I had a developer come for help with an application that was using a linked server to query our stage environment when he was expecting it to hit dev. He couldn’t figure out why it was happening. It turned out that the code was calling a nested view. Every synonym in every view (and there were a lot of them) had to be scripted to find the culprit. It also meant that his result set could have been inaccurate. I’ve also seen nested views that went seven views deep, bringing back huge amounts of data, running the same risks. That is one example. They can be worse.
Moral of the story: Let your views be viewed as views only. Don’t use them as reference objects.
Use the right temporary structures
Usually, this means using a temp table, but not always. Temp tables have the advantage of honoring statistics, having the ability to be indexed, and are generally more performant. However, if you’re working with SSIS, if you need your table to survive a transaction rollback, or if you’re working with functions, table variables can be the only way to go. They have a major drawback – the optimizer will always assume that a table variable will return just one row (which may be great if that’s all you expect, or horrible if it returns hundreds of rows). SQL Server 2019 does help with table variables; you will get the correct estimate on row return on the first execution. However, it will use that estimate for the next one, so you come up against a parameter sniffing issue. Its query optimizer is getting smart enough to “learn”, so over time, performance will improve some.
However, in some cases, using temp tables or table variables can hurt rather than help. For instance, if you are only going to query the data you are compiling once, you don’t need the cost of loading a temp table or a table variable. This is where a CTE can be your best friend, or a subquery with a CROSS APPLY might work better There are a lot of options at your disposal. Test and see what works best for your query.
Death by a Thousand Cuts – Non-SARGable Queries
Non-SARGable queries are those queries that require row-by-agonizing-row (RBAR) processing. I’ll focus on scalar-valued functions here, but any functions in the WHERE clause (that are on the column side of an operator) will do this as well.
Scalar valued functions are query killers because they execute row-by-row. Where at all possible, either rewrite these as table-valued functions or inline the logic. You might not easily see the damage to the query by looking at an execution plan, but a Profiler trace (make sure reads are included) will show you just how evil they can be.
Implicit Conversions – the Silent Killer
Implicit conversions happen when a query is comparing two values with different data types. This forces SQL Server to figure out what you’re talking about. The conversion is based on data type precedence and causes increased CPU, but the real performance hit comes from the forced index scans. In rare cases, implicit conversions can even give inaccurate or misleading query results. Worse yet, they aren’t always obvious (even in the execution plans). The fix is to CAST or CONVERT one of the data types to match the other.
Parameter Sniffing
The first time SQL Server gets a stored procedure, it optimizes for the parameter it receives from the end-user. Maybe it’s looking for the EmployeeID of anyone with the last name of Smith (not a real selective query). But the next time the sproc is used, it’s now looking for the EmployeeID of anyone with the last name of Meshungahatti. But the optimizer sees it has a plan it has already stored for Smith, and it uses that. The problem is, now SQL Server is estimating that it will return thousands of rows instead of one, wasting resources, memory, and IO. This can also work in reverse: SQL Server can assume that only a few rows will be returned when maybe millions actually will be. There are a few options to fix parameter sniffing – click here and here for more info. Also, be aware of these:
- In SQL Server 2016, there is an option to turn parameter sniffing off per database (
ALTER DATABASE SCOPE to set PARAMETER_SNIFFING =OFF) but it works a lot likeOPTIMIZE FOR UNKNOWNunder the covers. It can impact the performance of other queries, so be careful with this one. - You can enable trace flag 4136 (SQL Server 2008 R2 CU2 and up) to disable parameter sniffing at the instance level – again, be careful with this.
SQL Server under the hood
SQL Server is a big product, and there is a lot to learn. This article covered how SQL Server is built and some of the anti-patterns to look for when query tuning.
The post DBA in training: SQL Server under the hood appeared first on Simple Talk.
from Simple Talk https://ift.tt/3iXuvoc
via
No comments:
Post a Comment